On Distributional Reinforcement Learning in Chaotic Dynamical Systems
Pith reviewed 2026-06-29 08:28 UTC · model grok-4.3
The pith
Return distributions evolve more regularly than individual trajectories in chaotic systems under the 1-Wasserstein metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under mild statistical stability assumptions, the return distribution evolves more regularly than individual trajectories when measured under the 1-Wasserstein metric, yielding a smoother distributional Bellman objective. By aligning optimisation with this measure-level structure, distributional RL provides better conditioned learning in chaotic dynamical systems.
What carries the argument
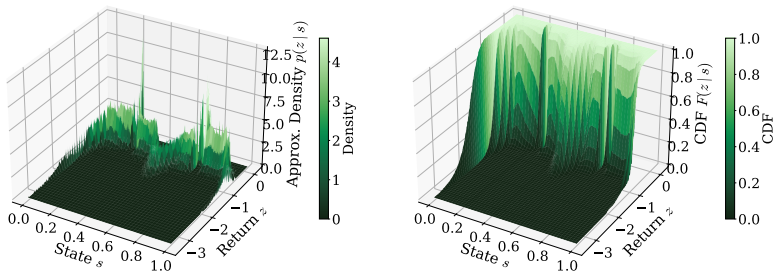
The 1-Wasserstein metric on return distributions inside the distributional Bellman operator, which quantifies regularity at the probability-measure level rather than along individual trajectories.
If this is right
- Distributional RL produces better-conditioned gradient updates than scalar RL when dynamics are chaotic.
- The 1-Wasserstein geometry on return distributions separates trajectory instability from the learning objective.
- Standard scalar methods entangle exponential divergence of paths with the optimisation landscape.
- Reliable learning becomes feasible in scientific domains whose governing equations are chaotic.
Where Pith is reading between the lines
- The same Wasserstein regularity could be checked empirically on standard chaotic benchmarks to quantify the improvement in conditioning.
- Extensions might examine whether other probability metrics preserve the regularity advantage or whether the result depends on the specific stability assumptions.
- Policy-search methods that operate directly on return distributions may inherit the same conditioning benefit in chaotic multi-agent settings.
Load-bearing premise
Mild statistical stability assumptions make the return distribution evolve more regularly than individual trajectories.
What would settle it
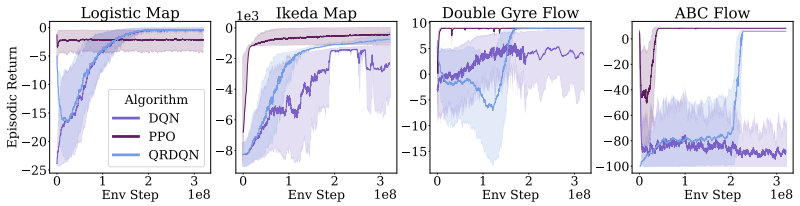
Measure the condition number or gradient variance of the distributional versus scalar Bellman operator on a concrete chaotic map such as the logistic map or Lorenz system and check whether the distributional version remains smaller.
Figures

read the original abstract
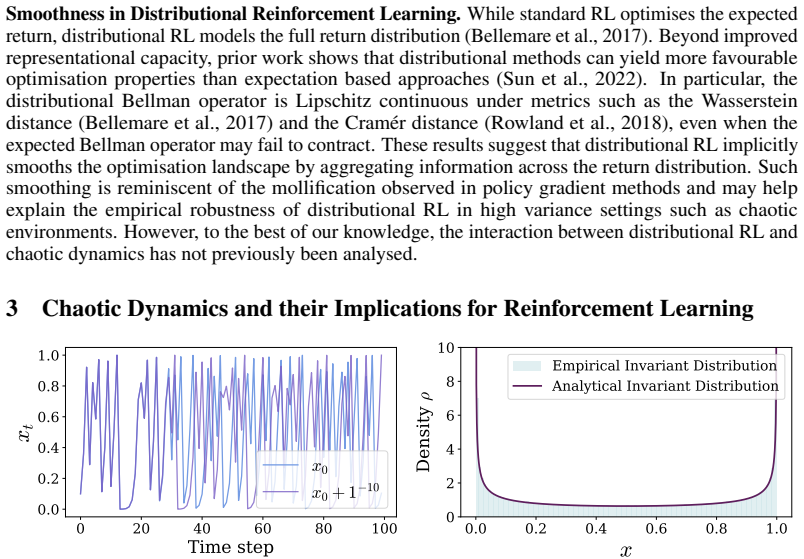
Chaotic dynamical systems pose a fundamental challenge for Reinforcement Learning (RL): exponential sensitivity to initial conditions induces high-variance bootstrap targets and poorly conditioned gradient updates. Chaotic dynamics arise across scientific and engineering domains, from fluid flows and climate systems to multi-agent systems, where reliable learning is highly desirable. Standard RL methods optimise expected returns through scalar value functions, implicitly averaging over diverging trajectories and entangling trajectory level instability with the learning objective. We show that under mild statistical stability assumptions, the return distribution evolves more regularly than individual trajectories when measured under the $1$-Wasserstein metric, yielding a smoother distributional Bellman objective. By aligning optimisation with this measure level structure, distributional RL provides better conditioned learning. We offer a principled explanation for the advantages of distributional methods in chaotic systems and the geometries of RL objectives under chaos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that chaotic dynamical systems pose challenges for standard RL due to exponential sensitivity inducing high-variance targets, but that under mild statistical stability assumptions the return distribution evolves more regularly than individual trajectories under the 1-Wasserstein metric; this yields a smoother distributional Bellman objective, providing a principled explanation for the advantages of distributional RL in chaotic domains such as fluid flows and climate systems.
Significance. If the central claim can be rigorously established, the work would supply a geometric and measure-theoretic rationale for preferring distributional methods in chaotic environments, potentially guiding algorithm design in scientific RL applications where trajectory instability is inherent.
major comments (2)
- [Abstract and §1] Abstract and §1: the headline regularity claim is conditioned on unspecified 'mild statistical stability assumptions' (mixing rates, invariant-measure regularity, moment conditions). No definition, verification that they are compatible with exponential divergence, or derivation showing the 1-Wasserstein contraction is stricter than the trajectory-level one is supplied, rendering the central comparison ungrounded.
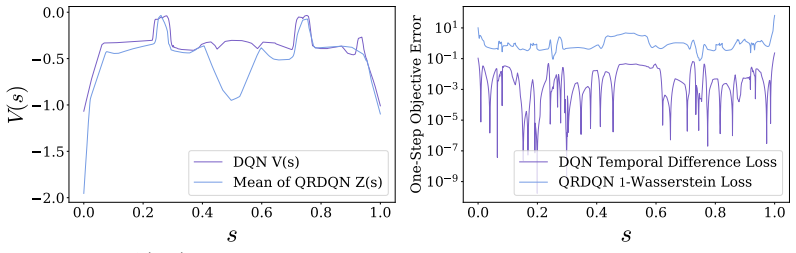
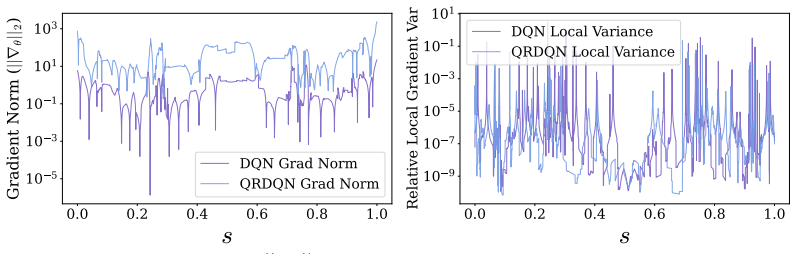
- [§3] §3 (presumed distributional Bellman section): the assertion that alignment with the return-measure geometry produces 'better conditioned learning' is stated without an explicit comparison of the Lipschitz constants or conditioning numbers of the scalar versus distributional operators under the stated assumptions.
minor comments (2)
- [Preliminaries] Notation for the return distribution and the precise form of the 1-Wasserstein metric used should be introduced with an equation in the preliminaries.
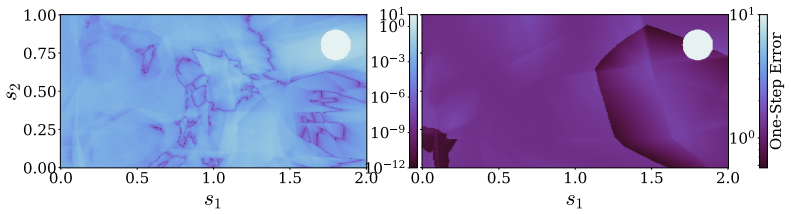
- The abstract refers to 'geometries of RL objectives under chaos' without a subsequent section or figure that visualizes or quantifies this geometry.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We agree that the statistical stability assumptions and the operator comparisons require explicit treatment in the manuscript. We will revise accordingly to strengthen the central claims. Responses to each major comment follow.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: the headline regularity claim is conditioned on unspecified 'mild statistical stability assumptions' (mixing rates, invariant-measure regularity, moment conditions). No definition, verification that they are compatible with exponential divergence, or derivation showing the 1-Wasserstein contraction is stricter than the trajectory-level one is supplied, rendering the central comparison ungrounded.
Authors: We agree that the assumptions are referenced but not defined in the abstract and §1, and that explicit verification and derivation are needed. In the revised manuscript we will insert a precise definition of the mild statistical stability assumptions (including quantitative mixing rates, regularity of the invariant measure, and moment conditions) immediately after the statement of the main claim. We will add a short lemma establishing compatibility with exponential trajectory divergence (stability holds at the level of the push-forward on measures, not pointwise) and a derivation comparing the contraction rate of the return distribution under the 1-Wasserstein metric to the growth of scalar return variance. revision: yes
-
Referee: [§3] §3 (presumed distributional Bellman section): the assertion that alignment with the return-measure geometry produces 'better conditioned learning' is stated without an explicit comparison of the Lipschitz constants or conditioning numbers of the scalar versus distributional operators under the stated assumptions.
Authors: We acknowledge that the current text does not supply an explicit side-by-side comparison of Lipschitz constants or conditioning numbers. In the revision we will add a proposition in §3 that derives the Lipschitz constant of the scalar Bellman operator (with respect to the sup norm) and of the distributional Bellman operator (with respect to the 1-Wasserstein metric) under the stability assumptions, and shows that the distributional operator has a strictly smaller effective conditioning number because the measure-valued evolution damps the sensitivity induced by chaos. revision: yes
Circularity Check
No circularity: claim presented as independent result under external assumptions
full rationale
The abstract states a regularity result for return distributions under 1-Wasserstein distance but supplies no equations, no fitted parameters, and no self-citations that reduce the claim to its own inputs. The central assertion is framed as a first-principles observation conditional on unspecified statistical stability assumptions; no derivation chain is exhibited that would make the conclusion tautological by construction. This is the normal case of an independent (if underspecified) insight rather than a circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From entropy to epiplexity: Rethinking information for computationally bounded intelligence
Marc Finzi, Shikai Qiu, Yiding Jiang, Pavel Izmailov, J Zico Kolter, and Andrew Gordon Wilson. From entropy to epiplexity: Rethinking information for computationally bounded intelligence. arXiv preprint arXiv:2601.03220,
-
[2]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing Atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ricard Montalà, Bernat Font, Pol Suárez, Jean Rabault, Oriol Lehmkuhl, Ricardo Vinuesa, and Ivette Rodríguez. Deep Reinforcement Learning for Active Flow Control Around a Three-dimensional Flow-separated Wing at Re = 1,000.arXiv preprint arXiv:2509.10195,
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The chaotic control environments are part of a github package that will be linked here upon acceptance to ensure double blind is respected
A Experimental Code Code for all the experiments will be released upon acceptance. The chaotic control environments are part of a github package that will be linked here upon acceptance to ensure double blind is respected. We’d like to thank Thyng et al. (2016) for creating cmocean, a great source of colour maps used throughout this paper! B Proof of Theo...
2016
-
[6]
right" attractor, and conversely δAR a
and using that Z π(·, a) is K-Lipschitz with respect to W1 (by the definition ofK), the mixture stability property ofW 1 implies: W1 (Z π(S′ 1, A′ 1), Zπ(S′ 2, A′ 2))≤E W1(Z π(S′ 1, A′ 1), Zπ(S′ 2, A′ 2)) ≤KE∥S ′ 1 −S ′ 2∥.(21) Here we use the standard inequality that W1 between mixtures is bounded by the expectation of W1 under a coupling of the mixing v...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.