CommunityFact: A Dynamic, Multilingual, Multi-domain Benchmark for Misinformation Detection in the Wild
Pith reviewed 2026-06-29 07:30 UTC · model grok-4.3
The pith
Web-enabled LLMs select sources for verifying claims that differ systematically from the sources human Community Notes raters converge on.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
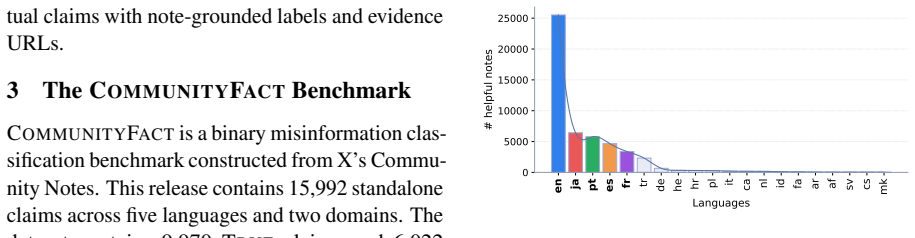
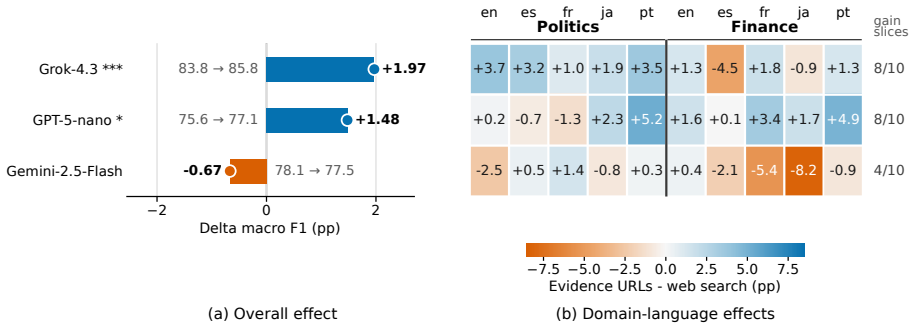
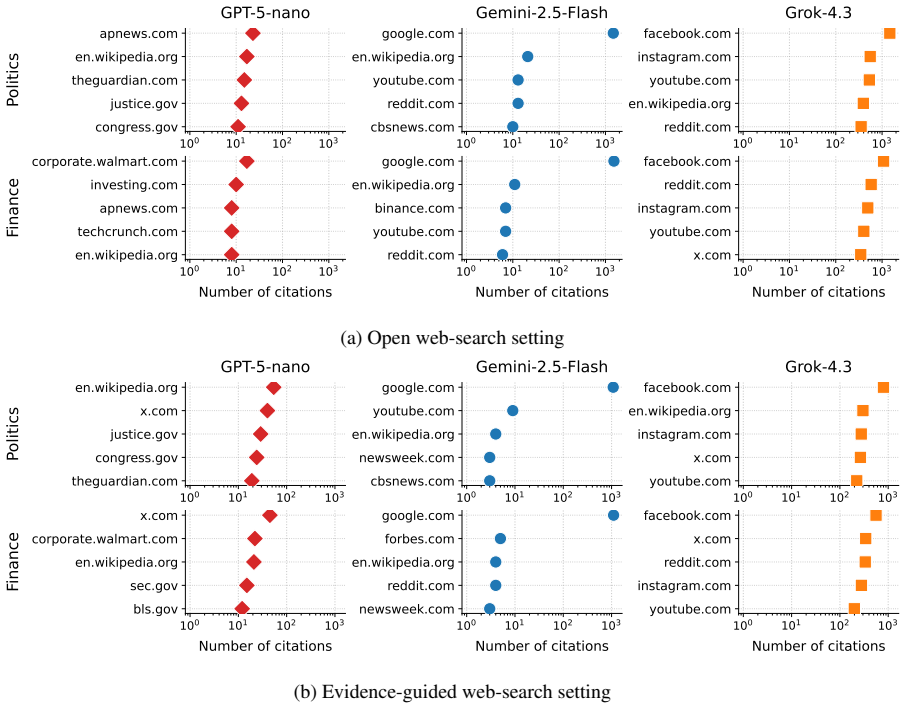
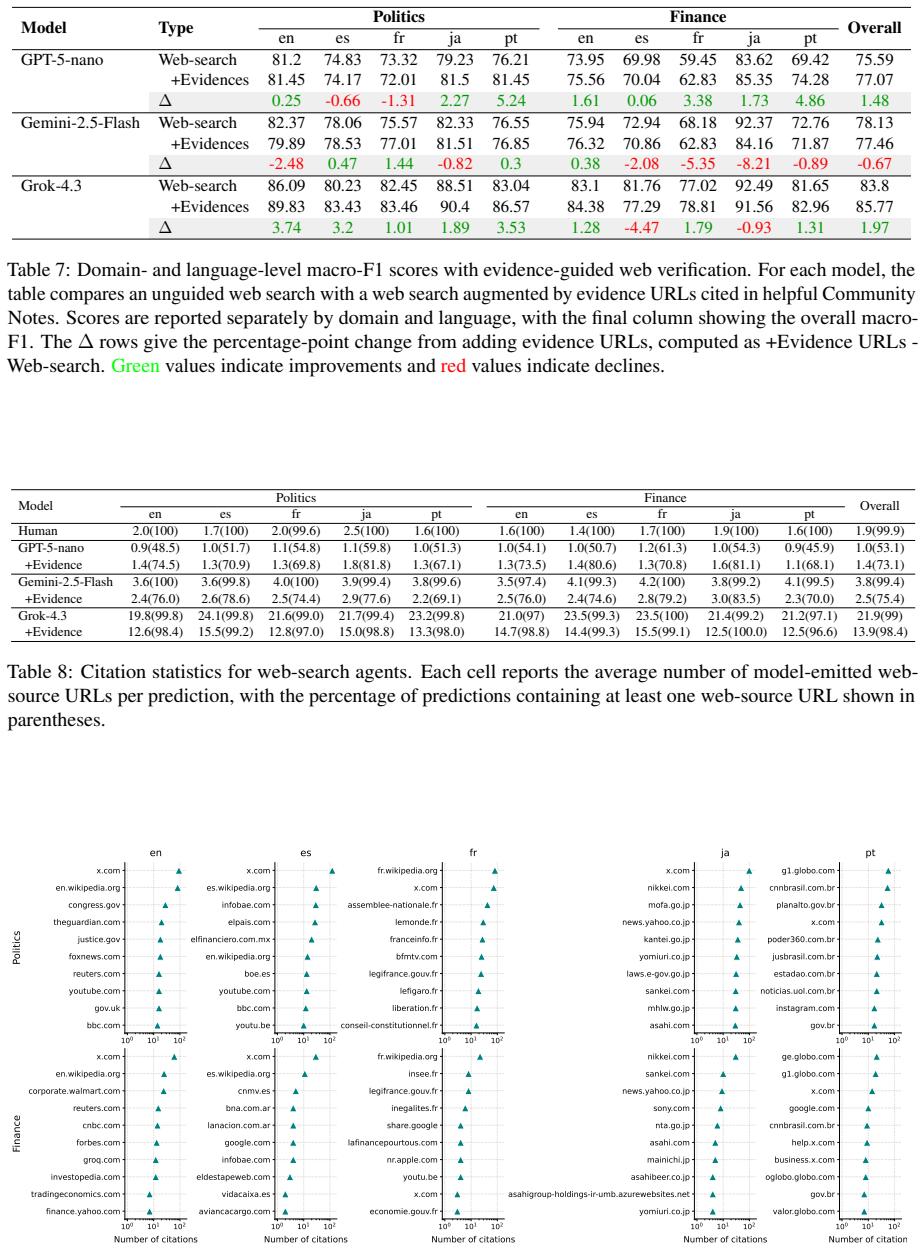
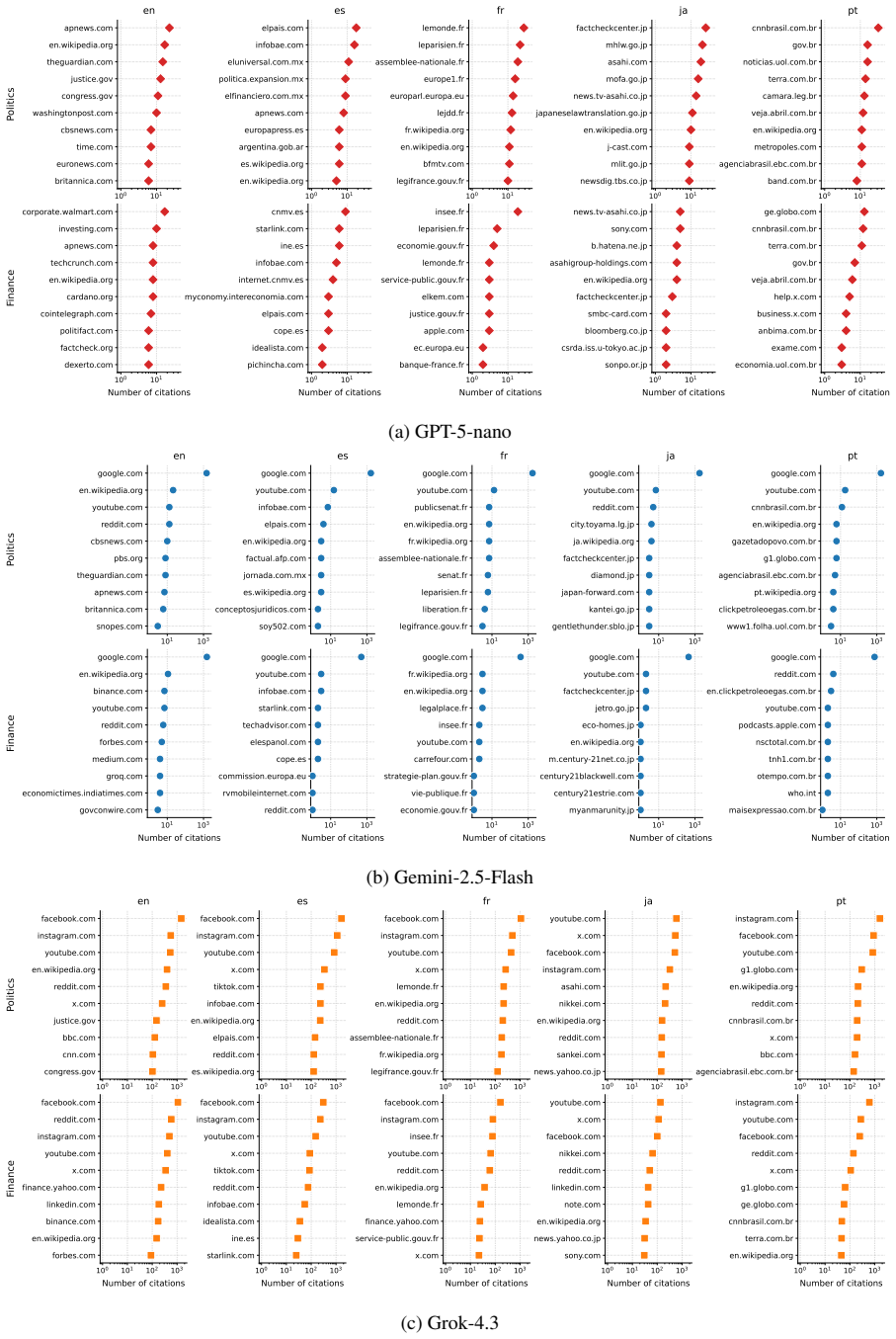
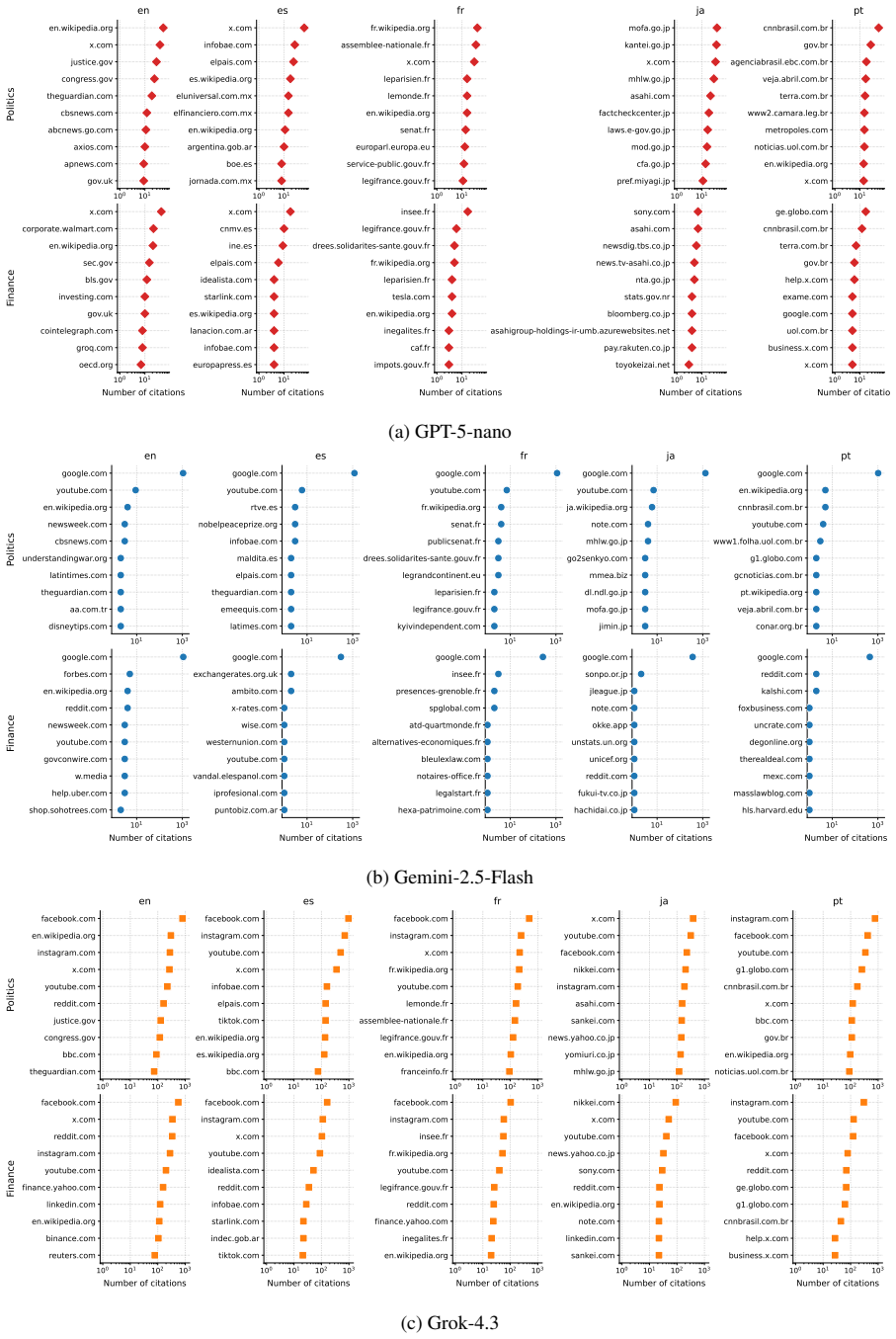
CommunityFact supplies a dynamic collection of 15,992 standalone claims across five languages and two domains. Evaluation of ten LLMs shows closed-input verification remains hard, web access yields the largest gains, and web-enabled models' source-selection policies are systematically misaligned with the sources that human Community Notes raters converge upon; this gap narrows through model-specific retrieval expansion or pruning. Substantial variation appears across language-domain slices and across the evidence ecosystems used by different web-enabled systems. The resource further frames Community Notes data as a training signal for claim-conditioned source suggesters.
What carries the argument
The CommunityFact benchmark, which pairs each claim with the sources converged upon by human Community Notes raters to quantify misalignment in LLM source-selection policies.
If this is right
- Closed-input verification stays difficult across the tested models.
- Web access produces larger accuracy gains than internal thinking alone.
- Source-selection misalignment varies by language and domain slice.
- Different web-enabled systems draw from distinct evidence ecosystems.
- Community Notes data can train claim-conditioned source suggesters for novel claims.
Where Pith is reading between the lines
- Models trained on these alignments could generalize source suggestions to claims outside the current benchmark.
- Dynamic updates to the benchmark would let researchers track whether retrieval policies improve or drift over time.
- The observed language-domain variation suggests targeted retrieval tuning per slice may be needed before broad deployment.
Load-bearing premise
Agreement among human Community Notes raters supplies a reliable external reference standard for judging whether an LLM has selected appropriate sources.
What would settle it
A fresh collection of claims on which web-enabled LLMs that apply retrieval expansion or pruning still select sources that diverge from the sources human raters converge on.
Figures








read the original abstract
Misinformation verification increasingly occurs in public, fast-moving, and multilingual online settings, where static benchmarks provide an incomplete measure of model reliability. We introduce CommunityFact, a refreshable benchmark for misinformation detection in the wild, with three major goals: coverage, granularity, and redistributability. This release contains 15,992 standalone claims across five languages and two domains. We evaluate ten LLMs under varying inference-time capabilities, including thinking and web-search. Our results show that closed-input verification remains challenging, web access yields the largest gains, and web-enabled LLMs' source-selection policies are systematically misaligned with the sources human Community Notes raters converge on -- a gap that closes through model-specific mechanisms of retrieval expansion or pruning. We further find substantial variation across language-domain slices and across the evidence ecosystems used by web-enabled systems. Beyond evaluation, CommunityFact positions Community Notes as a training signal for claim-conditioned source suggesters that could improve factual verification on novel claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CommunityFact, a refreshable benchmark with 15,992 standalone claims across five languages and two domains, designed to evaluate LLMs on misinformation detection in dynamic, multilingual, real-world settings. It reports evaluations of ten LLMs under closed-input, thinking, and web-search conditions, claiming that closed-input verification is challenging, web access yields the largest performance gains, web-enabled LLMs exhibit systematic misalignment in source-selection policies relative to sources converged upon by human Community Notes raters (with the gap closable via model-specific retrieval expansion or pruning), and that substantial variation exists across language-domain slices and evidence ecosystems. The work further positions the benchmark as a potential training signal for claim-conditioned source suggesters.
Significance. If the core empirical findings on web-access gains and source misalignment hold after addressing validation gaps, the benchmark could meaningfully advance evaluation practices for LLMs in fast-moving, multilingual misinformation contexts and open avenues for using Community Notes data in training. The dynamic and redistributable design addresses limitations of static benchmarks, and the multilingual/multi-domain coverage is a strength. However, the interpretive weight placed on human rater convergence as a reference standard without external accuracy validation limits the immediate significance of the misalignment claims.
major comments (2)
- [Abstract] Abstract (and implied results section): the claim that web-enabled LLMs' source-selection policies are 'systematically misaligned' with sources on which human Community Notes raters converge treats rater convergence as a reliable external reference standard for measuring misalignment. No independent validation (e.g., against external fact-checking accuracy, expert adjudication, or ground-truth labels) is described to establish that converged sources are more accurate, complete, or authoritative than LLM-retrieved alternatives; without this, the misalignment metric risks conflating deviation from crowd consensus with deviation from truth and is load-bearing for the performance-gap interpretation.
- [Abstract] Abstract: the reported results on closed-input verification difficulty, web-access gains, and cross-slice variation lack any description of the underlying statistical methods, confidence intervals, error analysis, or controls for claim difficulty, making it impossible to assess whether the stated patterns are robust or driven by the specific 15,992-claim sample.
minor comments (2)
- The manuscript provides no details on claim sourcing process, annotation guidelines, exclusion criteria, inter-rater agreement for the human Community Notes convergence, or how the benchmark ensures redistributability while remaining dynamic.
- No information is given on the ten LLMs evaluated (specific models, sizes, or versions), the exact prompting or retrieval setups for web-enabled conditions, or how 'thinking' and 'web-search' capabilities were operationalized.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract (and implied results section): the claim that web-enabled LLMs' source-selection policies are 'systematically misaligned' with sources on which human Community Notes raters converge treats rater convergence as a reliable external reference standard for measuring misalignment. No independent validation (e.g., against external fact-checking accuracy, expert adjudication, or ground-truth labels) is described to establish that converged sources are more accurate, complete, or authoritative than LLM-retrieved alternatives; without this, the misalignment metric risks conflating deviation from crowd consensus with deviation from truth and is load-bearing for the performance-gap interpretation.
Authors: The manuscript frames the source-selection analysis as a comparison against the specific sources on which human Community Notes raters converge, consistent with CommunityFact's construction from Community Notes data as a real-world human signal. We do not claim or provide evidence that these converged sources are more accurate, complete, or authoritative than LLM-selected alternatives, nor do we equate human consensus with ground truth. The reported misalignment describes a policy difference, and the performance gap refers to deviation from observed human rater behavior. We will revise the abstract and relevant sections to explicitly qualify the reference standard as human rater convergence without external accuracy validation, thereby avoiding any implication that deviation equals deviation from truth. revision: partial
-
Referee: [Abstract] Abstract: the reported results on closed-input verification difficulty, web-access gains, and cross-slice variation lack any description of the underlying statistical methods, confidence intervals, error analysis, or controls for claim difficulty, making it impossible to assess whether the stated patterns are robust or driven by the specific 15,992-claim sample.
Authors: We agree that the abstract does not describe the statistical methods, confidence intervals, error analysis, or controls. The full manuscript reports the core quantitative results, but to improve transparency we will revise the abstract to include a concise description of the statistical approaches (including confidence intervals and any controls for claim difficulty, language, and domain) and will ensure the results section provides explicit error analysis and robustness details. revision: yes
Circularity Check
No significant circularity in empirical benchmark evaluation
full rationale
The paper introduces CommunityFact as a new dataset and reports empirical results from evaluating LLMs under different inference settings against human Community Notes annotations. No equations, derivations, fitted parameters, or self-referential definitions appear in the provided abstract or described content. The comparison of LLM source selection to human rater convergence uses an external reference standard and does not reduce to a construction from the models' own outputs or prior self-citations. The work is self-contained as a benchmark study with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Machine Intelligence, 6(8):852–863
Factuality challenges in the era of large lan- guage models and opportunities for fact-checking. Nature Machine Intelligence, 6(8):852–863. Alberto Barrón-Cedeño, Firoj Alam, Tommaso Caselli, Giovanni Da San Martino, Tamer Elsayed, An- drea Galassi, Fatima Haouari, Federico Ruggeri, Ju- lia Maria Struß, Rabindra Nath Nandi, Gullal S. Cheema, Dilshod Azizo...
-
[2]
InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1610–1630, Vienna, Austria
Real-time factuality assessment from adver- sarial feedback. InProceedings of the 63rd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1610–1630, Vienna, Austria. Association for Computational Lin- guistics. Yuwei Chuai, Gabriele Lenzini, and Nicolas Pröllochs
-
[3]
Consensus stability of community notes on x. InProceedings of the ACM Web Conference 2026, WWW ’26, page 8885–8896, New York, NY , USA. Association for Computing Machinery. Yuwei Chuai, Haoye Tian, Nicolas Pröllochs, and Gabriele Lenzini. 2024. Did the roll-out of commu- nity notes reduce engagement with misinformation on x/twitter?Proc. ACM Hum.-Comput. ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Pedro Henrique Martins, João Alves, Patrick Fernan- des, Nuno M
Fact-audit: An adaptive multi-agent frame- work for dynamic fact-checking evaluation of large language models.Preprint, arXiv:2502.17924. Pedro Henrique Martins, João Alves, Patrick Fernan- des, Nuno M. Guerreiro, Ricardo Rei, Amin Fara- jian, Mateusz Klimaszewski, Duarte M. Alves, José Pombal, Nicolas Boizard, Manuel Faysse, Pierre Colombo, François Yvon...
-
[5]
NLP evaluation in trouble: On the need to mea- sure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Sin- gapore. Association for Computational Linguistics. Mohammadamin Shafiei, Hamidreza Saffari, and Nafise Sadat Moosavi. 2025. MultiHoax: A dataset of multi-hop false-p...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Motivations, methods and metrics of misin- formation detection: An nlp perspective.Natural Language Processing Research, 1:1–13. Yifan Sun, Han Wang, Dongbai Li, Gang Wang, and Huan Zhang. 2025. The emperor’s new clothes in benchmarking? a rigorous examination of mitiga- tion strategies for llm benchmark data contamination. Preprint, arXiv:2503.16402. Jam...
-
[7]
false" when the Note refutes the Tweet claim; label as
Tweet Claims: Extract Tweet claims only when the Note clearly addresses them. Label as "false" when the Note refutes the Tweet claim; label as "true" only when the Note clearly supports or confirms the Tweet claim. Otherwise drop
-
[8]
Note Claims: Label as "true" only when the Note itself makes a factual correction or factual assertion that is directly checkworthy
-
[9]
Do not use exact quotes
Paraphrase: Rewrite all claims in your own words. Do not use exact quotes. Claims must assert verifiable facts about the world — never about the tweet, note, or source itself. Drop any claim whose entire content is about the credibility, accuracy, sourcing, or wording of the tweet/note rather 19 than the underlying facts
-
[10]
Checkworthiness Scope: Keep only substantive high quality real-world facts/events. Drop metadata/status claims whose main point is who posted something, whether an account/source is official, verified, affiliated, fake, or impersonating, or whether a link/livestream/post/page is available, ended, deleted, or reposted. Do not extract these claims even when...
-
[11]
Text-Only: The downstream dataset will not include attached images, videos, screenshots, audio, or other media. Drop claims that require viewing, identifying, or interpreting media, including what media shows, who appears in it, where/when it was recorded, or whether it is edited, cropped, staged, AI-generated, or mislabeled
-
[12]
false" = the Tweet asserted it, and the Note refutes it
Label Precision: "false" = the Tweet asserted it, and the Note refutes it. "true" = the Note asserts it as fact. For substantive attributions, label the attribution itself: if a tweet says "X claims Y", label it "true" if the Note establishes that X made that substantive claim, even if Y is false. Do not apply this attribution rule to account/source authe...
-
[13]
U.S. visas
Specificity: Every claim must name the specific people, organizations, countries, jurisdictions, dates, places, figures, metrics, and issuers needed to identify the fact. Do not drop key qualifiers; for example, write "U.S. visas" rather than "visas" when the country matters. Do not add extra details unless they are necessary to disambiguate the claim
-
[14]
## Density & Balancing Rules
Language Match: Write each claim in the language of the input text segment. ## Density & Balancing Rules
-
[15]
Merge closely related contextual details such as who, what, when, and where into a single, comprehensive claim
Information Density: Do NOT hyper-fragment the text. Merge closely related contextual details such as who, what, when, and where into a single, comprehensive claim
-
[16]
Do not add background, explanation, evidence, rhetorical framing, or provenance unless it is essential to the fact being checked
Compactness: Keep each claim short while still being standalone and unambiguous. Do not add background, explanation, evidence, rhetorical framing, or provenance unless it is essential to the fact being checked
-
[17]
Do not make true claims longer by including extra evidence, caveats, or Note explanations
Length Neutrality: Write true and false claims at the same level of detail. Do not make true claims longer by including extra evidence, caveats, or Note explanations
-
[18]
false" Tweet claim and one strongest
Claim Balance: Extract one strongest "false" Tweet claim and one strongest "true" Note claim when both are valid
-
[19]
No Forced Claims: If no claim satisfies all rules, return []
-
[20]
A true corrective claim may contradict a false Tweet claim when it adds distinct factual content
No Duplicative Opposites: Do not output duplicate claims that merely restate the same fact with opposite labels. A true corrective claim may contradict a false Tweet claim when it adds distinct factual content
-
[21]
Zero-Context Formula
Output Limit: Strictly limit your output to a few high-value, information-dense claims. ## The "Zero-Context Formula" (CRITICAL) Every claim must be 100% standalone. A reader with zero knowledge of the tweet, note, media, URL, or other claims must fully understand it and fact-check it. - No back-references to other claims: If two claims share a subject, r...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.