DP-SAPF: Saliency-Aware Parameter Fine-tuning of Public Models for Differentially Private Image Synthesis
Pith reviewed 2026-06-29 06:37 UTC · model grok-4.3
The pith
Restricting LoRA to parameters with largest noisy gradients improves DP image synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
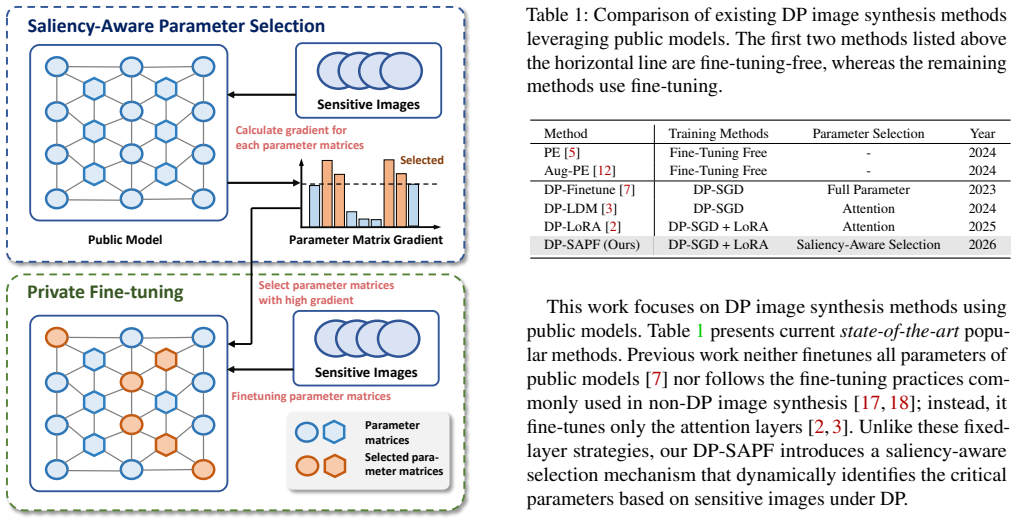
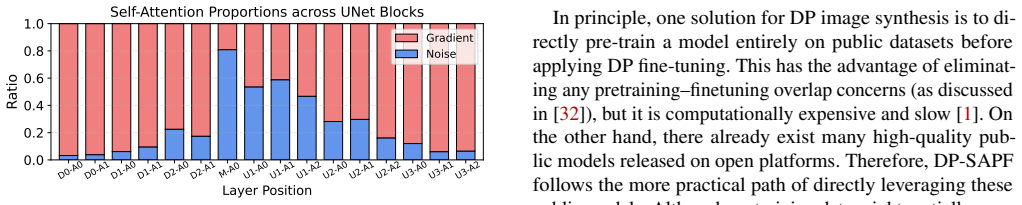
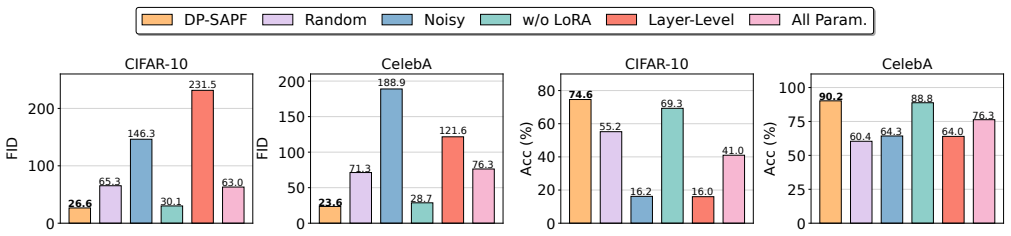
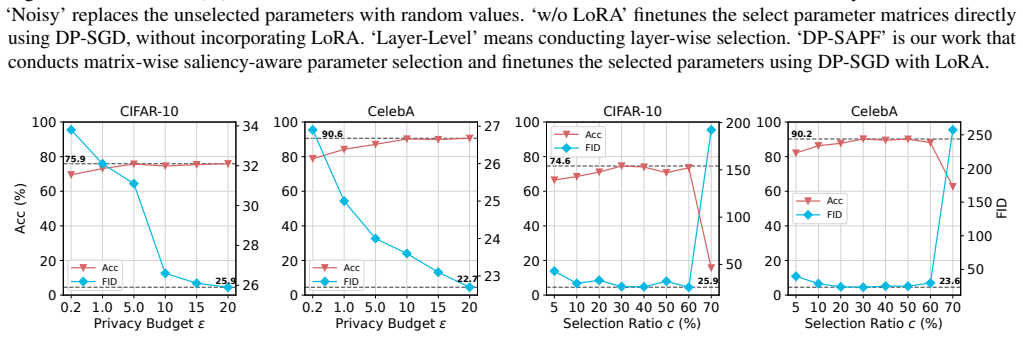
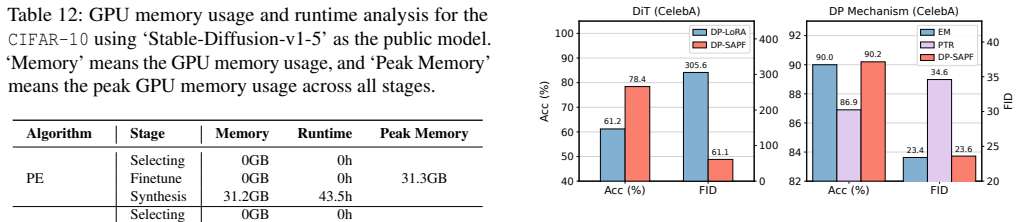
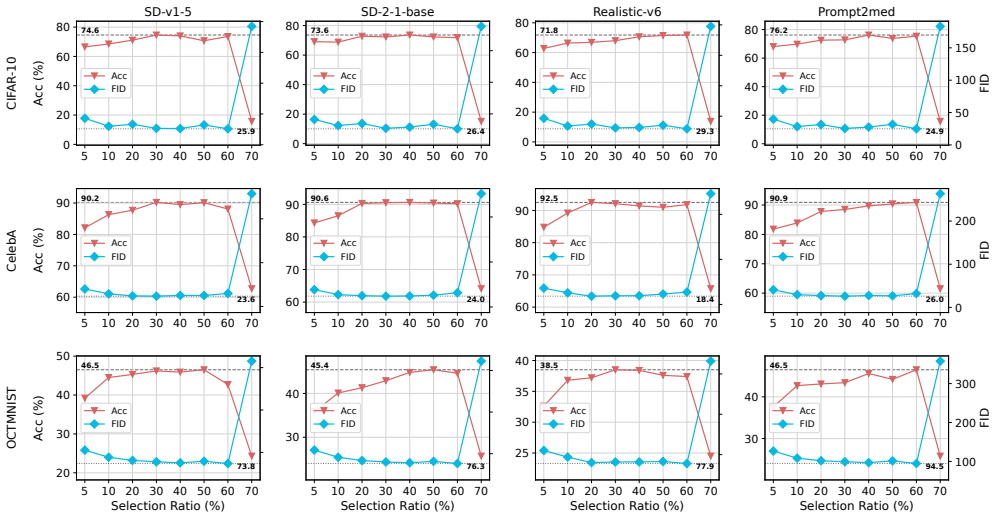
DP-SAPF identifies the most salient parameters by feeding sensitive images into the public model, adding noise to the gradients, and selecting those with high gradient magnitudes for LoRA-based DP fine-tuning, yielding better synthetic images than exhaustive LoRA coverage across attention layers.
What carries the argument
Saliency-aware selection that restricts LoRA targets to parameters showing the largest magnitudes in noisy gradients computed on sensitive images.
If this is right
- Synthetic images achieve higher utility and fidelity than those from full attention-layer LoRA under DP.
- Fewer parameters need training, which lowers the computational resources required.
- Noise accumulation during private training is reduced by avoiding low-saliency parameters.
- The approach applies to existing public models without changing the underlying DP-SGD procedure.
Where Pith is reading between the lines
- The same gradient-magnitude filter might help other DP adaptation methods beyond images if the saliency pattern holds across domains.
- Reusing the noisy gradients already computed for selection could avoid extra privacy budget cost.
- Testing whether magnitude is the optimal saliency statistic or if variance or other measures perform better would be a direct next measurement.
Load-bearing premise
Parameters with the largest noisy gradient magnitudes are the ones most critical to train for good performance in differentially private learning.
What would settle it
An experiment in which LoRA applied to a random subset of parameters of the same size produces synthetic images of equal or higher quality would show the saliency selection is not required.
Figures
read the original abstract
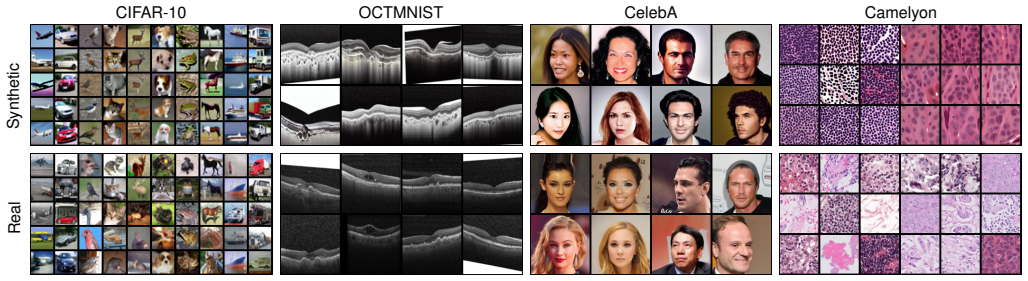
Differentially private (DP) image synthesis generates images that preserve the statistical characteristics of a sensitive dataset, enabling sensitive data analysis and usage while providing rigorous guarantees of privacy leakage. Existing methods fine-tune public models using DP Stochastic Gradient Descent (DP-SGD) on sensitive images to generate synthetic images. But full fine-tuning public models on sensitive images is computationally expensive, because current public models typically contain a large number of parameters. Recent work proposes heuristically using Low-Rank Adaptation (LoRA) on all attention-layer parameters of public models to reduce the number of trainable parameters. However, we argue that exhaustive LoRA coverage across all attention-layer parameters is suboptimal in a DP setting, as it leads to noise accumulation and collapse during private training. To address this issue, we propose DP-SAPF, which uses a saliency-aware strategy to identify specific target parameters for LoRA training under DP. DP-SAPF is inspired by the fact that larger gradients signify higher saliency, indicating that these parameters are most critical for the DP learning. Specifically, we feed the sensitive images into public models, compute gradients, and add noise to the gradients to satisfy DP. Then, DP-SAPF identifies the most salient parameters, those exhibiting high gradient magnitudes on sensitive images, for DP fine-tuning. Experiments on four sensitive image datasets show that DP-SAPF improves the utility and fidelity of synthetic images while requiring fewer computational resources than fine-tuning methods without parameter selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DP-SAPF, a method for differentially private image synthesis that selects a subset of parameters for LoRA fine-tuning based on the magnitudes of noisy gradients computed on sensitive images. It claims that exhaustive LoRA on all attention-layer parameters causes excessive noise accumulation under DP-SGD, whereas saliency-aware selection of high-magnitude parameters yields synthetic images with higher utility and fidelity on four datasets while using fewer computational resources.
Significance. If the empirical claims hold after proper validation, the work could meaningfully advance efficient DP fine-tuning of large public models by reducing the trainable parameter count in a principled way. The core idea of using DP-compliant noisy gradients for parameter saliency ranking is a plausible extension of existing LoRA and DP-SGD techniques, but its practical value hinges on whether the selection step remains stable when noise variance is large relative to gradient variation.
major comments (3)
- [Abstract] Abstract: the central empirical claim that 'DP-SAPF improves the utility and fidelity of synthetic images' is stated without any numerical results, baseline comparisons (e.g., full DP-SGD or exhaustive attention-layer LoRA), error bars, or dataset-specific metrics, rendering the improvement impossible to assess from the provided text.
- [Abstract] Abstract (method paragraph): the procedure 'compute gradients, and add noise to the gradients to satisfy DP. Then, DP-SAPF identifies the most salient parameters, those exhibiting high gradient magnitudes' supplies neither the exact selection rule (threshold or top-k value), the privacy budget used for the selection noise, nor the ordering of noise addition versus magnitude ranking, so the reproducibility of the saliency step and the validity of the 'larger gradients signify higher saliency' assumption cannot be evaluated.
- [Abstract] Abstract and introduction: the assertion that exhaustive LoRA 'leads to noise accumulation and collapse during private training' is presented as motivation but is unsupported by any quantitative analysis, reference to prior DP-SGD collapse results, or ablation isolating the effect of the saliency mask from the mere use of a sparse LoRA adapter.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major comment below with clarifications from the full manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that 'DP-SAPF improves the utility and fidelity of synthetic images' is stated without any numerical results, baseline comparisons (e.g., full DP-SGD or exhaustive attention-layer LoRA), error bars, or dataset-specific metrics, rendering the improvement impossible to assess from the provided text.
Authors: The abstract is written at a high level per typical conventions, while the full manuscript (Section 4) reports concrete metrics including FID, precision/recall, and downstream utility scores with error bars, comparing against full DP-SGD and exhaustive LoRA baselines on all four datasets. To make the abstract more informative, we will add one or two key quantitative highlights (e.g., average FID reduction) within length constraints. revision: yes
-
Referee: [Abstract] Abstract (method paragraph): the procedure 'compute gradients, and add noise to the gradients to satisfy DP. Then, DP-SAPF identifies the most salient parameters, those exhibiting high gradient magnitudes' supplies neither the exact selection rule (threshold or top-k value), the privacy budget used for the selection noise, nor the ordering of noise addition versus magnitude ranking, so the reproducibility of the saliency step and the validity of the 'larger gradients signify higher saliency' assumption cannot be evaluated.
Authors: The abstract summarizes the approach; the complete method (Section 3.2) specifies top-k selection (k set to 20% of attention parameters) performed after per-sample gradient clipping and noise addition, with a dedicated privacy budget slice for the saliency computation to ensure end-to-end DP. Noise precedes ranking by design. We will revise the abstract to state the top-k rule and the noise-before-ranking order for immediate clarity. revision: yes
-
Referee: [Abstract] Abstract and introduction: the assertion that exhaustive LoRA 'leads to noise accumulation and collapse during private training' is presented as motivation but is unsupported by any quantitative analysis, reference to prior DP-SGD collapse results, or ablation isolating the effect of the saliency mask from the mere use of a sparse LoRA adapter.
Authors: The claim is grounded in the scaling of DP-SGD noise variance with parameter count and our preliminary runs showing training instability under exhaustive LoRA. We will add citations to established DP-SGD analyses on high-dimensional noise effects and insert a targeted ablation (exhaustive vs. saliency-selected LoRA) in the experiments to quantify the difference and isolate the mask contribution. revision: yes
Circularity Check
No significant circularity; method is self-contained heuristic with independent empirical claims
full rationale
The paper describes a heuristic for selecting LoRA parameters based on noisy gradient magnitudes computed on sensitive images, motivated by the observation that larger gradients indicate higher saliency. No equations, fitted parameters, or derivations are presented that reduce the claimed utility improvements to a definition or self-citation. The abstract and method description contain no load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work. Experimental results on four datasets are reported as independent validation rather than a closed loop. This is the common case of an empirical method paper whose central claims do not reduce by construction to their inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dpimagebench: A unified benchmark for differentially private image synthesis,
C. Gong, K. Li, Z. Lin, and T. Wang, “Dpimagebench: A unified benchmark for differentially private image synthesis,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, CCS 2025, pp. 4139–4153, ACM, 2025
2025
-
[2]
Differentially pri- vate fine-tuning of diffusion models,
Y .-L. Tsai, Y . Li, C.-M. Yu,et al., “Differentially pri- vate fine-tuning of diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4561–4571, 2025
2025
-
[3]
Differen- tially private latent diffusion models,
M. F. Liu, S. Lyu, M. Vinaroz, and M. Park, “Differen- tially private latent diffusion models,”Transactions on Machine Learning Research, 2024
2024
-
[4]
Differen- tially private synthetic data via apis 3: Using simu- lators instead of foundation model,
Z. Lin, T. Baltrusaitis, and S. Yekhanin, “Differen- tially private synthetic data via apis 3: Using simu- lators instead of foundation model,”arXiv preprint arXiv:2502.05505, 2025
-
[5]
Differentially private synthetic data via foundation model APIs 1: Images,
Z. Lin, S. Gopi, J. Kulkarni,et al., “Differentially private synthetic data via foundation model APIs 1: Images,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
Privorl: Differen- tially private synthetic dataset for offline reinforcement learning,
C. Gong, Z. Liu, K. Li, and T. Wang, “Privorl: Differen- tially private synthetic dataset for offline reinforcement learning,”arXiv preprint arXiv:2512.07342, 2025
-
[7]
Differen- tially private diffusion models generate useful synthetic images,
S. Ghalebikesabi, L. Berrada, S. Gowal,et al., “Differen- tially private diffusion models generate useful synthetic images,”CoRR, vol. abs/2302.13861, 2023
-
[8]
PrivImage: Differentially private synthetic image generation using diffusion mod- els with Semantic-Aware pretraining,
K. Li, C. Gong, Z. Li,et al., “PrivImage: Differentially private synthetic image generation using diffusion mod- els with Semantic-Aware pretraining,” in33rd USENIX Security Symposium (USENIX Security 24), 2024
2024
-
[9]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and et al., “Deep learning face attributes in the wild,” in2015 IEEE International Con- ference on Computer Vision, pp. 3730–3738, 2015
2015
-
[10]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz,et al., “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2022
2022
-
[11]
Privcode: When code generation meets differential privacy,
Z. Liu, C. Gong, T. Y . Zhuo,et al., “Privcode: When code generation meets differential privacy,”arXiv preprint arXiv:2512.05459, 2025
-
[12]
Differentially private synthetic data via foundation model apis 2: Text,
C. Xie, Z. Lin, A. Backurs,et al., “Differentially private synthetic data via foundation model apis 2: Text,” in International Conference on Machine Learning, 2024. 15
2024
-
[13]
Syn- thesize privacy-preserving high-resolution images via private textual intermediaries,
H. Wang, Z. Lin, D. Yu, and H. Zhang, “Syn- thesize privacy-preserving high-resolution images via private textual intermediaries,”arXiv preprint arXiv:2506.07555, 2025
-
[14]
Struct-bench: A benchmark for differentially private structured text generation,
S. Wang, V . Raunak, A. Backurs,et al., “Struct-bench: A benchmark for differentially private structured text generation,”arXiv preprint arXiv:2509.10696, 2025
-
[15]
Pe-sgd: Differentially pri- vate deep learning via evolution of gradient subspace for text,
T. Zou, Z. Lin, S. Gopi, Y . Liu, Y .-Q. Zhang, R. Sim, X. Deng, and S. Yekhanin, “Pe-sgd: Differentially pri- vate deep learning via evolution of gradient subspace for text,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis,et al., “Lora: Low-rank adaptation of large language models,” inThe Tenth In- ternational Conference on Learning Representations, ICLR, 2022
2022
-
[17]
Large language models can be strong differentially private learners,
X. Li, F. Tramèr, P. Liang, and T. Hashimoto, “Large language models can be strong differentially private learners,” inInternational Conference on Learning Rep- resentations, ICLR 2022
2022
-
[18]
Multi-concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang,et al., “Multi-concept customization of text-to-image diffusion,” inIEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023
2023
-
[19]
Picking winning tickets before training by preserving gradient flow,
C. Wang, G. Zhang, and R. B. Grosse, “Picking winning tickets before training by preserving gradient flow,” in 8th International Conference on Learning Representa- tions, ICLR 2020, 2020
2020
-
[20]
Theoretical insights into fine-tuning attention mechanism: Generalization and optimization,
X. Yao, H. Qian, X. Hu,et al., “Theoretical insights into fine-tuning attention mechanism: Generalization and optimization,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2025
2025
-
[21]
Cal- ibrating noise to sensitivity in private data analysis,
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Cal- ibrating noise to sensitivity in private data analysis,” in Theory of Cryptography: Third Theory of Cryptography Conference,, pp. 265–284, 2006
2006
-
[22]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. J. Goodfellow, and et al., “Deep learning with differential privacy,” inProceedings of the ACM SIGSAC Conference on Computer and Communi- cations Security, pp. 308–318, 2016
2016
-
[23]
I. Mironov, K. Talwar, and L. Zhang, “Rényi differential privacy of the sampled gaussian mechanism,”CoRR, vol. abs/1908.10530, 2019
-
[24]
From easy to hard: Building a shortcut for differentially private image synthesis,
K. Li, C. Gong, X. Li, Y . Zhao, X. Hou, and T. Wang, “From easy to hard: Building a shortcut for differentially private image synthesis,” in2025 IEEE Symposium on Security and Privacy (SP), pp. 3656–3674, 2025
2025
-
[25]
Denoising diffusion prob- abilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion prob- abilistic models,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[26]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Information Processing Systems, 2017
2017
-
[27]
Real- fake: Effective training data synthesis through distribu- tion matching,
J. Yuan, J. Zhang, S. Sun, P. Torr, and B. Zhao, “Real- fake: Effective training data synthesis through distribu- tion matching,” inThe Twelfth International Conference on Learning Representations, ICLR 2024
2024
-
[28]
Membership inference attacks against diffusion models,
T. Matsumoto, T. Miura, and N. Yanai, “Membership inference attacks against diffusion models,” inIEEE Se- curity and Privacy Workshops (SPW), pp. 77–83, 2023
2023
-
[29]
Functional renyi differen- tial privacy for generative modeling,
D. Jiang, S. Sun, and Y . Yu, “Functional renyi differen- tial privacy for generative modeling,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[30]
Using gans for sharing networked time series data: Challenges, initial promise, and open questions,
Z. Lin, A. Jain, C. Wang, G. Fanti, and V . Sekar, “Using gans for sharing networked time series data: Challenges, initial promise, and open questions,” inProceedings of the ACM internet measurement conference, 2020
2020
-
[31]
Practical gan-based synthetic ip header trace generation using netshare,
Y . Yin, Z. Lin, M. Jin, G. Fanti, and V . Sekar, “Practical gan-based synthetic ip header trace generation using netshare,” inProceedings of the ACM SIGCOMM 2022 Conference, pp. 458–472, 2022
2022
-
[32]
Position: Con- siderations for differentially private learning with large- scale public pretraining,
F. Tramèr, G. Kamath, and N. Carlini, “Position: Con- siderations for differentially private learning with large- scale public pretraining,” inForty-first International Conference on Machine Learning, 2024
2024
-
[33]
Practical differen- tially private hyperparameter tuning with subsampling,
A. Koskela and T. D. Kulkarni, “Practical differen- tially private hyperparameter tuning with subsampling,” Advances in Neural Information Processing Systems, vol. 36, pp. 28201–28225, 2023
2023
-
[34]
Large lan- guage models can be strong differentially private learn- ers,
X. Li, F. Tramèr, P. Liang, and T. Hashimoto, “Large lan- guage models can be strong differentially private learn- ers,” inThe Tenth International Conference on Learning Representations, ICLR, 2022
2022
-
[35]
Lorada: Low-rank direct attention adaptation for effi- cient llm fine-tuning,
Z. Li, Q. Hu, Y . Chen, P. Wang, Y . Zhang, and J. Cheng, “Lorada: Low-rank direct attention adaptation for effi- cient llm fine-tuning,” inFindings of the Association for Computational Linguistics: EMNLP 2025
2025
-
[36]
I. Mironov, “Renyi differential privacy,”CoRR, vol. abs/1702.07476, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” tech. rep., University of Toronto, 2009. 16
2009
-
[38]
Medmnist v2-a large- scale lightweight benchmark for 2d and 3d biomedical image classification,
J. Yang, R. Shi, D. Wei,et al., “Medmnist v2-a large- scale lightweight benchmark for 2d and 3d biomedical image classification,”Scientific Data, p. 41, 2023
2023
-
[39]
From detection of individual metastases to classification of lymph node status at the patient level: The CAME- LYON17 challenge,
P. Bándi, O. Geessink, Q. Manson, and et al., “From detection of individual metastases to classification of lymph node status at the patient level: The CAME- LYON17 challenge,”IEEE Trans. Medical Imaging, vol. 38, no. 2, pp. 550–560, 2019
2019
-
[40]
Differentially private diffusion models,
T. Dockhorn, T. Cao, A. Vahdat,et al., “Differentially private diffusion models,”Transactions on Machine Learning Research, 2023
2023
-
[41]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF interna- tional conference on computer vision, 2023
2023
-
[42]
The algorithmic foundations of differential privacy,
C. Dwork, A. Roth,et al., “The algorithmic foundations of differential privacy,”Foundations and Trends® in Theoretical Computer Science, pp. 211–407, 2014
2014
-
[43]
Differential privacy and robust statistics,
C. Dwork and J. Lei, “Differential privacy and robust statistics,” inProceedings of the forty-first annual ACM symposium on Theory of computing, pp. 371–380, 2009
2009
-
[44]
To- wards better understanding of gradient-based attribution methods for deep neural networks,
M. Ancona, E. Ceolini, C. Öztireli, and M. Gross, “To- wards better understanding of gradient-based attribution methods for deep neural networks,” in6th International Conference on Learning Representations, ICLR 2018
2018
-
[45]
Snip: single-shot network pruning based on connection sensitivity,
N. Lee, T. Ajanthan, and P. H. S. Torr, “Snip: single-shot network pruning based on connection sensitivity,” in7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
2019
-
[46]
Picking winning tickets before training by preserving gradient flow,
C. Wang, G. Zhang, and R. B. Grosse, “Picking winning tickets before training by preserving gradient flow,” in 8th International Conference on Learning Representa- tions, ICLR 2020
2020
-
[47]
DP-MERF: differentially private mean embeddings with random fea- tures for practical privacy-preserving data generation,
F. Harder, K. Adamczewski, and M. Park, “DP-MERF: differentially private mean embeddings with random fea- tures for practical privacy-preserving data generation,” inAISTATS, pp. 1819–1827, 2021
2021
-
[48]
PEARL: data synthesis via private embeddings and adversarial recon- struction learning,
S. P. Liew, T. Takahashi, and M. Ueno, “PEARL: data synthesis via private embeddings and adversarial recon- struction learning,” inThe Tenth International Confer- ence on Learning Representations, 2022
2022
-
[49]
C. Gong, K. Li, Z. Lin, and T. Wang, “From easy to hard++: Promoting differentially private image syn- thesis through spatial-frequency curriculum,”arXiv preprint arXiv:2601.06368, 2026
-
[50]
Differentially pri- vate neural tangent kernels for privacy-preserving data generation,
Y . Yang, K. Adamczewski, and et al, “Differentially pri- vate neural tangent kernels for privacy-preserving data generation,”CoRR, vol. abs/2303.01687, 2023
-
[51]
Pre- trained perceptual features improve differentially private image generation,
F. Harder, M. Jalali, D. J. Sutherland, and et al., “Pre- trained perceptual features improve differentially private image generation,”Trans. Mach. Learn. Res., 2023
2023
-
[52]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol,et al., “Hierarchi- cal text-conditional image generation with clip latents,” arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Google fonts,
Google, “Google fonts,”https://github.com/google/fonts, 2022
2022
-
[54]
Selective pre-training for private fine-tuning,
D. Yu, S. Gopi, J. Kulkarni,et al., “Selective pre-training for private fine-tuning,”Transactions on Machine Learn- ing Research
-
[55]
Gradient-based pa- rameter selection for efficient fine-tuning,
Z. Zhang, Q. Zhang, Z. Gao,et al., “Gradient-based pa- rameter selection for efficient fine-tuning,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 28566–28577, 2024
2024
-
[56]
Sensitivity-aware visual parameter-efficient fine-tuning,
H. He, J. Cai, J. Zhang, D. Tao, and B. Zhuang, “Sensitivity-aware visual parameter-efficient fine-tuning,” inProceedings of the IEEE/CVF international confer- ence on computer vision, pp. 11825–11835, 2023
2023
-
[57]
Barocas, M
S. Barocas, M. Hardt, and A. Narayanan,Fairness and machine learning: Limitations and opportunities. MIT press, 2023
2023
-
[58]
{ModelGuard}:{Information- Theoretic} defense against model extraction attacks,
M. Tang, A. Dai, L. DiValentin, A. Ding, A. Hass, N. Z. Gong, Y . Chen,et al., “ {ModelGuard}:{Information- Theoretic} defense against model extraction attacks,” in 33rd USENIX Security Symposium, 2024
2024
-
[59]
Progressive skeletonization: Trimming more fat from a network at initialization,
P. de Jorge, A. Sanyal, H. S. Behl,et al., “Progressive skeletonization: Trimming more fat from a network at initialization,” in9th International Conference on Learn- ing Representations, ICLR 2021
2021
-
[60]
Pruning neural networks without any data by iteratively conserving synaptic flow,
H. Tanaka, D. Kunin, D. L. K. Yamins, and S. Ganguli, “Pruning neural networks without any data by iteratively conserving synaptic flow,” inAdvances in Neural Infor- mation Processing Systems NeurIPS 2020. A Details of Rényi DP in DP-SAPF We use the Rényi DP (RDP) paradigm [23] to account for the cumulative privacy costs, for fairness comparison with prev...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.