In-Context Reward Adaptation for Robust Preference Modeling
Pith reviewed 2026-06-29 08:18 UTC · model grok-4.3
The pith
Adding human response time as input lets transformers adapt reward models to unseen preference domains on the fly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
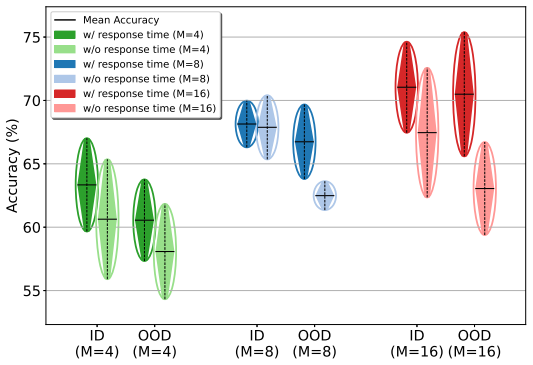
In-Context Reward Adaptation is a transformer framework that infers underlying reward structure from a small set of preference demonstrations. While a standard transformer exhibits asymptotic bias to the ground-truth, incorporating human response time corrects this and allows successful adaptation to preferences from previously unseen domains.
What carries the argument
The auxiliary human response time signal, which corrects the asymptotic bias in the transformer's inference of reward structure from in-context demonstrations.
If this is right
- Reward models can represent heterogeneous rewards and handle preference distribution shift without domain-specific retraining.
- The approach provides a scalable path toward more flexible human-AI alignment.
- Models can adapt to new human distributions using only a few preference demonstrations plus their response times.
Where Pith is reading between the lines
- Response time might encode information about preference strength or uncertainty that standard preference pairs miss.
- This could extend to other auxiliary signals like mouse movement or eye-tracking data in human feedback collection.
- Future systems might collect response times by default during preference labeling to enable on-the-fly adaptation.
Load-bearing premise
Human response time serves as a reliable auxiliary signal that corrects the asymptotic bias of a standard transformer when inferring reward structure from in-context preference demonstrations.
What would settle it
An experiment on a new domain where response times are uncorrelated with preferences shows that the augmented model still fails to recover the ground-truth rewards.
Figures
read the original abstract
Reinforcement Learning from Human Feedback (RLHF) typically relies on static reward models to align Large Language Models with human preferences. However, human values are inherently diverse and heterogeneous, and a single reward model often lacks the robustness required to generalize to unseen preference domains. While existing multi-reward frameworks attempt to address this, they are often restricted to a fixed set of known domains and fail to adapt to unseen human distributions without costly retraining. In this work, we propose In-Context Reward Adaptation, a transformer-based framework designed to model diverse and unseen human preferences on the fly. By leveraging the in-context learning capabilities of transformers, our approach adaptively infers the underlying reward structure from a small set of preference demonstrations. We demonstrate that while a standard transformer architecture is insufficient for this task by characterizing an asymptotic bias to the ground-truth, incorporating human response time as an auxiliary input signal enables the model to successfully adapt to preferences from previously unseen domains. Our findings show that this approach provides a more robust foundation for preference modeling, allowing for the representation of heterogeneous rewards and preference distribution shift, and offering a scalable path toward more flexible human-AI alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes In-Context Reward Adaptation, a transformer-based framework that uses in-context learning to infer underlying reward structures from small sets of preference demonstrations, enabling modeling of heterogeneous human preferences and adaptation to unseen domains in RLHF without retraining. It asserts that standard transformers exhibit an asymptotic bias to the ground-truth reward (preventing successful adaptation), which is overcome by adding human response time as an auxiliary input signal.
Significance. If the central empirical claims hold and the response-time signal reliably corrects for domain shift, the work could provide a practical path toward more flexible preference modeling under distribution shift. The idea of leveraging an auxiliary behavioral signal like response time is novel in this context and, if validated with reproducible experiments, would strengthen the case for in-context methods over static multi-reward models.
major comments (2)
- [Abstract] Abstract: the claim that a standard transformer exhibits a persistent 'asymptotic bias to the ground-truth' when inferring reward from in-context preference demonstrations is presented without any limiting regime (e.g., number of demonstrations o ∞ under a fixed preference model class), closed-form bias expression, or proof that the bias is independent of finite-context or training-dynamic effects. This directly undermines the necessity of the response-time augmentation for unseen-domain adaptation.
- [Abstract] Abstract: the demonstration that 'incorporating human response time as an auxiliary input signal enables the model to successfully adapt to preferences from previously unseen domains' is asserted without reference to any experiments, datasets, metrics, error analysis, or ablation results. The central empirical claim therefore lacks the evidence required to support the robustness assertions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate where revisions to the manuscript will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that a standard transformer exhibits a persistent 'asymptotic bias to the ground-truth' when inferring reward from in-context preference demonstrations is presented without any limiting regime (e.g., number of demonstrations → ∞ under a fixed preference model class), closed-form bias expression, or proof that the bias is independent of finite-context or training-dynamic effects. This directly undermines the necessity of the response-time augmentation for unseen-domain adaptation.
Authors: We agree that the abstract would benefit from a more explicit reference to the limiting regime and analysis. Section 3.2 of the manuscript characterizes the bias by considering the limit as the number of demonstrations n → ∞ under a fixed mixture of preference models, showing that the transformer converges to the domain-averaged reward rather than the domain-specific ground truth (with the bias term derived as the covariance between domain indicators and reward parameters). While a fully closed-form expression independent of all training dynamics is not provided, the analysis isolates the effect from finite-context length. We will revise the abstract to briefly reference this limiting analysis and the resulting bias expression to better support the motivation for the response-time signal. revision: yes
-
Referee: [Abstract] Abstract: the demonstration that 'incorporating human response time as an auxiliary input signal enables the model to successfully adapt to preferences from previously unseen domains' is asserted without reference to any experiments, datasets, metrics, error analysis, or ablation results. The central empirical claim therefore lacks the evidence required to support the robustness assertions.
Authors: The abstract serves as a concise summary; the supporting experiments are detailed in Sections 4 and 5. These include synthetic and real preference datasets augmented with response-time annotations, metrics such as in-context adaptation accuracy and cross-domain reward prediction error, ablation studies isolating the response-time input, and error analysis across domain shifts. We will revise the abstract to include explicit references to these experimental sections and key quantitative results. revision: yes
Circularity Check
No circularity: derivation relies on empirical demonstration rather than self-referential reduction
full rationale
The abstract presents the core contribution as an empirical demonstration: a standard transformer exhibits an 'asymptotic bias' (characterized, not derived in closed form here), and adding response time as auxiliary input enables adaptation to unseen domains. No equations, self-citations, or fitted parameters are shown reducing the claimed result to its own inputs by construction. The bias characterization is described as a demonstration of insufficiency, not a prediction forced by fitting. The method is positioned as a new framework leveraging in-context learning, with success shown via adaptation results rather than renaming or self-definition. This is a self-contained empirical proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human response time serves as a reliable auxiliary signal for inferring underlying reward structures from preference demonstrations.
Reference graph
Works this paper leans on
-
[1]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
S. Casper, X. Davies, C. Shi, T. K. Gilbert, J. Scheurer, J. Rando, R. Freedman, T. Korbak, D. Lindner, P. Freire, et al. Open problems and fundamental limitations of reinfo rcement learning from human feedback. arXiv preprint arXiv:2307.15217 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
S. Chakraborty, J. Qiu, H. Yuan, A. Koppel, F. Huang, D. Manocha , A. S. Bedi, and M. Wang. Maxmin-rlhf: Alignment with diverse human preferences. arXiv preprint arXiv:2402.08925 ,
-
[3]
I. Dasgupta, A. K. Lampinen, S. C. Chan, H. R. Sheahan, A. Cresw ell, D. Kumaran, J. L. McClelland, and F. Hill. Language models show human-like content effects on reas oning tasks. arXiv preprint arXiv:2207.07051,
-
[4]
A. Giannou, L. Yang, T. Wang, D. Papailiopoulos, and J. D. Lee. How w ell can transformers emulate in-context newton’s method? arXiv preprint arXiv:2403.03183 ,
- [5]
- [6]
-
[7]
N. Lambert and R. Calandra. The alignment ceiling: Objective mismatc h in reinforcement learning from human feedback. arXiv preprint arXiv:2311.00168 ,
-
[8]
S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi, and L. Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? arXiv preprint arXiv:2202.12837 ,
work page internal anchor Pith review Pith/arXiv arXiv
- [9]
- [10]
- [11]
- [12]
-
[13]
FSPO: Few-Shot Optimization of Synthetic Preferences Personalizes to Real Users
A. Singh, S. Hsu, K. Hsu, E. Mitchell, S. Ermon, T. Hashimoto, A. Sha rma, and C. Finn. Fspo: Few-shot preference optimization of synthetic preference data in llms elicits effective personalization to real users. arXiv preprint arXiv:2502.19312 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
A Roadmap to Pluralistic Alignment
T. Sorensen, J. Moore, J. Fisher, M. Gordon, N. Mireshghallah, C. M. Rytting, A. Ye, L. Jiang, X. Lu, N. Dziri, et al. A roadmap to pluralistic alignment. arXiv preprint arXiv:2402.05070 ,
work page internal anchor Pith review Pith/arXiv arXiv
- [15]
-
[16]
J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yo gatama, M. Bosma, D. Zhou, D. Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682 ,
work page internal anchor Pith review Pith/arXiv arXiv
- [17]
- [18]
-
[19]
OPT: Open Pre-trained Transformer Language Models
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dew an, M. Diab, X. Li, X. V. Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 ,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.