Colored Noise Diffusion Sampling
Pith reviewed 2026-06-29 07:45 UTC · model grok-4.3
The pith
A dynamic colored noise schedule in SDE sampling exploits spectral bias to steer diffusion outputs toward the data manifold without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reinterpreting SDE inference as targeted frequency-decoupled energy transfer enables CNS to replace uniform white noise with a dynamic colored noise schedule. This schedule allocates injected energy more efficiently to structurally unresolved frequency bands, exploiting the model's inherent spectral bias to steer the generated distribution closer to the true data manifold.
What carries the argument
The dynamic timestep- and frequency-dependent colored noise schedule that replaces uniform white noise injection.
If this is right
- CNS functions as a plug-and-play substitution for ODE and SDE solvers across architectures including SiT, JiT, and FLUX.
- It produces unguided FID reductions on ImageNet-256 such as 8.26 to 6.27 on SiT-XL/2.
- Relative FID gains remain consistent when Classifier-Free Guidance is applied.
- The finite energy budget is used more efficiently by matching the model's spectral bias.
Where Pith is reading between the lines
- The frequency-decoupled view might apply to diffusion models trained on video or audio where similar spectral progressions occur.
- The schedule could be adapted for conditional generation tasks beyond unconditional ImageNet sampling.
- Combining CNS with other inference accelerations might compound quality gains without extra training.
Load-bearing premise
Reinterpreting SDE inference as targeted frequency-decoupled energy transfer allows a dynamic colored noise schedule to steer samples toward the data manifold without model-specific tuning or retraining.
What would settle it
Applying CNS to the tested models or a new architecture and observing FID scores equal to or higher than standard white-noise sampling on ImageNet-256 would falsify the claim of systematic improvement.
Figures





read the original abstract
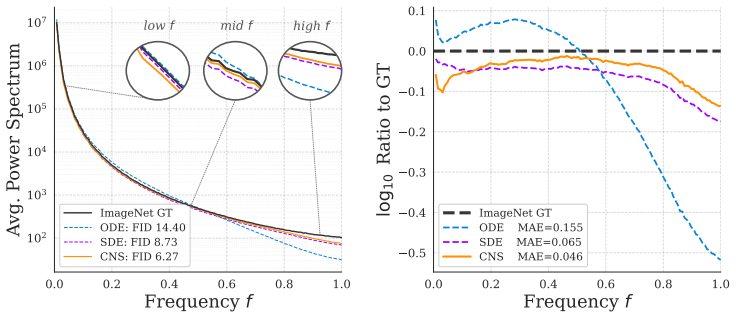
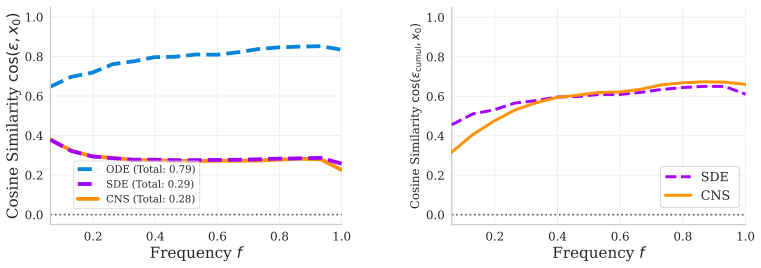
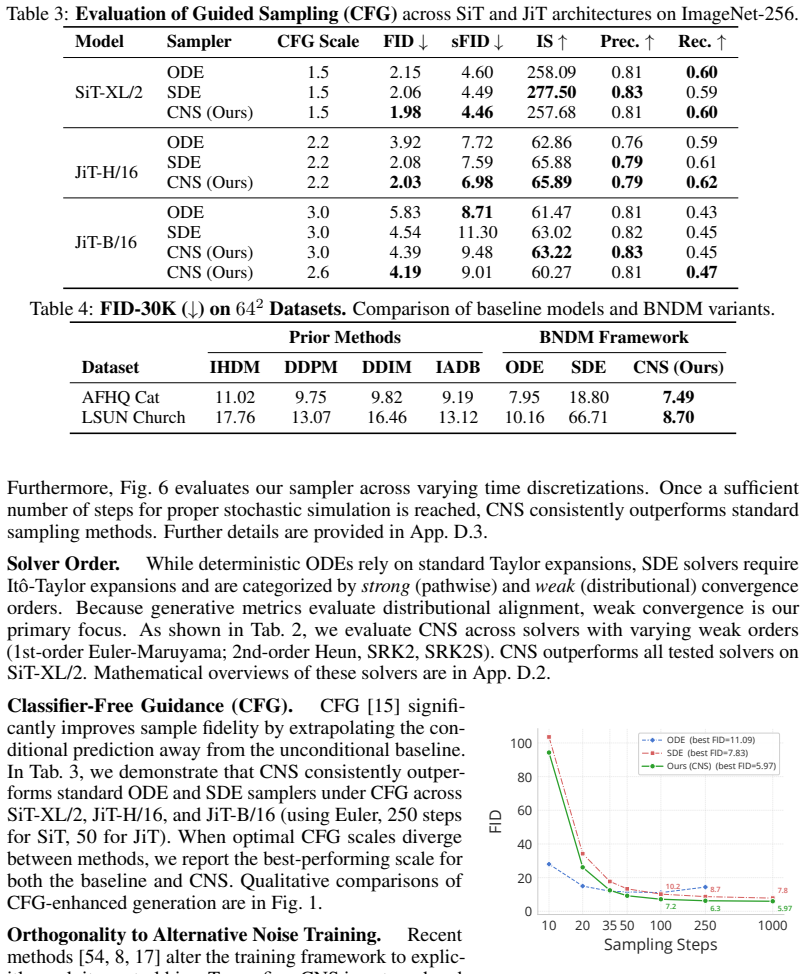
Diffusion models achieve state-of-the-art image synthesis, with their generative trajectories fundamentally exhibiting a spectral bias, resolving low-frequency global structures early and high-frequency fine details later. Conventional stochastic differential equation (SDE) solvers fail to account for this dynamic, naively injecting uniform white noise throughout the entire process and misusing the finite energy budget. In this work, we establish a mathematical framework that reconsiders SDE inference as a targeted, frequency-decoupled energy transfer. Leveraging this framework, we introduce Colored Noise Sampling (CNS), a novel, training-free stochastic solver. Rather than injecting uniform white noise, CNS utilizes a dynamic, timestep- and frequency-dependent schedule that more efficiently allocates injected energy toward structurally unresolved frequency bands. By actively exploiting the model's inherent spectral bias, CNS systematically steers the generated distribution toward the true data manifold. Extensive experiments demonstrate that CNS significantly outperforms standard ODE and SDE baselines as a strictly plug-and-play, inference-time sampler substitution across diverse architectures (SiT, JiT, FLUX). Compared to standard sampling on ImageNet-256, CNS achieves substantial unguided FID reductions, improving from 8.26 to 6.27 on SiT-XL/2, 32.39 to 26.69 on JiT-B/16, and 11.88 to 8.31 on JiT-H/16, while yielding consistent relative FID improvements with Classifier-Free Guidance. Project page is available at https://hadardavidson.github.io/CNS/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Colored Noise Sampling (CNS), a training-free plug-and-play stochastic solver for diffusion models. It reinterprets SDE inference as targeted frequency-decoupled energy transfer to derive a dynamic, timestep- and frequency-dependent colored noise schedule that allocates injected energy to unresolved frequency bands, exploiting the model's inherent spectral bias to steer samples toward the data manifold. Experiments report substantial unguided FID reductions on ImageNet-256 (e.g., 8.26 to 6.27 on SiT-XL/2, 32.39 to 26.69 on JiT-B/16) across SiT, JiT, and FLUX architectures, with consistent gains under classifier-free guidance.
Significance. If the claimed mathematical framework is rigorously derived and the FID gains prove robust and reproducible, CNS could offer a general inference-time improvement to diffusion sampling by better matching noise injection to the progressive resolution of frequencies, without model-specific tuning or retraining.
major comments (1)
- [Abstract / §2] Abstract and §2 (Mathematical Framework): the central claim that the dynamic colored noise schedule is derived from a frequency-decoupled energy-transfer reinterpretation of the SDE is unsupported because no equations, derivation steps, or explicit mapping from the re-interpretation to the specific timestep- and frequency-dependent schedule are provided. Without this, it is impossible to verify whether the schedule follows rigorously from the framework or reduces to an empirical choice whose justification rests only on the reported FID numbers.
minor comments (1)
- [Abstract] The abstract states results for unguided and CFG settings but provides no details on the number of sampling steps, exact noise schedule parameterization, or statistical significance of the FID differences.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our work. We address the major comment below and will revise the manuscript accordingly to strengthen the presentation of the mathematical framework.
read point-by-point responses
-
Referee: [Abstract / §2] Abstract and §2 (Mathematical Framework): the central claim that the dynamic colored noise schedule is derived from a frequency-decoupled energy-transfer reinterpretation of the SDE is unsupported because no equations, derivation steps, or explicit mapping from the re-interpretation to the specific timestep- and frequency-dependent schedule are provided. Without this, it is impossible to verify whether the schedule follows rigorously from the framework or reduces to an empirical choice whose justification rests only on the reported FID numbers.
Authors: We agree that the derivation in §2 would benefit from greater explicitness to allow independent verification. The current manuscript presents the frequency-decoupled energy-transfer reinterpretation of the SDE and states that the colored noise schedule follows from it, but the intermediate algebraic steps mapping the reinterpretation (energy allocation to unresolved bands under spectral bias) to the precise functional form of the timestep- and frequency-dependent schedule are not written out in full. In the revision we will expand §2 with the complete derivation, including (i) the re-expressed SDE in frequency space, (ii) the energy-transfer budget constraint, (iii) the closed-form schedule parameters, and (iv) the explicit mapping from those parameters to the CNS noise injection rule. This will make the logical chain fully rigorous and reproducible from the framework alone. revision: yes
Circularity Check
No circularity; claimed framework-to-schedule derivation not inspectable and no self-referential reductions present
full rationale
The provided text (abstract plus context) asserts that a mathematical framework reinterpreting SDE inference as frequency-decoupled energy transfer yields the CNS schedule, but supplies neither equations nor the explicit mapping from framework to schedule. No self-citations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear. Without any load-bearing step that reduces by construction to its own inputs, the derivation cannot be shown circular. Empirical FID gains are presented separately and do not substitute for the missing derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Adamkiewicz, B. Moser, S. Frolov, T. C. Nauen, F. Raue, and A. Dengel. When pretty isn’t useful: Investigating why modern text-to-image models fail as reliable training data generators. arXiv preprint arXiv:2602.19946, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [2]
-
[3]
M. S. Albergo and E. Vanden-Eijnden. Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
B. D. Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
1982
- [5]
-
[6]
Diffusion Posterior Sampling for General Noisy Inverse Problems
H. Chung, J. Kim, M. T. Mccann, M. L. Klasky, and J. C. Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
B. Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
2011
-
[8]
F. Falck, T. Pandeva, K. Zahirnia, R. Lawrence, R. Turner, E. Meeds, J. Zazo, and S. Karmalkar. A fourier space perspective on diffusion models.arXiv preprint arXiv:2505.11278, 2025
-
[9]
Ghosh, H
D. Ghosh, H. Hajishirzi, and L. Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[10]
Hairer, S
E. Hairer, S. Nørsett, and G. Wanner.Solving Ordinary Differential Equations I: Nonstiff Problems. Springer Series in Computational Mathematics. Springer Berlin Heidelberg, 2008. ISBN 9783540566700. URLhttps://books.google.co.il/books?id=F93u7VcSRyYC
2008
-
[11]
Heitz, L
E. Heitz, L. Belcour, and T. Chambon. Iterative α-(de) blending: A minimalist deterministic diffusion model. InACM SIGGRAPH 2023 Conference Proceedings, pages 1–8, 2023
2023
-
[12]
Hessel, A
J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y . Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[13]
Heun et al
K. Heun et al. Neue methoden zur approximativen integration der differentialgleichungen einer unabhängigen veränderlichen.Z. Math. Phys, 45(23-38):7, 1900
1900
-
[14]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[15]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[17]
Huang, C
X. Huang, C. Salaun, C. Vasconcelos, C. Theobalt, C. Oztireli, and G. Singh. Blue noise for diffusion models. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024
2024
-
[18]
Hyvärinen, J
A. Hyvärinen, J. Hurri, and P. Hoyer.Natural Image Statistics: A Probabilistic Approach to Early Computational Vision.Computational Imaging and Vision. Springer London, 2009. ISBN 9781848824911. URLhttps://books.google.co.il/books?id=pq_Fr1eYr7cC
2009
-
[19]
N. Issachar, M. Salama, R. Fattal, and S. Benaim. Designing a conditional prior distribution for flow-based generative models.arXiv preprint arXiv:2502.09611, 2025. 11
-
[20]
N. Issachar, G. Yariv, S. Benaim, Y . Adi, D. Lischinski, and R. Fattal. Dype: Dynamic position extrapolation for ultra high resolution diffusion.arXiv preprint arXiv:2510.20766, 2025
-
[21]
Kamien and N
M. Kamien and N. Schwartz.Dynamic Optimization, Second Edition: The Calculus of Variations and Optimal Control in Economics and Management. Dover Books on Mathematics. Dover Publications, 2013. ISBN 9780486310282. URL https://books.google.co.il/books? id=liLCAgAAQBAJ
2013
-
[22]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35:26565–26577, 2022
2022
-
[23]
Kloeden and E
P. Kloeden and E. Platen.Numerical Solution of Stochastic Differential Equations. Stochastic Modelling and Applied Probability. Springer Berlin Heidelberg, 2011. ISBN 9783540540625. URLhttps://books.google.co.il/books?id=BCvtssom1CMC
2011
-
[24]
Kynkäänniemi, T
T. Kynkäänniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila. Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32, 2019
2019
-
[25]
B. F. Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[26]
B. F. Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[27]
A. B. L. Larsen, S. K. Sønderby, H. Larochelle, and O. Winther. Autoencoding beyond pixels using a learned similarity metric. In M. F. Balcan and K. Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1558–1566, New York, New York, USA, 20–22 Jun 2016. PML...
2016
-
[28]
H. Lee, H. Lee, S. Gye, and J. Kim. Beta sampling is all you need: Efficient image generation strategy for diffusion models using stepwise spectral analysis. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 4215–4224. IEEE, 2025
2025
-
[29]
Back to Basics: Let Denoising Generative Models Denoise
T. Li and K. He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Liberzon.Calculus of Variations and Optimal Control Theory: A Concise Introduction
D. Liberzon.Calculus of Variations and Optimal Control Theory: A Concise Introduction. Princeton University Press, 2011. ISBN 9781400842643. URL https://books.google.co. il/books?id=xQHEjXy8rlUC
2011
-
[31]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
E. Liu, X. Ning, H. Yang, and Y . Wang. A unified sampling framework for solver search- ing of diffusion probabilistic models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[35]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024
2024
-
[36]
J. Mao, X. Wang, and K. Aizawa. Guided image synthesis via initial image editing in diffusion model. InProceedings of the 31st ACM International Conference on Multimedia, pages 5321–5329, 2023
2023
-
[37]
Maruyama
G. Maruyama. Continuous markov processes and stochastic equations.Rendiconti del Circolo Matematico di Palermo, 4(1):48–90, 1955. 12
1955
- [38]
- [39]
-
[40]
Øksendal
B. Øksendal. Stochastic differential equations. InStochastic differential equations: an introduc- tion with applications, pages 38–50. Springer, 2003
2003
-
[41]
Oppenheim, R
A. Oppenheim, R. Schafer, and J. Buck.Discrete-time Signal Processing. Prentice Hall International Editions Series. Prentice Hall, 1999. ISBN 9780130834430. URL https: //books.google.co.il/books?id=cR3CQgAACAAJ
1999
-
[42]
Peltier and J
R.-F. Peltier and J. L. Véhel.Multifractional Brownian motion: definition and preliminary results. PhD thesis, INRIA, 1995
1995
-
[43]
Plancherel and M
M. Plancherel and M. Leffler. Contribution à l’étude de la représentation d’une fonction arbitraire par des intégrales définies.Rendiconti del Circolo Matematico di Palermo (1884-1940), 30(1): 289–335, 1910
1940
-
[44]
Y . Qian, Q. Cai, Y . Pan, Y . Li, T. Yao, Q. Sun, and T. Mei. Boosting diffusion models with moving average sampling in frequency domain. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8911–8920, 2024
2024
-
[45]
Rahaman, A
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y . Bengio, and A. Courville. On the spectral bias of neural networks. InInternational conference on machine learning, pages 5301–5310. PMLR, 2019
2019
-
[46]
Ronen, D
B. Ronen, D. Jacobs, Y . Kasten, and S. Kritchman. The convergence rate of neural networks for learned functions of different frequencies.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[47]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015
2015
-
[48]
A. Rößler. Second order runge–kutta methods for itô stochastic differential equations.SIAM Journal on Numerical Analysis, 47(3):1713–1738, 2009
2009
-
[49]
A. Rößler. Runge–kutta methods for the strong approximation of solutions of stochastic differential equations.SIAM Journal on Numerical Analysis, 48(3):922–952, 2010
2010
-
[50]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115(3):211–252, 2015
2015
-
[51]
Saharia, W
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gon- tijo Lopes, B. Karagol Ayan, T. Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35: 36479–36494, 2022
2022
-
[52]
Salimans, I
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
2016
-
[53]
Schuhmann
C. Schuhmann. Improved aesthetic predictor.URL https://github. com/christophschuhmann/improved-aesthetic-predictor, 2022
2022
-
[54]
L. Scimeca, T. Jiralerspong, B. Earnshaw, J. Hartford, and Y . Bengio. Learning what matters: Steering diffusion via spectrally anisotropic forward noise.arXiv preprint arXiv:2510.09660, 2025
-
[55]
C. Si, Z. Huang, Y . Jiang, and Z. Liu. Freeu: Free lunch in diffusion u-net. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4733–4743, 2024. 13
2024
-
[56]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[57]
Song and S
Y . Song and S. Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019
2019
-
[58]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[59]
Ł. Staniszewski, Ł. Kuci ´nski, and K. Deja. There and back again: On the relation between noise and image inversions in diffusion models.arXiv preprint arXiv:2410.23530, 2024
-
[60]
A. van der Schaaf and J. van Hateren. Modelling the power spectra of natural images: Statistics and information.Vision Research, 36(17):2759–2770, 1996. ISSN 0042-6989. doi: https://doi. org/10.1016/0042-6989(96)00002-8. URL https://www.sciencedirect.com/science/ article/pii/0042698996000028
-
[61]
arXiv preprint arXiv:2303.02490 , year=
B. Wang and J. J. Vastola. Diffusion models generate images like painters: an analytical theory of outline first, details later.arXiv preprint arXiv:2303.02490, 2023
- [62]
-
[63]
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[64]
K. Xu, L. Zhang, and J. Shi. Good seed makes a good crop: Discovering secret seeds in text-to-image diffusion models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3024–3034. IEEE, 2025
2025
-
[65]
S. Xue, M. Yi, W. Luo, S. Zhang, J. Sun, Z. Li, and Z.-M. Ma. Sa-solver: Stochastic adams solver for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:77632–77674, 2023
2023
-
[66]
S. Yan, M. Li, B. Xinliang, J. Yang, Y . Zhang, G. Xiong, Y . Lan, T. Zhang, W. Zhai, and Z.-J. Zha. Beyond randomness: Understand the order of the noise in diffusion.arXiv preprint arXiv:2511.07756, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
M. Yu, L. Sun, J. Zeng, X. Chu, and K. Zhan. Elucidating the snr-t bias of diffusion probabilistic models.arXiv preprint arXiv:2604.16044, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [68]
-
[69]
Q. Zhang and Y . Chen. Fast sampling of diffusion models with exponential integrator.arXiv preprint arXiv:2204.13902, 2022
-
[70]
Zheng, C
K. Zheng, C. Lu, J. Chen, and J. Zhu. Dpm-solver-v3: Improved diffusion ode solver with empirical model statistics.Advances in Neural Information Processing Systems, 36:55502– 55542, 2023
2023
-
[71]
Z. Zhou, S. Shao, L. Bai, S. Zhang, Z. Xu, B. Han, and Z. Xie. Golden noise for diffusion models: A learning framework. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17688–17697, 2025
2025
-
[72]
D. Zou, E. Liu, X. Ning, H. Yang, and Y . Wang. Usf++: A unified sampling framework for solver searching of diffusion probabilistic models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 14 A Theoretical Constraints on Stochastic Energy Injection In the main text, we establish that the stochastic noise injected during the generative ...
2025
-
[73]
heat vs. contraction
=x , which cleanly aligns the energy drift expressions. B.1.1 Pathwise Energy Dynamics in Continuous-Time Sampling Let v(xt, t) denote the deterministic drift of the PF-ODE. The ODE trajectory is dxt =v(x t, t)dt . Applying standard differentiation, the expected energy progression is governed entirely by the alignment between the state and the velocity: d...
-
[74]
Because the expected clean signal magnitude is smaller than the current noisy state, the vector difference points inward
The Attenuation Regime ( Rf < N f ):At frequencies where the target data energy is lower than the initial noise (typically high frequencies), the required evolution is attenuation. Because the expected clean signal magnitude is smaller than the current noisy state, the vector difference points inward. Thus, the true score acts to destroy noise: ˆs∗ ∝ −c 1...
-
[75]
The expected clean data vector has a significantly larger magnitude (∥E[ˆx0(f)]∥>∥ˆx t(f)∥)
The Amplification Regime (Rf > N f ):At frequencies where the target structural magnitude is larger than the initial noise (typically low frequencies), the required evolution is amplification. The expected clean data vector has a significantly larger magnitude (∥E[ˆx0(f)]∥>∥ˆx t(f)∥). Thus, the vector difference points outward: ˆs∗ ∝c 2ˆxt. The underestim...
-
[76]
Here, the expected magnitude of the clean data equals the magnitude of the current noisy state
The Crossover Point (Rf =N f ):The regime transition occurs exactly at the frequency where the inherent energy of the initial noise matches the target energy of the real data. Here, the expected magnitude of the clean data equals the magnitude of the current noisy state. The score provides a purely tangential (phase-rotational) pull, exerting zero radial ...
-
[77]
Tangential Dominance of the True Score.By Tweedie’s formula [ 7], the true score in the frequency domain is proportional to the displacement from the current state toward its conditional clean estimate: ˆs∗(f, t)∝E[ˆx 0(f)|x t]−ˆxt(f)(58) 22 We suppress the schedule-dependent prefactor here because only thedirectionof ˆs∗ relative to ˆxt enters the radial...
-
[78]
Transition to Phase-Random Error on Unresolved Details.During the early phases of band formation (γf(t)≪1 ), MSE training induces a temporally coherent radial bias—specifically, a systematic underestimation of the score’s amplitude along the state direction. However, this coherence breaks once the band’s macroscopic magnitude is established (γf(t)→1 ). At...
-
[79]
Euler-Maruyama[ 37]: The foundational 1st-order weak (and 1/2-order strong) SDE solver, requiring 1 function evaluation per step
-
[80]
Stochastic Heun: A 2nd-order weak predictor-corrector method requiring 2 function evaluations per step [13, 22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.