DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation
Pith reviewed 2026-06-29 07:01 UTC · model grok-4.3
The pith
DynaFLIP pre-trains image encoders on image-language-3D flow triplets so the resulting representations capture motion and improve robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
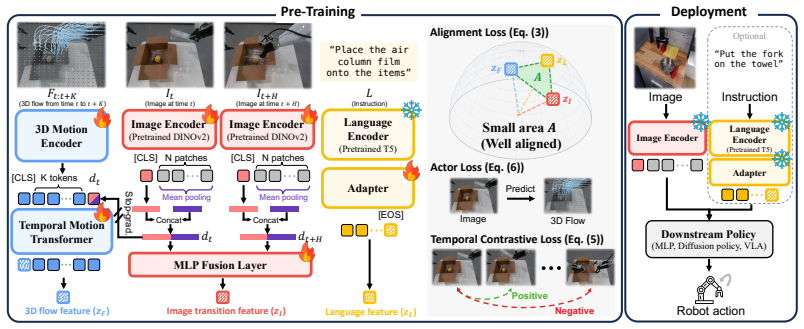
By constructing image-language-3D flow triplets from heterogeneous videos and training an image encoder to minimize simplex volume in the shared embedding space together with cosine regularization and contrastive learning, the resulting representations encode control-relevant dynamics and function as reusable backbones that raise performance on diverse policies including VLAs.
What carries the argument
Simplex-volume minimization of image-language-3D flow triplets in hyperspherical space, augmented by cosine regularizer and contrastive objective, to align the modalities during pre-training.
Load-bearing premise
That automatically built image-language-3D flow triplets supply reliable supervision and that volume minimization yields control-relevant features rather than artifacts of the geometric objective.
What would settle it
A controlled comparison in which policies using the DynaFLIP encoder show no improvement over policies using standard pre-trained encoders on the same manipulation tasks.
Figures


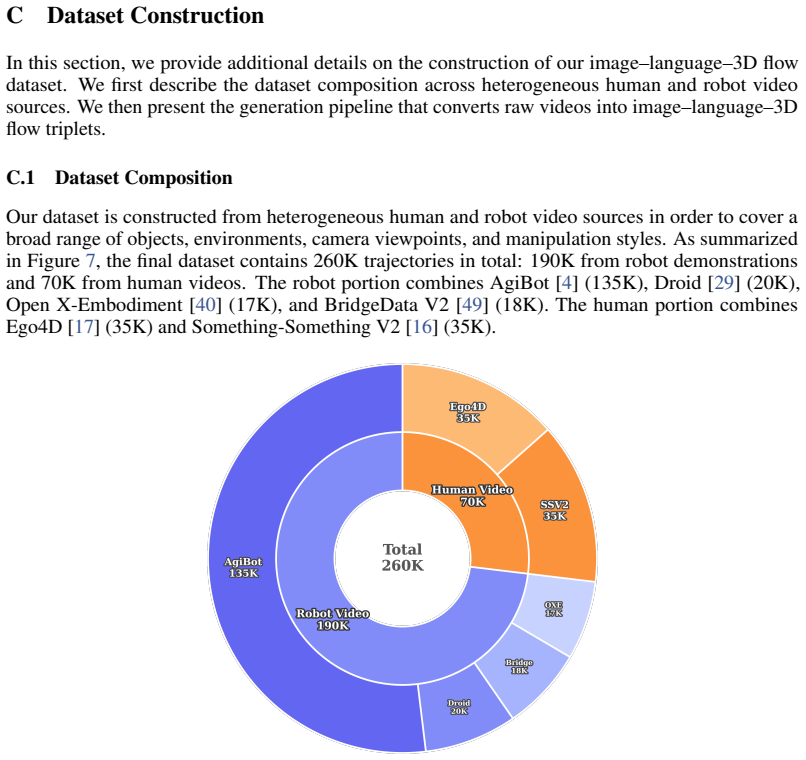
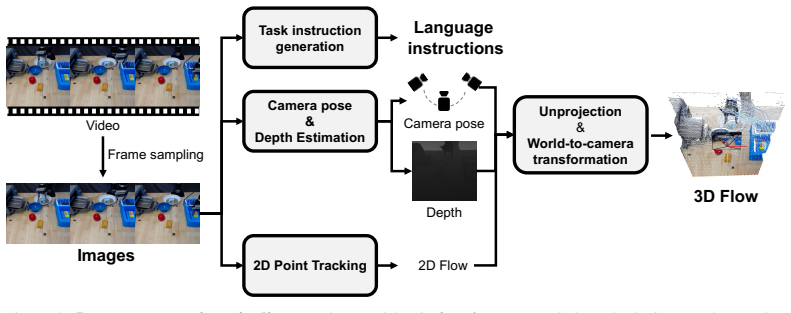



read the original abstract
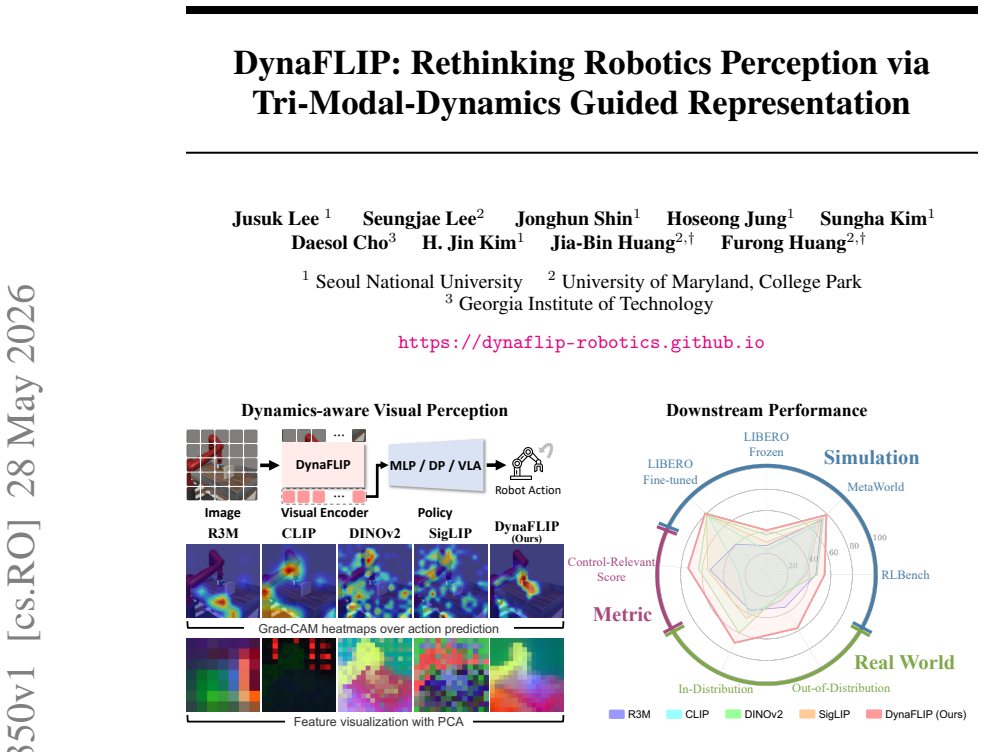
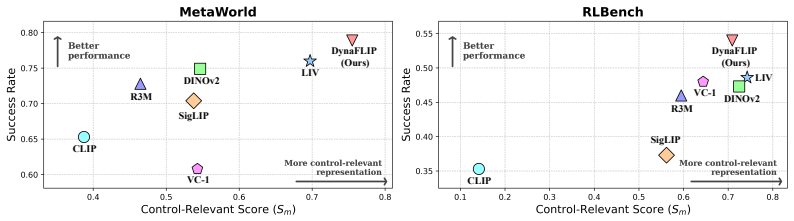
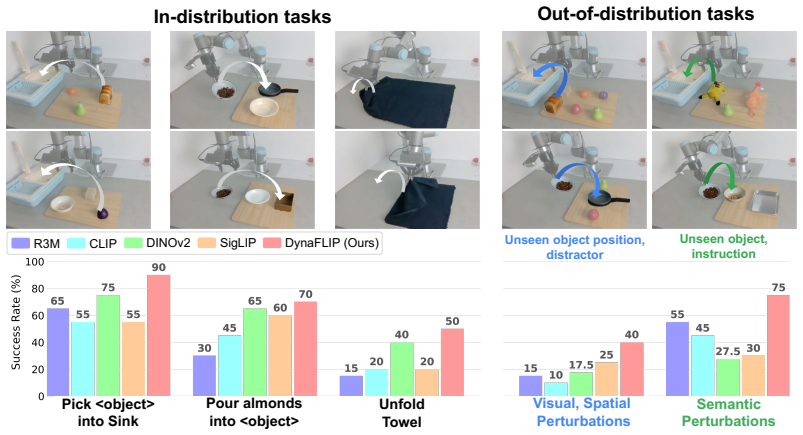
Robot manipulation critically depends on perception that preserves the action-relevant aspects of a scene. Yet most robot learning pipelines are built upon visual encoders pre-trained for static recognition or vision-language alignment, leaving motion understanding to downstream policies. We introduce DynaFLIP, a dynamics-aware multimodal pre-training framework that pushes motion understanding upstream into perception. We construct image-language-3D flow triplets from heterogeneous human and robot videos, and use these triplets as training-time supervision to shape an image-only encoder. Our key idea is to encourage the three modalities to span a small simplex volume in the shared hyperspherical space -- a smaller simplex volume indicating stronger alignment. To avoid the geometric ambiguity and trivial collapse of naive volume minimization, we combine simplex-volume minimization with a cosine regularizer and a contrastive objective. Our analyses show that DynaFLIP focuses on control-relevant regions critical for manipulation. The resulting dynamics-aware representations serve as reusable visual backbones and consistently outperform baselines across diverse downstream policies, including VLAs. We validate this across diverse simulation and real-world setups, with gains reaching +22.5% under out-of-distribution scenarios. Our results suggest that robot generalization improves when visual representations are trained to encode not just what is present, but how the world changes under action.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DynaFLIP, a dynamics-aware multimodal pre-training framework for robotics perception. It constructs image-language-3D flow triplets from heterogeneous human and robot videos to supervise an image-only encoder. The training objective minimizes the simplex volume spanned by the three modalities in hyperspherical space, combined with a cosine regularizer and contrastive objective to prevent collapse and ambiguity. The resulting representations are shown to focus on control-relevant regions and serve as backbones that outperform baselines in downstream policies, including VLAs, with gains up to +22.5% in out-of-distribution scenarios across simulation and real-world setups.
Significance. If the empirical results hold under rigorous evaluation, this work could significantly impact robot learning by integrating motion dynamics into visual pre-training rather than leaving it to the policy. The tri-modal alignment via geometric volume minimization offers a fresh perspective on representation learning for manipulation tasks, potentially leading to more generalizable policies.
major comments (1)
- [Experiments] The central claim of consistent outperformance and +22.5% OOD gains relies on the experimental results, but the manuscript lacks sufficient details on baseline descriptions, implementation specifics, statistical significance tests, number of runs, and ablation studies on the individual loss components (simplex volume, cosine, contrastive). This makes it difficult to verify if the gains are due to the proposed method or other factors.
minor comments (1)
- [Abstract] The abstract mentions 'our analyses show' and 'we validate' but does not provide any quantitative details or references to specific figures/tables in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive suggestion on strengthening the experimental section. We agree that additional details are required to support the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] The central claim of consistent outperformance and +22.5% OOD gains relies on the experimental results, but the manuscript lacks sufficient details on baseline descriptions, implementation specifics, statistical significance tests, number of runs, and ablation studies on the individual loss components (simplex volume, cosine, contrastive). This makes it difficult to verify if the gains are due to the proposed method or other factors.
Authors: We agree that the current manuscript would benefit from expanded experimental documentation. In the revision we will: (1) expand baseline descriptions with citations, re-implementation notes, and hyperparameter tables; (2) add a dedicated implementation section covering optimizer settings, learning rates, batch sizes, data preprocessing, and compute resources; (3) report all main results as mean ± std over five independent random seeds and include paired t-tests (p < 0.05) against the strongest baseline for each task; (4) insert a new ablation subsection that isolates the simplex-volume term, the cosine regularizer, and the contrastive term, showing downstream policy performance when each component is removed individually. These additions will make the source of the reported gains verifiable. revision: yes
Circularity Check
No significant circularity; empirical pipeline stands on external validation
full rationale
The paper's core pipeline—automatic construction of image-language-3D flow triplets from heterogeneous videos, followed by simplex-volume minimization on the hypersphere combined with cosine and contrastive regularizers to train an image encoder—is presented as an empirical training procedure whose outputs are then evaluated on downstream policy tasks. No equations, derivations, or claims in the provided text reduce the reported performance gains (+22.5% OOD) to quantities defined by the training objectives themselves or to self-citations. The method does not invoke uniqueness theorems, rename known results, or treat fitted parameters as predictions. The central claim remains an externally testable empirical outcome rather than a self-referential identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Smaller simplex volume in the shared hyperspherical embedding space indicates stronger cross-modal alignment of dynamics
Reference graph
Works this paper leans on
-
[1]
Infonce induces gaussian distribu- tion
Roy Betser, Eyal Gofer, Meir Yossef Levi, and Guy Gilboa. Infonce induces gaussian distribu- tion. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Rt-1: Robotics transformer for real-world control at scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. InRobotics: Science and Systems (RSS), 2023
2023
-
[4]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[5]
Univla: Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions. In Robotics: Science and Systems (RSS), 2025
2025
-
[6]
Unsupervised learning of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. InNeural Information Processing Systems (NeurIPS), 2020
2020
-
[7]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InInternational Conference on Computer Vision (ICCV), 2021
2021
-
[8]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InConference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[10]
A triangle enables multi- modal alignment beyond cosine similarity
Giordano Cicchetti, Eleonora Grassucci, and Danilo Comminiello. A triangle enables multi- modal alignment beyond cosine similarity. InNeural Information Processing Systems (NeurIPS), 2025
2025
-
[11]
Gramian multimodal representation learning and alignment
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello. Gramian multimodal representation learning and alignment. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InConference on Computer Vision and Pattern Recognition (CVPR), 2009
2009
-
[13]
Capturing visual environ- ment structure correlates with control performance
Jiahua Dong, Yunze Man, Pavel Tokmakov, and Yu-Xiong Wang. Capturing visual environ- ment structure correlates with control performance. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[15]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 11
2023
-
[16]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InInternational Conference on Computer Vision (ICCV), 2017
2017
-
[17]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. InConference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[18]
Bootstrap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. InNeural Information Processing Systems (NeurIPS), 2020
2020
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InConference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[20]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InConference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[21]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[22]
π0.5: a vision- language-action model with open-world generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision- language-action model with open-world generalization. InConference on Robot Learning (CoRL), 2025
2025
-
[23]
Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2): 3019–3026, 2020
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2): 3019–3026, 2020
2020
-
[24]
Robots pre-train robots: Manipulation-centric robotic representation from large-scale robot datasets
Guangqi Jiang, Yifei Sun, Tao Huang, Huanyu Li, Yongyuan Liang, and Huazhe Xu. Robots pre-train robots: Manipulation-centric robotic representation from large-scale robot datasets. In International Conference on Learning Representations (ICLR), 2025
2025
-
[25]
Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment
Cijo Jose, Théo Moutakanni, Dahyun Kang, Federico Baldassarre, Timothée Darcet, Hu Xu, Daniel Li, Marc Szafraniec, Michaël Ramamonjisoa, Maxime Oquab, et al. Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment. InConference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[26]
Learning visual features from large weakly supervised data
Armand Joulin, Laurens Van Der Maaten, Allan Jabri, and Nicolas Vasilache. Learning visual features from large weakly supervised data. InEuropean Conference on Computer Vision (ECCV), 2016
2016
-
[27]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. InConference on robot learning (CoRL), 2018
2018
-
[28]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In International Conference on Computer Vision (ICCV), 2025
2025
-
[29]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Fine-tuning vision-language-action models: Optimizing speed and success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success. InRobotics: Science and Systems (RSS), 2025. 12
2025
-
[31]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), 2025
2025
-
[32]
Tracegen: World modeling in 3d trace space enables learning from cross-embodiment videos
Seungjae Lee, Yoonkyo Jung, Inkook Chun, Yao-Chih Lee, Zikui Cai, Hongjia Huang, Aayush Talreja, Tan Dat Dao, Yongyuan Liang, Jia-Bin Huang, et al. Tracegen: World modeling in 3d trace space enables learning from cross-embodiment videos. InConference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[33]
Libero: Benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. InNeural Information Processing Systems (NeurIPS), 2023
2023
-
[34]
Liv: Language-image representations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language-image representations and rewards for robotic control. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[35]
Vip: Towards universal visual reward and representation via value-implicit pre-training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Osbert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[36]
Where are we in the search for an artificial visual cortex for embodied intelligence? InNeural Information Processing Systems (NeurIPS), 2023
Arjun Majumdar, Karmesh Yadav, Sergio Arnaud, Jason Ma, Claire Chen, Sneha Silwal, Aryan Jain, Vincent-Pierre Berges, Tingfan Wu, Jay Vakil, et al. Where are we in the search for an artificial visual cortex for embodied intelligence? InNeural Information Processing Systems (NeurIPS), 2023
2023
-
[37]
R3m: A universal visual representation for robot manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation. InConference on Robot Learning (CoRL), 2023
2023
-
[38]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
2024
-
[40]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. InIEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[41]
Control-oriented clustering of visual latent representa- tion
Han Qi, Haocheng Yin, and Heng Yang. Control-oriented clustering of visual latent representa- tion. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning (ICML), 2021
2021
-
[43]
Accommo- dating audio modality in clip for multimodal processing
Ludan Ruan, Anwen Hu, Yuqing Song, Liang Zhang, Sipeng Zheng, and Qin Jin. Accommo- dating audio modality in clip for multimodal processing. InAAAI Conference on Artificial Intelligence (AAAI), 2023
2023
-
[44]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InInternational Conference on Computer Vision (ICCV), 2017
2017
-
[45]
Masked world models for visual control
Younggyo Seo, Danijar Hafner, Hao Liu, Fangchen Liu, Stephen James, Kimin Lee, and Pieter Abbeel. Masked world models for visual control. InConference on Robot Learning (CoRL), 2023. 13
2023
-
[46]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021
2021
-
[47]
Hrp: Human affordances for robotic pre-training
Mohan Kumar Srirama, Sudeep Dasari, Shikhar Bahl, and Abhinav Gupta. Hrp: Human affordances for robotic pre-training. InRobotics: Science and Systems (RSS), 2024
2024
-
[48]
The open motion planning library.IEEE Robotics & Automation Magazine, 19(4):72–82, 2012
Ioan A Sucan, Mark Moll, and Lydia E Kavraki. The open motion planning library.IEEE Robotics & Automation Magazine, 19(4):72–82, 2012
2012
-
[49]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[50]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InConference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[51]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learning (ICML), 2020
2020
-
[52]
Wuding Weng, Tongshu Wu, Liucheng Chen, Siyu Xie, Zheng Wang, Xing Xu, Jingkuan Song, and Heng Tao Shen. Language-grounded decoupled action representation for robotic manipulation.arXiv preprint arXiv:2603.12967, 2026
-
[53]
Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
Tete Xiao, Ilija Radosavovic, Trevor Darrell, and Jitendra Malik. Masked visual pre-training for motor control.arXiv preprint arXiv:2203.06173, 2022
-
[54]
Spatialtrackerv2: 3d point tracking made easy
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy. In International Conference on Computer Vision (ICCV), 2025
2025
-
[55]
Wenzhe Yin, Pan Zhou, Zehao Xiao, Jie Liu, Shujian Yu, Jan-Jakob Sonke, and Efstratios Gavves. Towards uniformity and alignment for multimodal representation learning.arXiv preprint arXiv:2602.09507, 2026
-
[56]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning (CoRL), 2020
2020
-
[57]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[58]
Tapip3d: Tracking any point in persistent 3d geometry
Bowei Zhang, Lei Ke, Adam W Harley, and Katerina Fragkiadaki. Tapip3d: Tracking any point in persistent 3d geometry. InNeural Information Processing Systems (NeurIPS), 2025
2025
-
[59]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[60]
Zezhou Zhang, Songxin Zhang, Xiao Xiong, Junjie Zhang, Zejian Xie, Jingyi Xi, Zunyao Mao, Zan Mao, Zhixin Mai, Zhuoyang Song, et al. Pvi: Plug-in visual injection for vision-language- action models.arXiv preprint arXiv:2603.12772, 2026
-
[61]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daumé III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. InInternational Conference on Learning Representa- tions (ICLR), 2025
2025
-
[62]
pick up <object> and place it in sink
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, et al. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment. InInternational Conference on Learning Representations (ICLR), 2024. 14 Appendix A Additional Related Works 16 A.1 Pre-training Obj...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.