Enhancing Regime Shift Detection Using Unstructured Data: A Study on the Treasury Market
Pith reviewed 2026-06-30 19:02 UTC · model grok-4.3
The pith
Combining LLM reasoning on central bank texts with statistical tests on Treasury data detects monetary policy regime shifts more accurately than data-only methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
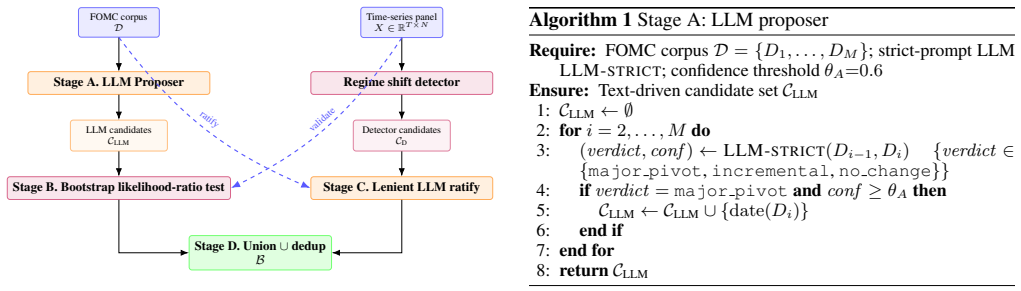
The text-enhanced regime shift detection pipeline integrates large language model reasoning over central-bank communications with bootstrap likelihood-ratio tests on a 14-variable vector autoregression of U.S. Treasury and macroeconomic series; when evaluated on 2010-2024 FOMC minutes, it attains an F1 score of 0.82 against a verified anchor list of monetary-policy regime shifts, exhibits same-day modal detection latency, and outperforms pure data-driven detectors across four interchangeable statistical methods.
What carries the argument
The text-enhanced regime shift detection pipeline, which uses LLM analysis of FOMC minutes to propose or validate candidates and applies statistical structural-break tests on a VAR for confirmation.
If this is right
- Regime shift detection gains robustness when text signals from policy communications are admitted alongside time-series data.
- The same pipeline works with any of four interchangeable data-driven detectors.
- Detection occurs with same-day modal latency relative to the anchor events.
- Interpretability improves because each flagged shift is tied to explicit textual evidence.
- Performance remains higher than pure statistical baselines even when the underlying detector changes.
Where Pith is reading between the lines
- The method could be tested on communications from other central banks to check whether the performance lift generalizes beyond the Federal Reserve.
- If the LLM component can be run on embargoed or real-time transcripts, the pipeline might flag shifts before they appear in market prices.
- A natural next measurement would be whether the detected shifts improve out-of-sample forecasts of yield volatility or bond returns.
- The framework might also reduce the number of spurious breaks that pure statistical detectors produce during periods of high multicollinearity.
Load-bearing premise
That LLM reasoning over central-bank communications can reliably surface accurate regime shift candidates from unstructured text without circular dependence on the same signals used to build the verified anchor list.
What would settle it
Apply the pipeline to FOMC minutes and Treasury data from 2025 onward and measure whether the F1 score against an independently compiled list of regime shifts falls materially below 0.75.
Figures



read the original abstract
Regime shifts in financial markets reorganise the joint dynamics of asset prices and macro variables, breaking any single-regime calibration. They are nonetheless difficult to detect reliably because the data signal is noisy and heavily multicollinear, while the contemporaneous text that announces them is unstructured. Standard regime shift detection methods rely solely on structured time-series data and ignore policy communications, even though these texts often signal shifts before they materialise in observed prices. We propose a text-enhanced regime shift detection pipeline that combines large language model (LLM) reasoning over central-bank communications with statistical validation on multivariate financial time series. The framework is detector-agnostic: text-proposed candidates are validated using a bootstrap likelihood-ratio test on a vector autoregression (VAR), while data-driven candidates from arbitrary regime detectors are ratified through a lenient LLM text check. We evaluate the framework on 2010-2024 FOMC minutes paired with a 14-variable U.S. Treasury and macroeconomic panel, using four interchangeable data-driven detectors. The proposed pipeline achieves F1 = 0.82 against a verified anchor list of monetary-policy regime shifts, with same-day modal detection latency and consistently stronger performance than pure data-driven baselines. The results demonstrate that combining unstructured policy text with statistical structural-break detection improves the robustness and interpretability of regime shift identification in financial markets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a detector-agnostic pipeline that uses LLM reasoning over FOMC minutes to propose monetary-policy regime-shift candidates, validates them via bootstrap likelihood-ratio tests on a 14-variable VAR of Treasury yields and macro series, and conversely ratifies data-driven candidates from four interchangeable detectors via lenient LLM text checks. It reports an F1 of 0.82 against a verified anchor list on 2010-2024 data, same-day modal latency, and consistent gains over pure time-series baselines.
Significance. If the anchor list is shown to be independent of the LLM component and the validation steps are fully specified, the hybrid approach could improve robustness of regime detection in noisy, multicollinear financial data by incorporating policy-text signals that often precede price movements. The framework's modularity across detectors is a constructive feature.
major comments (2)
- [Abstract] Abstract: The headline F1 = 0.82 is measured against a 'verified anchor list' of monetary-policy regime shifts, yet the manuscript supplies no description of how the list was constructed or verified, nor any demonstration that verification is independent of the same FOMC-minute text signals processed by the LLM component. This independence is load-bearing for interpreting both the absolute F1 value and the claimed lift over data-driven baselines.
- [Abstract] Abstract and evaluation description: The statistical validation step is described only at the level of 'bootstrap likelihood-ratio test on a vector autoregression (VAR)'; no equations, lag-selection procedure, bootstrap implementation details, or handling of the 14-variable panel's multicollinearity are provided. These omissions prevent assessment of whether the reported performance gains are attributable to the text component or to the particular statistical test.
minor comments (2)
- [Abstract] The abstract states results for 'four interchangeable data-driven detectors' but does not name them or report per-detector metrics, which would clarify the robustness claim.
- [Abstract] No error analysis, confusion-matrix breakdown, or discussion of LLM hallucination or prompt sensitivity is mentioned, even though these directly affect the reliability of the text-proposal and ratification steps.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We agree that the manuscript requires additional detail on the verified anchor list and the statistical validation procedure to support the reported results. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline F1 = 0.82 is measured against a 'verified anchor list' of monetary-policy regime shifts, yet the manuscript supplies no description of how the list was constructed or verified, nor any demonstration that verification is independent of the same FOMC-minute text signals processed by the LLM component. This independence is load-bearing for interpreting both the absolute F1 value and the claimed lift over data-driven baselines.
Authors: We acknowledge the omission in the current version. The anchor list was compiled from documented monetary-policy events drawn from official Federal Reserve releases and established academic references on FOMC actions, with verification performed via independent cross-referencing by the authors against primary sources. This process did not rely on the LLM pipeline. We will add a dedicated subsection in the data and evaluation sections that fully describes the list's construction, sources, and verification steps, explicitly demonstrating independence from the LLM text processing. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: The statistical validation step is described only at the level of 'bootstrap likelihood-ratio test on a vector autoregression (VAR)'; no equations, lag-selection procedure, bootstrap implementation details, or handling of the 14-variable panel's multicollinearity are provided. These omissions prevent assessment of whether the reported performance gains are attributable to the text component or to the particular statistical test.
Authors: We agree that the description is too high-level for reproducibility. In the revised manuscript we will expand the methodology and evaluation sections to include the VAR model equations for the 14-variable system, the lag-selection procedure based on information criteria, the precise bootstrap implementation (including resampling method and number of replications), and the steps taken to address multicollinearity in the Treasury panel. These additions will allow readers to evaluate the contribution of the text component separately from the statistical test. revision: yes
Circularity Check
No significant circularity; evaluation uses independent statistical validation on time series
full rationale
The abstract describes a detector-agnostic pipeline in which text-proposed candidates are validated via bootstrap likelihood-ratio test on a VAR using a 14-variable Treasury/macro panel, while data-driven candidates receive a separate LLM text check. The F1=0.82 is reported against a verified anchor list, but the provided text supplies no equation, definition, or self-citation showing that the anchor list construction or verification reduces to the LLM reasoning step by construction. No fitted-input-called-prediction, self-definitional, or load-bearing self-citation pattern is exhibited. The statistical validation step operates on structured time-series data distinct from the unstructured text proposals, rendering the central performance claim self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM reasoning can extract reliable regime shift signals from FOMC minutes
- domain assumption The verified anchor list accurately represents true monetary policy regime shifts
Reference graph
Works this paper leans on
-
[1]
Com- putation and analysis of multiple structural change models
[Bai and Perron, 2003] Jushan Bai and Pierre Perron. Com- putation and analysis of multiple structural change models. Journal of Applied Econometrics, 18(1):1–22,
2003
-
[2]
[Bullocket al., 2024 ] Seth Bullock, Nirav Ajmeri, Mike Batty, Michaela Black, John Cartlidge, Robert Challen, Cangxiong Chen, Jing Chen, Joan Condell, Leon Danon, Adam Dennett, Alison Heppenstall, Paul Marshall, Phil Morgan, Aisling O’Kane, Laura G. E. Smith, Theresa Smith, and Hywel T. P. Williams. Artificial intelligence for collective intelligence: A ...
2024
-
[3]
Campbell, Carolin Pflueger, and Luis M
[Campbellet al., 2020 ] John Y . Campbell, Carolin Pflueger, and Luis M. Viceira. Macroeconomic drivers of bond and equity risks.Journal of Political Economy, 128(8):3148– 3185,
2020
-
[4]
[Chow, 1960] Gregory C. Chow. Tests of equality between sets of coefficients in two linear regressions.Economet- rica, 28(3):591–605,
1960
-
[5]
Treasury inconvenience yields during the COVID- 19 crisis.Journal of Financial Economics, 143(1):57–79,
[Heet al., 2022 ] Zhiguo He, Stefan Nagel, and Zhaogang Song. Treasury inconvenience yields during the COVID- 19 crisis.Journal of Financial Economics, 143(1):57–79,
2022
-
[6]
Causal discovery from hetero- geneous/nonstationary data.Journal of Machine Learning Research, 21(89):1–53,
[Huanget al., 2020 ] Biwei Huang, Kun Zhang, Jiji Zhang, Joseph Ramsey, Ruben Sanchez-Romero, Clark Glymour, and Bernhard Sch ¨olkopf. Causal discovery from hetero- geneous/nonstationary data.Journal of Machine Learning Research, 21(89):1–53,
2020
-
[7]
From text to quantified insights: A large-scale LLM analysis of central bank communication
[International Monetary Fund, 2025] International Mone- tary Fund. From text to quantified insights: A large-scale LLM analysis of central bank communication. Technical Report IMF Working Paper 2025/109, International Monetary Fund,
2025
-
[8]
arXiv preprint arXiv:2305.00050 , year=
[Kıcımanet al., 2023] Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. Causal reasoning and large lan- guage models: Opening a new frontier for causality.arXiv preprint arXiv:2305.00050,
-
[9]
[Killicket al., 2012 ] Rebecca Killick, Paul Fearnhead, and Idris A. Eckley. Optimal detection of changepoints with a linear computational cost.Journal of the American Statis- tical Association, 107(500):1590–1598,
2012
-
[10]
Large language models in finance: A survey
[Liet al., 2023 ] Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. Large language models in finance: A survey. InProceedings of the F ourth ACM International Confer- ence on AI in Finance (ICAIF),
2023
-
[11]
Discovery of the hidden world with large language models
[Liuet al., 2024 ] Chenxi Liu, Yongqiang Chen, Tongliang Liu, Mingming Gong, James Cheng, Bo Han, and Kun Zhang. Discovery of the hidden world with large language models. InAdvances in Neural Information Processing Systems (NeurIPS),
2024
-
[12]
Can large language models build causal graphs? InNeurIPS Workshop on Causal Machine Learn- ing for Real-World Impact,
[Longet al., 2023 ] Stephanie Long, Tibor Schuster, and Alexandre Pich´e. Can large language models build causal graphs? InNeurIPS Workshop on Causal Machine Learn- ing for Real-World Impact,
2023
-
[13]
Can ChatGPT forecast stock price movements? Re- turn predictability and large language models,
[Lopez-Lira and Tang, 2023] Alejandro Lopez-Lira and Yuehua Tang. Can ChatGPT forecast stock price move- ments? Return predictability and large language models. arXiv preprint arXiv:2304.07619,
-
[14]
Detect- ing and quantifying causal associations in large nonlinear time series datasets.Science Advances, 5(11):eaau4996,
[Rungeet al., 2019 ] Jakob Runge, Peer Nowack, Marlene Kretschmer, Seth Flaxman, and Dino Sejdinovic. Detect- ing and quantifying causal associations in large nonlinear time series datasets.Science Advances, 5(11):eaau4996,
2019
-
[15]
Causal discovery in financial markets: A framework for nonstationary time-series data
[Sadeghiet al., 2024 ] Agathe Sadeghi, Achintya Gopal, and Mohammad Fesanghary. Causal discovery in financial markets: A framework for nonstationary time-series data. arXiv preprint arXiv:2312.17375,
-
[16]
Reconstructing regime-dependent causal relationships from observational time series.Chaos: An Interdisciplinary Journal of Non- linear Science, 30(11):113115,
[Saggioroet al., 2020 ] Elena Saggioro, Jana de Wiljes, Mar- lene Kretschmer, and Jakob Runge. Reconstructing regime-dependent causal relationships from observational time series.Chaos: An Interdisciplinary Journal of Non- linear Science, 30(11):113115,
2020
-
[17]
Sims and Tao Zha
[Sims and Zha, 2006] Christopher A. Sims and Tao Zha. Were there regime switches in U.S. monetary policy? American Economic Review, 96(1):54–81,
2006
-
[18]
Selective review of offline change point detection methods.Signal Processing, 167:107299,
[Truonget al., 2020 ] Charles Truong, Laurent Oudre, and Nicolas Vayatis. Selective review of offline change point detection methods.Signal Processing, 167:107299,
2020
-
[19]
G., Kumar, A., Bachu, S., Balasubramanian, V
[Vashishthaet al., 2023 ] Aniket Vashishtha, Ab- bavaram Gowtham Reddy, Abhinav Kumar, Saketh Bachu, Vineeth N. Balasubramanian, and Amit Sharma. Causal inference using LLM-guided discovery.arXiv preprint arXiv:2310.15117,
-
[20]
Balasubramanian, and Amit Sharma
[Vashishthaet al., 2025 ] Aniket Vashishtha, Ab- bavaram Gowtham Reddy, Abhinav Kumar, Saketh Bachu, Vineeth N. Balasubramanian, and Amit Sharma. Causal order: The key to leveraging imperfect experts in causal inference. InInternational Conference on Learning Representations (ICLR),
2025
-
[21]
BloombergGPT: A Large Language Model for Finance
[Wuet al., 2023 ] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prab- hanjan Kambadur, David Rosenberg, and Gideon Mann. BloombergGPT: A large language model for finance. arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
FinGPT: Open-source financial large lan- guage models,
[Yanget al., 2023 ] Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. FinGPT: Open-source financial large language models.arXiv preprint arXiv:2306.06031,
-
[23]
Causal par- rots: Large language models may talk causality but are not causal.Transactions on Machine Learning Research,
[Zeˇcevi´cet al., 2023 ] Matej Zeˇcevi´c, Moritz Willig, Deven- dra Singh Dhami, and Kristian Kersting. Causal par- rots: Large language models may talk causality but are not causal.Transactions on Machine Learning Research,
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.