AdvScene: Rethinking Adversarial Patch Evaluation Through Scene Robustness
Pith reviewed 2026-06-29 06:29 UTC · model grok-4.3
The pith
AdvScene shows adversarial patch effectiveness varies substantially across real scenes in ways missed by image or simulator tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
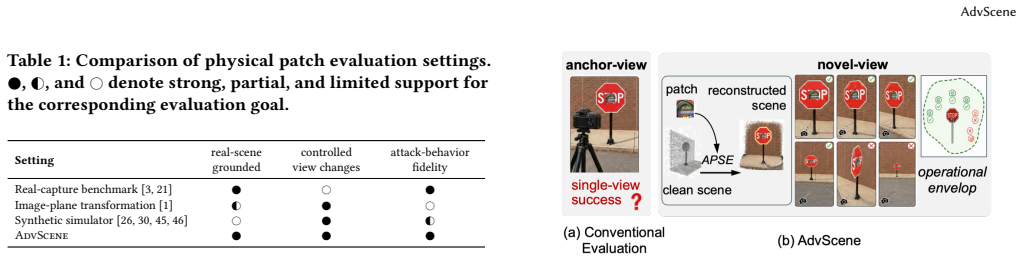
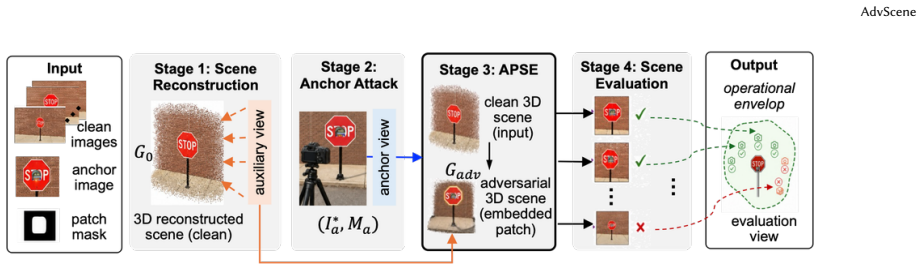
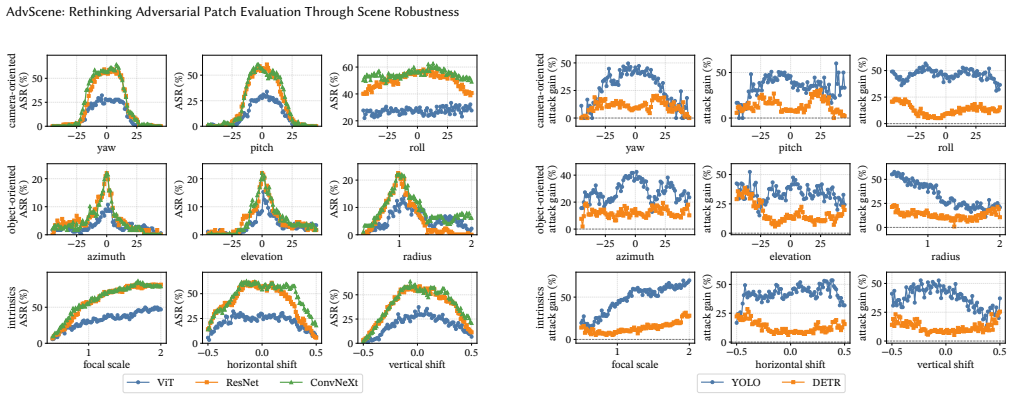
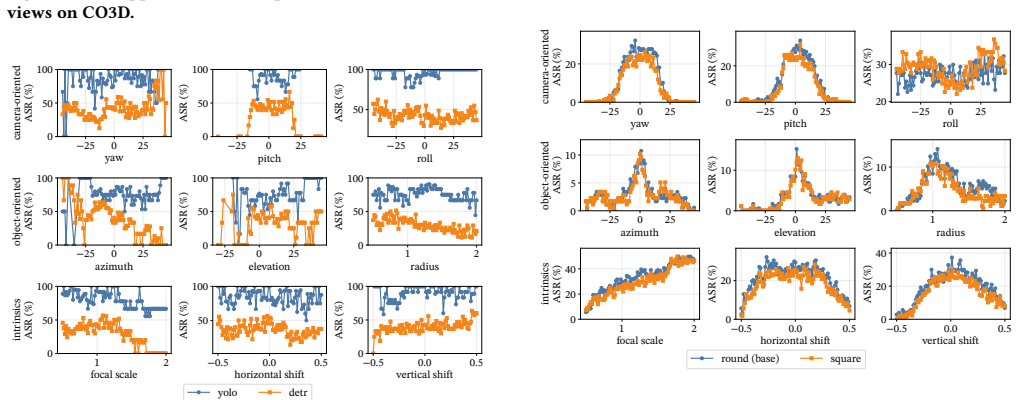
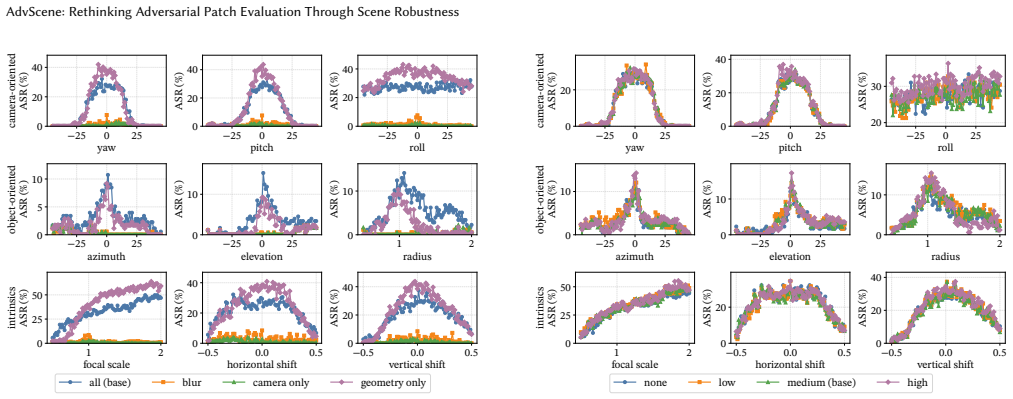
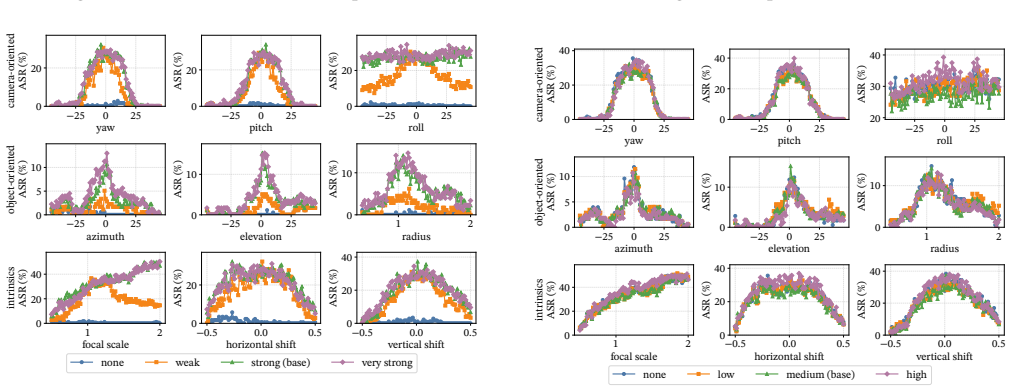
AdvScene reframes evaluation as operational measurement of a fixed deployed patch inside a reconstructed real scene. It formalizes the task of extending a patch defined in one anchor view to the full scene as a constrained lifting problem and introduces Adversarial Patch-to-Scene Embedding (APSE) to resolve cross-view ambiguity while preserving attack-critical appearance and enforcing locality, target-surface attachment, and cross-view consistency. Validation against real-world physical data shows that this approach reveals substantial scene-dependent variation in attack effectiveness that is not captured by existing image-centric or simulator-based evaluations.
What carries the argument
Adversarial Patch-to-Scene Embedding (APSE), which lifts a patch from a single anchor view into a 3D scene model while enforcing locality, surface attachment, and cross-view consistency.
If this is right
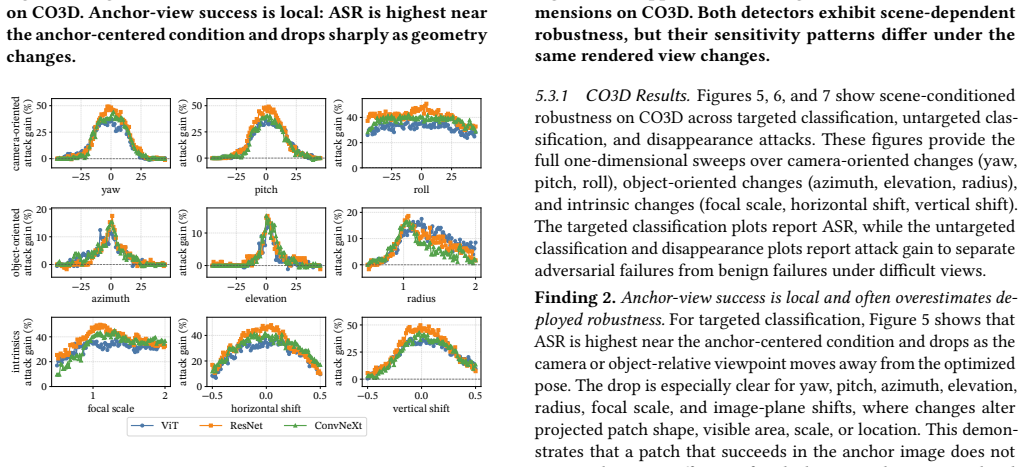
- A patch that succeeds from the anchor view can fail from other viewpoints or distances inside the same scene.
- Attack effectiveness must be characterized as a function of viewpoint, distance, and scene context rather than a single success rate.
- Image-centric and simulator-based evaluations systematically miss or misestimate real deployment risk.
- Security assessments need scene-specific operational envelopes to determine whether a patch poses a practical threat.
Where Pith is reading between the lines
- Patch designers could use the operational-envelope output to optimize for consistency across an entire scene rather than a single view.
- The framework could be applied to other physical adversarial objects such as stickers or clothing patterns to test their scene robustness.
- Requiring scene-grounded testing might shift regulatory or safety standards for vision systems in autonomous vehicles or surveillance.
Load-bearing premise
The reconstructed scenes and APSE embedding faithfully preserve attack-critical appearance and behavior under viewpoint changes without introducing artifacts or losing locality.
What would settle it
Physical experiments in the original scene where measured attack success rates across multiple viewpoints and distances differ significantly from the rates predicted by the AdvScene reconstruction.
Figures


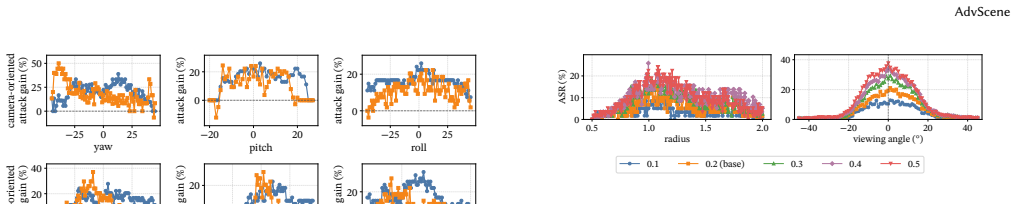










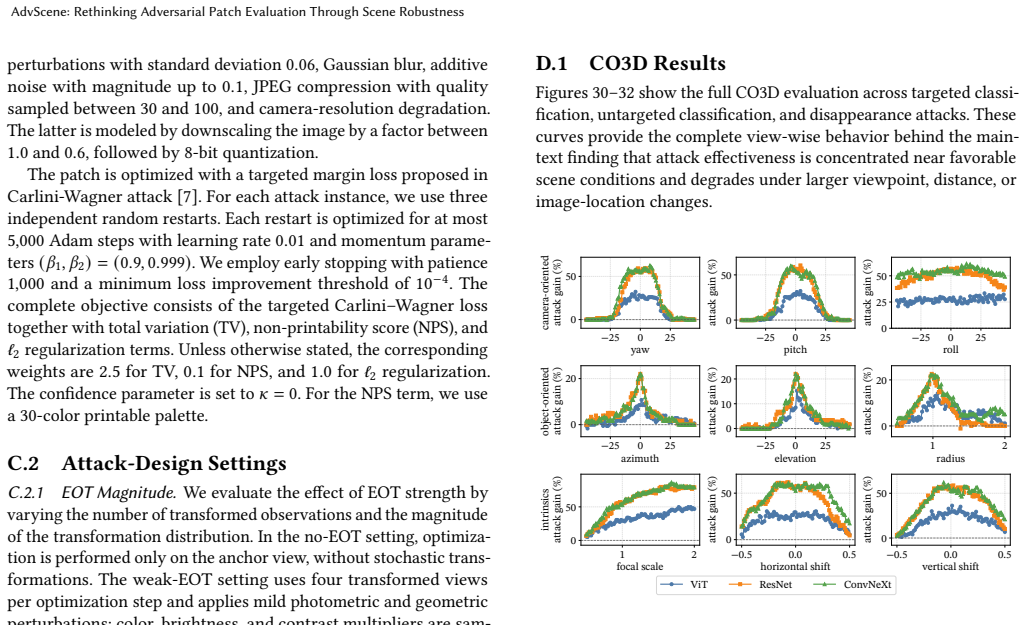
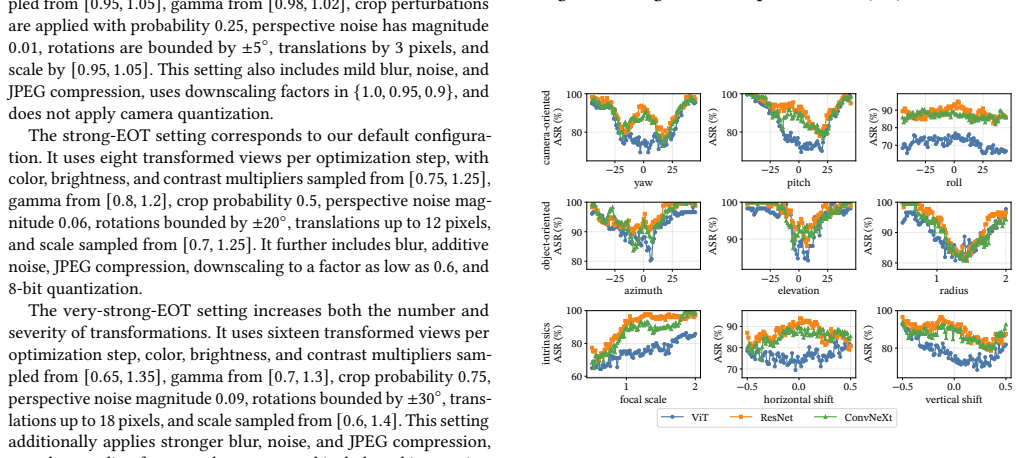
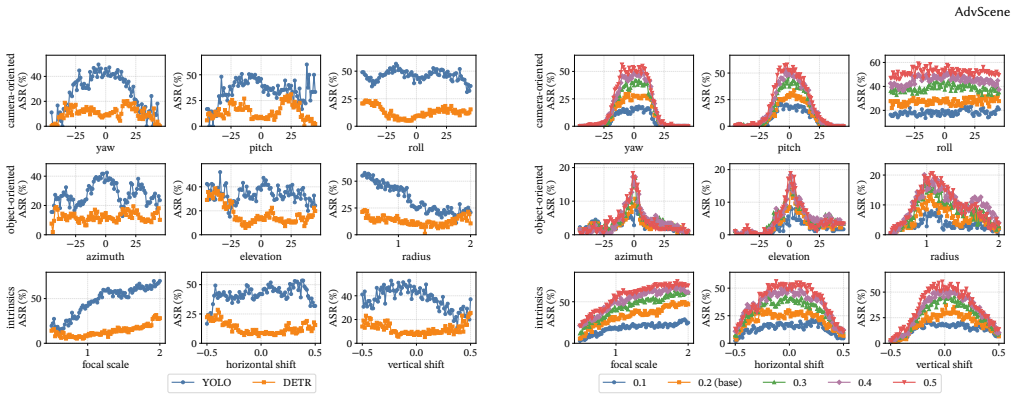
read the original abstract
Adversarial patches are physical patterns attached to real objects to mislead AI vision systems. Their real-world risk is not determined by a single successful prediction, but by whether they remain effective after deployment under changing viewpoints, distances, and scene conditions. We refer to this property as scene robustness, the effectiveness of a deployed patch across conditions in a real environment. Yet existing evaluations do not measure scene robustness well: real image benchmarks are realistic but fixed, while simulators are controllable but not grounded in a specific real scene. We present AdvScene, a scene-grounded framework for measuring the scene robustness of adversarial patches in reconstructed real environments. AdvScene reframes evaluation as operational measurement: given a fixed deployed patch, it characterizes the patch's operational envelope - where and when the attack succeeds - as a function of viewpoint, distance, and scene context. A key challenge is that the attack is typically defined only in a single anchor view, while evaluation requires a representation that remains faithful under viewpoint changes. We formalize this as a constrained lifting problem and introduce Adversarial Patch-to-Scene Embedding (APSE), which resolves cross-view ambiguity while preserving attack-critical appearance and enforcing locality, target-surface attachment, and cross-view consistency. We validate AdvScene using real-world physical data and conduct a comprehensive evaluation of existing adversarial patches. Our results show that AdvScene reveals substantial scene-dependent variation in attack effectiveness that is not captured by existing image-centric or simulator-based evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AdvScene, a scene-grounded evaluation framework for adversarial patches that measures 'scene robustness' (effectiveness across viewpoints, distances, and context in a reconstructed real environment). It reframes the task as characterizing an operational envelope and formalizes the cross-view embedding of a patch defined in an anchor view as a constrained lifting problem solved via Adversarial Patch-to-Scene Embedding (APSE), which is claimed to preserve attack-critical appearance while enforcing locality, surface attachment, and cross-view consistency. Validation on real physical data is reported to reveal substantial scene-dependent variation in attack success not captured by image-centric or simulator-based baselines.
Significance. If the APSE embedding and scene reconstructions are shown to faithfully reproduce physical attack behavior without introducing artifacts, the framework would provide a useful middle ground between fixed real-image benchmarks and ungrounded simulators, enabling more operationally relevant assessment of physical adversarial attacks. The explicit treatment of viewpoint/distance dependence as a measurable property is a conceptual strength.
major comments (2)
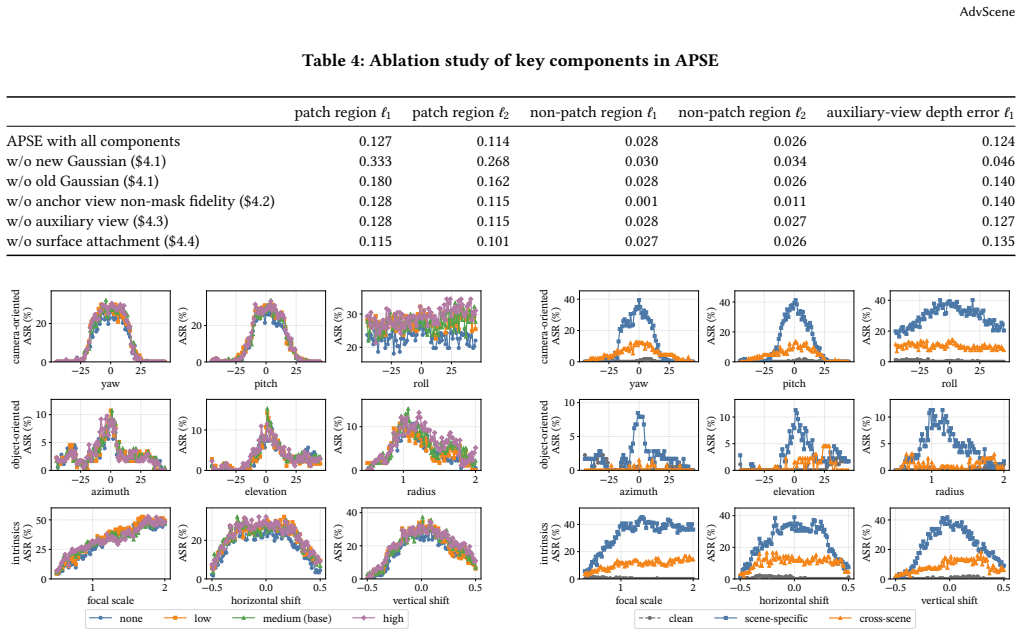
- [APSE / constrained lifting section] APSE formalization (constrained lifting problem): no quantitative check or theorem is provided demonstrating that solutions to the lifting constraints produce the same per-view attack success rates as the physical patch under viewpoint or distance changes. Multiple liftings can satisfy locality, attachment, and consistency while shifting texture, edge alignment, or effective scale; without an empirical match to physical deployments, the reported scene-dependent variation could be an embedding artifact rather than a property of the deployed patch.
- [Validation / evaluation section] Validation with real-world physical data: the abstract states that AdvScene is validated using physical data and that existing patches exhibit substantial scene-dependent variation, but no details are given on reconstruction fidelity metrics, per-view success-rate comparisons between embedded and physical patches, or statistical controls for scene reconstruction error. This is load-bearing for the central claim that AdvScene reveals variation 'not captured by existing evaluations.'
minor comments (2)
- The term 'scene robustness' is introduced but its precise operational definition (e.g., as a function or distribution over conditions) could be stated more formally in the abstract and introduction.
- Notation for the lifting constraints and APSE objective could be clarified with an explicit equation listing all enforced properties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the conceptual contribution of framing adversarial patch evaluation around scene robustness. We respond to each major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [APSE / constrained lifting section] APSE formalization (constrained lifting problem): no quantitative check or theorem is provided demonstrating that solutions to the lifting constraints produce the same per-view attack success rates as the physical patch under viewpoint or distance changes. Multiple liftings can satisfy locality, attachment, and consistency while shifting texture, edge alignment, or effective scale; without an empirical match to physical deployments, the reported scene-dependent variation could be an embedding artifact rather than a property of the deployed patch.
Authors: We acknowledge that the manuscript does not include a formal theorem or quantitative verification establishing exact equivalence of per-view success rates between APSE solutions and physical deployments. The constrained lifting formulation is intended to preserve attack-critical appearance while strictly enforcing locality, surface attachment, and cross-view consistency; the optimization objective is constructed to penalize deviations that would alter texture, alignment, or scale. Nevertheless, the referee correctly identifies that multiple feasible liftings could exist. To resolve this, the revised manuscript will add an empirical section that directly compares per-view attack success rates of APSE-embedded patches against the corresponding physical patch deployments, together with analysis of any residual differences attributable to the embedding process. revision: yes
-
Referee: [Validation / evaluation section] Validation with real-world physical data: the abstract states that AdvScene is validated using physical data and that existing patches exhibit substantial scene-dependent variation, but no details are given on reconstruction fidelity metrics, per-view success-rate comparisons between embedded and physical patches, or statistical controls for scene reconstruction error. This is load-bearing for the central claim that AdvScene reveals variation 'not captured by existing evaluations.'
Authors: We agree that the current presentation of the physical validation is insufficiently detailed to fully substantiate the central claim. Although the manuscript states that real-world physical data were used, explicit reporting of reconstruction fidelity metrics, per-view success-rate matches between embedded and physical patches, and statistical controls for reconstruction error is indeed absent. The revised version will expand the validation section to include these elements: quantitative fidelity measures (e.g., reprojection error and surface alignment accuracy), direct per-view success-rate comparisons with statistical significance testing, and controls that isolate the contribution of scene reconstruction error. These additions will allow readers to assess whether the reported scene-dependent variation originates from patch behavior rather than reconstruction artifacts. revision: yes
Circularity Check
No circularity: AdvScene introduces independent constrained-lifting framework and APSE embedding
full rationale
The derivation chain begins with the definition of scene robustness and reframes evaluation as an operational measurement task. It then formalizes the cross-view representation problem as a constrained lifting task and introduces APSE as a novel embedding that enforces the listed constraints (locality, attachment, consistency). No step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation, or prior ansatz from the same authors; the abstract and described method are self-contained constructions validated against real-world physical data rather than internal re-use of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reconstructed real environments accurately capture the variability of physical conditions relevant to attack success.
invented entities (1)
-
Adversarial Patch-to-Scene Embedding (APSE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. 2018. Syn- thesizing Robust Adversarial Examples. InProceedings of the 35th International Conference on Machine Learning. 284–293
2018
-
[2]
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. 2022. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5470–5479
2022
-
[3]
Anneliese Braunegg, Amartya Chakraborty, Michael Krumdick, Nicole Lape, Sara Leary, Keith Manville, Elizabeth Merkhofer, Laura Strickhart, and Matthew Walmer. 2020. Apricot: A dataset of physical adversarial attacks on object detection. InEuropean Conference on Computer Vision. Springer, 35–50
2020
-
[4]
Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer
Tom B. Brown, Dandelion Mané, Aurko Roy, Martín Abadi, and Justin Gilmer
-
[5]
InNeurIPS Workshop on Machine Learning and Computer Security
Adversarial Patch. InNeurIPS Workshop on Machine Learning and Computer Security
-
[6]
Jinkang Cai, Weiwen Deng, Haoran Guang, Ying Wang, Jiangkun Li, and Juan Ding. 2022. A survey on data-driven scenario generation for automated vehicle testing.Machines10, 11 (2022), 1101
2022
-
[7]
Xiao Cao, Beibei Lin, Bo Wang, Zhiyong Huang, and Robby Tan. 2026. 3DOT: Texture Transfer for 3DGS Objects from a Single Reference Image.Advances in Neural Information Processing Systems38 (2026), 156647–156667
2026
-
[8]
Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp). Ieee, 39–57
2017
-
[9]
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. 2022. Tensorf: Tensorial radiance fields. InEuropean conference on computer vision. Springer, 333–350
2022
-
[10]
Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Chau. 2018. ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detec- tor. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases. 52–68
2018
-
[11]
Yiwen Chen, Zilong Chen, Chi Zhang, Feng Wang, Xiaofeng Yang, Yikai Wang, Zhongang Cai, Lei Yang, Huaping Liu, and Guosheng Lin. 2024. GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21476–21485
2024
-
[12]
Zhi Cheng, Zhanhao Hu, Yuqiu Liu, Jianmin Li, Hang Su, and Xiaolin Hu. 2024. Full-Distance Evasion of Pedestrian Detectors in the Physical World. InAdvances in Neural Information Processing Systems
2024
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations
2021
-
[14]
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017. CARLA: An open urban driving simulator. InConference on robot learning. PMLR, 1–16
2017
-
[15]
Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. 2018. Robust Physical- World Attacks on Deep Learning Visual Classification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 1625–1634
2018
-
[16]
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2022. Plenoxels: Radiance fields without neural net- works. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5501–5510
2022
-
[17]
Bruno Galerne, Jianling Wang, Lara Raad, and Jean-Michel Morel. 2025. SGSST: scaling Gaussian splatting style transfer. InProceedings of the Computer Vision and Pattern Recognition Conference. 26535–26544
2025
-
[18]
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining and harnessing adversarial examples.ICLR (Poster)(2014)
2014
-
[19]
Amira Guesmi, Ruitian Ding, Muhammad Abdullah Hanif, Ihsen Alouani, and Muhammad Shafique. 2024. DAP: A Dynamic Adversarial Patch for Evading Person Detectors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24595–24604
2024
-
[20]
Ayaan Haque, Matthew Tancik, Alexei A Efros, Aleksander Holynski, and Angjoo Kanazawa. 2023. Instruct-nerf2nerf: Editing 3d scenes with instructions. In Proceedings of the IEEE/CVF international conference on computer vision. 19740– 19750
2023
-
[21]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Resid- ual Learning for Image Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 770–778
2016
-
[22]
Nabeel Hingun, Chawin Sitawarin, Jerry Li, and David Wagner. 2023. REAP: A large-scale realistic adversarial patch benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4640–4651
2023
-
[23]
Yu-Chih-Tuan Hu, Bo-Han Kung, Daniel Stanley Tan, Jun-Cheng Chen, Kai-Lung Hua, and Wen-Huang Cheng. 2021. Naturalistic Physical Adversarial Patch for Object Detectors. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7848–7857
2021
-
[24]
Zhanhao Hu, Wenda Chu, Xiaopei Zhu, Hui Zhang, Bo Zhang, and Xiaolin Hu. 2023. Physically realizable natural-looking clothing textures evade person detectors via 3d modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16975–16984
2023
-
[25]
Zhanhao Hu, Siyuan Huang, Xiaopei Zhu, Fuchun Sun, Bo Zhang, and Xiaolin Hu
-
[26]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Adversarial texture for fooling person detectors in the physical world. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 13307–13316
- [27]
-
[28]
Lifeng Huang, Chengying Gao, Yuyin Zhou, Cihang Xie, Alan L Yuille, Changqing Zou, and Ning Liu. 2020. Universal physical camouflage attacks on object detec- tors. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 720–729
2020
-
[29]
2023.Ultralytics YOLOv8
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. 2023.Ultralytics YOLOv8. https: //github.com/ultralytics/ultralytics
2023
-
[30]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis
-
[31]
3D Gaussian Splatting for Real-Time Radiance Field Rendering.ACM Transactions on Graphics42, 4 (2023)
2023
-
[32]
Alexey Kurakin, Ian J Goodfellow, and Samy Bengio. 2018. Adversarial examples in the physical world. InArtificial intelligence safety and security. Chapman and Hall/CRC, 99–112
2018
-
[33]
Zirui Lan, Wei Herng Choong, Ching-Yu Kao, Yi Wang, Mathias Dehm, Philip Sperl, Konstantin Böttinger, and Michael Kasper. 2024. Demo: CARLA-based Adversarial Attack Assessment on Autonomous Vehicles. InProceedings of the Symposium on Vehicle Security and Privacy (VehicleSec)
2024
-
[34]
Mark Lee and Zico Kolter. 2019. On physical adversarial patches for object detection.arXiv preprint arXiv:1906.11897(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[35]
Simin Li, Shuing Zhang, Gujun Chen, Dong Wang, Pu Feng, Jiakai Wang, Aishan Liu, Xin Yi, and Xianglong Liu. 2023. Towards Benchmarking and Assessing Visual Naturalness of Physical World Adversarial Attacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12324–12333
2023
-
[36]
Xin Liu, Huanrui Yang, Ziwei Liu, Linghao Song, Hai Li, and Yiran Chen
-
[37]
Dpatch: An adversarial patch attack on object detectors.arXiv preprint arXiv:1806.02299(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. 2022. A ConvNet for the 2020s.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2022)
2022
-
[39]
Tianrui Lou, Xiaojun Jia, Siyuan Liang, Jiawei Liang, Ming Zhang, Yanjun Xiao, and Xiaochun Cao. 2025. 3D Gaussian Splatting Driven Multi-View Robust Physical Adversarial Camouflage Generation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 28752–28762
2025
-
[40]
Giulio Lovisotto, Henry Turner, Ivo Sluganovic, Martin Strohmeier, and Ivan Martinovic. 2021. {SLAP}: Improving physical adversarial examples with{Short- Lived} adversarial perturbations. In30th USENIX Security Symposium (USENIX Security 21). 1865–1882
2021
-
[41]
Wenyu Lv, Yian Zhao, Qinyao Chang, Kui Huang, Guanzhong Wang, and Yi Liu
- [42]
-
[43]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. InInternational Conference on Learning Representations
2018
-
[44]
Lingzhuang Meng, Mingwen Shao, Yuanjian Qiao, Wenjie Liu, and Xiang Lv. 2025. Gaussian splitting attack: Gaussian splatting-based multi-view 3D adversarial attack.Pattern Recognition(2025), 112466
2025
-
[45]
Ben Mildenhall, Pratul P Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalan- tari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar. 2019. Local light field fusion: Practical view synthesis with prescriptive sampling guidelines.ACM Transactions on Graphics (ToG)38, 4 (2019), 1–14
2019
-
[46]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis.Commun. ACM65, 1 (2021), 99–106
2021
-
[47]
Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. In- stant neural graphics primitives with a multiresolution hash encoding.ACM transactions on graphics (TOG)41, 4 (2022), 1–15
2022
-
[48]
Demin Nalic, Tomislav Mihalj, Maximilian Bäumler, Matthias Lehmann, Arno Eichberger, and Stefan Bernsteiner. 2020. Scenario based testing of automated driving systems: A literature survey. InProceedings of the FISITA web Congress, Vol. 10
2020
-
[49]
Ben Nassi, Yisroel Mirsky, Dudi Nassi, Raz Ben-Netanel, Oleg Drokin, and Yuval Elovici. 2020. Phantom of the adas: Securing advanced driver-assistance systems from split-second phantom attacks. InProceedings of the 2020 ACM SIGSAC conference on computer and communications security. 293–308
2020
-
[50]
Federico Nesti, Giulio Rossolini, Gianluca D’Amico, Alessandro Biondi, and Giorgio Buttazzo. 2024. CARLA-GeAR: A Dataset Generator for a Systematic Evaluation of Adversarial Robustness of Vision Models.IEEE Transactions on AdvScene Intelligent Transportation Systems25, 8 (2024), 9840–9851
2024
-
[51]
Federico Nesti, Giulio Rossolini, Saasha Nair, Alessandro Biondi, and Giorgio Buttazzo. 2022. Evaluating the Robustness of Semantic Segmentation for Au- tonomous Driving Against Real-World Adversarial Patch Attacks. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2280–2289
2022
-
[52]
Christian Neurohr, Lukas Westhofen, Tabea Henning, Thies De Graaff, Eike Möhlmann, and Eckard Böde. 2020. Fundamental considerations around scenario- based testing for automated driving. In2020 IEEE intelligent vehicles symposium (IV). IEEE, 121–127
2020
-
[53]
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. 2021. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision. 10901–10911
2021
-
[54]
Johannes L Schonberger and Jan-Michael Frahm. 2016. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition. 4104–4113
2016
-
[55]
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys
-
[56]
InEuropean conference on computer vision
Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision. Springer, 501–518
-
[57]
Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer, and Michael K Reiter. 2016. Ac- cessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. InProceedings of the 2016 acm sigsac conference on computer and communications security. 1528–1540
2016
-
[58]
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. 2020. Scalability in Perc...
2020
-
[59]
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2013. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[60]
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. 2023. Dream- gaussian: Generative gaussian splatting for efficient 3d content creation.arXiv preprint arXiv:2309.16653(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Simen Thys, Wiebe Van Ranst, and Toon Goedemé. 2019. Fooling Automated Surveillance Cameras: Adversarial Patches to Attack Person Detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 49–55
2019
-
[62]
Junjie Wang, Jiemin Fang, Xiaopeng Zhang, Lingxi Xie, and Qi Tian. 2024. Gaus- sianeditor: Editing 3d gaussians delicately with text instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20902–20911
2024
-
[63]
Tong Wu, Yu-Jie Yuan, Ling-Xiao Zhang, Jie Yang, Yan-Pei Cao, Ling-Qi Yan, and Lin Gao. 2024. Recent advances in 3d gaussian splatting.Computational Visual Media10, 4 (2024), 613–642
2024
-
[64]
Chaowei Xiao, Dawei Yang, Bo Li, Jia Deng, and Mingyan Liu. 2019. Meshadv: Ad- versarial meshes for visual recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6898–6907
2019
-
[65]
Hanyuan Xiao, Yingshu Chen, Huajian Huang, Haolin Xiong, Jing Yang, Pra- tusha Prasad, and Yajie Zhao. 2025. Localized Gaussian Splatting Editing with Contextual Awareness. InProceedings of the Winter Conference on Applications of Computer Vision. 5207–5217
2025
-
[66]
Kaidi Xu, Gaoyuan Zhang, Sijia Liu, Quanfu Fan, Mengshu Sun, Hongge Chen, Pin-Yu Chen, Yanzhi Wang, and Xue Lin. 2020. Adversarial T-Shirt! Evading Person Detectors in a Physical World. InComputer Vision – ECCV 2020. 665–681
2020
-
[67]
Xiaoyong Yuan, Pan He, Qile Zhu, and Xiaolin Li. 2019. Adversarial examples: Attacks and defenses for deep learning.IEEE transactions on neural networks and learning systems30, 9 (2019), 2805–2824
2019
-
[68]
Shibo Zhang, Yushi Cheng, Wenjun Zhu, Xiaoyu Ji, and Wenyuan Xu. 2023. {CAPatch}: Physical Adversarial Patch against Image Captioning Systems. In 32nd USENIX Security Symposium (USENIX Security 23). 679–696
2023
- [69]
- [70]
-
[71]
Wenjun Zhu, Xiaoyu Ji, Yushi Cheng, Shibo Zhang, and Wenyuan Xu. 2023. TPatch: A Triggered Physical Adversarial Patch. In32nd USENIX Security Sym- posium. 661–678. A Related Work A.1 Physical Adversarial Attacks Physical adversarial attacks aim to generate perturbations that re- main effective after real-world capture. Early studies showed that adversaria...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.