Speculative Decoding Across Languages
Pith reviewed 2026-06-29 07:13 UTC · model grok-4.3
The pith
N-gram draft models deliver larger speed-ups for speculative decoding in non-English languages than finetuned small models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
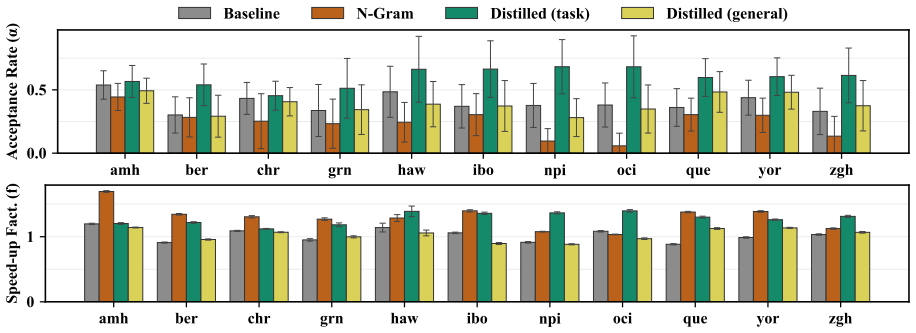
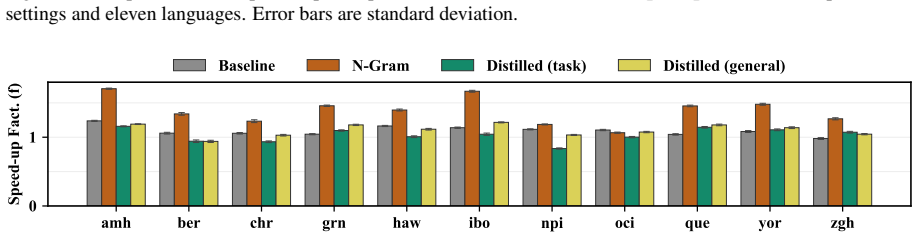
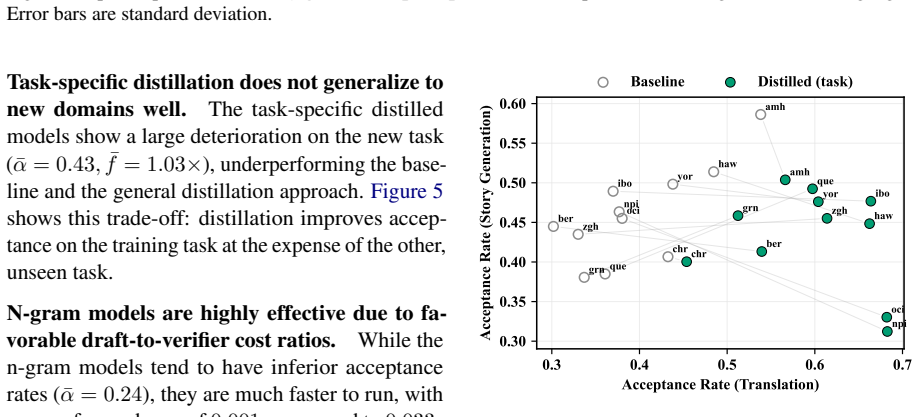
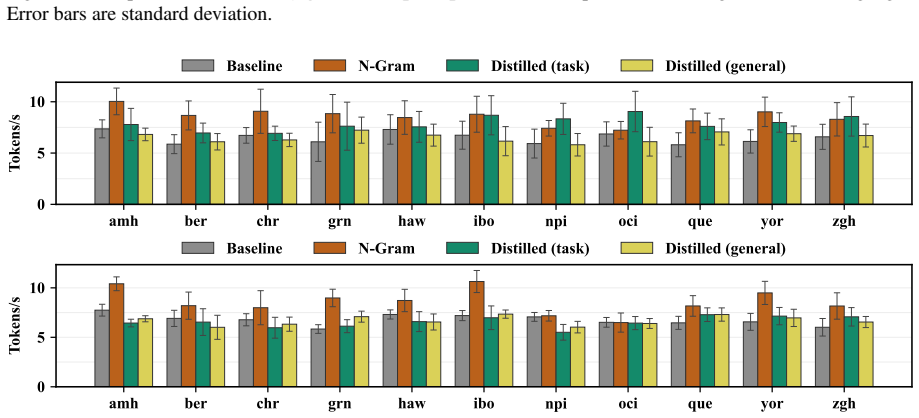
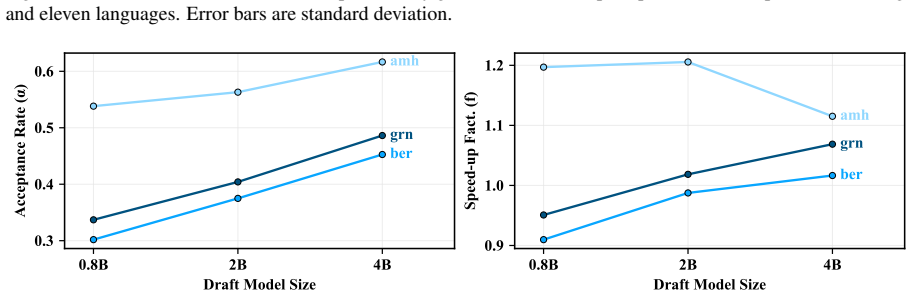
While task-specific distillation can significantly improve efficiency, distilled models generalize poorly to a new task. Meanwhile, n-gram draft models, despite lower acceptance rates, consistently provide large speed-ups due to much faster draft generation.
What carries the argument
n-gram draft models trained on monolingual corpora, which trade lower acceptance rates for substantially faster draft generation in the speculative decoding process.
If this is right
- Speculative decoding can be made effective for multilingual generation using lightweight n-gram models instead of neural ones.
- Training on unlabeled monolingual data suffices for draft models without needing task-specific parallel data.
- Efficiency gains hold across both translation and unrelated tasks like story generation.
- Overall latency depends more on draft generation speed than on the rate of accepted tokens.
Where Pith is reading between the lines
- Similar n-gram approaches might help in other domains where small models lack training data, such as low-resource languages.
- Combining n-gram drafts with occasional neural drafts could balance speed and quality.
- The findings suggest that for many inference optimizations, simpler statistical models may outperform complex neural ones when generation cost is the bottleneck.
Load-bearing premise
Draft generation time with the n-gram model is the main contributor to total latency and the models do not suffer from domain mismatch on the story generation task.
What would settle it
Running the story generation task with the n-gram draft model and finding that total time is not reduced compared to standard decoding or the finetuned model.
Figures




read the original abstract
Speculative decoding has become a crucial component of large language model (LLM) inference, enabling faster generation by drafting multiple tokens and verifying them in parallel. However, small draft models tend to suffer from disproportionately poor multilingual capabilities. Thus, when generating text in a non-English language, speculative decoding is far less effective. We compare three strategies to improve speculative decoding efficiency for eleven languages: finetuning the draft model on task-specific data (translation); finetuning the draft model on unlabeled monolingual corpora; and training simple n-gram draft models on the same monolingual corpora. We evaluate efficiency on translation (from English into the target language) and the held-out task of story generation. We find that while task-specific distillation can significantly improve efficiency, distilled models generalize poorly to a new task. Meanwhile, n-gram draft models, despite lower acceptance rates, consistently provide large speed-ups due to much faster draft generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares three approaches to improve speculative decoding for 11 languages: task-specific finetuning of draft models on translation data, finetuning on monolingual corpora, and training n-gram draft models on the same corpora. It evaluates these on English-to-target translation and the held-out story generation task, claiming that while task-specific models improve efficiency on their training task but generalize poorly, n-gram models deliver consistent large speed-ups on both tasks despite lower acceptance rates, owing to substantially faster draft generation.
Significance. If the reported speed-ups hold under the measured acceptance rates, the work offers a practical, low-resource method for multilingual speculative decoding that avoids the need for capable small draft models or task-specific data collection. The direct empirical evaluation on a held-out task (story generation) provides a concrete test of generalization and addresses potential domain mismatch between training corpora and evaluation prompts. The concrete reporting of acceptance rates and latency measurements across languages and tasks is a strength.
minor comments (2)
- [Abstract] Abstract: The abstract states that n-gram models 'consistently provide large speed-ups' on both tasks but supplies no numerical values for acceptance rates, speed-up factors, or controls; adding these would strengthen the summary of the central empirical claim.
- [Methods or Experiments] The manuscript would benefit from a brief discussion of how the monolingual corpora were selected and any steps taken to mitigate domain shift relative to the story-generation prompts, even if the held-out results already demonstrate net gains.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical value of n-gram draft models for multilingual speculative decoding, and the recommendation for minor revision. The emphasis on consistent speed-ups despite lower acceptance rates, faster draft generation, and the held-out story generation evaluation aligns with our core claims. No major comments were raised in the report.
Circularity Check
No circularity: purely empirical evaluation with direct measurements
full rationale
The paper reports an empirical study comparing three draft-model strategies for speculative decoding on eleven languages. All reported outcomes (acceptance rates, speed-ups) are measured directly on held-out translation and story-generation tasks after training n-gram models or fine-tuning on the stated corpora. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim reduces to observable latency differences rather than any self-referential construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Esther Awokoya, and Cristina Espa \ n a-Bonet
David Ifeoluwa Adelani, Dana Ruiter, Jesujoba O. Alabi, Damilola Adebonojo, Adesina Ayeni, Mofe Adeyemi, Ayodele Esther Awokoya, and Cristina Espa \ n a-Bonet. 2021. https://aclanthology.org/2021.mtsummit-research.6/ The effect of domain and diacritics in Y oruba -- E nglish neural machine translation . In Proceedings of Machine Translation Summit XVIII: ...
2021
-
[2]
Damian Blasi, Antonios Anastasopoulos, and Graham Neubig. 2022. https://doi.org/10.18653/v1/2022.acl-long.376 Systematic inequalities in language technology performance across the world ' s languages . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5486--5505, Dublin, Ireland. Asso...
-
[3]
Marc Brysbaert, Amy Beth Warriner, and Victor Kuperman. 2014. Concreteness ratings for 40 thousand generally known english word lemmas. Behavior research methods, 46(3):904--911
2014
-
[4]
Chang, Catherine Arnett, Zhuowen Tu, and Ben Bergen
Tyler A. Chang, Catherine Arnett, Zhuowen Tu, and Ben Bergen. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.236 When is multilinguality a curse? language modeling for 250 high- and low-resource languages . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4074--4096, Miami, Florida, USA. Association for C...
-
[5]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. https://arxiv.org/abs/2302.01318 Accelerating large language model decoding with speculative sampling . Preprint, arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. https://doi.org/10.18653/v1/2020.acl-main.747 Unsupervised cross-lingual representation learning at scale . In Proceedings of the 58th Annual Meeting of the Association for Comp...
-
[7]
Sayantan Dasgupta, Timothy Baldwin, and Trevor Cohn. 2026. https://openreview.net/forum?id=EYflZV1caL Don't ignore the tail: Decoupling top-\ k\ probabilities for efficient language model distillation
2026
-
[8]
Liam Doherty. 2016. https://dohliam.github.io/corpus/haw/ The hawaiian corpus project: Data from a corpus of written hawaiian
2016
-
[9]
Abteen Ebrahimi, Ona de Gibert, Raul Vazquez, Rolando Coto-Solano, Pavel Denisov, Robert Pugh, Manuel Mager, Arturo Oncevay, Luis Chiruzzo, Katharina von der Wense, and Shruti Rijhwani. 2024. https://doi.org/10.18653/v1/2024.americasnlp-1.28 Findings of the A mericas NLP 2024 shared task on machine translation into indigenous languages . In Proceedings of...
-
[10]
W Nelson Francis. 1979. Brown corpus manual. http://icame. uib. no/brown/bcm. html
1979
-
[11]
Dirk Goldhahn, Thomas Eckart, and Uwe Quasthoff. 2012. https://aclanthology.org/L12-1154/ Building large monolingual dictionaries at the L eipzig corpora collection: From 100 to 200 languages . In Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12) , pages 759--765, Istanbul, Turkey. European Language Resour...
2012
-
[12]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. https://arxiv.org/abs/1503.02531 Distilling the knowledge in a neural network . Preprint, arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
IRCA . 2015. https://tal.ircam.ma/talam/corpus.php Talam (traitement automatique de la langue amazighe)
2015
-
[14]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. https://arxiv.org/abs/2211.17192 Fast inference from transformers via speculative decoding . Preprint, arXiv:2211.17192
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
https://cherokeedictionary.net/ [link]
Tim Nuttle, Tim Orr, TommyLee Whitlock, and Sarah Orndorff. https://cherokeedictionary.net/ [link]
-
[16]
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. https://doi.org/10.3115/v1/D14-1162 G lo V e: Global vectors for word representation . In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 1532--1543, Doha, Qatar. Association for Computational Linguistics
-
[17]
Aleksandar Petrov, Emanuele La Malfa, Philip Torr, and Adel Bibi. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/74bb24dca8334adce292883b4b651eda-Paper-Conference.pdf Language model tokenizers introduce unfairness between languages . In Advances in Neural Information Processing Systems, volume 36, pages 36963--36990. Curran Associates, Inc
2023
- [18]
- [19]
-
[20]
Shivalika Singh, Freddie Vargus, Daniel D ' souza, B \"o rje F. Karlsson, Abinaya Mahendiran, Wei-Yin Ko, Herumb Shandilya, Jay Patel, Deividas Mataciunas, Laura O ' Mahony, Mike Zhang, Ramith Hettiarachchi, Joseph Wilson, Marina Machado, Luisa Moura, Dominik Krzemi \'n ski, Hakimeh Fadaei, Irem Ergun, Ifeoma Okoh, and 14 others. 2024. https://doi.org/10....
-
[21]
Qwen Team. 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5: Accelerating productivity with native multimodal agents
2026
-
[22]
Prajwal Thapa, Jinu Nyachhyon, Mridul Sharma, and Bal Krishna Bal. 2025. https://aclanthology.org/2025.chipsal-1.2/ Development of pre-trained transformer-based models for the N epali language . In Proceedings of the First Workshop on Challenges in Processing South Asian Languages (CHiPSAL 2025), pages 9--16, Abu Dhabi, UAE. International Committee on Com...
2025
-
[23]
J \"o rg Tiedemann. 2012. https://aclanthology.org/L12-1246/ Parallel data, tools and interfaces in OPUS . In Proceedings of the Eighth International Conference on Language Resources and Evaluation ( LREC '12) , pages 2214--2218, Istanbul, Turkey. European Language Resources Association (ELRA)
2012
-
[24]
J \"o rg Tiedemann. 2020. https://aclanthology.org/2020.wmt-1.139/ The tatoeba translation challenge -- realistic data sets for low resource and multilingual MT . In Proceedings of the Fifth Conference on Machine Translation, pages 1174--1182, Online. Association for Computational Linguistics
2020
-
[25]
Heming Xia, Tao Ge, Peiyi Wang, Si-Qing Chen, Furu Wei, and Zhifang Sui. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.257 Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3909--3925, Singapore. Association for Computational ...
-
[26]
Euiin Yi, Taehyeon Kim, Hongseok Jeung, Du-Seong Chang, and Se-Young Yun. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.602 Towards fast multilingual LLM inference: Speculative decoding and specialized drafters . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10789--10802, Miami, Florida, USA. Associat...
- [27]
-
[28]
Rodolfo Zevallos, John Ortega, William Chen, Richard Castro, N \'u ria Bel, Cesar Yoshikawa, Renzo Venturas, Hilario Aradiel, and Nelsi Melgarejo. 2022. https://doi.org/10.18653/v1/2022.deeplo-1.1 Introducing Q u BERT : A large monolingual corpus and BERT model for S outhern Q uechua . In Proceedings of the Third Workshop on Deep Learning for Low-Resource...
-
[29]
Biao Zhang, Philip Williams, Ivan Titov, and Rico Sennrich. 2020 a . https://doi.org/10.18653/v1/2020.acl-main.148 Improving massively multilingual neural machine translation and zero-shot translation . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1628--1639, Online. Association for Computational Linguistics
-
[30]
Shiyue Zhang, Benjamin Frey, and Mohit Bansal. 2020 b . https://doi.org/10.18653/v1/2020.emnlp-main.43 C hr E n: C herokee- E nglish machine translation for endangered language revitalization . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 577--595, Online. Association for Computational Linguistics
-
[31]
Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Rostamizadeh, Sanjiv Kumar, Jean-Fran c ois Kagy, and Rishabh Agarwal. 2024. https://openreview.net/forum?id=rsY6J3ZaTF Distillspec: Improving speculative decoding via knowledge distillation . In The Twelfth International Conference on Learning Representations
2024
-
[32]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[33]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.