AMNESIA: A Large Scale Medical Unlearning Benchmark Suite with Disease-Informed Analysis
Pith reviewed 2026-06-29 08:13 UTC · model grok-4.3
The pith
Unlearning one patient's medical data erodes a model's knowledge of other patients sharing the same disease.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
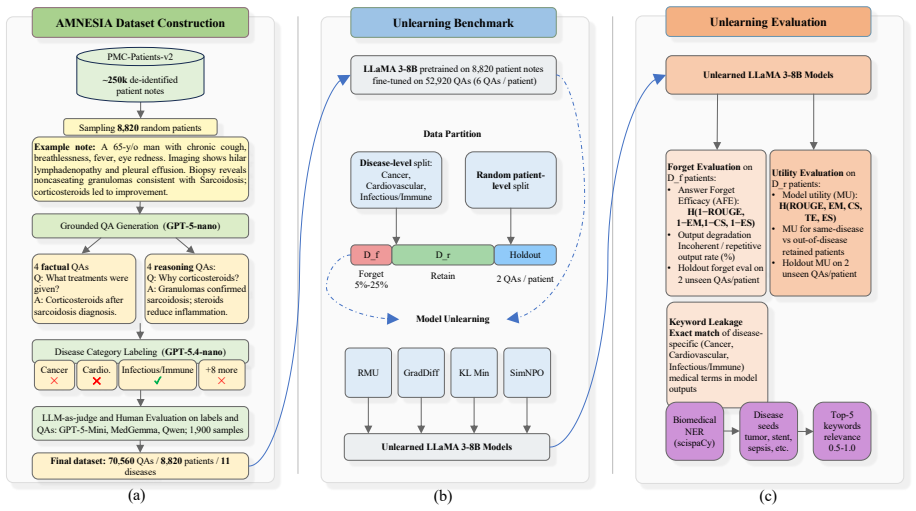
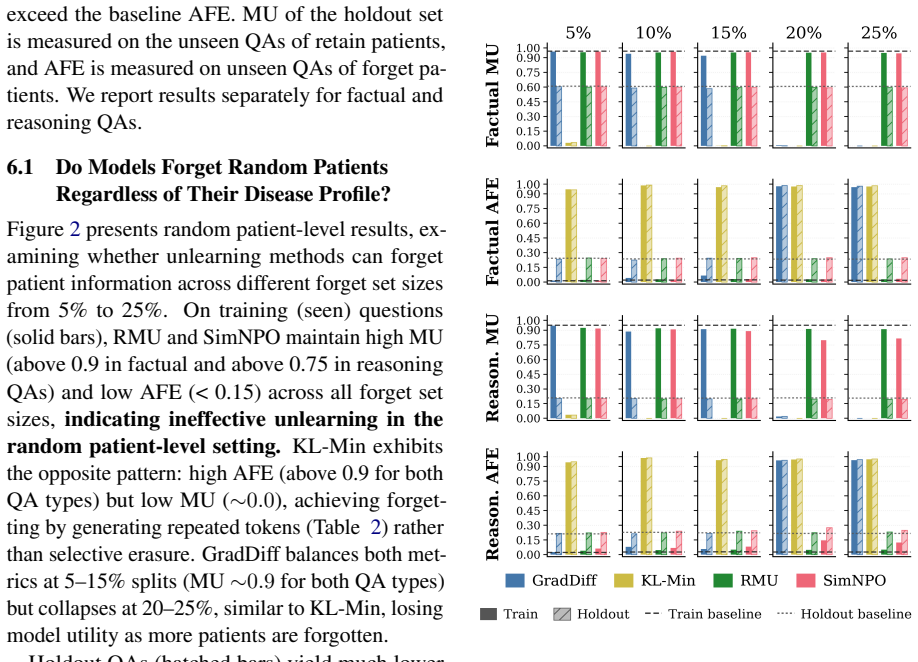
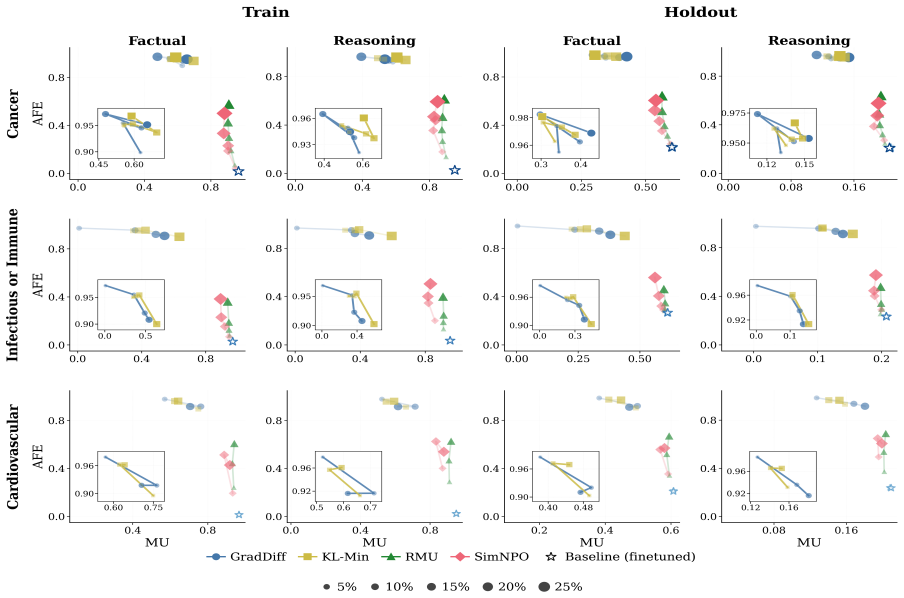
AMNESIA shows that unlearning individual patients erodes knowledge of others with the same condition. The benchmark supplies 70,560 factual and reasoning QA pairs from 8,820 patient notes in 11 disease categories. When four common unlearning methods are applied at the patient level, performance on same-disease cases declines; disease-level unlearning produces different leakage patterns. A new terminology-leakage metric quantifies how medical terms remain accessible after unlearning. These results establish that patient-specific facts and shared clinical knowledge are entangled in trained models and that existing methods do not respect this entanglement.
What carries the argument
The AMNESIA benchmark suite, which organizes large-scale QA pairs by disease category to expose interference between patient-specific facts and shared clinical knowledge during unlearning.
If this is right
- Unlearning methods must be tested at both random-patient and disease-group scales to detect cross-patient interference.
- Medical unlearning requires explicit mechanisms to isolate individual records from condition-level clinical patterns.
- A terminology-leakage metric provides a practical way to measure whether shared medical vocabulary survives unlearning.
- Factual recall and clinical-reasoning questions both reveal the same erosion pattern, indicating the problem is not limited to rote memorization.
Where Pith is reading between the lines
- Benchmarks that separate individual and categorical knowledge may be needed in other regulated domains such as legal or financial records.
- Training regimes that tag disease-level versus patient-level information at the data stage could reduce the interference observed here.
- Regulatory requirements to remove patient data may force periodic re-evaluation of model performance on related conditions.
Load-bearing premise
The constructed QA pairs and disease categories sufficiently capture the distinction between patient-specific facts and shared clinical knowledge that unlearning methods must respect.
What would settle it
A result in which unlearning one patient's records leaves model accuracy on other patients with the same disease completely unchanged would falsify the central claim.
Figures

read the original abstract
Medical knowledge is continuously evolving. This creates a need to update or selectively forget information encoded in already-trained medical LLMs. Machine unlearning aims to remove the influence of specific training data from a model without full retraining. Yet, existing unlearning benchmarks rely on synthetic or small-scale general data, leaving clinical unlearning understudied. We introduce AMNESIA, the first large-scale, open source benchmark for medical unlearning, with 70,560 question-answer pairs from 8,820 patient notes across 11 disease categories. AMNESIA includes both factual questions testing direct recall and reasoning questions testing clinical inference. We use it to evaluate four widely used unlearning methods at both random patient and disease-level, and introduce a new metric for detecting leakage of medical terminology. We show that unlearning individual patients erodes knowledge of others with the same condition, calling for methods that can better separate patients from shared clinical knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AMNESIA, the first large-scale open-source benchmark for medical unlearning, with 70,560 QA pairs derived from 8,820 patient notes across 11 disease categories. It includes both factual recall and clinical reasoning questions, evaluates four standard unlearning methods at the individual-patient and disease levels, proposes a new metric for medical terminology leakage, and reports that patient-level unlearning degrades performance on other patients sharing the same disease.
Significance. If the erosion result is robust, the benchmark is significant because it supplies a clinically grounded testbed that existing synthetic or small-scale unlearning suites lack. The scale, the split between factual and reasoning questions, the disease-informed grouping, and the open release constitute concrete strengths that can drive development of methods able to separate patient-specific facts from shared clinical knowledge. The terminology-leakage metric is a useful addition for evaluation in the medical domain.
major comments (2)
- [Benchmark Construction] Benchmark Construction section: the central claim that unlearning one patient erodes performance on others with the same condition rests on the assumption that the QA pairs and 11 disease categories cleanly separate patient-specific facts from shared clinical knowledge. The manuscript supplies no explicit construction protocol, examples of how factual versus reasoning questions were authored, or validation that the groupings achieve this separation; without these details the erosion pattern cannot be interpreted as evidence for the claimed limitation of current methods.
- [Evaluation] Evaluation section: the reported erosion finding is presented without statistical significance tests, confidence intervals, or ablation on the choice of disease groupings; because the claim is quantitative and load-bearing for the call for new methods, the absence of these controls weakens the evidential basis.
minor comments (2)
- [Abstract] The abstract and title both use 'disease-informed analysis' but the manuscript should add a short paragraph clarifying how the 11 categories were chosen and whether they were validated by clinicians.
- Figure captions should explicitly state which unlearning method and which metric (including the new leakage metric) are plotted in each panel.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of AMNESIA. We address each major comment below and describe the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: the central claim that unlearning one patient erodes performance on others with the same condition rests on the assumption that the QA pairs and 11 disease categories cleanly separate patient-specific facts from shared clinical knowledge. The manuscript supplies no explicit construction protocol, examples of how factual versus reasoning questions were authored, or validation that the groupings achieve this separation; without these details the erosion pattern cannot be interpreted as evidence for the claimed limitation of current methods.
Authors: We agree that greater transparency on construction is needed to support interpretation of the erosion results. The current manuscript describes the high-level process (extraction from 8,820 notes into 70,560 QA pairs across 11 ICD-10-aligned categories, with factual items drawn directly from notes and reasoning items derived from clinical guidelines), but does not provide the full protocol, sample pairs, or expert validation steps. In the revision we will add an explicit construction protocol subsection, representative examples of both factual and reasoning questions per disease, and a description of the medical-expert review used to confirm separation of patient-specific versus shared knowledge. These additions will allow readers to assess whether the observed erosion indeed indicates limitations in separating patient facts from disease-level knowledge. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported erosion finding is presented without statistical significance tests, confidence intervals, or ablation on the choice of disease groupings; because the claim is quantitative and load-bearing for the call for new methods, the absence of these controls weakens the evidential basis.
Authors: We concur that quantitative claims require statistical controls. The revision will include paired t-tests with p-values and 95% confidence intervals on the performance drops after patient-level unlearning, plus an ablation that varies the disease groupings (e.g., coarser vs. finer partitions) to test robustness of the erosion pattern. These analyses will be reported in the updated Evaluation section and will strengthen the evidential basis for recommending new methods that better isolate patient-specific information. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark introduction that constructs a dataset of QA pairs from patient notes and evaluates existing unlearning methods on it; no derivations, equations, fitted parameters, or self-citational load-bearing steps are present that reduce any claim to its own inputs by construction. The reported pattern (erosion of related-patient knowledge) follows directly from the benchmark design once the groupings are accepted, with no internal reduction or renaming of results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceed- ings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, pages 237–247, Toronto, Canada
Multiple evidence combination for fact- checking of health-related information. InProceed- ings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, pages 237–247, Toronto, Canada. Association for Computational Linguistics. Vineeth Dorna, Anmol Reddy Mekala, Wenlong Zhao, Andrew McCallum, J Zico Kolter, Zachary Chase Lip...
2026
-
[2]
Scientific Data, 6
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data, 6. 9 Yunsoo Kim, Yusuf Abdulle, and Honghan Wu. 2025. BioHopR: A benchmark for multi-hop, multi-answer reasoning in biomedical domain. InFindings of the Association for Computational Linguistics: ACL 2025, pages 12894–12908, Vienna, Austria...
2025
-
[3]
MedHallu: A comprehensive benchmark for detecting medical hallucinations in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2858–2873, Suzhou, China. Association for Computational Linguistics. Protection Regulation. 2016. Regulation (eu) 2016/679 of the european parliament and of the c...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
MUSE: Machine unlearning six-way evalua- tion for language models. InThe Thirteenth Interna- tional Conference on Learning Representations. Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 oth- ers. 2025. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Sangyeon Yoon, Wonje Jeung, and Albert No. 2025. R- TOFU: Unlearning in large reasoning models. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 5239– 5258, Suzhou, China. Association for Computational Linguistics. Ruiqi Zhang, Licong Lin, Yu Bai, an...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Anemia or Iron Deficiency
-
[7]
Arthritis and Bone • Arthritis • Osteoporosis
-
[8]
Cardiovascular • Cerebrovascular Disease or Stroke • Cholesterol • Heart Disease • Hypertension
-
[9]
Dementia and Mental Health • Alzheimer’s Disease • Attention Deficit Hyperactivity Disorder • Depression • Mental Health
-
[10]
Digestive and Liver • Digestive Diseases • Chronic Liver Disease and Cirrhosis
-
[11]
Infectious or Immune Diseases • AIDS and HIV • Viral Hepatitis • Infectious Disease • Influenza • Measles, Mumps, and Rubella • Pneumonia • Sexually Transmitted Diseases (STD) • Chronic Sinusitis • Whooping Cough or Pertussis
-
[12]
Oral and Dental Health
-
[13]
Other” and explain briefly. Return valid JSON only in this exact format: {
Respiratory and Allergies • Allergies and Hay Fever • Asthma • Chronic Obstructive Pulmonary Disease Rules: • Return the best matching top-level category only. • Base the decision mainly on the article_title. • Use the subcategories only as guidance for mapping into the correct top-level category. • Do not use any category outside the taxonomy. • If no ca...
-
[14]
factual_items • direct recall from the summary • answerable solely from the provided summary • answers must be 1–2 sentences • cover diagnosis, symptoms, labs, treatments, out- comes
-
[15]
% # Patients # QAs Available For Forget Splits 5 441 2,646 Random, Cancer, Inf/Imm., Cardio
reasoning_items • multi-hop clinical reasoning • each question MUST connect at least TWO findings from the summary • answers should explain the reasoning chain in 2–3 11 sentences Global rules: • Do NOT ask about patient name, age, gender, or any PII • Questions must REQUIRE this specific patient’s details and must NOT be answered confidently from general...
2048
-
[16]
Named entities identified by the biomedical en- tity recognizer
-
[17]
Noun chunks from the dependency parser
-
[18]
lung cancer
Filtering: remove common clinical terms, phrases<3 characters, and phrases>6 words Relevance ScoringEach candidate phrase re- ceives a lexical disease relevance score based on its overlap with seed terms: •Exact match:score = 1.0 • Multi-word phrase containment:score = 0.9 (e.g., “lung cancer” contains seed “lung cancer”) • Partial word overlap:score = 0....
2025
-
[19]
What is the primary medical topic of this title?
-
[20]
Which of the three categories does it best fit?
-
[21]
reasoning
Does the assigned category match? Respond ONLY with this JSON (no markdown, no extra text): { "reasoning": "<1-2 sentence explanation>", "verdict": "<Supported | Unsupported | Ambiguous>", "correct_category": "<Cardiovascular | Cancer | Infec- tious or Immune Diseases | Unclear>" } F.2 Panel Results on 900 Titles The panel evaluated all 900 sampled patien...
-
[22]
The question is clear and well-formed
-
[23]
The answer is correct based on the patient note
-
[24]
The answer can be derived from the information in the patient note
-
[25]
valid": true/false,
The question and answer are clinically meaningful Provide your evaluation in JSON format: { "valid": true/false, "reasoning": "Brief explanation of your decision (2-3 sentences)" } Be strict in your evaluation. If ANY criterion is not met, mark as invalid. G.2 Panel Results Table 12 summarizes verdicts at the judge and panel level over the N= 1,000 triple...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.