Bridging the Gap Between Natural Language and Market Dynamics via High-Dimensional Representation Learning
Pith reviewed 2026-06-29 08:11 UTC · model grok-4.3
The pith
Siamese-optimized FinBERT embeddings improve short-term stock price prediction accuracy over scalar sentiment scores by retaining narrative context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing discrete polarity ratings with dense FinBERT embeddings inside a Transformer-based forecasting architecture, and especially optimizing those embeddings with a Siamese network, yields higher accuracy for short-term stock price movements on the FNSPID dataset than either a scalar sentiment baseline or raw embeddings, because the high-dimensional narrative context is preserved.
What carries the argument
Siamese-optimized FinBERT embeddings fed into a Transformer forecasting model, which replace scalar polarity scores while keeping the full high-dimensional structure of the news text.
If this is right
- Siamese-optimized embeddings outperform both scalar baselines and raw embeddings for short-term price movement prediction.
- Attention-weighted aggregation of embeddings fails to improve results because financial data has low signal-to-noise ratio.
- Preserving high-dimensional narrative context from news produces measurable gains in predictive accuracy.
- Transformer architectures for multi-modal financial forecasting benefit when text is kept in dense form rather than reduced to scalars.
Where Pith is reading between the lines
- The same embedding strategy could be tested on other text-rich forecasting tasks such as earnings surprises or macroeconomic releases.
- If the Siamese network is replaced by another contrastive objective, the performance edge might persist or change depending on how the narrative similarity is defined.
- Extending the approach to longer prediction horizons would show whether the narrative signal remains useful beyond short-term windows.
Load-bearing premise
The accuracy gains on the FNSPID dataset come specifically from the high-dimensional narrative preservation and not from differences in model capacity, training procedure, or dataset noise between the scalar and embedding pipelines.
What would settle it
A re-run on the FNSPID dataset that matches model size, training steps, and data splits exactly between the scalar baseline and the Siamese embedding pipeline and finds no accuracy difference would falsify the claim.
Figures



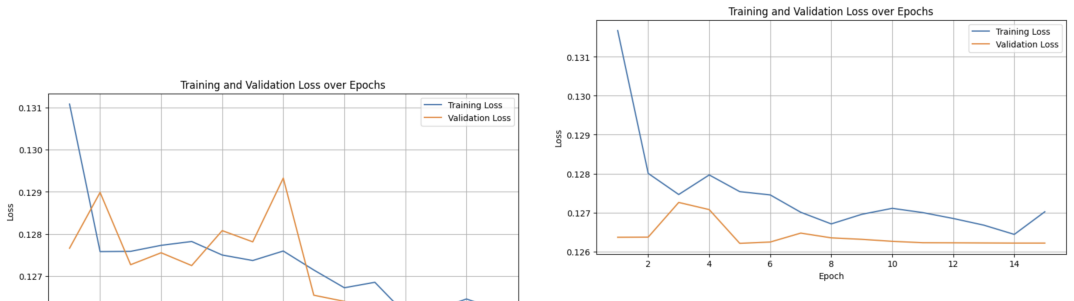
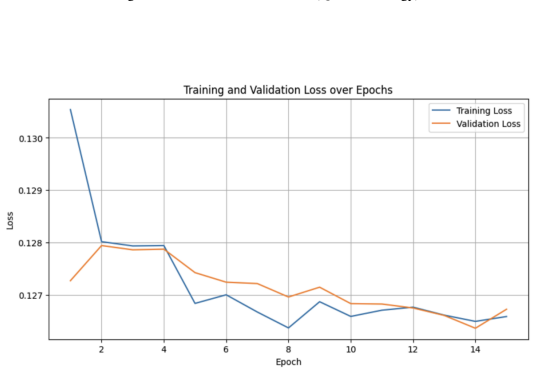
read the original abstract
Traditional multi-modal financial forecasting often relies on scalar sentiment scores, which fail to capture the nuances of financial news. To address this information loss, this paper explores high-dimensional representation learning by replacing discrete polarity ratings with dense FinBERT embeddings within a Transformer-based forecasting architecture. We benchmarked various embedding strategies on the FNSPID dataset, including raw embeddings, attention-weighted aggregation, and a custom Siamese network. While the attention-based mechanism struggled with the low signal-to-noise ratio typical of financial data, the integration of Siamese-optimized embeddings outperformed both the scalar baseline and raw embedding approaches, demonstrating that preserving high-dimensional narrative context yields improved predictive accuracy for short-term stock price movements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that replacing scalar sentiment scores with high-dimensional FinBERT embeddings in a Transformer-based forecasting model improves short-term stock price prediction on the FNSPID dataset. It benchmarks raw embeddings, attention-weighted aggregation, and a custom Siamese network, reporting that Siamese-optimized embeddings outperform both the scalar baseline and raw embeddings by preserving narrative context.
Significance. If the performance gains can be isolated to high-dimensional context preservation under matched controls, the result would provide concrete evidence that dense embeddings capture useful signal beyond scalar polarity in noisy financial text, strengthening multimodal forecasting pipelines. The use of a public dataset is a positive for reproducibility, but the current presentation leaves the attribution insecure.
major comments (2)
- [Abstract] Abstract: the statement that Siamese-optimized embeddings 'outperformed both the scalar baseline and raw embedding approaches' supplies no numerical metrics, error bars, statistical tests, data-split details, or hyperparameter controls, preventing verification that the reported gains are attributable to dimensionality rather than other factors.
- [Experiments] Experiments section (implied by benchmarking description): the Siamese pipeline necessarily introduces a contrastive loss and pairing mechanism that alters model capacity and optimization relative to the scalar and raw-embedding baselines; without explicit controls for parameter count, optimizer schedule, or training objective, the attribution of gains specifically to 'high-dimensional narrative preservation' cannot be isolated.
minor comments (1)
- [Abstract] Abstract: the claim that the attention-based mechanism 'struggled with the low signal-to-noise ratio' is stated without any supporting quantitative comparison or ablation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify areas where additional experimental controls and reporting are needed to strengthen attribution of results. We will revise the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that Siamese-optimized embeddings 'outperformed both the scalar baseline and raw embedding approaches' supplies no numerical metrics, error bars, statistical tests, data-split details, or hyperparameter controls, preventing verification that the reported gains are attributable to dimensionality rather than other factors.
Authors: We agree that the abstract statement lacks quantitative support. In the revision we will include specific metrics (e.g., MSE or accuracy deltas with error bars), reference to the data split, and mention of statistical testing. Full hyperparameter and split details will remain in the Experiments section, with the abstract updated to report the key numerical gains while respecting length limits. revision: yes
-
Referee: [Experiments] Experiments section (implied by benchmarking description): the Siamese pipeline necessarily introduces a contrastive loss and pairing mechanism that alters model capacity and optimization relative to the scalar and raw-embedding baselines; without explicit controls for parameter count, optimizer schedule, or training objective, the attribution of gains specifically to 'high-dimensional narrative preservation' cannot be isolated.
Authors: This point is valid. The contrastive objective and pairing do change the training dynamics relative to the scalar and raw-embedding baselines. We will revise the Experiments section to report parameter counts for all variants, document the shared optimizer schedule, and add an ablation that applies the same contrastive loss to the raw-embedding baseline. These additions will allow clearer isolation of the contribution from high-dimensional context preservation. revision: yes
Circularity Check
No circularity: empirical performance comparison on public dataset
full rationale
The paper reports an empirical benchmark of embedding strategies (raw FinBERT, attention-weighted, Siamese-optimized) against scalar baselines on the FNSPID dataset for short-term stock prediction. The central claim is a measured accuracy improvement; no equations, predictions, or first-principles derivations are presented that could reduce to fitted inputs or self-citations by construction. The abstract and described content contain no self-referential steps, uniqueness theorems, or ansatzes. The result is externally falsifiable via replication on the public dataset under controlled conditions, satisfying the criteria for a self-contained empirical finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- Siamese network parameters
axioms (1)
- domain assumption FinBERT embeddings preserve financially relevant narrative information beyond scalar polarity
Reference graph
Works this paper leans on
-
[1]
to the FNSPID dataset to set a new useful benchmark. Unlike generic models, FinBERT is pre-trained specifically on financial texts to better grasp domain-specific contexts. LSA employs singular value decomposition to extract semantically dense sentences, balancing input length against information-density. 3 Dataset and Features We used FNSPID [ 6], select...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Rising competition from TikTok, privacy policy changes from Apple, and the raging war
with FinBERT. For the scalar baseline, FinBERT probabilities (Ppos, Pneg, Pneu) were mapped to a discrete sentiment score S in [1, 5] using the formula: S= (P neg ×1.0) + (P neu ×3.0) + (P pos ×5.0)(1) Daily scores were computed by averaging all articles released on a given trading day. Data sparsity proved to be a challenge, with coverage of summaries fo...
2023
-
[3]
in-graph
did not disclose specific stock symbols or hyperparameters, we approxi- mated the experiment setup to generate comparable results. Consequently, our validation focused on matching relative performance trends rather than exact numerical values. While we observed the expected performance gains when adding FinBERT sentiment scores to the Transformer, the LST...
-
[4]
Github: github.com/hkmamike/market-encoder
-
[5]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiao- qiang Zheng
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiao- qiang Zheng. TensorFlow: A system for lar...
2016
-
[6]
Boto3: The AWS SDK for Python, 2023
Amazon Web Services. Boto3: The AWS SDK for Python, 2023
2023
-
[7]
ASNESS, TOBIAS J
CLIFFORD S. ASNESS, TOBIAS J. MOSKOWITZ, and LASSE HEJE PEDERSEN. Value and momentum everywhere.The Journal of Finance, 68(3):929–985, 2013
2013
-
[8]
AWS data wrangler, 2023
AWS Professional Services. AWS data wrangler, 2023
2023
-
[9]
Fnspid: A comprehensive financial news dataset in time series, 2024
Zihan Dong, Xinyu Fan, and Zhiyuan Peng. Fnspid: A comprehensive financial news dataset in time series, 2024
2024
-
[10]
Eugene F. Fama. Efficient capital markets: A review of theory and empirical work.The Journal of Finance, 25(2):383–417, 1970
1970
-
[11]
Generic text summarization using rele- vance measure and latent semantic analysis
Yihong Gong and Xin Liu. Generic text summarization using rele- vance measure and latent semantic analysis. InProceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval, pages 19–25, 2001
2001
-
[12]
Fine-tuning large language models for stock return prediction using newsflow, 2024
Tian Guo and Emmanuel Hauptmann. Fine-tuning large language models for stock return prediction using newsflow, 2024
2024
-
[13]
Harris, K
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Hal- dane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin She...
2020
-
[14]
Huang, Hui Wang, and Yi Yang
Allen H. Huang, Hui Wang, and Yi Yang. Finbert: A large language model for extracting information from financial text.Contemporary Accounting Research, 40(7):1588–1619, 2023
2023
-
[15]
John D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95, 2007
2007
-
[16]
Sarthak Jain and Byron C. Wallace. Attention is not explanation, 2019
2019
-
[17]
Predicting stock prices with finbert-lstm: Integrating news sentiment analysis
Wen jun Gu, Yi hao Zhong, Shi zun Li, Chang song Wei, Li ting Dong, Zhuo yue Wang, and Chao Yan. Predicting stock prices with finbert-lstm: Integrating news sentiment analysis. InProceedings of the 2024 8th International Conference on Cloud and Big Data Computing, ICCBDC 2024, page 67–72. ACM, August 2024
2024
-
[18]
Isolation forest
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining, pages 413–422. IEEE, 2008
2008
-
[19]
Data structures for statistical computing in Python
Wes McKinney. Data structures for statistical computing in Python. In Stéfan van der Walt and Jarrod Millman, editors,Proceedings of the 9th Python in Science Conference, pages 56–61, 2010
2010
-
[20]
DA VID McLEAN and JEFFREY PONTIFF
R. DA VID McLEAN and JEFFREY PONTIFF. Does academic re- search destroy stock return predictability?The Journal of Finance, 71(1):5–31, 2016
2016
-
[21]
PyTorch: An imperative style, high-performance deep learning li- brary
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-per...
2019
-
[22]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Van- derplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[23]
Financial sentiment analysis on news and reports using large language models and finbert
Yanxin Shen and Pulin Kirin Zhang. Financial sentiment analysis on news and reports using large language models and finbert. In2024 IEEE 6th International Conference on Power , Intelligent Computing and Systems (ICPICS), pages 717–721, 2024
2024
-
[24]
Con- trastive similarity learning for market forecasting: The contrasim framework, 2025
Nicholas Vinden, Raeid Saqur, Zining Zhu, and Frank Rudzicz. Con- trastive similarity learning for market forecasting: The contrasim framework, 2025
2025
-
[25]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art na...
2020
-
[26]
Differential transformer.arXiv preprint arXiv:2410.05258, 2024
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer.arXiv preprint arXiv:2410.05258, 2024. 9 Appendix Implementation Details The experimental framework was primarily implemented using Py- Torch [18] for deep learning model development, though initial comparative experiments were conducted using TensorFlow ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.