ConTrans: Learning Text-enhanced Local-global Temporal Representations for Zero-shot Temporal Action Localization
Pith reviewed 2026-06-28 23:25 UTC · model grok-4.3
The pith
ConTrans integrates convolutional biases with transformer self-attention in a multi-scale encoder to capture local and global video features for zero-shot temporal action localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
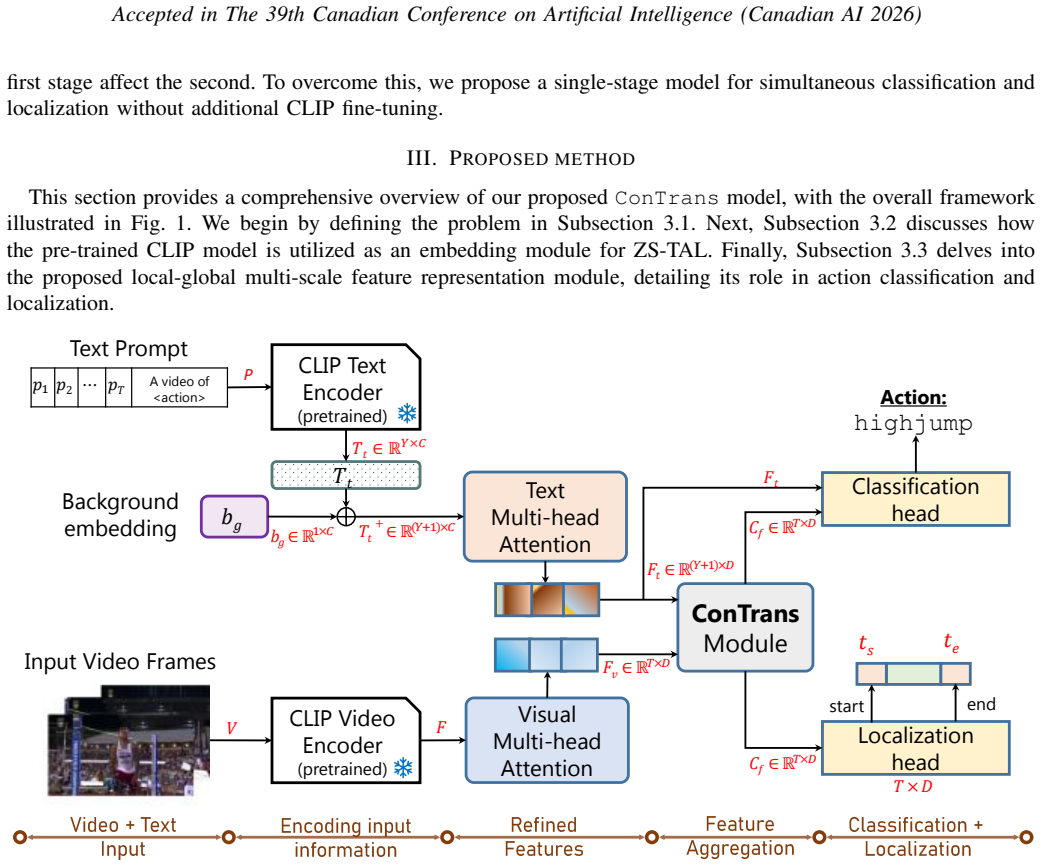
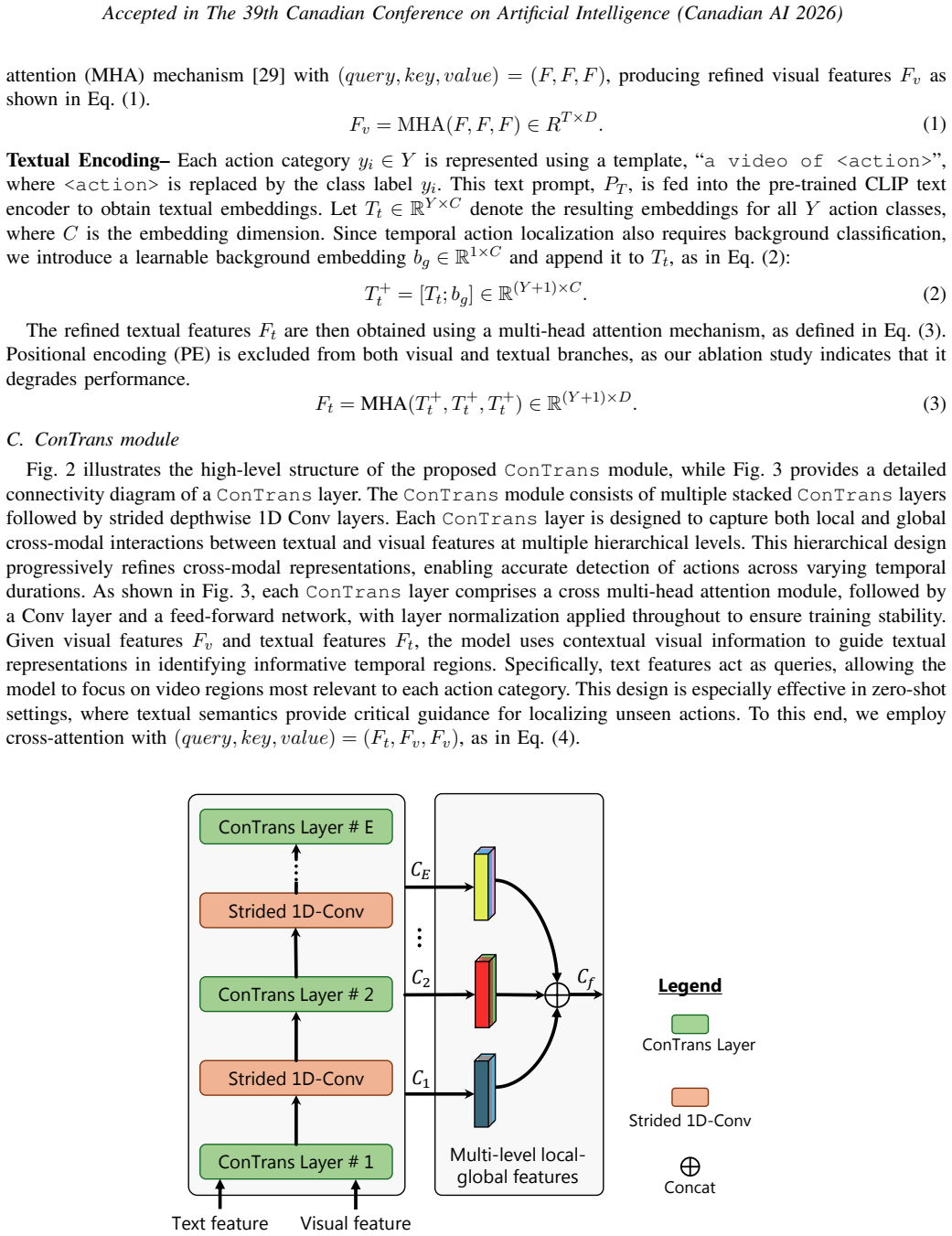
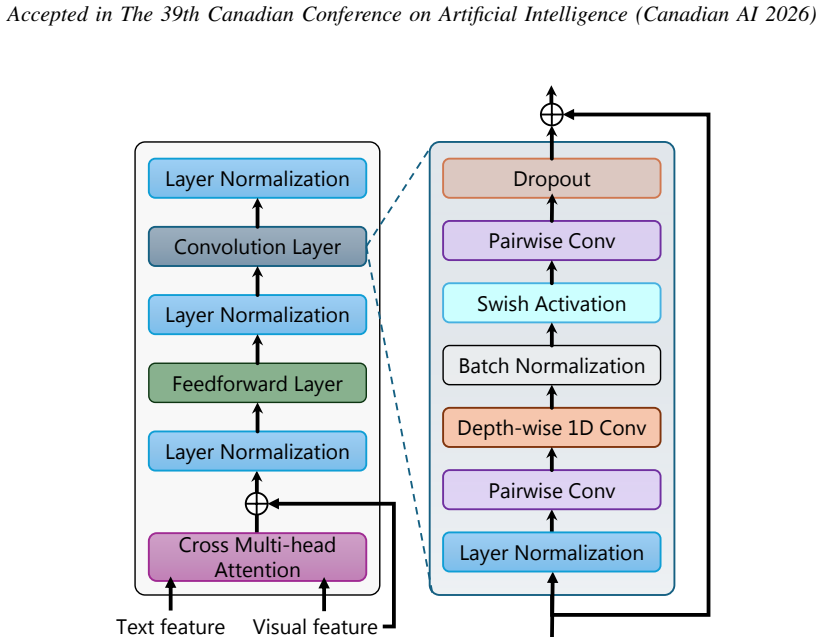
We propose a novel multi-scale encoder architecture, termed ConTrans, that integrates convolutional (Conv) inductive biases with transformer Self-attention to jointly capture fine-grained local dependencies and long-range global context, leading to more comprehensive feature representations than existing methods. Experimental evaluations on the ActivityNet-1.3 and THUMOS14 datasets demonstrate that ConTrans significantly outperforms existing methods, establishing a new benchmark for ZS-TAL.
What carries the argument
ConTrans, the multi-scale encoder that fuses convolutional inductive biases with transformer self-attention to jointly model local frame correlations and long-range context.
If this is right
- ConTrans produces higher performance than prior ZS-TAL methods on ActivityNet-1.3 and THUMOS14.
- The encoder supplies more complete local and global temporal features for detecting unseen actions.
- The method directly addresses the omission of relative-offset local correlations in earlier approaches.
- Text-enhanced local-global representations become feasible within the same multi-scale architecture.
Where Pith is reading between the lines
- If the hybrid design is responsible for the gains, comparable convolutional-transformer fusions could be examined on other temporal video tasks such as dense captioning.
- The title emphasis on text enhancement implies the encoder may also improve semantic alignment between video segments and action descriptions, a link left implicit in the reported experiments.
- Success on two benchmarks leaves open whether the same architecture would maintain gains on longer or more diverse untrimmed video collections.
Load-bearing premise
The specific integration of convolutional inductive biases with transformer self-attention inside the multi-scale encoder produces more comprehensive feature representations than the shallow architectures used in prior work.
What would settle it
An ablation that removes either the convolutional component or the self-attention component from ConTrans and measures no improvement over a single-component baseline on ActivityNet-1.3 or THUMOS14 would falsify the claimed benefit of the integration.
Figures

read the original abstract
Zero-shot Temporal Action Localization (ZS-TAL) aims to detect and locate previously unseen actions in untrimmed videos. However, existing approaches primarily focus on modeling long-range contextual information, often neglecting the critical relative-offset-based local correlations between video frames. Furthermore, their performance is hindered by limited feature representation capabilities due to the shallow nature of their network architectures. In this paper, we address these limitations by introducing a novel local-global multi-scale feature representation module. We propose a novel multi-scale encoder architecture, termed ConTrans, that integrates convolutional (Conv) inductive biases with transformer Self-attention to jointly capture fine-grained local dependencies and long-range global context, leading to more comprehensive feature representations than existing methods. Experimental evaluations on the ActivityNet-1.3 and THUMOS14 datasets demonstrate that ConTrans significantly outperforms existing methods, establishing a new benchmark for ZS-TAL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConTrans, a novel multi-scale encoder architecture for zero-shot temporal action localization (ZS-TAL) that integrates convolutional inductive biases with transformer self-attention to jointly model fine-grained local dependencies (via relative-offset correlations) and long-range global context. It claims this hybrid design overcomes limitations of prior shallow architectures, yielding more comprehensive features and significant outperformance over existing methods on ActivityNet-1.3 and THUMOS14, thereby establishing a new benchmark.
Significance. If the empirical results and architectural claims hold with supporting evidence, the work could advance ZS-TAL by demonstrating the value of hybrid Conv-Transformer multi-scale encoding for better generalization to unseen actions, providing a stronger baseline than shallow networks focused only on long-range context.
major comments (1)
- [Abstract] Abstract: the central claim that ConTrans 'significantly outperforms existing methods' and 'establishes a new benchmark' is unsupported by any quantitative results, error bars, ablation studies, or methodological details in the provided text, rendering the soundness of the hybrid architecture claim unevaluable.
Simulated Author's Rebuttal
We thank the referee for their review. The major comment concerns the abstract's claims lacking supporting details in the provided text. We address this point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ConTrans 'significantly outperforms existing methods' and 'establishes a new benchmark' is unsupported by any quantitative results, error bars, ablation studies, or methodological details in the provided text, rendering the soundness of the hybrid architecture claim unevaluable.
Authors: The abstract is a concise summary and does not include numerical results or methodological details by design. The full manuscript contains the supporting quantitative comparisons (with error bars), ablation studies, and architectural details in the Experiments and Method sections. These substantiate the claims of outperformance on ActivityNet-1.3 and THUMOS14. To improve clarity, we will revise the abstract to incorporate key quantitative improvements and a brief mention of the evaluation setup. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal of a multi-scale encoder architecture (ConTrans) that combines convolutional biases with transformer attention for ZS-TAL feature representation. No derivation chain, equations, fitted parameters presented as predictions, or self-referential definitions exist in the abstract or described content. Claims rest on experimental outperformance on ActivityNet-1.3 and THUMOS14 rather than any reduction to inputs by construction, self-citation load-bearing premises, or renamed known results. The work is self-contained as an architectural contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Action sensitivity learning for temporal action localization,
J. Shao, X. Wang, R. Quan, J. Zheng, J. Yang, and Y . Yang, “Action sensitivity learning for temporal action localization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 457–13 469
2023
-
[2]
Actionformer: Localizing moments of actions with transformers,
C.-L. Zhang, J. Wu, and Y . Li, “Actionformer: Localizing moments of actions with transformers,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 492–510
2022
-
[3]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[4]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
2021
-
[5]
Unified contrastive learning in image-text-label space,
J. Yang, C. Li, P. Zhang, B. Xiao, C. Liu, L. Yuan, and J. Gao, “Unified contrastive learning in image-text-label space,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 19 163–19 173
2022
-
[6]
Zim: Zero-shot image matting for anything,
B. Kim, C. Shin, J. Jeong, H. Jung, S.-Y . Lee, S. Chun, D.-H. Hwang, and J. Yu, “Zim: Zero-shot image matting for anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 23 828–23 838
2025
-
[7]
Zero shot domain adaptive semantic segmentation by synthetic data generation and progressive adaptation,
J. Luo, Z. Zhao, and Y . Liu, “Zero shot domain adaptive semantic segmentation by synthetic data generation and progressive adaptation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 11 531–11 538
2025
-
[8]
J. Li, Q. Xie, R. Gu, J. Xu, Y . Liu, and X. Yu, “Lgd: Leveraging generative descriptions for zero-shot referring image segmentation,” arXiv preprint arXiv:2504.14467, 2025
-
[9]
Text-enhanced zero-shot action recognition: A training-free approach,
M. Bosetti, S. Zhang, B. Liberatori, G. Zara, E. Ricci, and P. Rota, “Text-enhanced zero-shot action recognition: A training-free approach,” inInternational Conference on Pattern Recognition. Springer, 2024, pp. 327–342
2024
-
[10]
Zero-shot compositional action recognition with neural logic constraints,
G. Ye, L. Li, K. Li, J. Xiao, and L. Chen, “Zero-shot compositional action recognition with neural logic constraints,” inProceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3625–3634
2025
-
[11]
Zero-shot video captioning with evolving pseudo-tokens,
Y . Tewel, Y . Shalev, R. Nadler, I. Schwartz, and L. Wolf, “Zero-shot video captioning with evolving pseudo-tokens,”arXiv preprint arXiv:2207.11100, 2022
-
[12]
Temporal prompt guided visual-text-object alignment for zero-shot video captioning,
P. Li, T. Wang, and Z. Pan, “Temporal prompt guided visual-text-object alignment for zero-shot video captioning,”Computer Vision and Image Understanding, p. 104601, 2025
2025
-
[13]
Z-gmot: Zero-shot generic multiple object tracking,
K. Tran, A. D. Le Dinh, T.-P. Nguyen, T. Phan, P. Nguyen, K. Luu, D. Adjeroh, G. Doretto, and N. Le, “Z-gmot: Zero-shot generic multiple object tracking,” inFindings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 3468–3479
2024
-
[14]
Zero-shot temporal action detection via vision-language prompting,
S. Nag, X. Zhu, Y .-Z. Song, and T. Xiang, “Zero-shot temporal action detection via vision-language prompting,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 681–697
2022
-
[15]
Zero-shot temporal action detection by learning multimodal prompts and text-enhanced actionness,
A. Raza, B. Yang, and Y . Zou, “Zero-shot temporal action detection by learning multimodal prompts and text-enhanced actionness,” IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[16]
Activitynet: A large-scale video benchmark for human activity understanding,
F. Caba Heilbron, V . Escorcia, B. Ghanem, and J. Carlos Niebles, “Activitynet: A large-scale video benchmark for human activity understanding,” inProceedings of the ieee conference on computer vision and pattern recognition, 2015, pp. 961–970
2015
-
[17]
The thumos challenge on action recognition for videos “in the wild
H. Idrees, A. R. Zamir, Y .-G. Jiang, A. Gorban, I. Laptev, R. Sukthankar, and M. Shah, “The thumos challenge on action recognition for videos “in the wild”,”Computer Vision and Image Understanding, vol. 155, pp. 1–23, 2017
2017
-
[18]
Video self-stitching graph network for temporal action localization,
C. Zhao, A. K. Thabet, and B. Ghanem, “Video self-stitching graph network for temporal action localization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 658–13 667
2021
-
[19]
Bsn++: Complementary boundary regressor with scale-balanced relation modeling for temporal action proposal generation,
H. Su, W. Gan, W. Wu, Y . Qiao, and J. Yan, “Bsn++: Complementary boundary regressor with scale-balanced relation modeling for temporal action proposal generation,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 3, 2021, pp. 2602–2610
2021
-
[20]
Learning salient boundary feature for anchor-free temporal action localization,
C. Lin, C. Xu, D. Luo, Y . Wang, Y . Tai, C. Wang, J. Li, F. Huang, and Y . Fu, “Learning salient boundary feature for anchor-free temporal action localization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3320–3329
2021
-
[21]
Prompting visual-language models for efficient video understanding,
C. Ju, T. Han, K. Zheng, Y . Zhang, and W. Xie, “Prompting visual-language models for efficient video understanding,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 105–124. Accepted in The 39th Canadian Conference on Artificial Intelligence (Canadian AI 2026)
2022
-
[22]
Zeetad: Adapting pretrained vision-language model for zero-shot end- to-end temporal action detection,
T. Phan, K. V o, D. Le, G. Doretto, D. Adjeroh, and N. Le, “Zeetad: Adapting pretrained vision-language model for zero-shot end- to-end temporal action detection,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2024, pp. 7046–7055
2024
-
[23]
Unloc: A unified framework for video localization tasks,
S. Yan, X. Xiong, A. Nagrani, A. Arnab, Z. Wang, W. Ge, D. Ross, and C. Schmid, “Unloc: A unified framework for video localization tasks,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 623–13 633
2023
-
[24]
Towards completeness: A generalizable action proposal generator for zero-shot temporal action localization,
J.-R. Du, K.-Y . Lin, J. Meng, and W.-S. Zheng, “Towards completeness: A generalizable action proposal generator for zero-shot temporal action localization,” inInternational Conference on Pattern Recognition. Springer, 2024, pp. 252–267
2024
-
[25]
Camp: Cross-modal adaptive message passing for text-image retrieval,
Z. Wang, X. Liu, H. Li, L. Sheng, J. Yan, X. Wang, and J. Shao, “Camp: Cross-modal adaptive message passing for text-image retrieval,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5764–5773
2019
-
[26]
Vqa: Visual question answering,
S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “Vqa: Visual question answering,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 2425–2433
2015
-
[27]
Multicapclip: Auto-encoding prompts for zero-shot multilingual visual captioning,
B. Yang, F. Liu, X. Wu, Y . Wang, X. Sun, and Y . Zou, “Multicapclip: Auto-encoding prompts for zero-shot multilingual visual captioning,”arXiv preprint arXiv:2308.13218, 2023
-
[28]
End-to-end learning of visual representations from uncurated instructional videos,
A. Miech, J.-B. Alayrac, L. Smaira, I. Laptev, J. Sivic, and A. Zisserman, “End-to-end learning of visual representations from uncurated instructional videos,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9879–9889
2020
-
[29]
Attention is all you need,
A. Vaswani, “Attention is all you need,”Advances in Neural Information Processing Systems, 2017
2017
-
[30]
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wuet al., “Conformer: Convolution-augmented transformer for speech recognition,”arXiv preprint arXiv:2005.08100, 2020
-
[31]
Soft-nms–improving object detection with one line of code,
N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Soft-nms–improving object detection with one line of code,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 5561–5569
2017
-
[32]
Bmn: Boundary-matching network for temporal action proposal generation,
T. Lin, X. Liu, X. Li, E. Ding, and S. Wen, “Bmn: Boundary-matching network for temporal action proposal generation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3889–3898
2019
-
[33]
Zstad: Zero-shot temporal activity detection,
L. Zhang, X. Chang, J. Liu, M. Luo, S. Wang, Z. Ge, and A. Hauptmann, “Zstad: Zero-shot temporal activity detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 879–888
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.