Diversity Matters: Revisiting Test-Time Compute in Vision-Language Models
Pith reviewed 2026-06-28 23:39 UTC · model grok-4.3
The pith
Entropy-based selection from model ensembles outperforms majority voting and single best models for vision-language tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
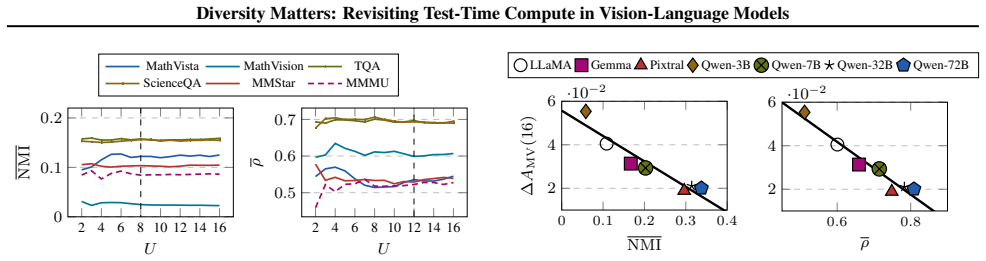
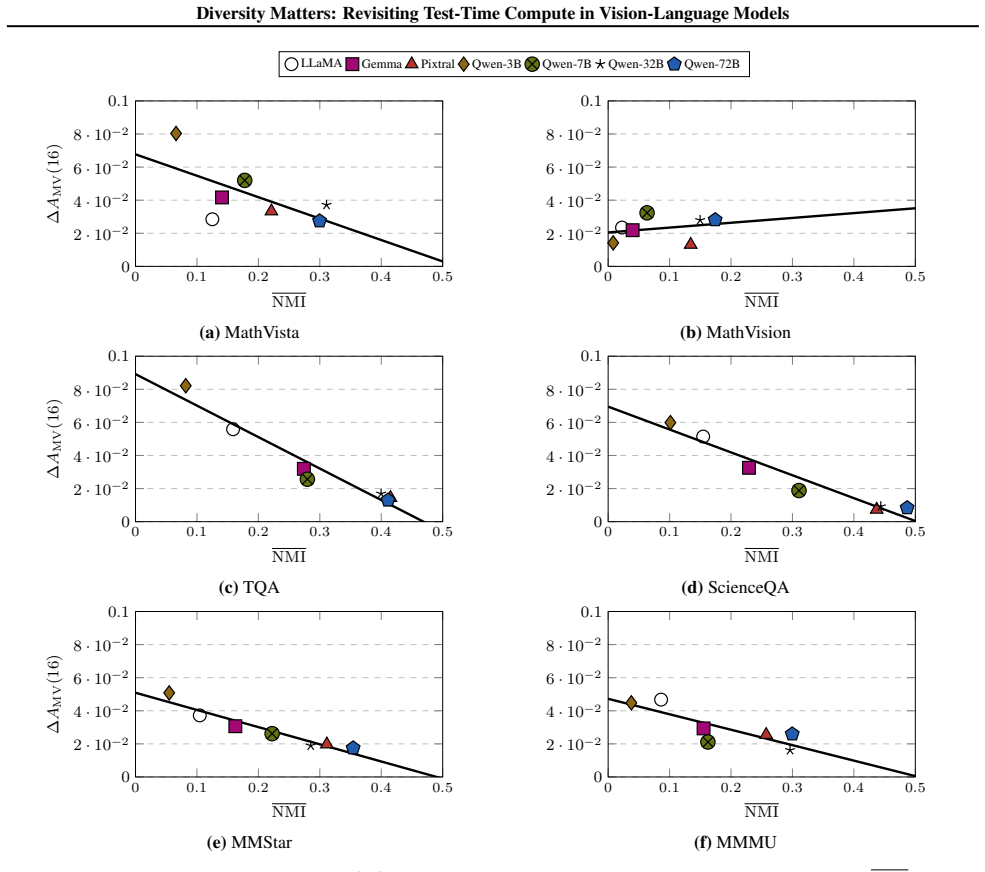
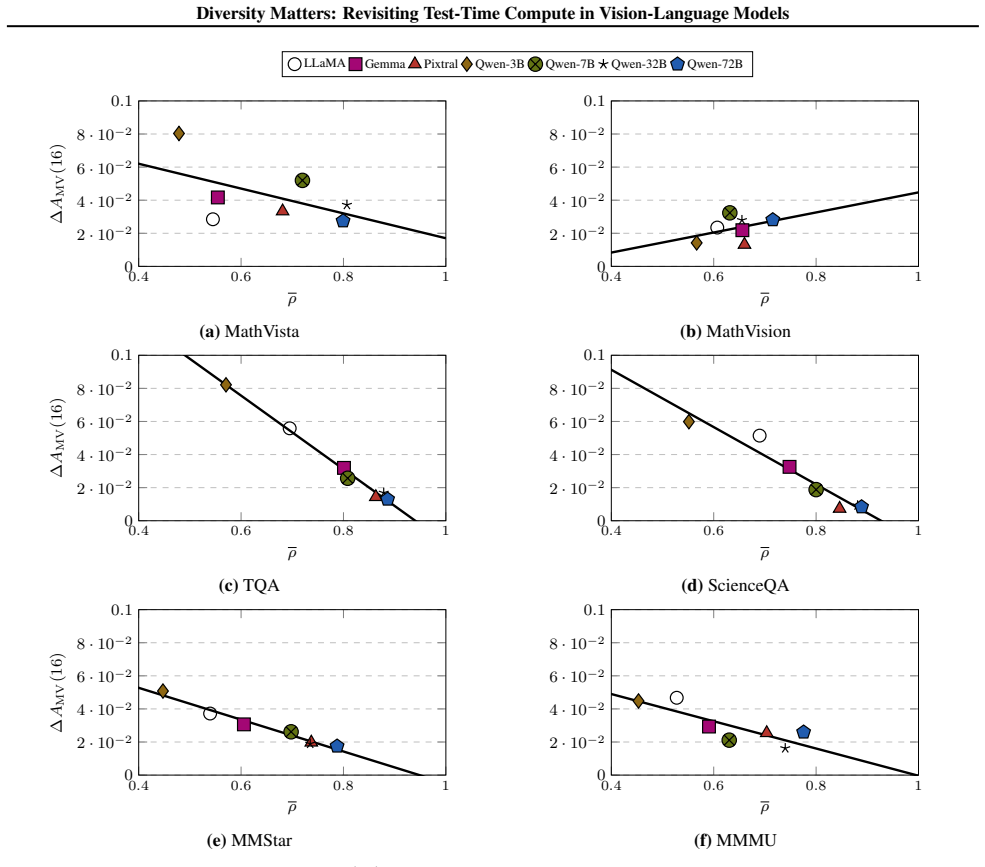
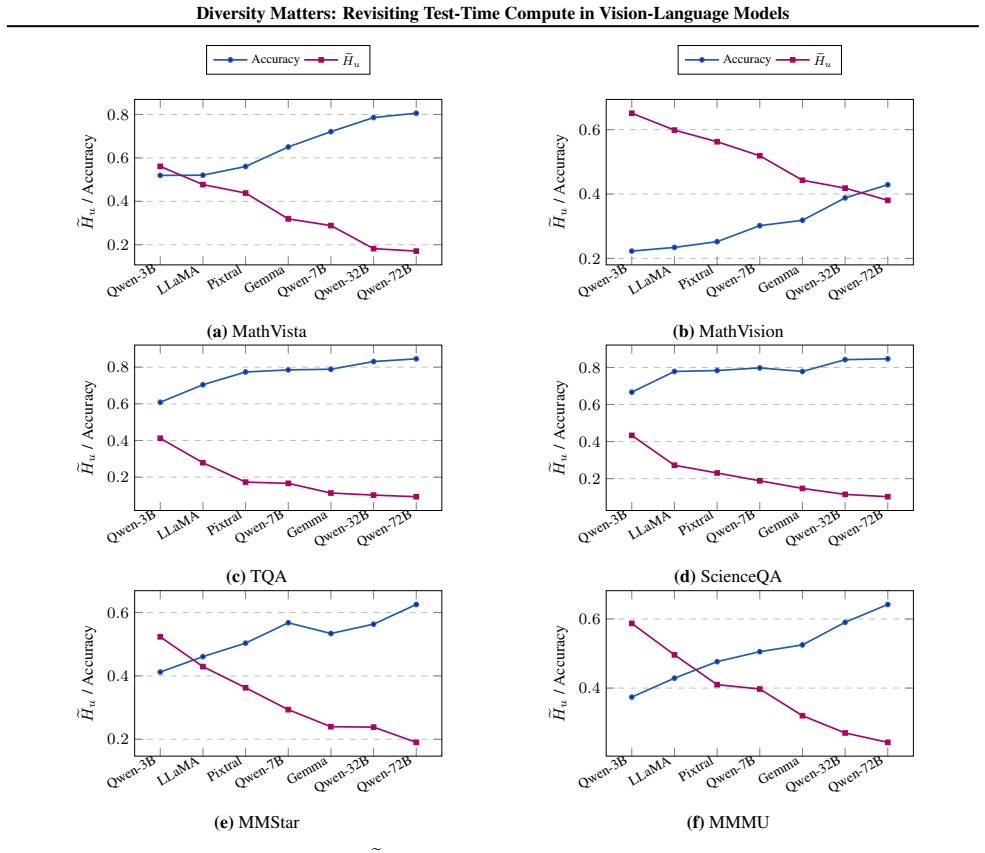
The central claim is that limited prediction diversity restricts single-model TTC methods, whereas multi-model ensembles combined with ETTC—which selects the lowest-entropy output—leverage capability differences to exceed both voting and the best single model; the method is proved superior to voting under mild assumptions on predictions and entropies, and smaller models are shown to enhance larger ones in this setting.
What carries the argument
Entropy-based Test-Time Compute (ETTC), the mechanism that selects the prediction with lowest predictive entropy across an ensemble.
If this is right
- ETTC reduces exactly to majority voting when applied to a single model.
- In ensembles ETTC uses entropy disparities to prioritize stronger models over weaker ones.
- Smaller models produce measurable synergistic gains when combined with larger models under ETTC.
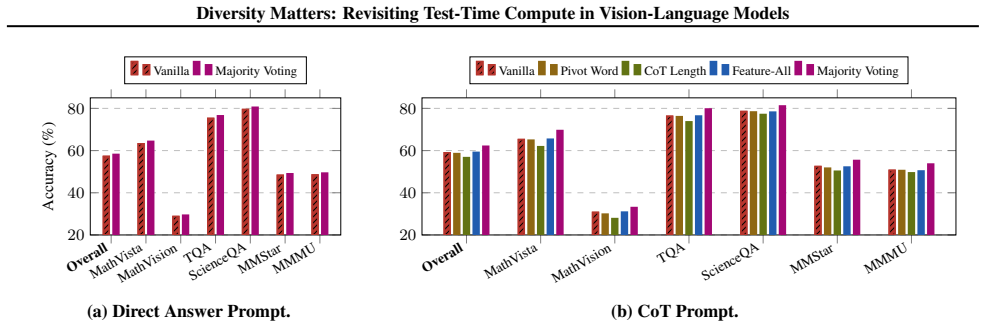
- The gains appear consistently across the seven VLMs and six benchmarks examined.
Where Pith is reading between the lines
- The method may transfer to language-only or other multimodal settings whenever prediction diversity exists.
- Developers could benefit from releasing model families of mixed sizes rather than scaling a single architecture.
- Pairing ETTC with other lightweight TTC heuristics might compound gains if the signals are complementary.
- Expanding the evaluation to out-of-distribution tasks would test whether the mild assumptions remain valid.
Load-bearing premise
The theoretical superiority of ETTC over voting rests on unspecified mild assumptions about model predictions and entropies holding in practice.
What would settle it
A controlled test on new VLMs and benchmarks where ETTC shows no gain over majority voting despite measured prediction diversity would falsify the core empirical and theoretical claims.
Figures
read the original abstract
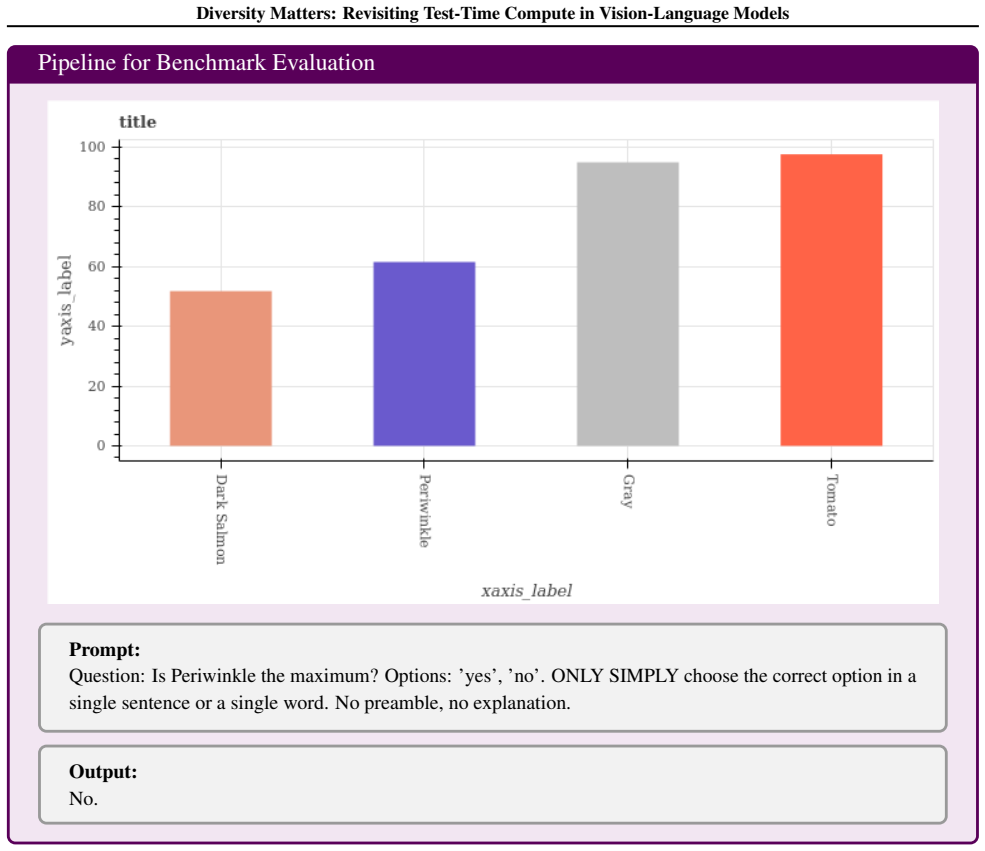
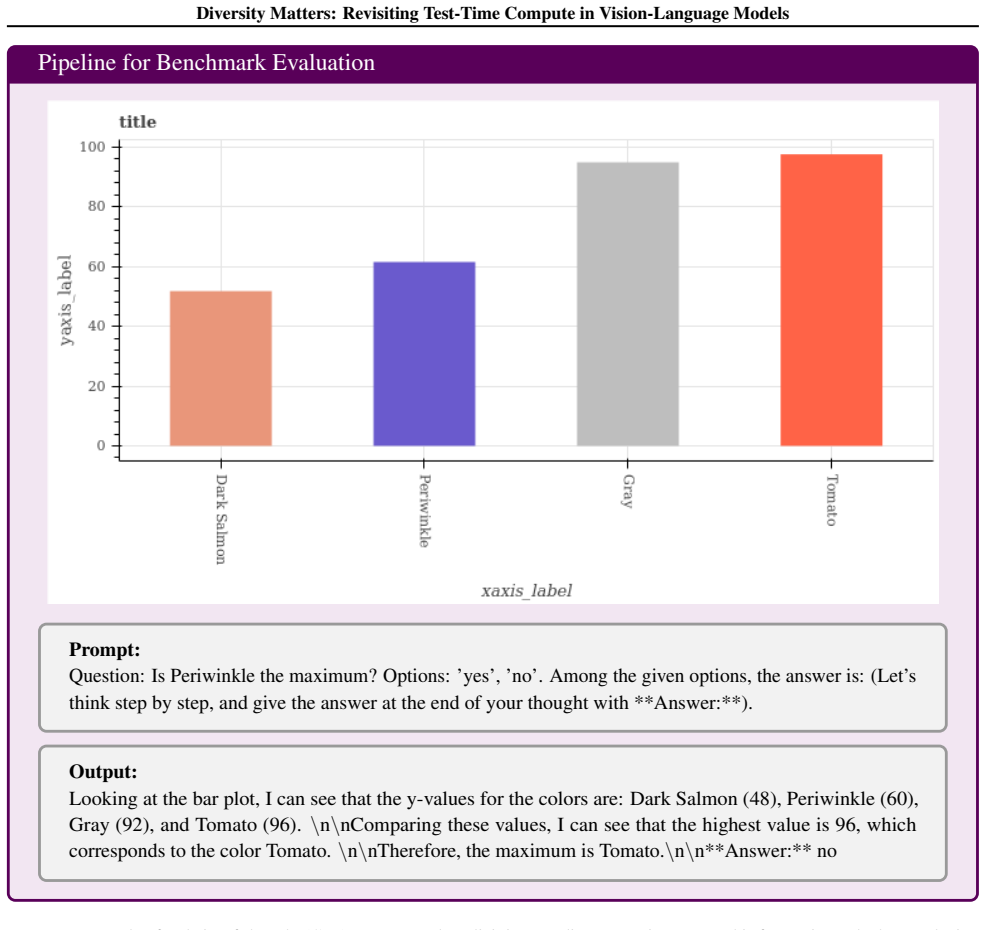
Test-time compute (TTC) strategies have emerged as a lightweight approach to boost reasoning in large language models (LLMs). However, their application and benefits for vision-language models (VLMs) remain underexplored. We present a systematic study of TTC across seven VLMs and six benchmarks, specifically analyzing feature-based scoring and majority voting methods. We find that feature heuristics fail and voting yields only modest gains in single-model settings. We theoretically show that this limitation stems from a lack of prediction diversity: when outputs are highly correlated, voting provides little benefit. In contrast, multi-model ensembles offer richer diversity, yet standard majority voting fails to account for varying model capabilities. To address this, we propose Entropy-based TTC (ETTC), which selects the most confident prediction based on predictive entropy. Our method reduces to majority voting in the single-model case, but in model ensembles, it leverages confidence disparities to prioritize stronger models. We prove that ETTC outperforms majority voting under mild assumptions and empirically demonstrate that it consistently surpasses both voting and the best individual model. Crucially, our results show that smaller models can synergistically enhance larger ones, unlocking ensembling gains not achievable with standard strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies test-time compute (TTC) for vision-language models across seven VLMs and six benchmarks. It reports that feature-based heuristics fail and majority voting yields only modest gains in single-model settings due to low prediction diversity. It proposes Entropy-based TTC (ETTC), which selects the lowest-entropy prediction and reduces to voting for single models; the method is shown to outperform voting in multi-model ensembles by exploiting capability differences. The central claims are a proof of ETTC superiority over voting under mild assumptions and consistent empirical gains, including synergistic benefits from including smaller models.
Significance. If the proof holds and the mild assumptions are satisfied by the tested VLMs, the result supplies a simple, theoretically motivated alternative to voting that can extract additional performance from heterogeneous model collections. The empirical demonstration that smaller models can improve larger ones in ensembles would be a useful practical finding for multimodal systems.
major comments (2)
- [Abstract / theoretical analysis] Abstract and theoretical section: the claim that ETTC 'outperforms majority voting under mild assumptions' is load-bearing for the central theoretical contribution, yet the assumptions (e.g., any required correlation between predictive entropy and model accuracy or ordering of model capabilities) are never enumerated. Without an explicit theorem statement listing them, it is impossible to verify whether the seven VLMs satisfy the conditions on the six benchmarks.
- [Experiments] Empirical evaluation section: the manuscript asserts that ETTC 'consistently surpasses both voting and the best individual model' and that smaller models 'synergistically enhance larger ones,' but provides no direct check (e.g., a table or figure) confirming that the mild assumptions hold for the evaluated models and tasks. If the assumptions fail, the observed gains cannot be attributed to the ETTC construction rather than coincidence.
minor comments (2)
- [Experiments] The experimental protocol should report error bars, number of runs, and any data-exclusion rules to support the 'consistent' superiority claim.
- [Method] The precise definition of predictive entropy (including temperature or normalization choices) should be given as an equation before the ETTC algorithm is introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity on the theoretical assumptions and their empirical verification.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract and theoretical section: the claim that ETTC 'outperforms majority voting under mild assumptions' is load-bearing for the central theoretical contribution, yet the assumptions (e.g., any required correlation between predictive entropy and model accuracy or ordering of model capabilities) are never enumerated. Without an explicit theorem statement listing them, it is impossible to verify whether the seven VLMs satisfy the conditions on the six benchmarks.
Authors: We agree that an explicit enumeration of the assumptions is necessary for verifiability. The revised manuscript will include a dedicated theorem statement that lists all mild assumptions, including the correlation between predictive entropy and model accuracy as well as the ordering of model capabilities. This will allow readers to check whether the seven VLMs satisfy the conditions on the six benchmarks. revision: yes
-
Referee: [Experiments] Empirical evaluation section: the manuscript asserts that ETTC 'consistently surpasses both voting and the best individual model' and that smaller models 'synergistically enhance larger ones,' but provides no direct check (e.g., a table or figure) confirming that the mild assumptions hold for the evaluated models and tasks. If the assumptions fail, the observed gains cannot be attributed to the ETTC construction rather than coincidence.
Authors: We concur that a direct empirical check of the assumptions would strengthen the link between theory and results. The revised version will add a table (or figure) reporting the relevant statistics—such as entropy-accuracy correlations and capability orderings—for all seven VLMs across the six benchmarks. This will confirm that the assumptions hold and support attribution of the gains to the ETTC method. revision: yes
Circularity Check
No circularity detected; derivation is self-contained
full rationale
The paper motivates ETTC from an analysis of prediction diversity, reduces to majority voting in the single-model case by construction, and claims a proof of outperformance under mild assumptions plus empirical gains. No quoted equations or steps reduce a claimed prediction or uniqueness result to a fitted input, self-citation chain, or ansatz smuggled from prior work by the same authors. The central theoretical claim is presented as conditional on external assumptions rather than tautological, and the empirical comparisons are to external baselines (voting, best single model). This is the normal case of an independent derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Mild assumptions under which ETTC outperforms majority voting
Reference graph
Works this paper leans on
-
[2]
OpenReview.net, 2023. URL https://openre view.net/forum?id=yf1icZHC-l9. Gemini Team, G. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URL https: //arxiv.org/abs/2507.06261. Gemma Team, G. D. Gemma 3 technical report.CoRR, abs/2503.19786, 2025. doi: 10.48550/ARXIV.2503.19
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19 2023
-
[5]
Association for Computational Linguistics, 2024. 11 Diversity Matters: Revisiting Test-Time Compute in Vision-Language Models doi: 10.18653/V1/2024.FINDINGS-ACL.108. URL https://doi.org/10.18653/v1/2024.fin dings-acl.108. Kim, D., Kim, S., and Kwak, N. Textbook question an- swering with multi-modal context graph understanding and self-supervised open-set ...
-
[6]
URL https: //doi.org/10.18653/v1/p19-1347
doi: 10.18653/V1/P19-1347. URL https: //doi.org/10.18653/v1/p19-1347. Kojima, T., Gu, S. S., Reid, M., Matsuo, Y ., and Iwasawa, Y . Large language models are zero-shot reasoners. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Infor- mation Processing Systems 35: Annual Conference on Neural Information...
-
[9]
URL https://doi.org/10.48550/arXiv .2506.08243. Movva, P. and Marupaka, N. H. Enhancing scientific visual question answering through multimodal reasoning and ensemble modeling. In Ghosal, T., Mayr, P., Singh, A., Naik, A., Rehm, G., Freitag, D., Li, D., Schimmler, S., and De Waard, A. (eds.),Proceedings of the Fifth Work- shop on Scholarly Document Proces...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[10]
doi: 10.18653/v1/2025.sdp-1.23. URL https: //aclanthology.org/2025.sdp-1.23/. OpenAI. GPT-4 technical report.CoRR, abs/2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.sdp-1.23 2025
-
[11]
doi: 10.48550/ARXIV.2303.08774. URL https: //doi.org/10.48550/arXiv.2303.08774. Rufo, M. and P ´erez, C. Log-linear pool to combine prior distributions: A suggestion for a calibration-based ap- proach.Bayesian Analysis, 7:1–28, 06 2012. doi: 10.1214/12-BA714. 12 Diversity Matters: Revisiting Test-Time Compute in Vision-Language Models Snell, C., Lee, J., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2012
-
[12]
VGR: Visual Grounded Reasoning
doi: 10.1080/095400996116839. URL https: //doi.org/10.1080/095400996116839. Wang, J., Kang, Z., Wang, H., Jiang, H., Li, J., Wu, B., Wang, Y ., Ran, J., Liang, X., Feng, C., and Xiao, J. VGR: visual grounded reasoning.CoRR, abs/2506.11991, 2025. doi: 10.48550/ARXIV.2506.11991. URL https: //doi.org/10.48550/arXiv.2506.11991. Wang, K., Pan, J., Shi, W., Lu,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/095400996116839 2025
-
[13]
In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
URL http://papers.nips.cc/paper_f iles/paper/2024/hash/ad0edc7d5fa1a78 3f063646968b7315b-Abstract-Datasets_ and_Benchmarks_Track.html. Wang, X., Wei, J., Schuurmans, D., Le, Q. V ., Chi, E. H., Narang, S., Chowdhery, A., and Zhou, D. Self- consistency improves chain of thought reasoning in lan- guage models. InThe Eleventh International Confer- ence on Le...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.