MAVEN: Improving Generalization in Agentic Tool Calling
Pith reviewed 2026-06-28 22:40 UTC · model grok-4.3
The pith
A lightweight symbolic scaffold raises open-model tool-calling accuracy from 48% to 71% on a new multi-step benchmark without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
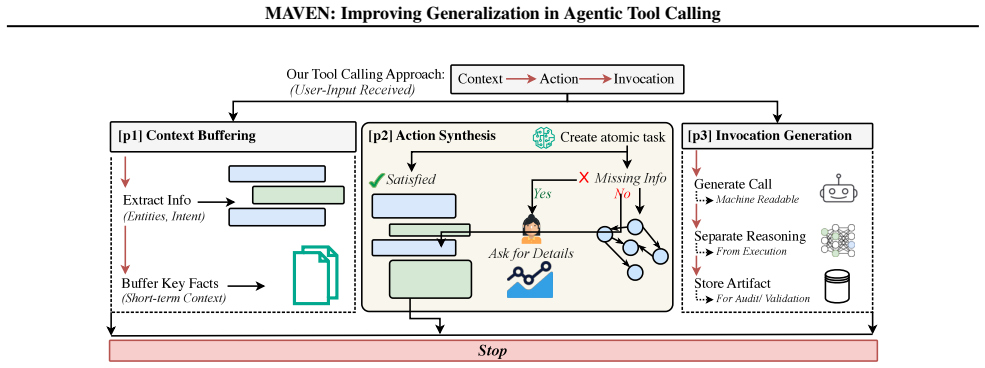
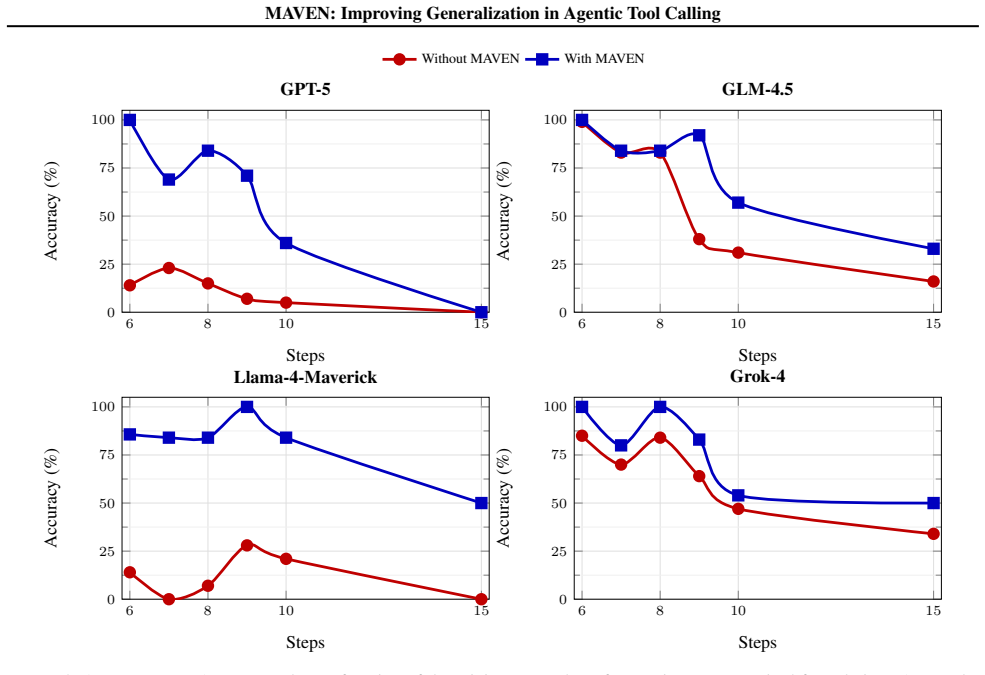
MAVEN is a lightweight symbolic reasoning scaffold for structured decomposition, adaptive tool orchestration, and intermediate verification that improves generalization in agentic tool calling; when applied to GPT-OSS-120b it raises accuracy on MAVEN-Bench from 48% to 71% without additional training and stays competitive with frontier systems at roughly one-tenth the cost.
What carries the argument
The Modular Agentic Verification and Execution Network (MAVEN), a lightweight symbolic reasoning scaffold that supplies structured decomposition, adaptive tool orchestration, and intermediate verification.
If this is right
- Lightweight symbolic scaffolds can raise end-to-end success rates in multi-step tool-calling without model retraining.
- Benchmarks that separate partial reasoning quality from full task completion expose gaps that current evaluations miss.
- Open-weight models augmented with verification scaffolds can approach proprietary performance at substantially lower cost.
- Process-aware evaluation that includes explicit verification steps becomes necessary for measuring real agent reliability.
Where Pith is reading between the lines
- If the scaffold's gains hold outside the tested benchmarks, similar lightweight verification layers could be added to many existing agent frameworks.
- The approach leaves open the question of whether the same decomposition and verification steps would remain effective once the underlying model is fine-tuned rather than used zero-shot.
- Future agent benchmarks might need to include live tool-use traces from production environments to test whether MAVEN-Bench-style adversarial composition matches actual deployment failures.
Load-bearing premise
The performance gains observed on MAVEN-Bench will transfer to unseen real-world agentic environments and the benchmark's adversarial tasks accurately reflect practical failure modes.
What would settle it
Running the same MAVEN scaffold on a fresh collection of live, multi-domain agent tasks that were never part of MAVEN-Bench or the other evaluated benchmarks and finding that the 48-to-71 percent accuracy lift disappears.
Figures


read the original abstract
Generalization across agentic tool-calling environments remains a central challenge for reliable agentic reasoning systems. Although large language models achieve strong results on individual benchmarks, their ability to compose reasoning strategies, preserve intermediate states, and coordinate tools across domains remains underexplored. We present MAVEN (Modular Agentic Verification and Execution Network), a lightweight symbolic reasoning scaffold for structured decomposition, adaptive tool orchestration, and intermediate verification. We evaluate MAVEN across established tool-calling benchmarks, including BFCL v3, TauBench, Tau2Bench, AceBench, and introduce MAVEN-Bench, a stress-test benchmark for multi-step mathematical and physical reasoning with explicit verification and adversarial task composition. MAVEN-Bench exposes a substantial gap between partial reasoning quality and end-to-end task success; in direct MAVEN-Bench runs, MAVEN improves its GPT-OSS-120b base model from 48% to 71% accuracy without additional training. It also remains competitive with frontier proprietary baselines while using an open-weight backbone with an estimated cost ratio of roughly 1/10, suggesting that lightweight verification-centered scaffolds can strengthen compositional reasoning and motivate more process-aware evaluation of agents in the wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MAVEN, a lightweight symbolic scaffold for modular decomposition, adaptive tool orchestration, and intermediate verification in agentic tool-calling systems. It evaluates the approach on established benchmarks (BFCL v3, TauBench, Tau2Bench, AceBench) and introduces MAVEN-Bench, a new stress-test for multi-step math/physics reasoning with explicit verification and adversarial composition. The central empirical claim is that MAVEN raises accuracy on MAVEN-Bench from 48% to 71% for the GPT-OSS-120b base model with no additional training, while remaining competitive with frontier proprietary models at roughly 1/10 the cost.
Significance. If the reported gains prove robust and general, the work would provide concrete evidence that verification-centered symbolic scaffolds can improve compositional reasoning in agents without retraining or fine-tuning. The emphasis on process-aware evaluation and the cost ratio would also strengthen the case for hybrid neuro-symbolic designs over pure scaling approaches.
major comments (2)
- [Abstract / MAVEN-Bench] Abstract and MAVEN-Bench section: the 48%→71% improvement is measured exclusively on MAVEN-Bench, a benchmark introduced in the same paper and explicitly constructed around 'adversarial task composition' and 'explicit verification.' This alignment between benchmark design and MAVEN's modular verification scaffold is load-bearing for the generalization claim; without additional results on independently constructed environments or an analysis showing that the adversarial elements do not preferentially reward the scaffold's decomposition strategy, the delta cannot be interpreted as evidence of broader agentic generalization.
- [Evaluation] Evaluation section: the manuscript reports no error bars, statistical significance tests, or details on data exclusion / task sampling rules for the MAVEN-Bench runs. Given that the central claim rests on a 23-point absolute gain, the absence of these controls makes it impossible to assess whether the improvement is reliable or sensitive to particular task subsets.
minor comments (2)
- [Abstract] The cost-ratio estimate of 1/10 is stated without an explicit breakdown of token usage, API pricing assumptions, or hardware costs; adding a short table or paragraph with these numbers would improve reproducibility.
- [Method] Notation for the symbolic scaffold components (e.g., verification modules, orchestration logic) is introduced without a compact diagram or pseudocode listing; a single figure summarizing the information flow would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on generalization evidence and statistical robustness. We address each major point below.
read point-by-point responses
-
Referee: [Abstract / MAVEN-Bench] Abstract and MAVEN-Bench section: the 48%→71% improvement is measured exclusively on MAVEN-Bench, a benchmark introduced in the same paper and explicitly constructed around 'adversarial task composition' and 'explicit verification.' This alignment between benchmark design and MAVEN's modular verification scaffold is load-bearing for the generalization claim; without additional results on independently constructed environments or an analysis showing that the adversarial elements do not preferentially reward the scaffold's decomposition strategy, the delta cannot be interpreted as evidence of broader agentic generalization.
Authors: The manuscript reports MAVEN results on multiple independently constructed benchmarks (BFCL v3, TauBench, Tau2Bench, AceBench) where it remains competitive with frontier models at ~1/10 cost. MAVEN-Bench was explicitly introduced to stress-test the compositional and verification gaps that the scaffold targets; the 48%→71% delta demonstrates the scaffold's impact on precisely those capabilities. We will add a new subsection comparing error patterns and success rates across all benchmarks, plus a brief analysis of how MAVEN-Bench's adversarial composition maps to documented failure modes in the other suites. This will clarify the scope of the generalization claim. revision: partial
-
Referee: [Evaluation] Evaluation section: the manuscript reports no error bars, statistical significance tests, or details on data exclusion / task sampling rules for the MAVEN-Bench runs. Given that the central claim rests on a 23-point absolute gain, the absence of these controls makes it impossible to assess whether the improvement is reliable or sensitive to particular task subsets.
Authors: We agree that these controls are necessary. The revised manuscript will report standard deviations across three independent runs, McNemar's test for the accuracy difference, and explicit task-sampling and exclusion criteria (including how adversarial compositions were generated and filtered). revision: yes
Circularity Check
No circularity: empirical gains reported on new benchmark without fitted parameters, self-definitional equations, or load-bearing self-citations.
full rationale
The paper presents MAVEN as a symbolic scaffold and reports accuracy improvements on MAVEN-Bench (a newly introduced benchmark) alongside established external benchmarks (BFCL v3, TauBench, etc.). No equations, parameter fitting, or derivation chain are described that would reduce the reported 48%→71% delta to a self-referential construction. The benchmark's design properties are stated explicitly but do not constitute a 'prediction' that is forced by the method's definition; the central claim remains an empirical observation on both new and prior benchmarks. This is the common case of a self-contained empirical paper with no detectable circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Arora, R. K., Wei, J., Hicks, R. S., Bowman, P., Qui˜nonero- Candela, J., Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., et al. Healthbench: Evaluating large language models towards improved human health. arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Barres, V ., Dong, H., Ray, S., Si, X., and Narasimhan, K. τ 2-Bench: Evaluating conversational agents in a dual- control environment.arXiv preprint arXiv:2506.07982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Acebench: Who wins the match point in tool usage?arXiv preprint arXiv:2501.12851,
Chen, C., Hao, X., Liu, W., Huang, X., Zeng, X., Yu, S., Li, D., Wang, S., Gan, W., Huang, Y ., et al. Acebench: Who wins the match point in tool usage?arXiv preprint arXiv:2501.12851,
-
[5]
Towards general agen- tic intelligence via environment scaling.arXiv preprint arXiv:2509.13311,
Fang, R., Cai, S., Li, B., Wu, J., Li, G., Yin, W., Wang, X., Wang, X., Su, L., Zhang, Z., et al. Towards general agen- tic intelligence via environment scaling.arXiv preprint arXiv:2509.13311,
-
[6]
On robustness and reliability of benchmark-based evaluation of llms.arXiv preprint arXiv:2509.04013,
Lunardi, R., Della Mea, V ., Mizzaro, S., and Roitero, K. On robustness and reliability of benchmark-based evaluation of llms.arXiv preprint arXiv:2509.04013,
-
[7]
Exploring Code Analysis: Zero-Shot Insights on Syntax and Semantics with LLMs
Ma, W., Liu, S., Lin, Z., Wang, W., Hu, Q., Liu, Y ., Zhang, C., Nie, L., Li, L., and Liu, Y . Lms: Understanding code syntax and semantics for code analysis.arXiv preprint arXiv:2305.12138,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
A survey on large language model benchmarks.arXiv preprint arXiv:2508.15361,
Ni, S., Chen, G., Li, S., Chen, X., Li, S., Wang, B., Wang, Q., Wang, X., Zhang, Y ., Fan, L., et al. A survey on large language model benchmarks.arXiv preprint arXiv:2508.15361,
-
[9]
Ac- cessed: 2025-10-06
URL https://cdn.openai.com/pdf/ 2221c875-02dc-4789-800b-e7758f3722c1/ o3-and-o4-mini-system-card.pdf . Ac- cessed: 2025-10-06. Patil, S. G., Mao, H., Yan, F., Ji, C. C.-J., Suresh, V ., Stoica, I., and Gonzalez, J. E. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InF orty-second Internation...
2025
-
[10]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Qin, Y ., Liang, S., Ye, Y ., Zhu, K., Yan, L., Lu, Y ., Lin, Y ., Cong, X., Tang, X., Qian, B., et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
and Tavor, A
Rabinovich, E. and Tavor, A. A. On the robustness of agentic function calling. InProceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025), pp. 298–304,
2025
-
[12]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y ., Bao, Y ., Charles, Y ., Chen, C., Chen, G., Chen, H., Chen, H., Chen, J., Chen, N., et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
ReAct: Synergizing Reasoning and Acting in Language Models
URL https://data.x. ai/2025-08-20-grok-4-model-card.pdf . Accessed: 2025-10-10. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Yao, S., Shinn, N., Razavi, P., and Narasimhan, K.τ-Bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Zeng, A., Lv, X., Zheng, Q., Hou, Z., Chen, B., Xie, C., Wang, C., Yin, D., Zeng, H., Zhang, J., et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.