On the impact of retrieved content representations in RAG Pipelines
Pith reviewed 2026-06-28 21:18 UTC · model grok-4.3
The pith
Answer retention is the primary driver of generator accuracy in RAG, outweighing wording, structure, length, or query dependence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Holding retrieval fixed, varying only the representation of retrieved documents through thirteen transformations plus baseline, we observe that answer retention is the primary determinant of generator accuracy for four LLMs. When a representation maintains high retention, its specific wording, structure, length, and query dependence have limited additional effect on accuracy. This indicates that gains previously attributed to particular mechanisms may be partly due to better preservation of answer-bearing content.
What carries the argument
the answer retention metric, which checks whether a transformed document still supports a known answer and predicts generator accuracy more strongly than wording, structure, length, or query dependence
If this is right
- Accuracy gains from specific transformations are largely explained by their impact on answer retention.
- When retention is preserved, changes in document length, wording, or query dependence produce little further change in accuracy.
- Prior studies attributing performance differences to representation mechanisms require controls for retention to isolate other effects.
- Generator accuracy remains stable across selection, summarisation, and reformulation as long as the transformed document retains support for the answer.
Where Pith is reading between the lines
- RAG systems could shift design priority toward retrieval and filtering steps that maximise retention rather than toward elaborate post-retrieval transformations.
- Measuring retention on a small set of known answer pairs could serve as a cheap proxy for expected accuracy before running full generator evaluations.
- The result may generalise to other RAG tasks such as multi-hop reasoning if those tasks also depend on the generator accessing specific retained facts.
- Simple, query-independent representations may suffice for many cases provided they preserve answer content.
Load-bearing premise
The answer retention metric accurately captures the information actually used by the generator models.
What would settle it
Finding two representations with matching retention scores but reliably different generator accuracies, or a representation that changes retention without changing accuracy, would falsify the claim that retention is the primary determinant.
Figures
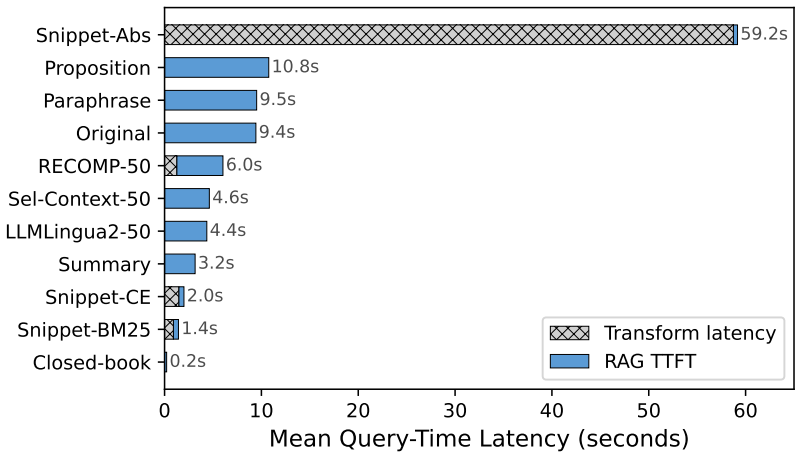
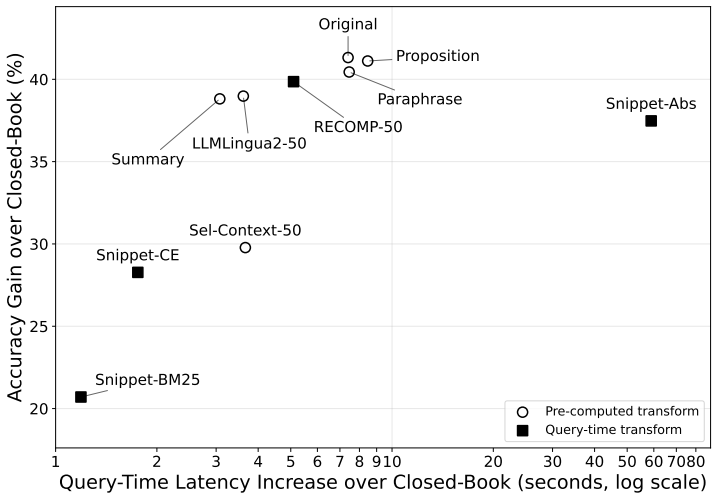
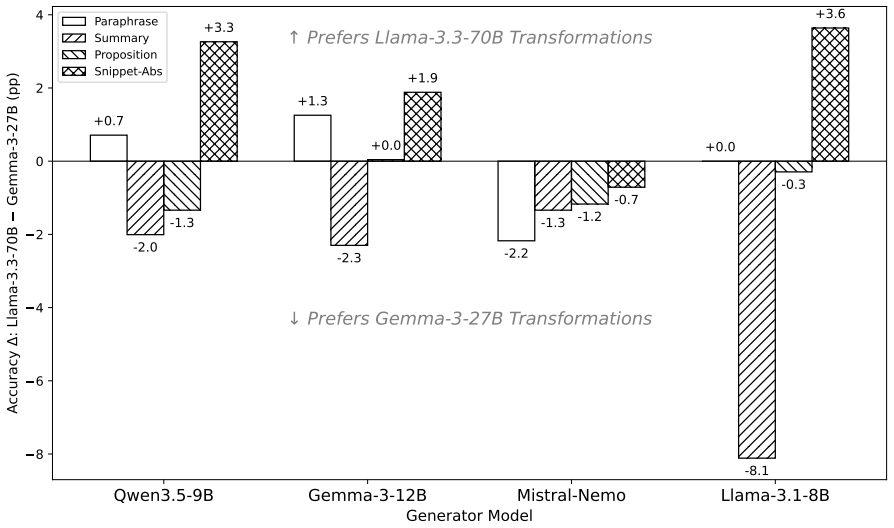

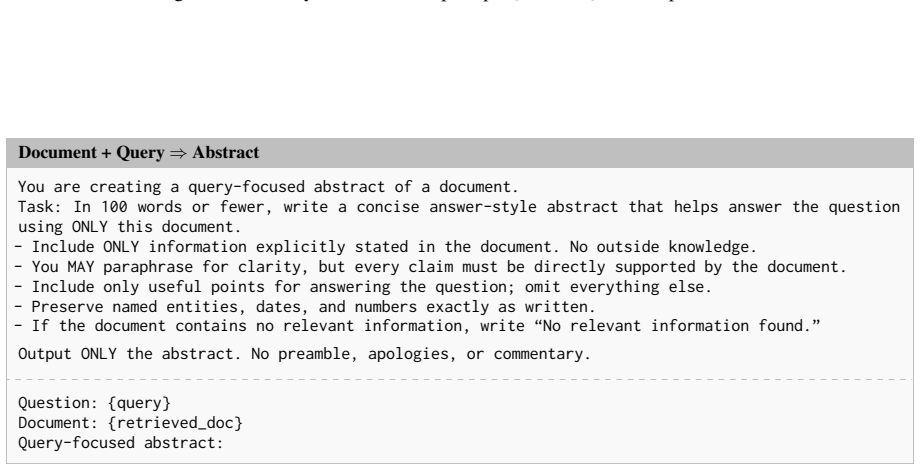

read the original abstract
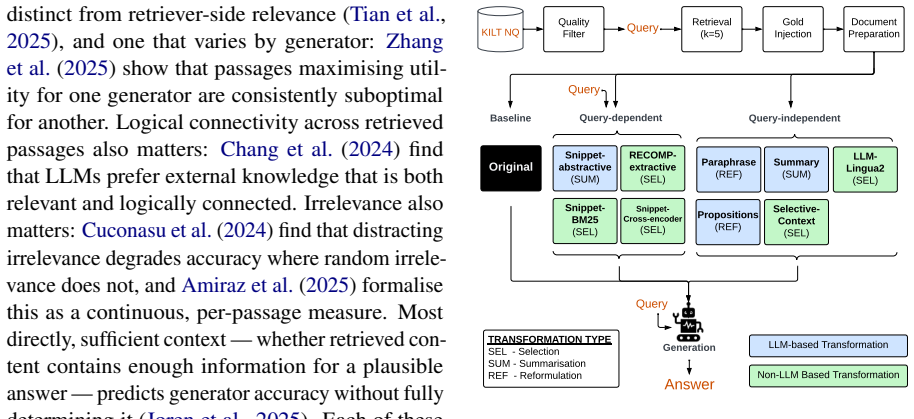
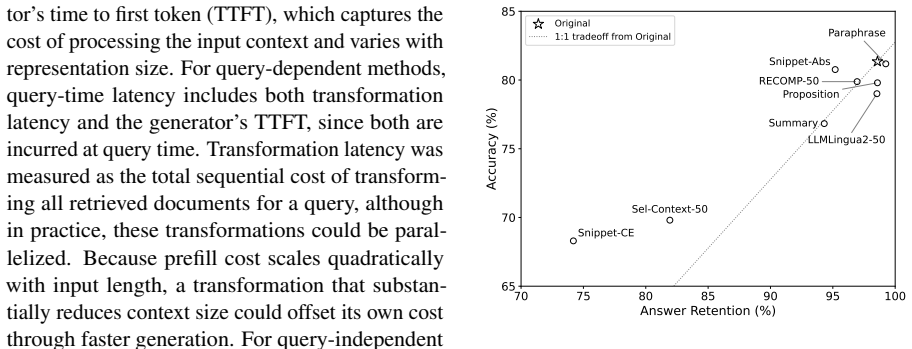
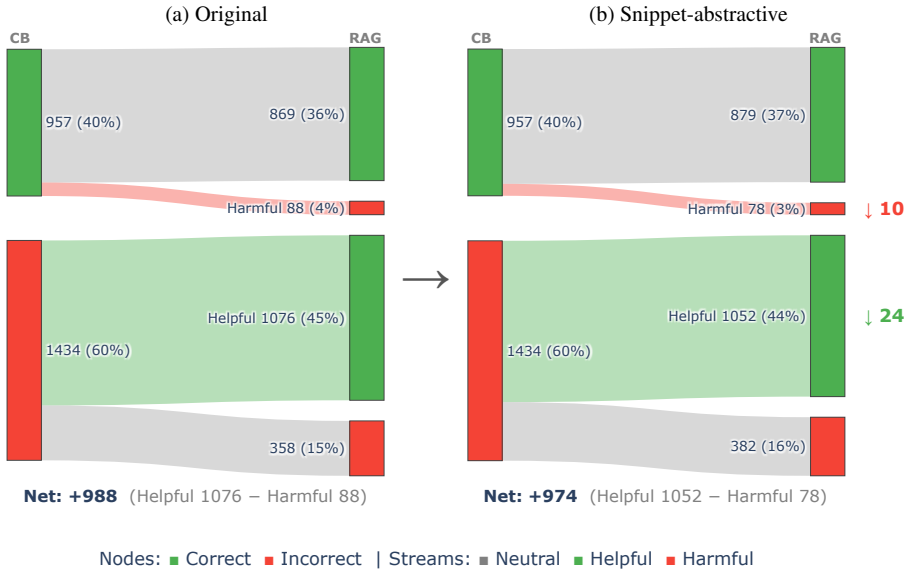
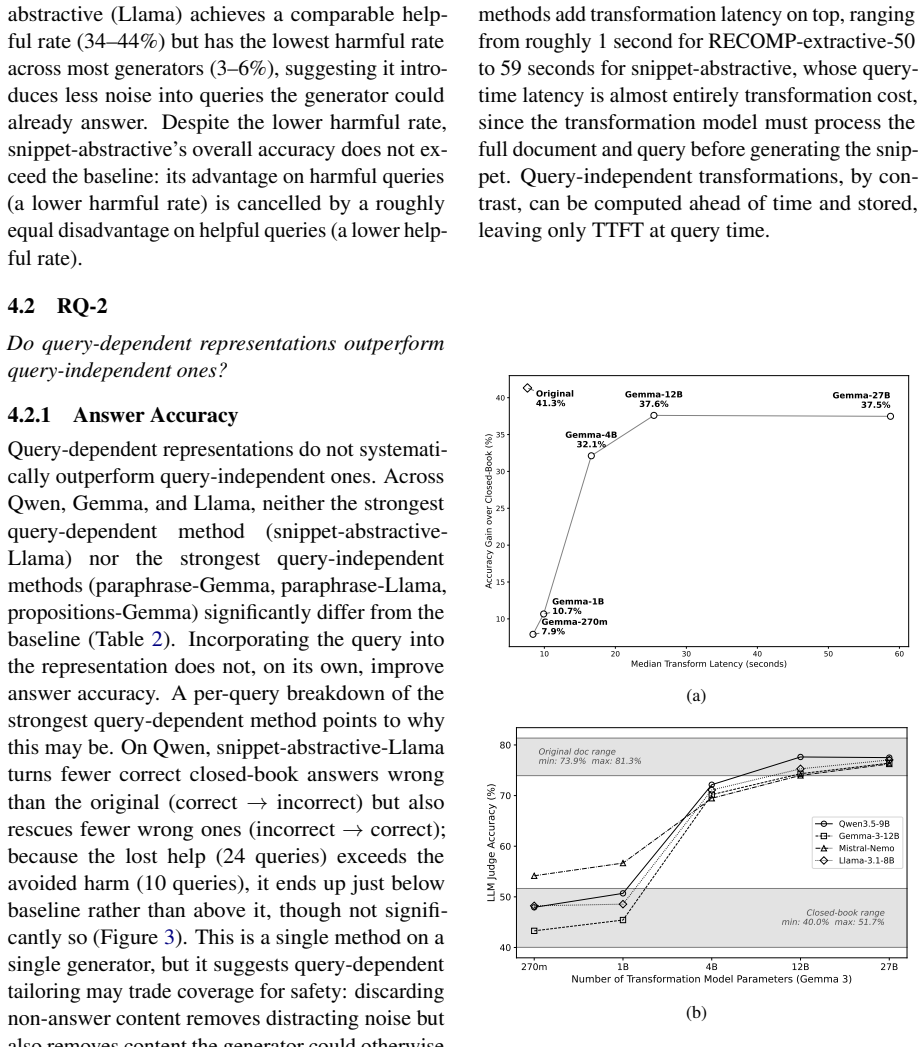
Retrieval-Augmented Generation (RAG) supplements a language model's input with retrieved documents, yet most RAG pipelines inherit retrieval components designed for human readers. How retrieved content should be represented when the consumer is a large language model (LLM) rather than a human is less well understood. Recent work has proposed transformations of retrieved content and identified properties that affect generation, but each examines a single transformation or property in isolation, leaving open which features of a document's representation matter most. We address this with a controlled comparison: holding retrieval fixed, we vary only the representation of retrieved documents, comparing an original baseline against thirteen transformations spanning selection, summarisation, and reformulation, in query-dependent and query-independent variants. Across these fourteen representations we measure question-answering accuracy for four generators, and for each representation we also measure answer retention: whether a known answer-bearing document still supports its answer after transformation. We find that answer retention is the primary determinant of generator accuracy; notably, when retention is high, a representation's wording, structure, length, and query-dependence have limited effect. This suggests that accuracy gains attributed to specific mechanisms in prior work may be partly explained by how well those mechanisms preserve answer-bearing content, an attribution that cannot be settled without controlling for retention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that answer retention is the primary determinant of generator accuracy in RAG pipelines. Holding retrieval fixed, it compares an original baseline against thirteen transformations (selection, summarisation, reformulation; query-dependent and independent) across fourteen representations. It measures question-answering accuracy for four generators and answer retention (whether a known answer-bearing document still supports its answer post-transformation), concluding that when retention is high, wording, structure, length, and query-dependence have limited effect. This implies prior gains from specific mechanisms may be partly explained by retention preservation.
Significance. If the result holds, the work is significant for RAG research by offering a unifying empirical account of why different content transformations affect performance. The controlled multi-generator, multi-representation design allows isolation of retention as the dominant factor and suggests that future evaluations of representations should control for it. The direct measurement approach without fitted parameters or derivations is a methodological strength.
major comments (1)
- [Abstract and experimental protocol] Abstract and experimental protocol: the central claim that retention is the primary determinant requires that the retention metric closely tracks the specific content each generator actually conditions on. The abstract provides no evidence that retention (measured via an independent procedure such as string match or separate judge) was validated against generator behavior, e.g., via attention inspection or content ablation inside the generator itself. Without this, high retention could coexist with low accuracy if generators rely on different spans or inferences, undermining the attribution that other factors have limited effect when retention is high.
minor comments (1)
- The manuscript lacks detail on statistical tests, exact dataset sizes, precise transformation implementations, and error analysis; adding these would strengthen reproducibility without altering the core claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and experimental protocol] Abstract and experimental protocol: the central claim that retention is the primary determinant requires that the retention metric closely tracks the specific content each generator actually conditions on. The abstract provides no evidence that retention (measured via an independent procedure such as string match or separate judge) was validated against generator behavior, e.g., via attention inspection or content ablation inside the generator itself. Without this, high retention could coexist with low accuracy if generators rely on different spans or inferences, undermining the attribution that other factors have limited effect when retention is high.
Authors: We agree that direct validation of the retention metric against each generator's internal behavior (e.g., via attention maps or targeted ablations) would provide stronger causal evidence. Our retention procedure (Section 3.3) uses an independent judge to assess whether the transformed document still contains sufficient information to support the known answer; this is intentionally generator-agnostic to enable controlled comparison. The manuscript reports a high correlation between retention and accuracy that holds consistently across all four generators, which offers indirect support that the metric captures content relevant to generation. However, we did not perform generator-internal analyses. We will revise the abstract to briefly note the metric's design and add a limitations paragraph discussing this point, along with suggestions for future direct validation where model access permits. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential reductions
full rationale
The paper reports controlled experiments that vary document representations while holding retrieval fixed, then directly measures generator accuracy and answer retention across 14 representations and 4 generators. The central finding is an observed correlation between retention and accuracy. No equations, fitted parameters, uniqueness theorems, or derivations are present in the provided text; the result is not obtained by construction from any input metric or prior self-citation. The retention metric is defined operationally (whether a transformed document still supports a known answer) and evaluated independently of the generator's internal behavior, but this is a validity concern rather than a circular reduction. The study is self-contained against external benchmarks and receives a normal non-finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Question-answering accuracy is a sufficient proxy for overall RAG quality
- domain assumption Answer retention can be measured independently of generator behavior
Reference graph
Works this paper leans on
-
[1]
Attributed question answering: Evaluation and modeling for attributed large language models. ArXiv, abs/2212.08037. Zhiyuan Chang, Mingyang Li, Xiaojun Jia, Junjie Wang, Yuekai Huang, Qing Wang, Yihao Huang, and Yang Liu. 2024. What external knowledge is preferred by llms? characterizing and exploring chain of evidence in imperfect context.ArXiv, abs/2412...
-
[2]
InProceedings of the 47th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 719– 729, Washington DC USA
The Power of Noise: Redefining Retrieval for RAG Systems. InProceedings of the 47th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 719– 729, Washington DC USA. ACM. Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasu- pat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. InInternation...
2020
-
[3]
Evaluating the impact of snippet highlight- ing in search. InUIIR@SIGIR. Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi- Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot Learning with Re- trieval Augmented Language Models.Journal of Machine Learning Research. Thorsten Joa...
-
[4]
LLM Evaluators Recognize and Favor Their Own Generations.Advances in Neural Information Processing Systems, 37. Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. 2021. KILT: A Benchmark for K...
2021
-
[5]
Raptor: Recursive abstractive processing for tree-organized retrieval. InInternational Conference on Learning Representations, volume 2024, pages 32628–32649. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying Language Models’ Sensitiv- ity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt for...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Maintain the original phrasing from the input whenever possible
Split compound sentence into simple sentences. Maintain the original phrasing from the input whenever possible
-
[7]
For any named entity that is accompanied by additional descriptive information, separate this information into its own distinct proposition
-
[8]
it”, “he
Decontextualize the proposition by adding necessary modifier to nouns or entire sentences and replacing pronouns (e.g., “it”, “he”, “she”, “they”, “this”, “that”) with the full name of the entities they refer to
-
[9]
- ”. Output ONLY the propositions. Do not include any preamble, commentary, or bullet styles other than “-
Present the results as a bulleted list. Each line must start with “- ”. Output ONLY the propositions. Do not include any preamble, commentary, or bullet styles other than “- ”. Example: Title: ¯Eostre Section: Theories and interpretations, Connection to Easter Hares Content: The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.