Your Teacher Can't Help You Here: Combating Supervision Fidelity Decay in On-Policy Distillation
Pith reviewed 2026-06-28 22:59 UTC · model grok-4.3
The pith
Lookahead group reward based on induced next-step teacher confidence mitigates supervision fidelity decay in on-policy distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
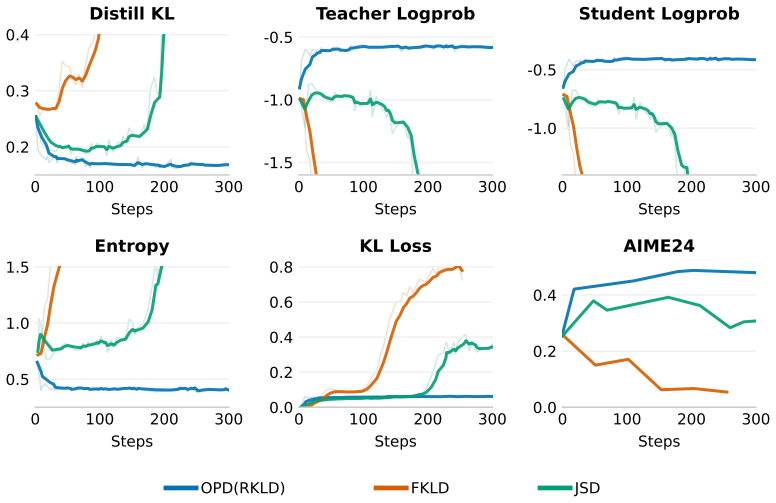
Supervision fidelity decay occurs because teacher next-token distributions become less confident and discriminative as student prefixes lengthen, weakening the reverse-KL corrective signal and allowing drift to accumulate. Lookahead Group Reward counters this by evaluating the student's top-K candidates according to the teacher confidence each induces at the subsequent step and applying group-normalized rewards, with entropy-triggered tree attention preserving efficiency.
What carries the argument
Lookahead Group Reward, which assigns group-normalized rewards to top-K tokens according to the teacher confidence they induce at the next step.
If this is right
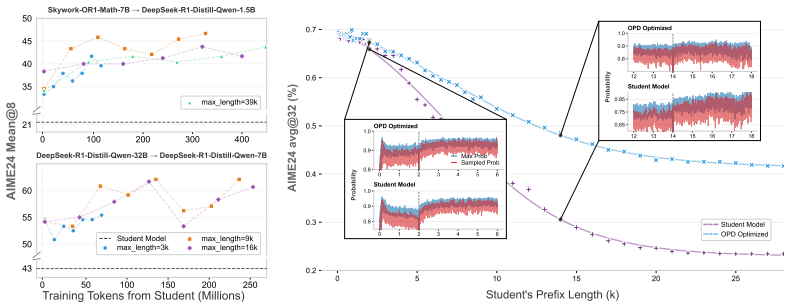
- Mean@8 improves by 2.57 points over standard on-policy distillation for a 7B student across six math and code benchmarks.
- Gains scale with sequence length and reach 4.92 points on AIME-26 when generations reach 39k tokens.
- The entropy-triggered tree-attention mechanism keeps the added computation tractable during training.
- The corrective signal remains effective even when student trajectories diverge substantially from teacher demonstrations.
Where Pith is reading between the lines
- The same lookahead principle could be tested in other distillation losses that also rely on token-level teacher distributions.
- If next-step confidence serves as a reliable proxy, the method may reduce the need for expensive full-sequence teacher rollouts in long-horizon tasks.
- The approach suggests that supervision quality can be maintained without forcing the student to stay close to the teacher's exact token choices at every step.
Load-bearing premise
Next-step teacher confidence directly reflects the discriminative strength of future reverse-KL supervision.
What would settle it
An experiment in which lookahead group reward produces no accuracy gain on long-generation math tasks even though next-step teacher confidence is successfully increased.
Figures
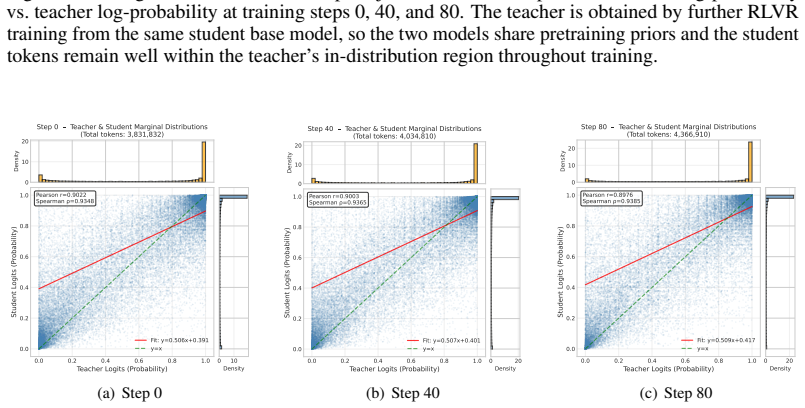
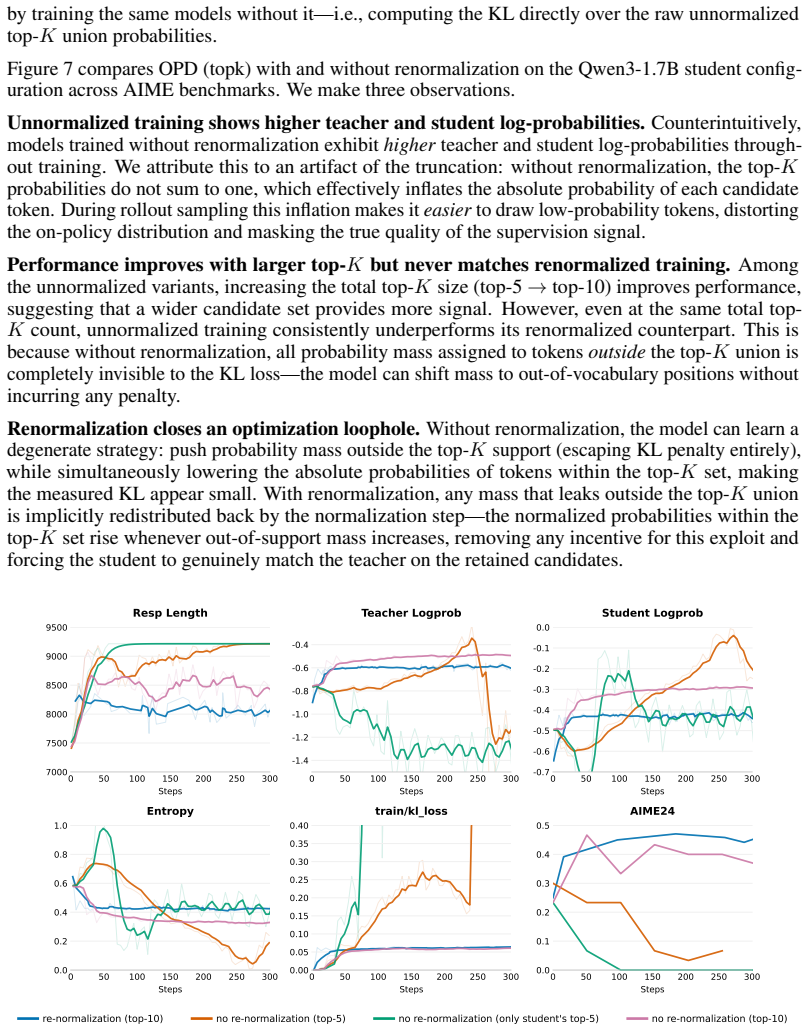
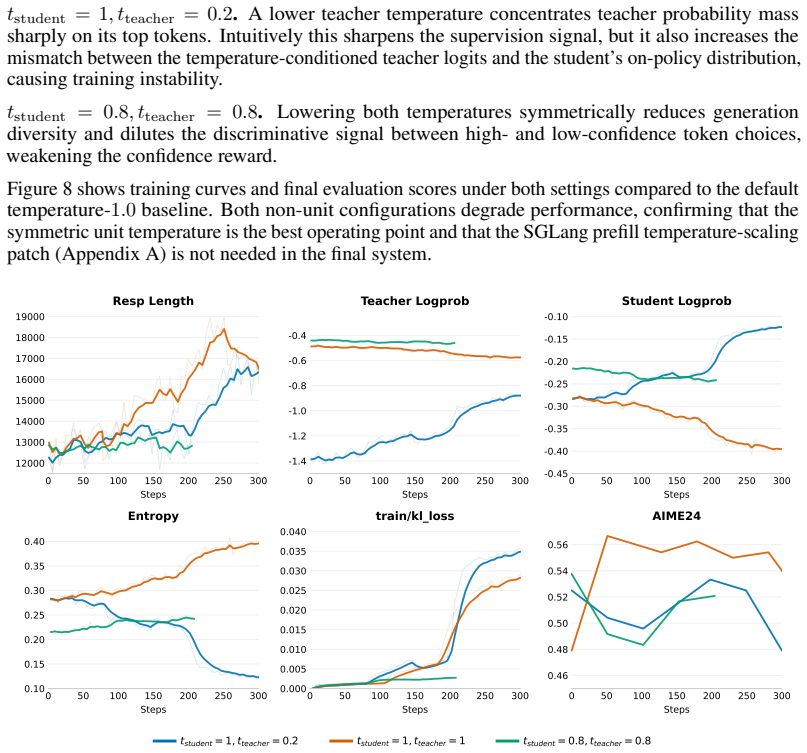

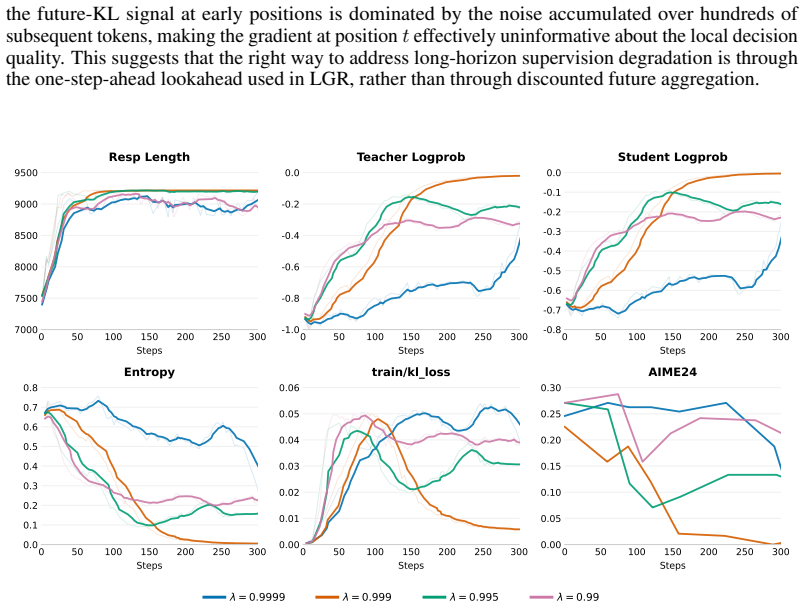

read the original abstract
On-policy distillation transfers reasoning capabilities by training a student model on its own generated trajectories using token-level feedback from a teacher. However, we identify a critical bottleneck, \textbf{Supervision Fidelity Decay (SFD)}: as student-generated prefixes lengthen, the teacher's next-token distribution becomes less confident and less discriminative. Consequently, the teacher-dependent corrective signal in reverse-KL distillation weakens, causing student drift to compound across long reasoning chains. To mitigate SFD, we introduce \textbf{Lookahead Group Reward (\ours{})}. Building on the insight that next-step teacher confidence reflects the discriminative strength of future reverse-KL supervision, \ours{} evaluates the student's top-K candidate tokens by the teacher confidence they induce at the subsequent step and assigns a group-normalized reward. To maintain computational efficiency, we further design an entropy-triggered tree-attention mechanism. Across six math and code benchmarks, \ours{} improves mean@8 by \textbf{2.57} points over OPD for a 7B student, with gains increasing in longer-generation and reaching +\textbf{4.92} points on AIME-26 at 39k tokens.
Editorial analysis
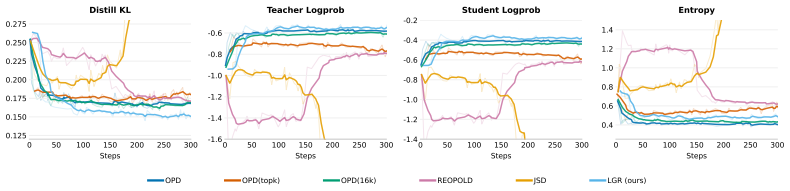
A structured set of objections, weighed in public.
Referee Report
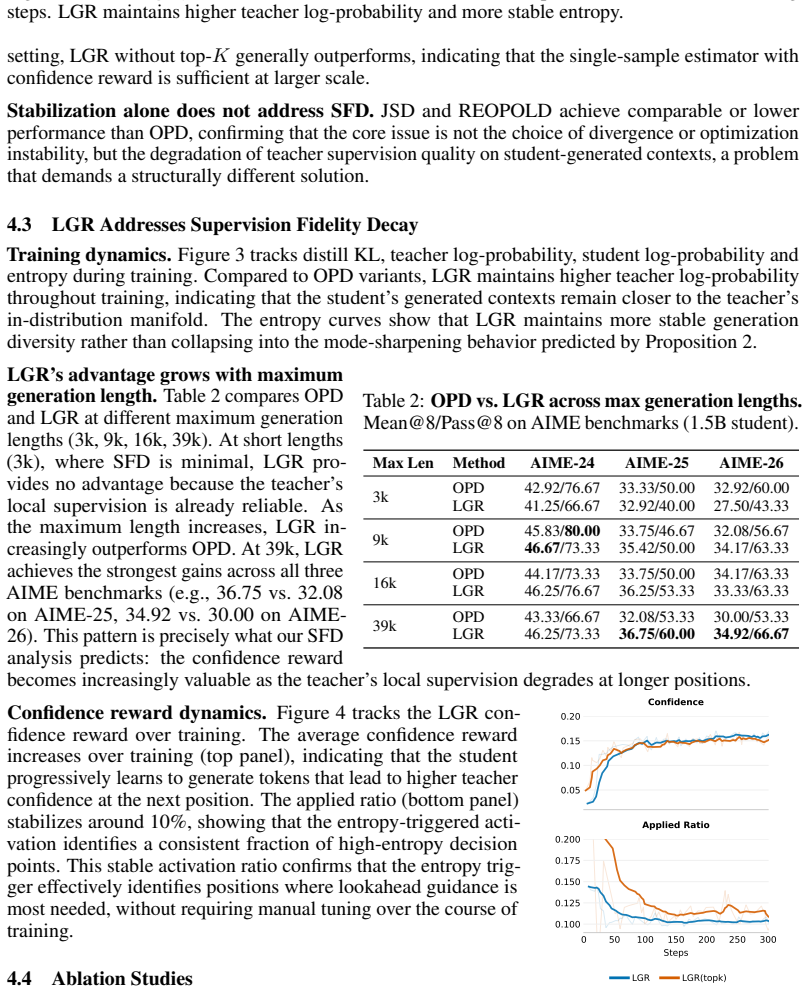
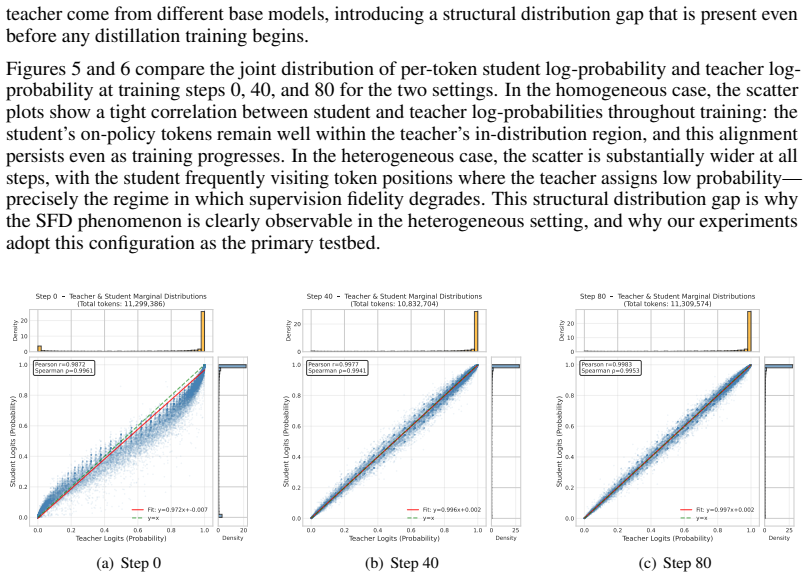
Summary. The manuscript identifies Supervision Fidelity Decay (SFD) as a bottleneck in on-policy distillation (OPD) of reasoning capabilities: as student-generated prefixes lengthen, the teacher's next-token distribution becomes less confident and less discriminative, weakening the reverse-KL corrective signal and allowing drift to compound. It introduces Lookahead Group Reward (LGR), which assigns group-normalized rewards to the student's top-K candidate tokens according to the teacher confidence induced at the immediate next step, together with an entropy-triggered tree-attention mechanism for efficiency. Experiments across six math and code benchmarks are reported to show a mean@8 improvement of 2.57 points over OPD for a 7B student, with gains increasing for longer generations and reaching +4.92 on AIME-26 at 39k tokens.
Significance. If the empirical claims hold under scrutiny, the work would be significant for distillation research. It isolates a concrete, length-dependent degradation in teacher supervision that is especially relevant to long-horizon reasoning, and supplies a lightweight, on-policy intervention whose reported benefit scales with generation length. The emphasis on preserving the discriminative power of reverse-KL signals offers a practical lever for improving student trajectories without altering the core distillation objective.
major comments (2)
- [Abstract] Abstract: the central design premise that 'next-step teacher confidence reflects the discriminative strength of future reverse-KL supervision' is asserted without any reported correlation analysis, ablation against alternative proxies (e.g., future entropy or simulated drift), or verification that the proxy remains valid at 39k-token lengths. If this correlation is weak, the observed gains cannot be confidently attributed to SFD mitigation rather than incidental regularization.
- [Abstract] Abstract: the reported improvements (+2.57 mean@8, +4.92 on AIME-26) are presented without any description of experimental protocol, number of runs, variance estimates, baseline implementation details, or statistical tests. This absence prevents assessment of whether the gains are robust or reproducible.
minor comments (1)
- [Abstract] The acronyms OPD and SFD appear without prior definition; expand on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below, clarifying the manuscript's content and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central design premise that 'next-step teacher confidence reflects the discriminative strength of future reverse-KL supervision' is asserted without any reported correlation analysis, ablation against alternative proxies (e.g., future entropy or simulated drift), or verification that the proxy remains valid at 39k-token lengths. If this correlation is weak, the observed gains cannot be confidently attributed to SFD mitigation rather than incidental regularization.
Authors: The premise follows directly from the SFD analysis in the manuscript, where teacher next-token distributions are shown to lose confidence and discriminativeness as student prefixes lengthen. The reported scaling of gains with generation length (reaching +4.92 on AIME-26 at 39k tokens) provides supporting evidence that the intervention targets this length-dependent effect. We agree that an explicit correlation study or ablation against alternative proxies would strengthen attribution and will add such analysis in the revised version. revision: yes
-
Referee: [Abstract] Abstract: the reported improvements (+2.57 mean@8, +4.92 on AIME-26) are presented without any description of experimental protocol, number of runs, variance estimates, baseline implementation details, or statistical tests. This absence prevents assessment of whether the gains are robust or reproducible.
Authors: The abstract is a concise summary; the full experimental protocol, baseline implementations, and evaluation details across the six benchmarks are provided in Sections 4 and 5, with additional implementation specifics in the appendix. The mean@8 metric is defined and applied consistently. To address the concern, we will revise the abstract to include a brief reference to the number of runs and note that variance estimates appear in the main results. revision: partial
Circularity Check
No circularity: empirical intervention with no reductive derivations
full rationale
The paper identifies Supervision Fidelity Decay as an observed empirical phenomenon in on-policy distillation and proposes Lookahead Group Reward as a practical mitigation based on an explicit insight about next-step teacher confidence. No equations, derivations, or parameter-fitting steps are described that reduce the method or its reported gains to self-referential definitions, fitted inputs renamed as predictions, or self-citation chains. The performance numbers (e.g., +2.57 mean@8) are presented as experimental outcomes on external benchmarks rather than outputs of any closed-form derivation, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-step teacher confidence reflects the discriminative strength of future reverse-KL supervision
Reference graph
Works this paper leans on
-
[1]
Jaech, et al
OpenAI, :, A. Jaech, et al. Openai o1 system card, 2026
2026
-
[2]
Guo, D., D. Yang, H. Zhang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[3]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[4]
Vieillard, Y
Agarwal, R., N. Vieillard, Y . Zhou, et al. On-policy distillation of language models: Learning from self-generated mistakes, 2024
2024
-
[5]
Lu, K., T. M. Lab. On-policy distillation.Thinking Machines Lab: Connectionism, 2025. Https://thinkingmachines.ai/blog/on-policy-distillation
2025
-
[6]
Gu, Y ., L. Dong, F. Wei, et al. Minillm: On-policy distillation of large language models, 2026
2026
-
[7]
Patiño, C. M., K. Rasul, Q. Gallouédec, et al. Unlocking on-policy distillation for any model family, 2025
2025
-
[8]
Yang, A., A. Li, B. Yang, et al. Qwen3 technical report, 2025
2025
-
[9]
Team, C., B. Xiao, B. Xia, et al. Mimo-v2-flash technical report, 2026
2026
-
[10]
Yang, Z., Z. Liu, Y . Chen, et al. Nemotron-cascade 2: Post-training llms with cascade rl and multi-domain on-policy distillation, 2026
2026
-
[11]
Abdali, Y
Ko, J., S. Abdali, Y . J. Kim, et al. Scaling reasoning efficiently via relaxed on-policy distillation, 2026
2026
-
[12]
Xiao, T., Y . Yuan, M. Li, et al. On a connection between imitation learning and rlhf, 2025
2025
-
[13]
Sutton, R. S., A. G. Barto.Reinforcement Learning: An Introduction. The MIT Press, second edn., 2018
2018
-
[14]
Sharma, E
Rafailov, R., A. Sharma, E. Mitchell, et al. Direct preference optimization: Your language model is secretly a reward model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, S. Levine, eds.,Advances in Neural Information Processing Systems, vol. 36, pages 53728–53741. Curran Associates, Inc., 2023
2023
-
[15]
Zhang, Y ., T. Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[16]
Cai, T., Y . Li, Z. Geng, et al. Medusa: Simple llm inference acceleration framework with multiple decoding heads, 2024
2024
-
[17]
Li, Y ., F. Wei, C. Zhang, et al. Eagle: Speculative sampling requires rethinking feature uncertainty, 2025
2025
-
[18]
Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025
—. Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025
2025
-
[19]
He, J., J. Liu, C. Y . Liu, et al. Skywork open reasoner 1 technical report, 2025
2025
-
[20]
Balog, M., A. L. Gaunt, M. Brockschmidt, et al. Deepcoder: Learning to write programs, 2017
2017
-
[21]
Zhang, Y ., T. Math-AI. American invitational mathematics examination (aime) 2025, 2025
2025
-
[22]
American invitational mathematics examination (aime) 2026, 2026
—. American invitational mathematics examination (aime) 2026, 2026
2026
-
[23]
Jovanovi ´c, T
Dekoninck, J., N. Jovanovi ´c, T. Gehrunger, et al. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms. 2026
2026
-
[24]
Jain, N., K. Han, A. Gu, et al. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024
2024
-
[25]
Vinyals, J
Hinton, G., O. Vinyals, J. Dean. Distilling the knowledge in a neural network, 2015. 11
2015
-
[26]
Ko, J., T. Chen, S. Kim, et al. Distillm-2: A contrastive approach boosts the distillation of llms, 2025
2025
-
[27]
Kim, Y ., A. M. Rush. Sequence-level knowledge distillation.CoRR, abs/1606.07947, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Ye, T., L. Dong, Z. Chi, et al. Black-box on-policy distillation of large language models, 2026
2026
-
[29]
Lübeck, L
Hübotter, J., F. Lübeck, L. Behric, et al. Reinforcement learning via self-distillation, 2026
2026
-
[30]
Kim, T., J. Oh, N. Kim, et al. Comparing kullback-leibler divergence and mean squared error loss in knowledge distillation, 2021
2021
-
[31]
Vinyals, N
Bengio, S., O. Vinyals, N. Jaitly, et al. Scheduled sampling for sequence prediction with recurrent neural networks, 2015
2015
-
[32]
Zhang, Z
He, T., J. Zhang, Z. Zhou, et al. Exposure bias versus self-recovery: Are distortions really incremental for autoregressive text generation?, 2021
2021
-
[33]
Kim, Y ., D. Shin, M. Kang, et al. Distillation of large language models via concrete score matching, 2026
2026
-
[34]
Yang, W., W. Liu, R. Xie, et al. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation, 2026
2026
-
[35]
Kim, M., S. J. Baek. Explain in your own words: Improving reasoning via token-selective dual knowledge distillation, 2026
2026
-
[36]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Fu, Y ., H. Huang, K. Jiang, et al. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Li, Y ., Y . Zuo, B. He, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe, 2026
2026
-
[38]
Zhu, Z., C. Xie, X. Lv, et al. slime: An llm post-training framework for rl scaling. https: //github.com/THUDM/slime, 2025. GitHub repository. Corresponding author: Xin Lv
2025
-
[39]
Zheng, L., L. Yin, Z. Xie, et al. Sglang: Efficient execution of structured language model programs, 2024
2024
-
[40]
Wohlwend, H
Lin, A., J. Wohlwend, H. Chen, et al. Autoregressive knowledge distillation through imitation learning. In B. Webber, T. Cohn, Y . He, Y . Liu, eds.,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6121–6133. Association for Computational Linguistics, Online, 2020
2020
-
[41]
Bhatia, R., C. Davis. A better bound on the variance.The american mathematical monthly, 107(4):353–357, 2000
2000
-
[42]
Thomas.Elements of Information Theory
Cover, T., J. Thomas.Elements of Information Theory. Wiley, 2012. 12 Technical Appendices and Supplementary Material Table of Contents A. Training and Evaluation Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 B. Additional Experimental Results . . . . . . . . . . . . . . . . . . . . ....
2012
-
[43]
2.∆ T (t)≤log 2 |V| −Ent(π T (·|x<t))2
Whenπ T (·|x<t) = Uniform(V), we have∆ T (t) = 0andA t depends only on the student. 2.∆ T (t)≤log 2 |V| −Ent(π T (·|x<t))2. 3.SNR T (t) =O(∆ T (t))and decreases monotonically under SFD. Proof. Part (1).When πT (·|x<t) = Uniform(V) , we have πT (xt|x<t) = 1/|V| for every xt ∈ V , so logπ T (xt|x<t) =−log|V| is a constant independent of xt. Therefore ∆T (t)...
-
[44]
When ∆T (t) = 0 , the advantage At = 1 + logπ θ(xt) + log|V| reinforces the student’s existing mode without teacher correction
-
[45]
When∆ T (t)< δ crit,E[d t+1|dt]≥d t, creating a positive feedback loop
-
[46]
relative drift indicator
Forward-KL avoids SFD by construction but introduces exposure bias. Proof sketch.Part (1).From Part (1) of Proposition 1, when∆ T (t) = 0: At = 1 + logπ θ(xt|x<t) + log|V|. Under gradient descent on Lrkl, the update to πθ(xt) is proportional to −At. Since At is an increasing function of logπ θ(xt), the gradient is negative (decreasing πθ(xt)) when πθ(xt)>...
-
[47]
Limitations
Zero-mean:PK k=1 πθ(x(k) t )·r conf(x(k) t )≈0 when top-K probabilities are approximately equal. 2.Graceful degradation:Whenσ K →0,r conf(x(k) t )→0for allk. 3.Scale invariance:The ranking byr conf is invariant to affine transformations ofr raw. Proof.Part (1).By the definition ofµ K: KX k=1 (r(k) raw −µ K) = KX k=1 r(k) raw −Kµ K = 0. Whenπ θ(x(k) t )≈1/...
-
[48]
Guidelines: • The answer NA means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.