Send a SCOUT First: Pre-hoc Reasoning for Adaptive Detector Allocation in Prompt-Injection Defense
Pith reviewed 2026-06-28 22:15 UTC · model grok-4.3
The pith
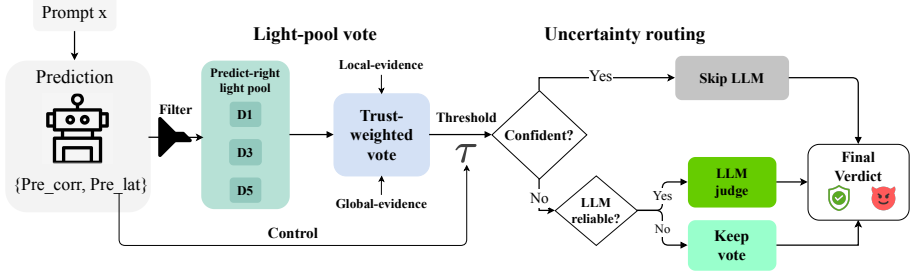
SCOUT allocates prompt-injection detectors per request by predicting each one's reliability and latency from past similar inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
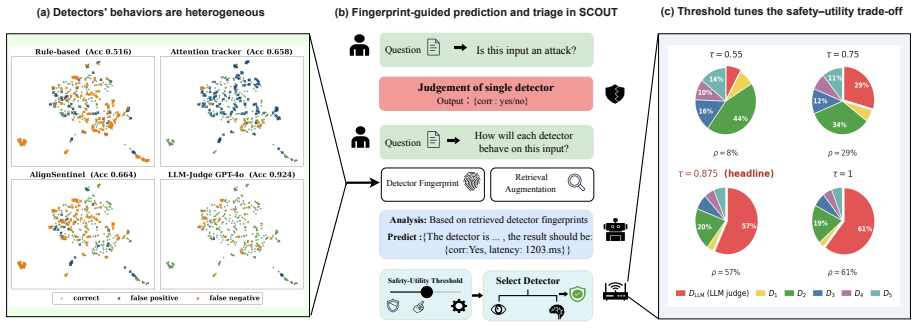
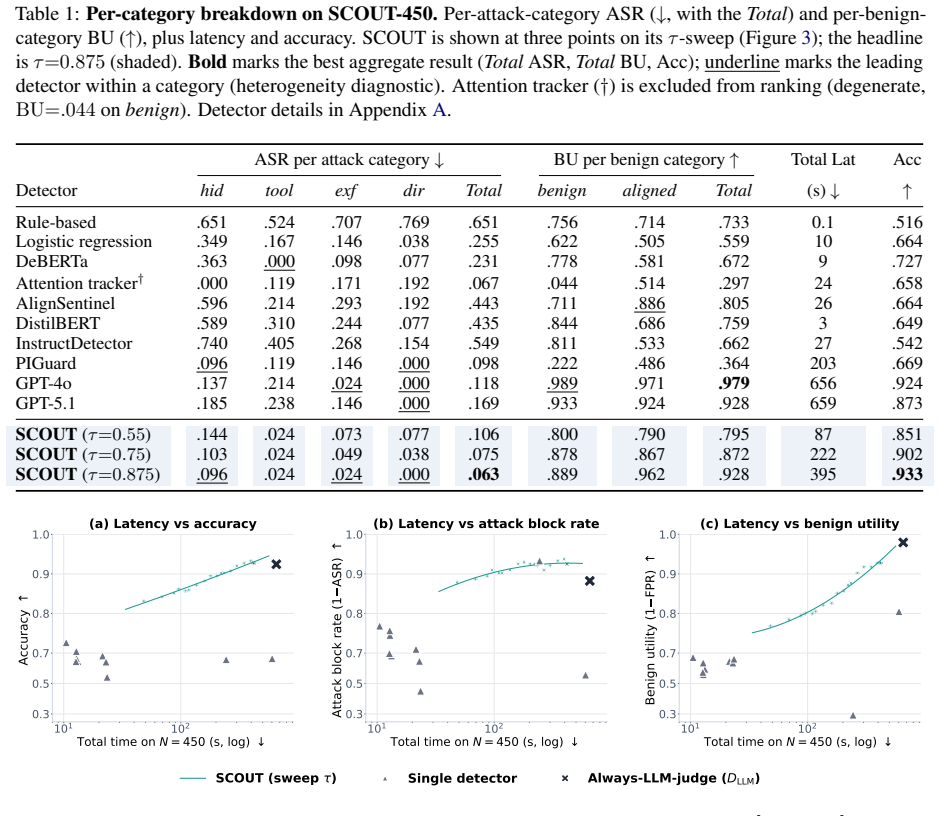
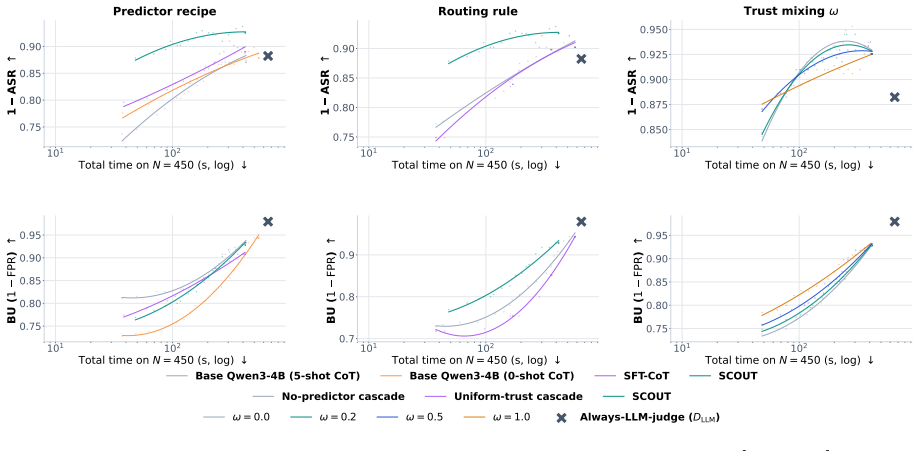
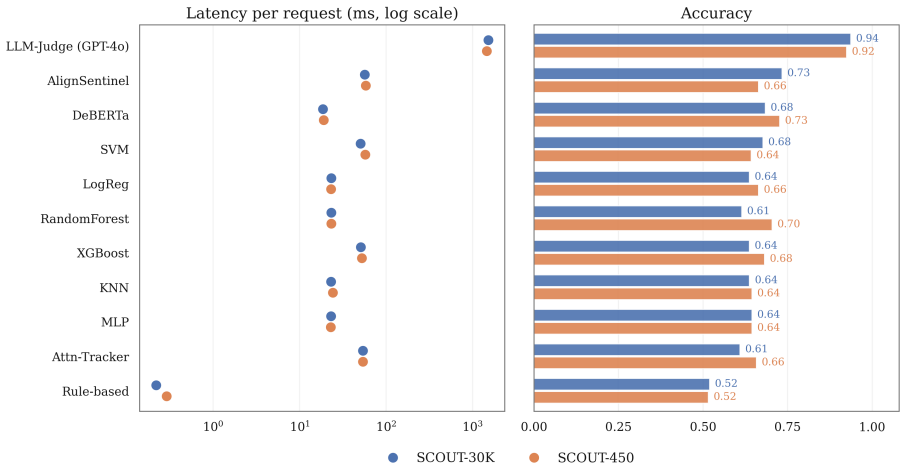
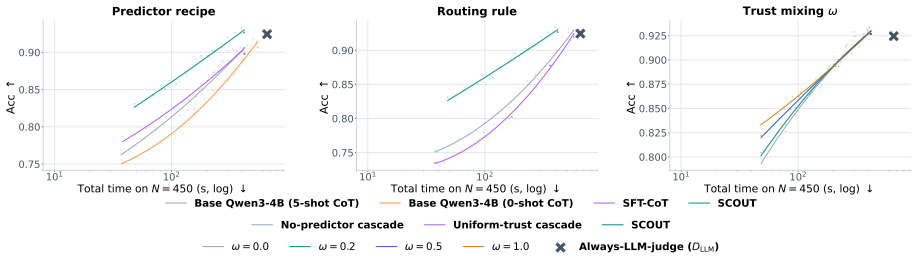
SCOUT forecasts each detector's reliability and latency on the current input from its performance on similar past inputs, then uses those forecasts to decide detector allocation and escalation under a single safety-utility threshold. On SCOUT-450 this produces a 46 percent drop in attack-success rate and 40 percent drop in total wall-clock time versus an always-on GPT-4o judge, with a 5.1-point benign-utility cost. The same allocation policy improves the safety-utility frontier on BIPIA, IPI, and IHEval.
What carries the argument
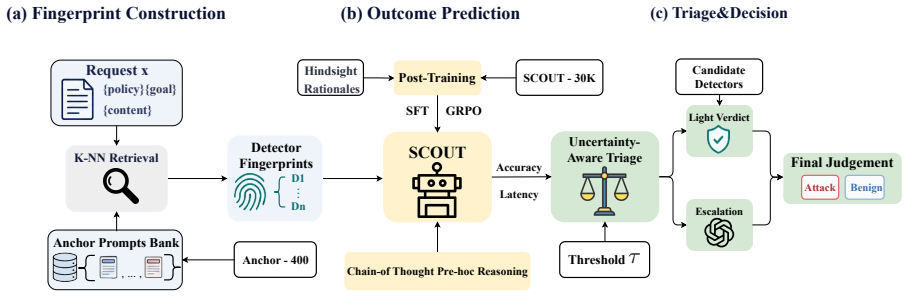
The SCOUT outcome-prediction model that forecasts per-detector reliability and latency to drive per-request allocation and escalation decisions.
If this is right
- A safety-oriented operating point on SCOUT-450 reduces attack-success rate by 46 percent and wall-clock time by 40 percent relative to always-on GPT-4o.
- The same point incurs only a 5.1-point drop in benign utility.
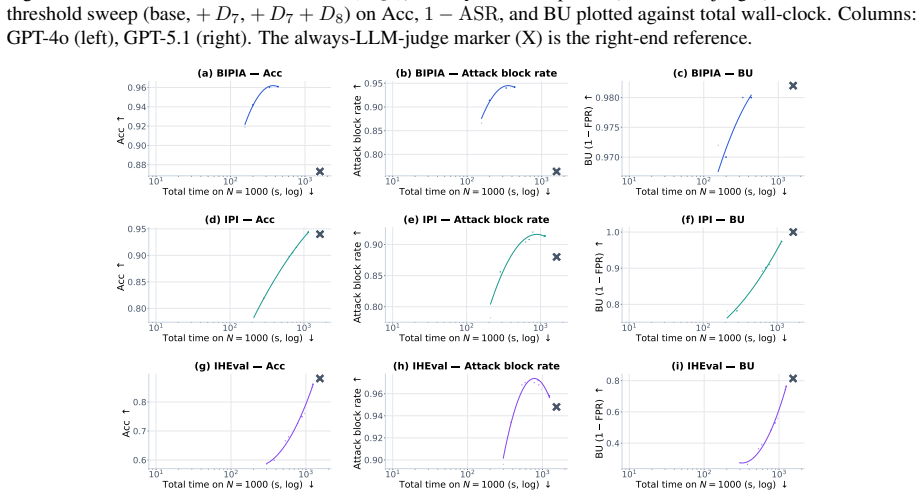
- SCOUT improves the safety-utility frontier when applied to BIPIA, IPI, and IHEval.
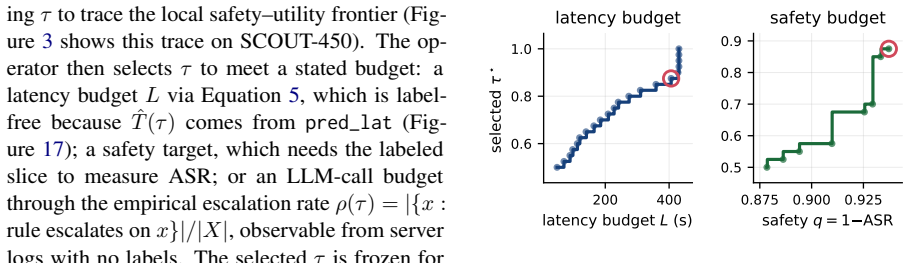
- Operators control the trade-off through one adjustable safety-utility threshold.
Where Pith is reading between the lines
- The same prediction-driven allocation logic could be tested on heterogeneous detectors in other security settings such as malware or phishing classification.
- Collecting additional historical traces over time would likely tighten the reliability forecasts for attacks that evolve after initial training.
- Pairing SCOUT with periodic retraining on recent attacks could maintain accuracy as the distribution of injections shifts.
Load-bearing premise
Predictions drawn from how detectors behaved on similar past inputs will accurately forecast their performance on new structurally complex attacks.
What would settle it
A held-out collection of prompt-injection attacks structurally unlike the historical data where the predicted reliabilities produce allocations whose attack-success rate and latency are no better than those of a fixed single-detector pipeline.
Figures


read the original abstract
Prompt-injection detectors are heterogeneous: each is strong on a different slice of attacks, and none is always reliable. Yet existing systems still treat detection as a fixed single-detector pipeline, committing every request to one detector's blind spots. We reframe defense as detector allocation: given a heterogeneous pool, decide per request which detectors to run and whether to escalate to an LLM judge. Our framework SCOUT (Scalable and Controllable Outcome-prediction for Uncertainty-aware Triage) makes this decision dynamic by predicting each detector's per-sample reliability and latency from how it behaved on similar past inputs, and exposes a single safety-utility threshold to the operator (where utility bundles benign-pass rate and wall-clock). To evaluate this setting, we build SCOUT-450, a benchmark that captures the structurally complex, agent-facing injections that older prompt-injection sets under-represent. On SCOUT-450, a safety-oriented operating point reduces attack-success rate by 46% and total wall-clock by 40% relative to an always-on GPT-4o judge, at a 5.1-point benign-utility drop. SCOUT also transfers to three external benchmarks (BIPIA, IPI, and IHEval), improving the safety-utility frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SCOUT framework for prompt-injection defense, which reframes detection as per-request detector allocation. SCOUT predicts each detector's reliability and latency on a new input by referencing its behavior on similar past inputs, then uses a single tunable safety-utility threshold to decide which detectors to invoke and whether to escalate to an LLM judge. The authors construct the SCOUT-450 benchmark to better capture structurally complex, agent-facing injections and report that a safety-oriented operating point yields a 46% reduction in attack-success rate and 40% reduction in wall-clock time versus an always-on GPT-4o judge (with a 5.1-point benign-utility penalty), while also improving the safety-utility frontier on BIPIA, IPI, and IHEval.
Significance. If the similarity-based prediction mechanism generalizes, the work offers a practical way to exploit detector heterogeneity without committing every query to a single detector's blind spots, potentially lowering both false-negative risk and inference cost in production LLM systems. The release of SCOUT-450 as a benchmark focused on agent-facing attacks is a concrete contribution that could stimulate further research on adaptive defenses.
major comments (4)
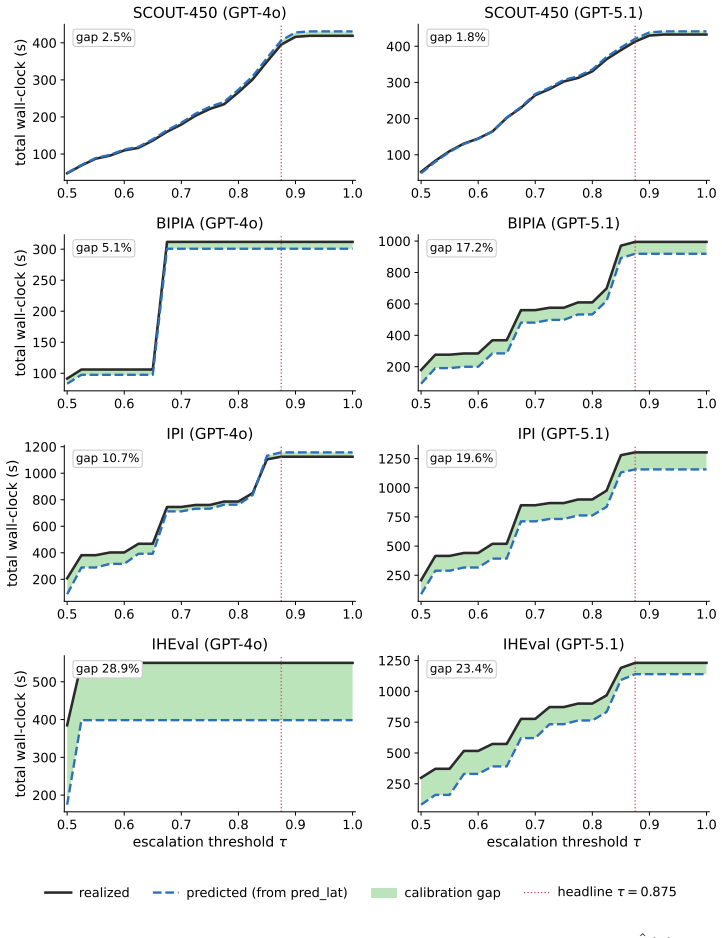
- [Abstract, §4] Abstract and §4 (evaluation results): The headline claims of 46% ASR reduction and 40% wall-clock reduction are stated without error bars, statistical significance tests, or an explicit description of how the safety-utility threshold was selected on SCOUT-450; this leaves open whether the reported operating point was chosen post-hoc or pre-specified, directly affecting the reproducibility of the safety-utility frontier improvement.
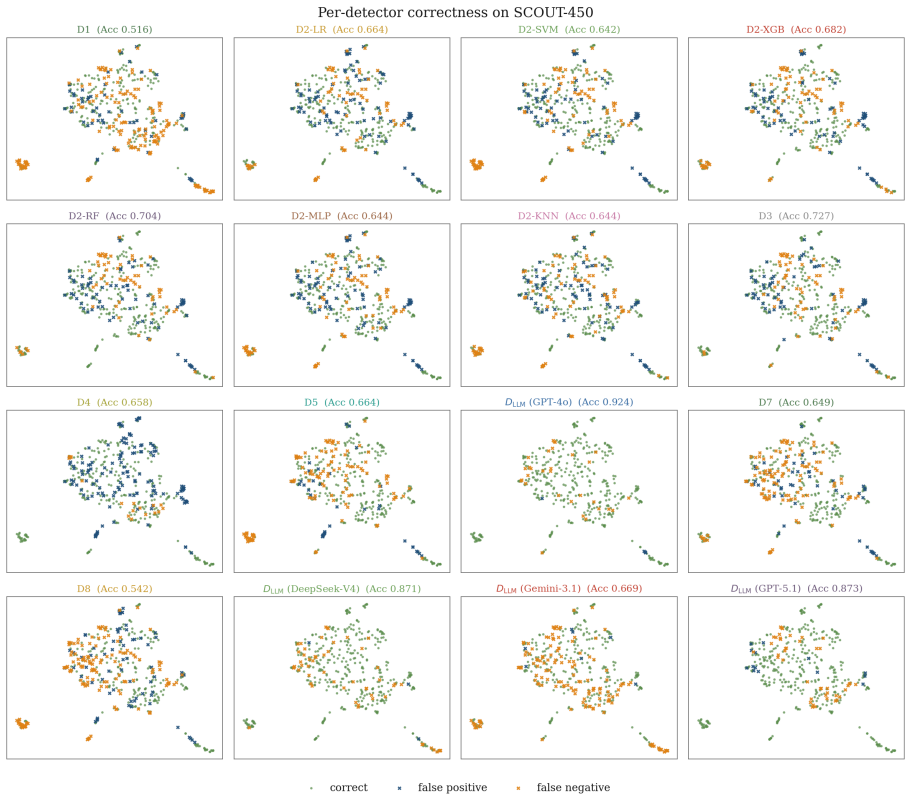
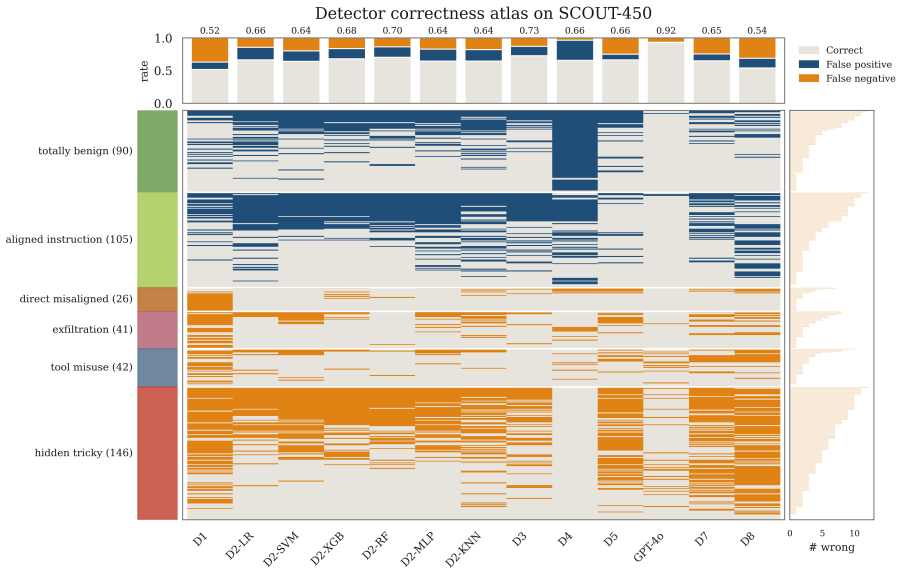
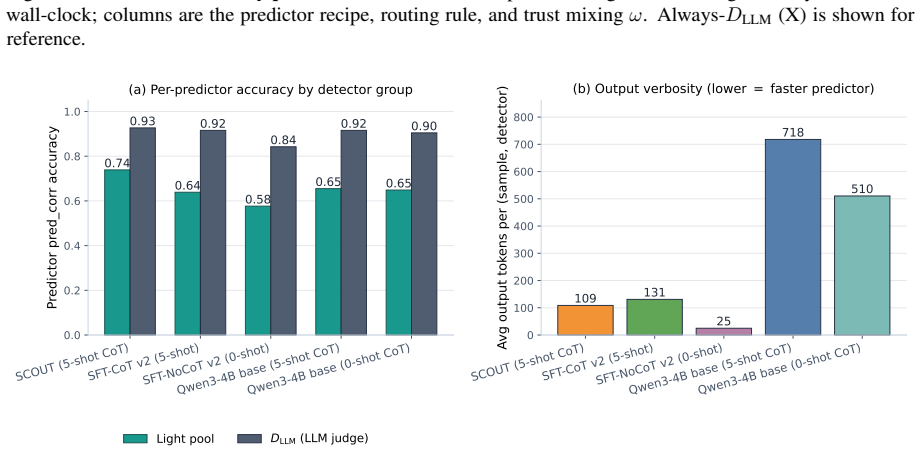
- [§3] §3 (SCOUT prediction mechanism): The method for computing per-sample reliability and latency predictions from similar past inputs is described at a high level but lacks an ablation on the similarity metric (embedding model, feature set, or distance function) and does not report how many historical examples are retrieved or how their outcomes are aggregated; because the central claim rests on these predictions transferring to novel attacks, the absence of such controls is load-bearing.
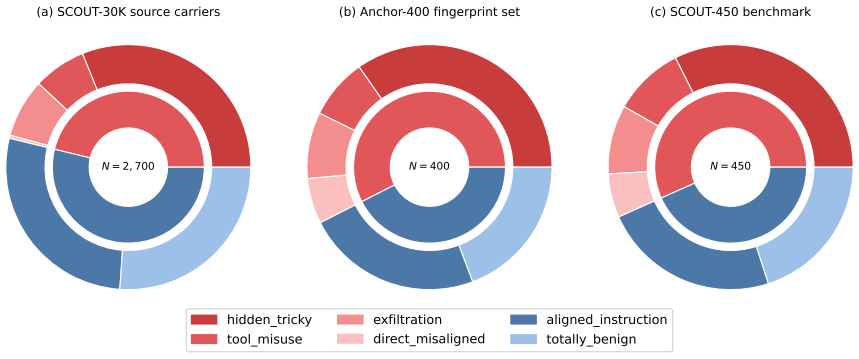
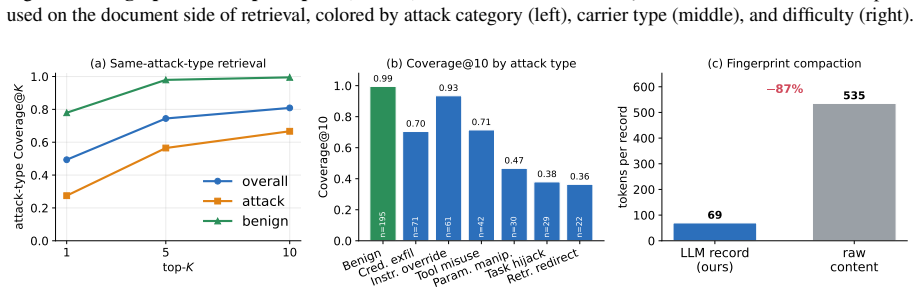
- [§4.1] §4.1 (SCOUT-450 construction): The paper states that SCOUT-450 captures "structurally complex, agent-facing injections" under-represented in prior sets, yet provides no quantitative comparison (e.g., attack taxonomy coverage, structural complexity metrics) against BIPIA/IPI/IHEval or details on how the 450 samples were sampled or generated; without this, it is impossible to verify that the benchmark actually stresses the generalization assumption highlighted in the skeptic note.
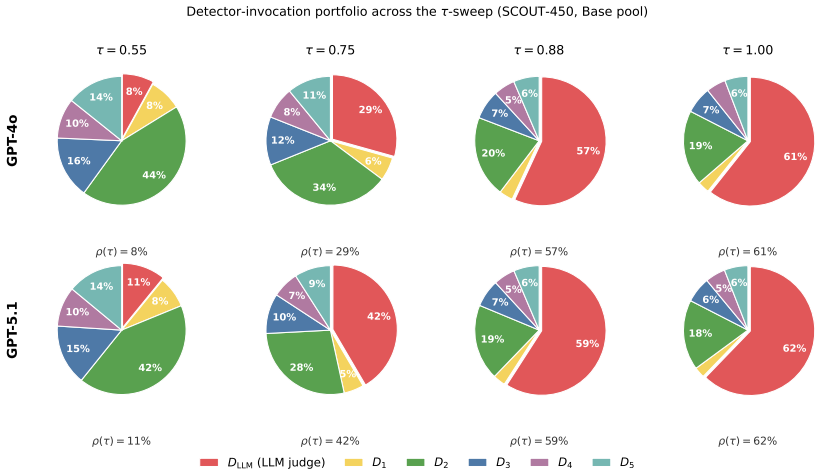
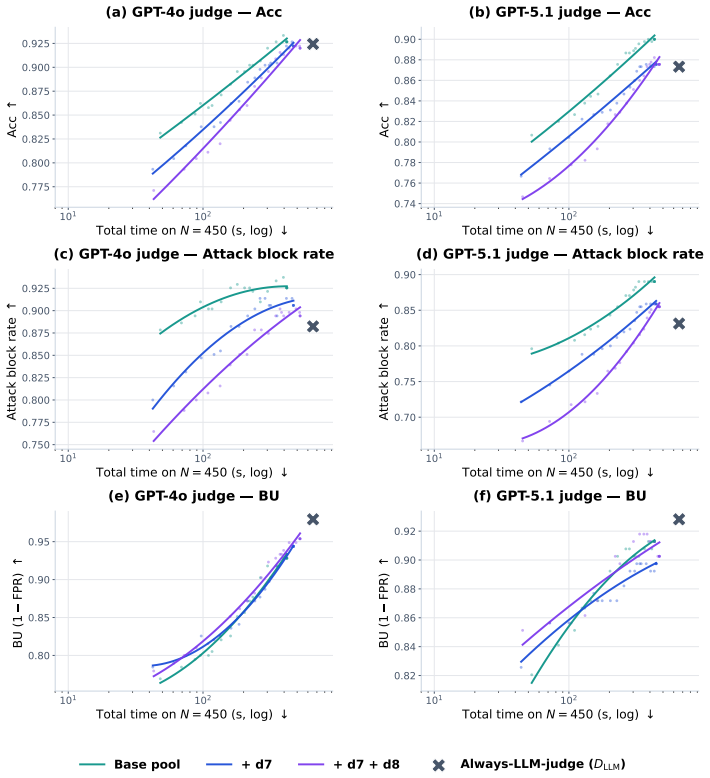
- [§4.3] Transfer experiments (§4.3): The claim that SCOUT improves the safety-utility frontier on the three external benchmarks does not specify whether the safety-utility threshold was held fixed from SCOUT-450 or re-tuned per benchmark, nor does it report per-detector allocation statistics; this information is required to assess whether the gains arise from the pre-hoc reasoning or from benchmark-specific tuning.
minor comments (2)
- [§3] Notation for the safety-utility threshold and the similarity lookup should be introduced with an explicit equation or pseudocode early in §3 rather than only in prose.
- [Figures in §4] Figure captions for the safety-utility frontier plots should include the exact threshold values used for each curve and the number of runs or seeds underlying any shaded regions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen reproducibility and methodological transparency. We address each major point below and will incorporate revisions where they improve the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (evaluation results): The headline claims of 46% ASR reduction and 40% wall-clock reduction are stated without error bars, statistical significance tests, or an explicit description of how the safety-utility threshold was selected on SCOUT-450; this leaves open whether the reported operating point was chosen post-hoc or pre-specified, directly affecting the reproducibility of the safety-utility frontier improvement.
Authors: We agree that error bars, significance testing, and explicit threshold-selection details are needed for reproducibility. The operating point was chosen via grid search on a held-out validation split of SCOUT-450 targeting a fixed safety level; we will add this procedure, report standard errors from 5 random seeds, and include paired t-tests against the GPT-4o baseline in the revised §4. revision: yes
-
Referee: [§3] §3 (SCOUT prediction mechanism): The method for computing per-sample reliability and latency predictions from similar past inputs is described at a high level but lacks an ablation on the similarity metric (embedding model, feature set, or distance function) and does not report how many historical examples are retrieved or how their outcomes are aggregated; because the central claim rests on these predictions transferring to novel attacks, the absence of such controls is load-bearing.
Authors: We will expand §3 with the missing controls: cosine similarity on sentence-transformer embeddings, k=5 nearest neighbors, and mean aggregation of historical outcomes. An ablation table comparing alternative embeddings, distance functions, and k values will be added to demonstrate that the reported gains are robust to these choices. revision: yes
-
Referee: [§4.1] §4.1 (SCOUT-450 construction): The paper states that SCOUT-450 captures "structurally complex, agent-facing injections" under-represented in prior sets, yet provides no quantitative comparison (e.g., attack taxonomy coverage, structural complexity metrics) against BIPIA/IPI/IHEval or details on how the 450 samples were sampled or generated; without this, it is impossible to verify that the benchmark actually stresses the generalization assumption highlighted in the skeptic note.
Authors: We will augment §4.1 with quantitative comparisons (average prompt length, tool-call count, and a 6-category taxonomy coverage) against the three external sets, plus explicit sampling details (stratified draw from production agent traces plus controlled synthetic generation). These additions directly address the request for evidence that SCOUT-450 stresses the generalization claim. revision: yes
-
Referee: [§4.3] Transfer experiments (§4.3): The claim that SCOUT improves the safety-utility frontier on the three external benchmarks does not specify whether the safety-utility threshold was held fixed from SCOUT-450 or re-tuned per benchmark, nor does it report per-detector allocation statistics; this information is required to assess whether the gains arise from the pre-hoc reasoning or from benchmark-specific tuning.
Authors: The threshold was held fixed at the SCOUT-450 safety-oriented value for all transfer runs; we will state this explicitly and add per-benchmark allocation statistics (fraction of queries routed to each detector and to the LLM judge) in the revised §4.3 to clarify that gains stem from the pre-hoc mechanism rather than per-benchmark retuning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper frames SCOUT as using similarity-based predictions of per-detector reliability and latency drawn from historical behavior, then evaluates the resulting allocation policy on the new SCOUT-450 benchmark plus three external sets. No equations, self-citations, or definitional steps are visible that would make the reported safety-utility gains (ASR reduction, wall-clock savings) equivalent to the input data or fitted parameters by construction. The similarity lookup is presented as an empirical mechanism rather than a tautology, and the central claims rest on out-of-sample transfer rather than internal re-labeling of the same quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- safety-utility threshold
axioms (1)
- domain assumption Each detector is strong on a different slice of attacks and none is always reliable.
Reference graph
Works this paper leans on
-
[1]
On the impossibility of separating intel- ligence from judgment: The computational in- tractability of filtering for AI alignment.Preprint, arXiv:2507.07341. Qi Cao, Shuhao Zhang, Ruizhe Zhou, Ruiyi Zhang, Peijia Qin, and Pengtao Xie. 2026. Models under SCOPE: Scalable and controllable routing via pre- hoc reasoning.Preprint, arXiv:2601.22323. Lingjiao Ch...
-
[2]
InProceedings of the 16th ACM Workshop on Artificial Intelligence and Secu- rity, AISec ’23, pages 79–90
Not what you’ve signed up for: Compromis- ing real-world LLM-integrated applications with in- direct prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Secu- rity, AISec ’23, pages 79–90. ACM. Pengcheng He, Jianfeng Gao, and Weizhu Chen
-
[3]
A multi-agent llm defense pipeline against prompt injection attacks,
DeBERTaV3: Improving DeBERTa us- ing ELECTRA-style pre-training with gradient- disentangled embedding sharing. InInternational Conference on Learning Representations (ICLR). S M Asif Hossain, Ruksat Khan Shayoni, Mohd Ruhul Ameen, Akif Islam, M. F. Mridha, and Jung- pil Shin. 2025. A multi-agent LLM defense pipeline against prompt injection attacks.Prepri...
-
[4]
Yinuo Liu, Ruohan Xu, Xilong Wang, Yuqi Jia, and Neil Zhenqiang Gong
Evaluating the instruction-following robust- ness of large language models to prompt injection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 557– 568, Miami, Florida, USA. Association for Compu- tational Linguistics. Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. 2024a. Chain of hindsight aligns language ...
-
[5]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
UMAP: Uniform manifold approximation and projection for dimension reduction.Preprint, arXiv:1802.03426. Nay Myat Min, Long H. Pham, and Jun Sun. 2026. Lay- erwise convergence fingerprints for runtime misbe- havior detection in large language models.Preprint, arXiv:2604.24542. Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chi- ang, Tianhao Wu, Joseph E. ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
ignore the above and instead
LlamaFactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Appendix contents.The appendix is organized in three parts. Method details (A–E). • A Detector pool details. • B Data construction and composition. • C Fingerprint...
2019
-
[7]
for the SFT stage and veRL (Sheng et al.,
-
[8]
for the GRPO stage, both built on Hug- gingFace Transformers (Wolf et al., 2020); infer- ence is served with vLLM (Kwon et al., 2023) batched decoding. Sentence embeddings for the D2 family and for retrieval use Qwen3-Embedding- 0.6B (Zhang et al., 2025b); the D2 classifiers use scikit-learn (Pedregosa et al., 2011) defaults ex- cept for the k-nearest-nei...
-
[9]
as the LLM judge DLLM. To choose it, we first ran five candidate judges (GPT-4o, GPT- 5.1 (OpenAI, 2026), DeepSeek-V3.2 (DeepSeek- AI, 2025), DeepSeek-V4 (DeepSeek-AI, 2026), and Gemini-3.1 (Google DeepMind, 2026)) on Anchor-400 (Section 6) and selected by accuracy (Table 10). We then evaluated the candidates on the held-out SCOUT-450 benchmark to check w...
2026
-
[10]
Detector profile: one sentence describing what this detector does and how it works
-
[11]
Keep to 3 sentences or fewer
Sample characteristics: describe in detail what the sample contains -- whether it is an attack or benign, its category, difficulty, carrier type, attack mechanism (if applicable), and the full content and goal. Keep to 3 sentences or fewer
-
[12]
id": "<sample id>
Prediction result: state what the detector predicted (attack /benign), whether it was correct or incorrect, the confidence score, and the latency in milliseconds. Return ONLY a JSON array, one object per sample, preserving input order: [ { "id": "<sample id>", "detector_profile": "<1 sentence>", "sample_characteristics": "<detailed description>", "predict...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.