Robust Dreamer: Deviation-Aware Latent Gaussian Memory for Action-Controlled AR Video Generation
Pith reviewed 2026-06-28 22:55 UTC · model grok-4.3
The pith
Latent Gaussian Memory anchored to primitives plus synthesized deviations during training prevents drift in long-horizon action-controlled video generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
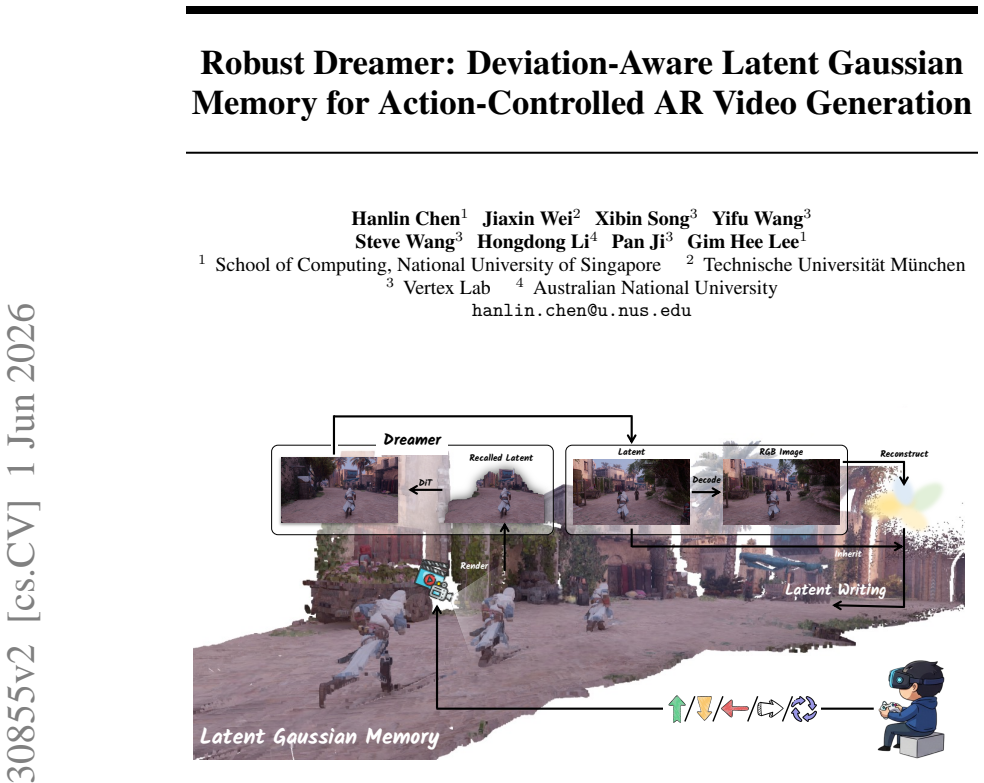
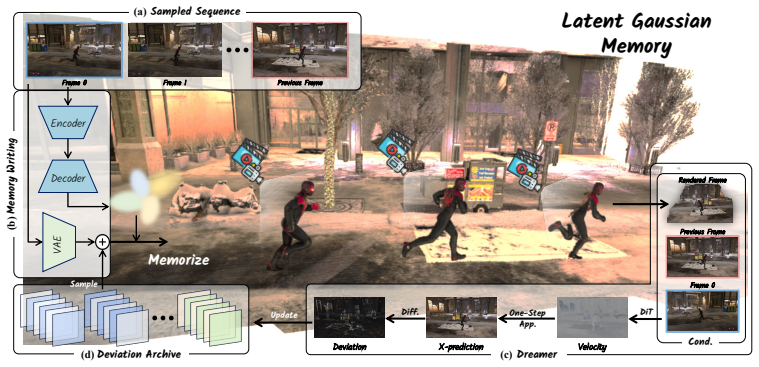
Robust Dreamer claims that anchoring diffusion latents inherited from the generation process to Gaussian primitives and recalling them via latent-space Gaussian splatting supplies dense geometry-aware conditioning without accumulated VAE degradation, while Deviation Learning with Dynamic Deviation Archive synthesizes rollout-induced corruptions through one-step approximation, indexes them by autoregressive stage and denoising timestamp, and injects them into historical memory so the generator learns internal correction before inference.
What carries the argument
Latent Gaussian Memory that anchors diffusion latents to Gaussian primitives recalled by latent-space Gaussian splatting, paired with a Dynamic Deviation Archive that stores one-step-approximated rollout deviations indexed by stage and timestamp.
If this is right
- Autoregressive rollouts maintain 3D consistency without progressive degradation from repeated VAE conversions.
- The generator acquires the ability to correct corrupted historical memory states before they appear at inference time.
- Action signals continue to produce immediate, geometrically coherent visual responses over hundreds of frames.
- Performance gains appear across indoor reconstruction, outdoor driving, and synthetic game environments.
Where Pith is reading between the lines
- The same Gaussian-anchored memory could be tested in other autoregressive generative domains that currently rely on RGB or token cycling.
- If the one-step deviation approximation proves sufficient, full multi-step rollouts may no longer be required to collect realistic training corruptions.
- The archive structure suggests a general way to index and replay distribution shifts indexed by generation time and denoising step.
Load-bearing premise
The one-step approximation used to synthesize rollout-induced latent deviations during training is sufficient to expose the model to the actual distribution of corrupted memory states encountered at inference.
What would settle it
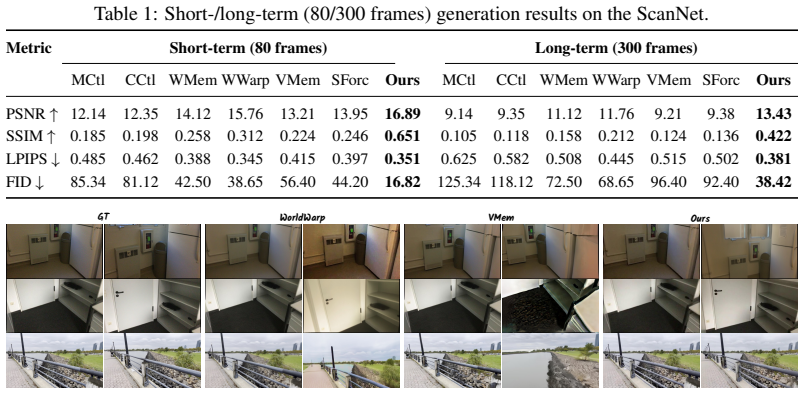
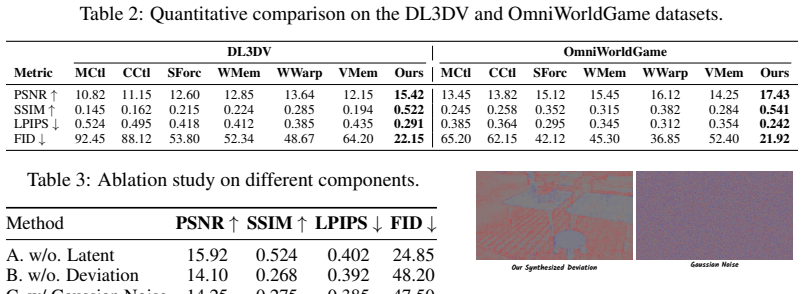
Train two identical generators on the same data, one with the Dynamic Deviation Archive and one without, then measure whether the version lacking the archive exhibits the same rate of 3D drift after 50-plus autoregressive steps on ScanNet or DL3DV as the baselines the paper compares against.
Figures











read the original abstract
Frame-wise action-controlled image-to-video generation is a promising paradigm for interactive world simulation, where each control signal should elicit an immediate visual response. However, maintaining visual fidelity and 3D consistency over long autoregressive rollouts remains challenging. Existing 3D-aware methods often suffer from catastrophic drift due to two impediments: information loss from \textit{Latent--RGB Cycling}, where generated latents are repeatedly decoded to RGB and re-encoded for future conditioning, and the training--inference gap induced by the \textit{error-free hypothesis}, where clean training memory fails to match prediction-corrupted inference memory. To address these challenges, we present \textbf{Robust Dreamer}, a memory-augmented framework built around how to design 3D memory and how to use it robustly. First, we introduce \textbf{Latent Gaussian Memory}, which anchors diffusion latents inherited from the generation process to Gaussian primitives and recalls them via latent-space Gaussian splatting. This provides dense, geometry-aware, view-aligned conditioning while avoiding accumulated degradation from repeated VAE conversion. Second, we propose \textbf{Deviation Learning with Dynamic Deviation Archive}, which synthesizes rollout-induced latent deviations through a one-step approximation, stores them by autoregressive stage and denoising timestamp, and injects them into historical memory during training. This exposes the generator to realistic corrupted memory states and teaches internal correction before inference. Experiments on ScanNet, DL3DV, and OmniWorldGame demonstrate state-of-the-art long-horizon performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Robust Dreamer, a memory-augmented framework for action-controlled autoregressive (AR) video generation. It introduces Latent Gaussian Memory, which anchors diffusion latents to Gaussian primitives and recalls them via latent-space Gaussian splatting to avoid degradation from repeated Latent-RGB Cycling. It further proposes Deviation Learning with Dynamic Deviation Archive, which synthesizes rollout-induced latent deviations via a one-step approximation, stores them by autoregressive stage and denoising timestamp, and injects them into historical memory during training to address the training-inference gap from the error-free hypothesis. Experiments on ScanNet, DL3DV, and OmniWorldGame are claimed to demonstrate state-of-the-art long-horizon performance.
Significance. If the central claims hold, the work addresses practically important impediments to long-horizon consistency in interactive world simulation and AR video generation. The Latent Gaussian Memory approach offers a geometry-aware conditioning mechanism that sidesteps VAE cycling losses, while the deviation archive provides a targeted way to close the train-inference distribution gap. These contributions could influence downstream applications in robotics simulation and controllable video synthesis if supported by rigorous quantitative validation.
major comments (1)
- [Abstract (Deviation Learning with Dynamic Deviation Archive)] Abstract (Deviation Learning with Dynamic Deviation Archive paragraph): The SOTA long-horizon claim depends on Deviation Learning successfully exposing the generator to realistic corrupted memory states. The method relies on a one-step approximation to synthesize rollout-induced latent deviations. This approximation may produce a narrower or differently structured deviation distribution than the multi-step error accumulation that occurs at inference, where generated (deviated) latents are repeatedly fed back as conditioning. Without additional analysis or experiments demonstrating that the one-step distribution is representative of the true inference regime, the internal correction mechanism may remain under-trained for the conditions that determine long-horizon performance.
minor comments (1)
- [Abstract] The abstract introduces terms such as 'Latent--RGB Cycling' and 'error-free hypothesis' without citing the prior work that defines or motivates them; adding these references would improve traceability.
Simulated Author's Rebuttal
We thank the referee for their constructive comment regarding the Deviation Learning component in our manuscript. We provide a point-by-point response below.
read point-by-point responses
-
Referee: Abstract (Deviation Learning with Dynamic Deviation Archive paragraph): The SOTA long-horizon claim depends on Deviation Learning successfully exposing the generator to realistic corrupted memory states. The method relies on a one-step approximation to synthesize rollout-induced latent deviations. This approximation may produce a narrower or differently structured deviation distribution than the multi-step error accumulation that occurs at inference, where generated (deviated) latents are repeatedly fed back as conditioning. Without additional analysis or experiments demonstrating that the one-step distribution is representative of the true inference regime, the internal correction mechanism may remain under-trained for the conditions that determine long-horizon performance.
Authors: We agree with the referee that the one-step approximation is a key design choice whose fidelity to the multi-step inference distribution merits further validation. In the original manuscript, we describe the one-step approximation as a practical means to generate deviations at each autoregressive stage and denoising timestamp for storage in the Dynamic Deviation Archive. To strengthen the evidence, we will add in the revision: (1) a quantitative comparison of deviation statistics (e.g., mean and variance of latent differences) between one-step synthesized deviations and those accumulated over multiple steps in short rollouts, and (2) an ablation showing long-horizon performance when training with the one-step vs. a more expensive multi-step deviation synthesis on a smaller dataset. This will directly address whether the approximation sufficiently covers the inference regime. revision: yes
Circularity Check
No circularity: engineering framework with no self-referential derivations or fitted predictions
full rationale
The provided abstract and description introduce Latent Gaussian Memory (anchoring diffusion latents to Gaussian primitives) and Deviation Learning with Dynamic Deviation Archive (one-step synthesis of rollout deviations stored by stage/timestamp). These are presented as design choices to address information loss and training-inference gap, without any equations, uniqueness theorems, or derivations that reduce a claimed result to a quantity defined by the method itself. No self-citations are invoked as load-bearing premises, no ansatzes are smuggled, and no predictions are statistically forced by fitting. The approach is self-contained as an empirical engineering solution; the one-step approximation is an explicit modeling choice, not a circular redefinition of the target distribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers.arXiv preprint arXiv:2411.18673, 2024
arXiv 2024
-
[2]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, Ci...
2025
-
[3]
PixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. PixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D reconstruction. InCVPR, 2024
2024
-
[4]
Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2025
2025
-
[5]
Gnesf: Generalizable neural semantic fields
Hanlin Chen, Chen Li, Mengqi Guo, Zhiwen Yan, and Gim Hee Lee. Gnesf: Generalizable neural semantic fields. InNeurIPS, 2023
2023
-
[6]
Hanlin Chen, Chen Li, and Gim Hee Lee. Neusg: Neural implicit surface reconstruction with 3d gaussian splatting guidance.arXiv preprint arXiv:2312.00846, 2023
arXiv 2023
-
[7]
Hanlin Chen, Fangyin Wei, Chen Li, Tianxin Huang, Yunsong Wang, and Gim Hee Lee. Vcr-gaus: View consistent depth-normal regularizer for gaussian surface reconstruction.arXiv preprint arXiv:2406.05774, 2024
arXiv 2024
-
[8]
Ttt3r: 3d reconstruction as test-time training.arXiv preprint arXiv:2509.26645, 2025
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruction as test-time training.arXiv preprint arXiv:2509.26645, 2025
Pith/arXiv arXiv 2025
-
[9]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InECCV, 2024
2024
-
[10]
Mvsplat360: Feed-forward 360 scene synthesis from sparse views
Yuedong Chen, Chuanxia Zheng, Haofei Xu, Bohan Zhuang, Andrea Vedaldi, Tat-Jen Cham, and Jianfei Cai. Mvsplat360: Feed-forward 360 scene synthesis from sparse views. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[11]
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong Wang, Hongwei Yi, Xihui Liu, Hengshuang Zhao, et al. Wan-move: Motion-controllable video generation via latent trajectory guidance.arXiv preprint arXiv:2512.08765, 2025
arXiv 2025
-
[12]
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
Pith/arXiv arXiv 2025
-
[13]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[14]
Oasis: A universe in a transformer
Decart, Julian Quevedo, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer. 2024
2024
-
[15]
Veo 3 technical report
Google DeepMind. Veo 3 technical report. Technical report, Google, 2025
2025
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021. 10
2021
-
[17]
Y . Duan, S. Ren, J. Luo, Y . Chen, H. Wang, L. Zheng, and Q. Dai. 4d radiance fields with multi-scale occupancy networks for dynamic scene reconstruction. InCVPR, 2024
2024
-
[18]
4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes
Yuanxing Duan, Fangyin Wei, Qiyu Dai, Yuhang He, Wenzheng Chen, and Baoquan Chen. 4d-rotor gaussian splatting: towards efficient novel view synthesis for dynamic scenes. InACM SIGGRAPH 2024 Conference Papers, 2024
2024
-
[19]
Yuwei Guo, Ceyuan Yang, Hao He, Yang Zhao, Meng Wei, Zhenheng Yang, Weilin Huang, and Dahua Lin. End-to-end training for autoregressive video diffusion via self-resampling.arXiv preprint arXiv:2512.15702, 2025
arXiv 2025
-
[20]
Cameractrl: Enabling camera control for text-to-video generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation. InICLR, 2025
2025
-
[21]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-Game 2.0: An Open-Source Real-Time and Streaming Interactive World Model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
arXiv preprint arXiv:2512.04040 , year=
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, et al. RELIC: Interactive Video World Model with Long-Horizon Memory.arXiv preprint arXiv:2512.04040, 2025
-
[23]
2D Gaussian splatting for geometrically accurate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2D Gaussian splatting for geometrically accurate radiance fields. InSIGGRAPH 2024 Conference Papers. ACM, 2024
2024
-
[24]
V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Rynson Lau, Wangmeng Zuo, et al. V oyager: Long-range and world-consistent video diffusion for explorable 3d scene generation.ACM Transactions on Graphics (TOG), 44(6):1–15, 2025
2025
-
[25]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
InSpatio Team. InSpatio: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling. arXiv preprint arXiv:2604.07209, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
3d gaussian splatting for real-time radiance field rendering.ACM TOG, 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM TOG, 2023
2023
-
[28]
Hanyang Kong, Xingyi Yang, Xiaoxu Zheng, and Xinchao Wang. Worldwarp: Propagating 3d geometry with asynchronous video diffusion.arXiv preprint arXiv:2512.19678, 2025
-
[29]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jerome Revaud. Grounding image matching in 3d with mast3r. arXiv:2406.09756, 2024
-
[30]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. In European Conference on Computer Vision, pages 71–91. Springer, 2024
2024
-
[31]
Guangyuan Li, Siming Zheng, Shuolin Xu, Jinwei Chen, Bo Li, Xiaobin Hu, Lei Zhao, and Peng-Tao Jiang. Magicworld: Interactive geometry-driven video world exploration.arXiv preprint arXiv:2511.18886, 2025
-
[32]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2025
-
[33]
arXiv preprint arXiv:2506.18903 (2025) 2, 4, 9, 10, 11, 21, 25
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
-
[34]
Teng Li, Guangcong Zheng, Rui Jiang, Tao Wu, Yehao Lu, Yining Lin, Xi Li, et al. Realcam- i2v: Real-world image-to-video generation with interactive complex camera control.arXiv preprint arXiv:2502.10059, 2025
-
[35]
Wuyang Li, Wentao Pan, Po-Chien Luan, Yang Gao, and Alexandre Alahi. Stable video infinity: Infinite- length video generation with error recycling.arXiv preprint arXiv:2510.09212, 2025
-
[36]
DL3DV-10K: a large-scale scene dataset for deep learning-based 3D vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. DL3DV-10K: a large-scale scene dataset for deep learning-based 3D vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 11
2024
-
[37]
Infinite nature: Perpetual view generation of natural scenes from a single image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite nature: Perpetual view generation of natural scenes from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14458–14467, 2021
2021
-
[38]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
Pith/arXiv arXiv 2025
-
[39]
See4d: Pose-free 4d generation via auto-regressive video inpainting
Dongyue Lu, Ao Liang, Tianxin Huang, Xiao Fu, Yuyang Zhao, Baorui Ma, Liang Pan, Wei Yin, Lingdong Kong, Wei Tsang Ooi, and Ziwei Liu. See4d: Pose-free 4d generation via auto-regressive video inpainting. arXiv preprint arXiv:2510.26796, 2025
arXiv 2025
-
[40]
Scaffold-gs: Structured 3d gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20654–20664, 2024
2024
-
[41]
Dynamic 3D Gaussians: tracking by persistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3D Gaussians: tracking by persistent dynamic view synthesis. In3DV, 2024
2024
-
[42]
Yuta Oshima, Yusuke Iwasawa, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Worldpack: Com- pressed memory improves spatial consistency in video world modeling.arXiv preprint arXiv:2512.02473, 2025
arXiv 2025
-
[43]
Stefan Popov, Amit Raj, Michael Krainin, Yuanzhen Li, William T Freeman, and Michael Rubinstein. Cam- ctrl3d: Single-image scene exploration with precise 3d camera control.arXiv preprint arXiv:2501.06006, 2025
arXiv 2025
-
[44]
Langsplat: 3d language gaus- sian splatting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaus- sian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20051–20060, 2024
2024
-
[45]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[46]
Genwarp: Single image to novel views with semantic- preserving generative warping
Junyoung Seo, Kazumi Fukuda, Takashi Shibuya, Takuya Narihira, Naoki Murata, Shoukang Hu, Chieh- Hsin Lai, Seungryong Kim, and Yuki Mitsufuji. Genwarp: Single image to novel views with semantic- preserving generative warping. InNeurIPS, 2024
2024
-
[47]
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
Pith/arXiv arXiv 2024
-
[48]
History- guided video diffusion, 2025
Kiwhan Song, Boyuan Chen, Max Simchowitz, Yilun Du, Russ Tedrake, and Vincent Sitzmann. History- guided video diffusion, 2025
2025
-
[49]
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling.arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[50]
Shengji Tang, Weicai Ye, Peng Ye, Weihao Lin, Yang Zhou, Tao Chen, and Wanli Ouyang. Hisplat: Hierar- chical 3d gaussian splatting for generalizable sparse-view reconstruction.arXiv preprint arXiv:2410.06245, 2024
arXiv 2024
-
[51]
Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Pith/arXiv arXiv 2025
-
[52]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[53]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[54]
Jing Wang et al. Error analyses of auto-regressive video diffusion models: A unified framework.arXiv preprint arXiv:2503.10704, 2025
arXiv 2025
-
[55]
Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state.arXiv preprint arXiv:2501.12387, 2025
arXiv 2025
-
[56]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024
2024
-
[57]
DUSt3R: geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: geometric 3D vision made easy. InCVPR, 2024
2024
-
[58]
Gov-nesf: Generalizable open-vocabulary neural semantic fields
Yunsong Wang, Hanlin Chen, and Gim Hee Lee. Gov-nesf: Generalizable open-vocabulary neural semantic fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20443–20453, 2024
2024
-
[59]
Yunsong Wang, Tianxin Huang, Hanlin Chen, and Gim Hee Lee. Freesplat: Generalizable 3d gaussian splatting towards free-view synthesis of indoor scenes.arXiv preprint arXiv:2405.17958, 2024
arXiv 2024
-
[60]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[61]
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and W. Xinggang. 4d gaussian splatting for real-time dynamic scene rendering.arXiv preprint arXiv:2310.08528, 2023
arXiv 2023
-
[62]
Haoyu Wu, Diankun Wu, Tianyu He, Junliang Guo, Yang Ye, Yueqi Duan, and Jiang Bian. Geometry forcing: Marrying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982, 2025
Pith/arXiv arXiv 2025
-
[63]
Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
arXiv 2025
-
[64]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
arXiv 2025
-
[65]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[66]
Zeyu Yang, Hongye Yang, Zijie Pan, Xiatian Zhu, and Li Zhang. Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting.arXiv preprint arXiv:2310.10642, 2023
arXiv 2023
-
[67]
Botao Ye, Sifei Liu, Haofei Xu, Li Xueting, Marc Pollefeys, Ming-Hsuan Yang, and Peng Songyou. No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207, 2024
arXiv 2024
-
[68]
gsplat: An open-source library for gaussian splatting
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, and Angjoo Kanazawa. gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research, 26(34):1–17, 2025
2025
-
[69]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self-rollout.arXiv preprint arXiv:2511.20649, 2025
arXiv 2025
-
[70]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
2025
-
[71]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
2025
-
[72]
Mark YU, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2025. 13
arXiv 2025
-
[73]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. ViewCrafter: taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
Pith/arXiv arXiv 2024
-
[74]
Gaussian opacity fields: Efficient adaptive surface reconstruction in unbounded scenes.ACM Transactions on Graphics, 2024
Zehao Yu, Torsten Sattler, and Andreas Geiger. Gaussian opacity fields: Efficient adaptive surface reconstruction in unbounded scenes.ACM Transactions on Graphics, 2024
2024
-
[75]
Chuanrui Zhang, Yingshuang Zou, Zhuoling Li, Minmin Yi, and Haoqian Wang. Transplat: Generalizable 3d gaussian splatting from sparse multi-view images with transformers.arXiv preprint arXiv:2408.13770, 2024
arXiv 2024
-
[76]
Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame Context Packing and Drift Prevention in Next-Frame-Prediction Video Diffusion Models. InNeurIPS, 2025
2025
-
[77]
Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Ze- dong Gao, Eric Li, Yang Liu, et al. Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
arXiv 2025
-
[78]
Spatia: Video Generation with Updatable Spatial Memory.arXiv preprint arXiv:2512.15716, 2025
Jinjing Zhao, Fangyun Wei, Zhening Liu, Hongyang Zhang, Chang Xu, and Yan Lu. Spatia: Video Generation with Updatable Spatial Memory.arXiv preprint arXiv:2512.15716, 2025
arXiv 2025
-
[79]
Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis
Shunyuan Zheng, Boyao Zhou, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, and Yebin Liu. Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19680–19690, 2024
2024
-
[80]
Yang Zhou, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Haoyu Guo, Zizun Li, Kaijing Ma, Xinyue Li, Yating Wang, Haoyi Zhu, Mingyu Liu, Dingning Liu, Jiange Yang, Zhoujie Fu, Junyi Chen, Chunhua Shen, Jiangmiao Pang, Kaipeng Zhang, and Tong He. Omniworld: A multi-domain and multi-modal dataset for 4d world modeling.arXiv preprint arXiv:2509.12201, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.