dMoE: dLLMs with Learnable Block Experts
Pith reviewed 2026-06-28 22:48 UTC · model grok-4.3
The pith
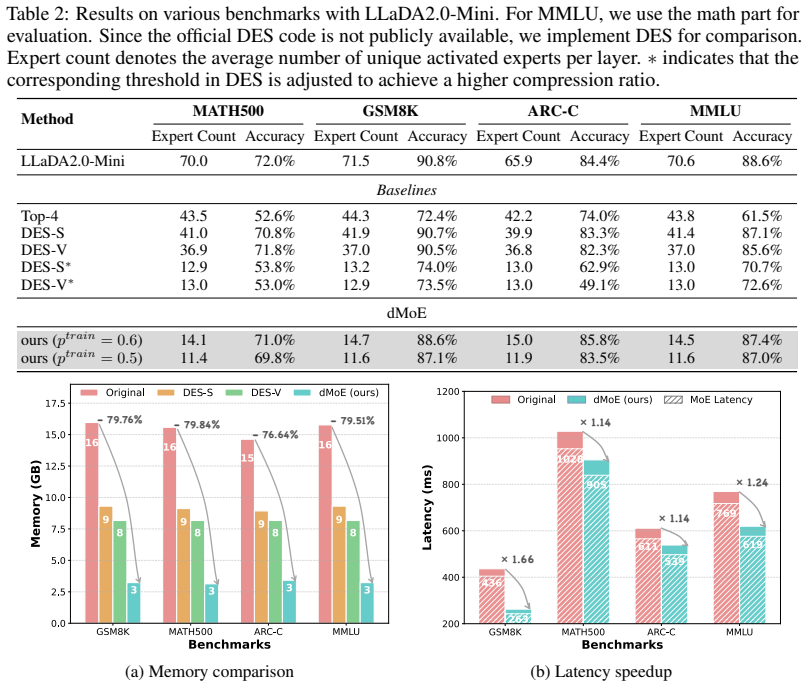
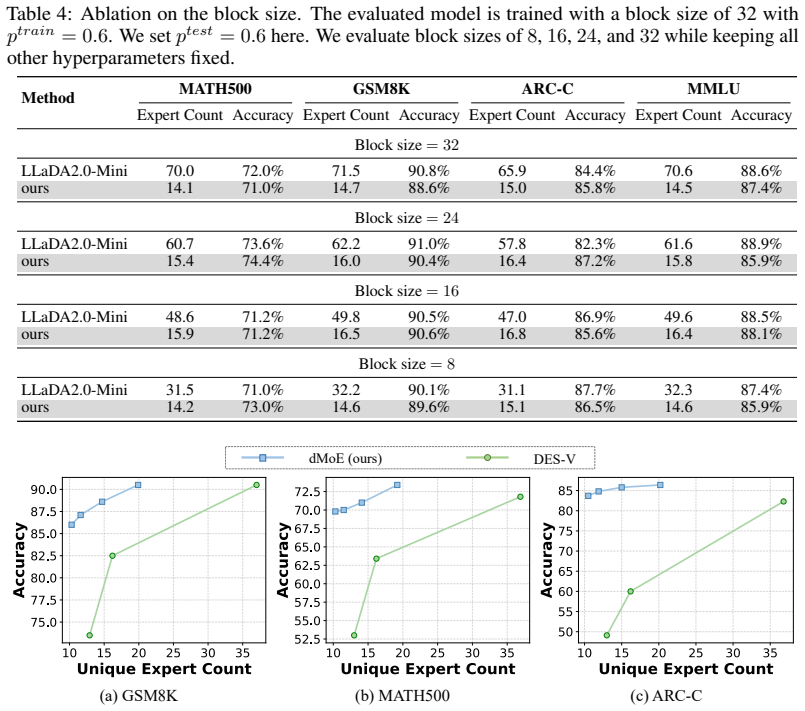
Aggregating per-token expert distributions into block-level ones reduces unique activations from 69.5 to 14.6 in dLLMs while retaining 99.11% performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
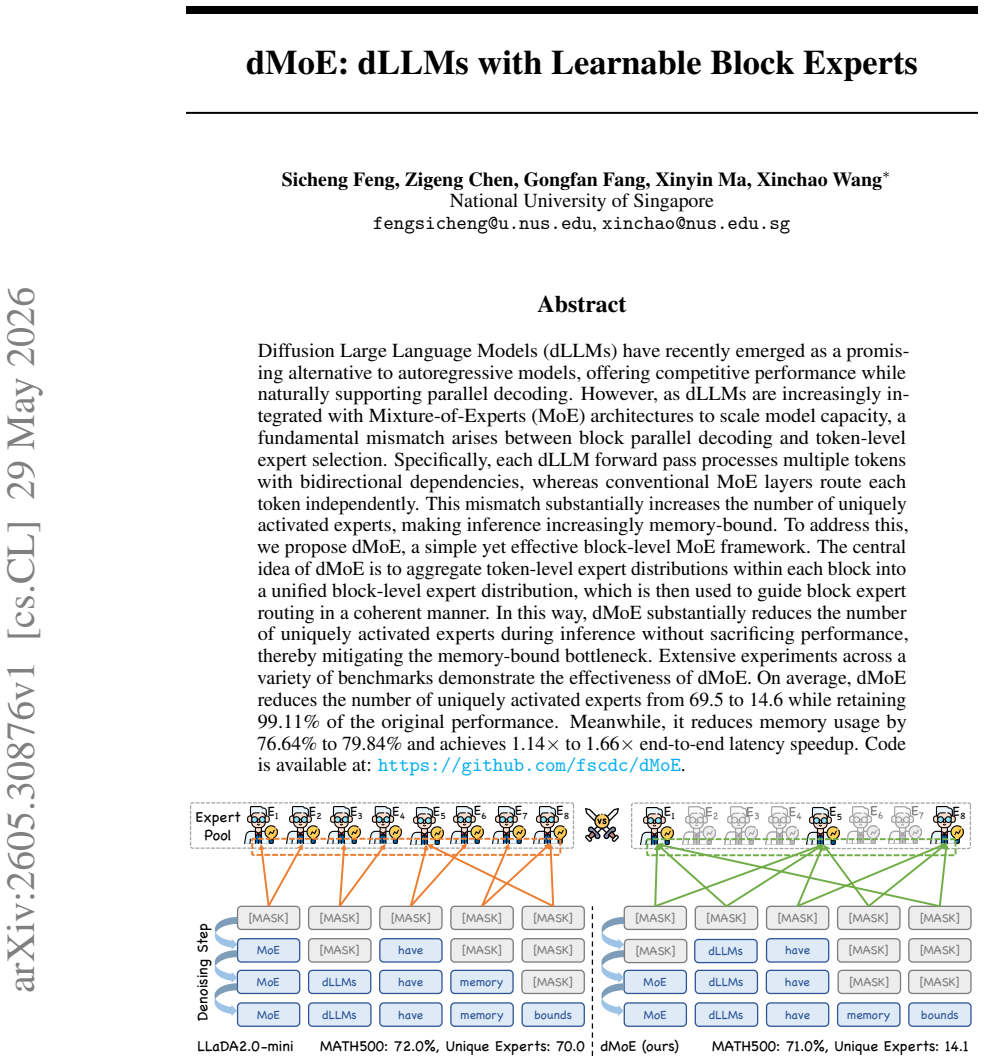
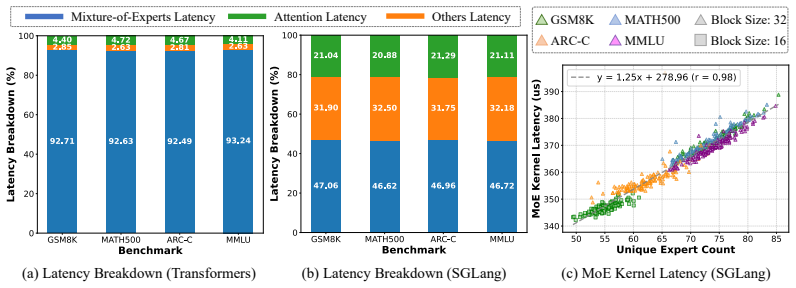
By replacing independent token-level routing with a unified block-level expert distribution formed by aggregation, dMoE reduces the number of uniquely activated experts from 69.5 to 14.6 on average, retains 99.11% of baseline performance, lowers memory usage by 76.64% to 79.84%, and delivers 1.14× to 1.66× end-to-end latency speedup across benchmarks.
What carries the argument
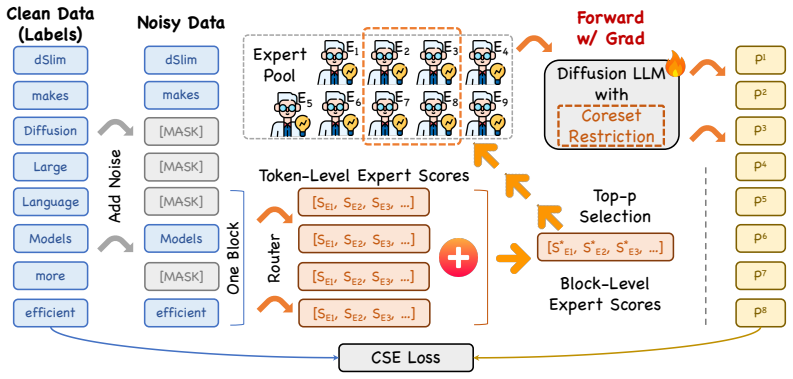
The block-level expert distribution obtained by aggregating token-level distributions within each diffusion block, which then determines a single coherent set of experts for the block.
If this is right
- Inference steps become far less memory-bound because only a small shared set of experts must be loaded per block.
- The reduction in unique expert count directly enables larger MoE models inside diffusion frameworks without proportional memory growth.
- End-to-end speedups of 1.14×–1.66× follow from the lower memory traffic during parallel decoding.
- Performance retention at 99.11% indicates the block-level signal is sufficient for the routing decisions the model actually needs.
Where Pith is reading between the lines
- The same aggregation principle could be tested in other parallel-decoding settings such as speculative decoding or non-autoregressive translation.
- If the block distribution is learned jointly with the experts, the model may discover optimal granularity for different layers or sequence positions.
- On longer contexts the memory savings may compound because fewer experts stay resident across successive blocks.
- The approach raises the question of whether expert specialization in MoE truly requires per-token granularity or can tolerate coarser routing in many domains.
Load-bearing premise
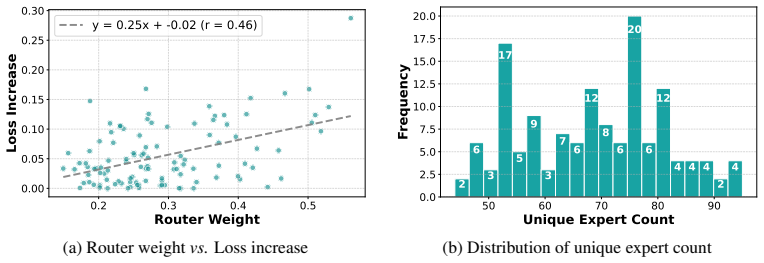
Aggregating per-token expert distributions into one block-level distribution still preserves enough routing signal to avoid degrading model quality.
What would settle it
An ablation that applies the same block aggregation to a dLLM on a task known to require sharply different expert choices for tokens inside the same block and measures whether task accuracy falls below the token-level baseline by more than 1%.
Figures
read the original abstract
Diffusion Large Language Models (dLLMs) have recently emerged as a promising alternative to autoregressive models, offering competitive performance while naturally supporting parallel decoding. However, as dLLMs are increasingly integrated with Mixture-of-Experts (MoE) architectures to scale model capacity, a fundamental mismatch arises between block parallel decoding and token-level expert selection. Specifically, each dLLM forward pass processes multiple tokens with bidirectional dependencies, whereas conventional MoE layers route each token independently. This mismatch substantially increases the number of uniquely activated experts, making inference increasingly memory-bound. To address this, we propose dMoE, a simple yet effective block-level MoE framework. The central idea of dMoE is to aggregate token-level expert distributions within each block into a unified block-level expert distribution, which is then used to guide expert routing in a more coherent manner. In this way, dMoE substantially reduces the number of uniquely activated experts during inference without sacrificing performance, thereby mitigating the memory-bound bottleneck. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of dMoE. On average, dMoE reduces the number of uniquely activated experts from 69.5 to 14.6 while retaining 99.11% of the original performance. Meanwhile, it reduces memory usage by 76.64% to 79.84% and achieves 1.14$\times$ to 1.66$\times$ end-to-end latency speedup. Code is available at: https://github.com/fscdc/dMoE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes dMoE, a block-level MoE framework for diffusion LLMs (dLLMs) that aggregates per-token expert distributions within each parallel decoding block into a single block-level distribution to guide expert selection. This is intended to resolve the mismatch between block-parallel decoding and conventional token-level routing, which inflates the number of uniquely activated experts. The central empirical claim is that dMoE reduces unique experts from 69.5 to 14.6 on average while retaining 99.11% of baseline performance, cuts memory usage by 76.64–79.84%, and yields 1.14–1.66× end-to-end latency speedup across benchmarks.
Significance. If the reported gains are reproducible and the aggregation operator does not systematically discard critical routing information, the method would offer a practical route to scaling MoE capacity in dLLMs without exacerbating memory-bound inference. The simplicity of the aggregation step and the magnitude of the claimed expert-count reduction are notable strengths, but the absence of any experimental protocol, baseline definitions, dataset details, variance statistics, or ablation of the aggregation operator in the abstract leaves the central performance-retention claim unverified and the load-bearing assumption (that block-level aggregation preserves sufficient routing signal) untested.
major comments (3)
- [Abstract] Abstract: the quantitative claims (expert reduction 69.5 o14.6, 99.11% performance retention, memory and latency figures) are presented without any description of model sizes, training or evaluation datasets, baseline MoE configurations, performance metrics, or statistical variance. These omissions are load-bearing for the central claim that quality is retained while unique experts drop sharply.
- [Abstract] Abstract / §3 (method description): no ablation or comparison is reported for the aggregation operator (average, max, learned combiner, etc.) used to form the block-level distribution from per-token router outputs. This directly tests whether the 0.89% average drop is robust or whether divergent per-token preferences within bidirectional blocks cause larger localized degradations.
- [Abstract] Abstract: the paper states that dMoE “substantially reduces the number of uniquely activated experts … without sacrificing performance,” yet supplies neither per-block performance breakdowns nor any verification that the observed expert reduction is caused by the proposed aggregation rather than other implementation choices (e.g., changed top-k, capacity factors, or training schedule).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below. Where the concerns identify gaps in the current presentation, we commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the quantitative claims (expert reduction 69.5 to 14.6, 99.11% performance retention, memory and latency figures) are presented without any description of model sizes, training or evaluation datasets, baseline MoE configurations, performance metrics, or statistical variance. These omissions are load-bearing for the central claim that quality is retained while unique experts drop sharply.
Authors: We agree that the abstract would benefit from additional context. The model sizes, training/evaluation datasets, baseline configurations, metrics, and variance statistics are reported in Sections 4 and 5 of the manuscript. In the revision we will expand the abstract to briefly state the model scale, primary benchmarks, and that results are averaged across runs with reported standard deviation, while retaining the abstract's conciseness. revision: yes
-
Referee: [Abstract] Abstract / §3 (method description): no ablation or comparison is reported for the aggregation operator (average, max, learned combiner, etc.) used to form the block-level distribution from per-token router outputs. This directly tests whether the 0.89% average drop is robust or whether divergent per-token preferences within bidirectional blocks cause larger localized degradations.
Authors: The current implementation uses mean aggregation of the per-token router logits within each block (Section 3). We acknowledge that an explicit ablation of alternative operators would strengthen the paper. We will add this ablation (mean vs. max vs. sum) in the revised version, including per-block performance breakdowns to verify robustness. revision: yes
-
Referee: [Abstract] Abstract: the paper states that dMoE “substantially reduces the number of uniquely activated experts … without sacrificing performance,” yet supplies neither per-block performance breakdowns nor any verification that the observed expert reduction is caused by the proposed aggregation rather than other implementation choices (e.g., changed top-k, capacity factors, or training schedule).
Authors: The reduction in unique experts follows directly from replacing independent token-level routing with a single block-level distribution (Section 3); all other hyperparameters remain identical to the baseline. Overall performance retention is measured across the full evaluation suite. To address the request for isolation, we will add control experiments and per-block metrics in the revision. revision: yes
Circularity Check
No circularity: empirical outcomes from design choice
full rationale
The paper's core claims consist of measured experimental outcomes (expert count reduced from 69.5 to 14.6, 99.11% performance retention, memory and latency gains) obtained after applying the block-level aggregation design. No equations, fitted parameters, or self-citations are shown that would make these quantities equivalent to the inputs by construction. The aggregation operator is a methodological choice whose effects are validated externally via benchmarks rather than being tautological. This is the standard non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion models in text generation: a survey.PeerJ Computer Science, 2024
Qiuhua Yi, Xiangfan Chen, Chenwei Zhang, Zehai Zhou, Linan Zhu, and Xiangjie Kong. Diffusion models in text generation: a survey.PeerJ Computer Science, 2024
2024
-
[2]
Lingzhe Zhang, Liancheng Fang, Chiming Duan, Minghua He, Leyi Pan, Pei Xiao, Shiyu Huang, Yunpeng Zhai, Xuming Hu, Philip S Yu, et al. A survey on parallel text generation: From parallel decoding to diffusion language models.arXiv preprint arXiv:2508.08712, 2025
-
[3]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Runpeng Yu, Xinyin Ma, and Xinchao Wang. Dimple: Discrete diffusion multimodal large language model with parallel decoding.arXiv preprint arXiv:2505.16990, 2025
-
[6]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Mercury: Ultra-Fast Language Models Based on Diffusion
Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, et al. Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Llada2.1: Speeding up text diffusion via token editing, 2026
Tiwei Bie, Maosong Cao, Xiang Cao, Bingsen Chen, Fuyuan Chen, Kun Chen, Lun Du, Daozhuo Feng, Haibo Feng, Mingliang Gong, Zhuocheng Gong, Yanmei Gu, Jian Guan, Kaiyuan Guan, Hongliang He, Zenan Huang, Juyong Jiang, Zhonghui Jiang, Zhenzhong Lan, Chengxi Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Yuan Lu, Yuxin Ma, Xingyu Mou, Zhenxuan Pan...
2026
-
[13]
Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389, 2025
Fengqi Zhu, Zebin You, Yipeng Xing, Zenan Huang, Lin Liu, Yihong Zhuang, Guoshan Lu, Kangyu Wang, Xudong Wang, Lanning Wei, Hongrui Guo, Jiaqi Hu, Wentao Ye, Tieyuan Chen, Chenchen Li, Chengfu Tang, Haibo Feng, Jun Hu, Jun Zhou, Xiaolu Zhang, Zhenzhong Lan, Junbo Zhao, Da Zheng, Chongxuan Li, Jianguo Li, and Ji-Rong Wen. Llada-moe: A sparse moe diffusion ...
-
[14]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, et al. Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303, 2025
-
[15]
Openmoe 2: Sparse diffusion language models
Jinjie Ni and team. Openmoe 2: Sparse diffusion language models. https://github.com/JinjieNi/ OpenMoE2, 2025
2025
-
[16]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[17]
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs.arXiv preprint arXiv:2407.00945, 2024. 10
-
[18]
Task-specific expert pruning for sparse mixture-of-experts.arXiv preprint arXiv:2206.00277, 2022
Tianyu Chen, Shaohan Huang, Yuan Xie, Binxing Jiao, Daxin Jiang, Haoyi Zhou, Jianxin Li, and Furu Wei. Task-specific expert pruning for sparse mixture-of-experts.arXiv preprint arXiv:2206.00277, 2022
-
[19]
Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, and Christopher Carothers. A provably effective method for pruning experts in fine-tuned sparse mixture-of-experts.arXiv preprint arXiv:2405.16646, 2024
-
[20]
Hongcheng Guo, Juntao Yao, Boyang Wang, Junjia Du, Shaosheng Cao, Donglin Di, Shun Zhang, and Zhoujun Li. Cluster-driven expert pruning for mixture-of-experts large language models.arXiv preprint arXiv:2504.07807, 2025
-
[21]
Chenyang Song, Weilin Zhao, Xu Han, Chaojun Xiao, Yingfa Chen, Yuxuan Li, Zhiyuan Liu, and Maosong Sun. Blockffn: Towards end-side acceleration-friendly mixture-of-experts with chunk-level activation sparsity.arXiv preprint arXiv:2507.08771, 2025
-
[22]
Merging experts into one: Improving computational efficiency of mixture of experts
Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao. Merging experts into one: Improving computational efficiency of mixture of experts. InEMNLP, 2023
2023
-
[23]
Sejik Park. Learning more generalized experts by merging experts in mixture-of-experts.arXiv preprint arXiv:2405.11530, 2024
-
[24]
Sub-moe: Efficient mixture-of-expert llms compression via subspace expert merging
Lujun Li, Qiyuan Zhu, Jiacheng Wang, Xiaoyu Qin, Wei Li, Hao Gu, Sirui Han, and Yike Guo. Sub-moe: Efficient mixture-of-expert llms compression via subspace expert merging. InAAAI, 2026
2026
-
[25]
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li. Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. InACL, 2024
2024
-
[26]
Yushi Huang, Zining Wang, Zhihang Yuan, Yifu Ding, Ruihao Gong, Jinyang Guo, Xianglong Liu, and Jun Zhang. Modes: Accelerating mixture-of-experts multimodal large language models via dynamic expert skipping.arXiv preprint arXiv:2511.15690, 2025
-
[27]
Maryam Akhavan Aghdam, Hongpeng Jin, and Yanzhao Wu. Da-moe: Towards dynamic expert allocation for mixture-of-experts models.arXiv preprint arXiv:2409.06669, 2024
-
[28]
Eac-moe: Expert-selection aware compressor for mixture-of-experts large language models
Yuanteng Chen, Yuantian Shao, Peisong Wang, and Jian Cheng. Eac-moe: Expert-selection aware compressor for mixture-of-experts large language models. InACL, 2025
2025
-
[29]
Rexmoe: Reusing experts with minimal overhead in mixture-of-experts
Zheyue Tan, Zhiyuan Li, Tao Yuan, Dong Zhou, Weilin Liu, Yueqing Zhuang, Yadong Li, Guowei Niu, Cheng Qin, Zhuyu Yao, et al. Rexmoe: Reusing experts with minimal overhead in mixture-of-experts. arXiv preprint arXiv:2510.17483, 2025
-
[30]
Costin-Andrei Oncescu, Qingyang Wu, Wai Tong Chung, Robert Wu, Bryan Gopal, Junxiong Wang, Tri Dao, and Ben Athiwaratkun. Opportunistic expert activation: Batch-aware expert routing for faster decode without retraining.arXiv preprint arXiv:2511.02237, 2025
-
[31]
Shuibai Zhang, Caspian Zhuang, Chihan Cui, Zhihan Yang, Fred Zhangzhi Peng, Yanxin Zhang, Haoyue Bai, Zack Jia, Yang Zhou, Guanhua Chen, et al. Expert-choice routing enables adaptive computation in diffusion language models.arXiv preprint arXiv:2604.01622, 2026
-
[32]
Linye Wei, Zixiang Luo, Pingzhi Tang, and Meng Li. Team: Temporal-spatial consistency guided expert activation for moe diffusion language model acceleration.arXiv preprint arXiv:2602.08404, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Hao Mark Chen, Zhiwen Mo, Royson Lee, Qianzhou Wang, Da Li, Shell Xu Hu, Wayne Luk, Timothy Hospedales, and Hongxiang Fan. Dynamic expert sharing: Decoupling memory from parallelism in mixture-of-experts diffusion llms.arXiv preprint arXiv:2602.00879, 2026
-
[34]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InICLR, 2023
2023
-
[35]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018. 11
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InICLR, 2021
2021
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[39]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[40]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. InNeurIPS, 2022
2022
-
[41]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[42]
Audioldm: Text-to-audio generation with latent diffusion models,
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503, 2023
-
[43]
Fast timing-conditioned latent audio diffusion
Zach Evans, CJ Carr, Josiah Taylor, Scott H Hawley, and Jordi Pons. Fast timing-conditioned latent audio diffusion. InICML, 2024
2024
-
[44]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[45]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In NeurIPS, 2019
2019
-
[46]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[47]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. InNeurIPS, 2021
2021
-
[48]
Simple and effective masked diffusion language models
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InNeurIPS, 2024
2024
-
[49]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling.arXiv preprint arXiv:2409.02908, 2024
-
[51]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning.arXiv preprint arXiv:2504.12216, 2025
-
[53]
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838, 2025
-
[54]
Boundary-Guided Policy Optimization for Memory-efficient RL of Diffusion Large Language Models
Nianyi Lin, Jiajie Zhang, Lei Hou, and Juanzi Li. Boundary-guided policy optimization for memory- efficient rl of diffusion large language models.arXiv preprint arXiv:2510.11683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
dvoting: Fast voting for dllms.arXiv preprint arXiv:2602.12153, 2026
Sicheng Feng, Zigeng Chen, Xinyin Ma, Gongfan Fang, and Xinchao Wang. dvoting: Fast voting for dllms.arXiv preprint arXiv:2602.12153, 2026
-
[56]
Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903, 2025
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient reasoning models: A survey.arXiv preprint arXiv:2504.10903, 2025
-
[57]
MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Shufan Li, Konstantinos Kallidromitis, Hritik Bansal, Akash Gokul, Yusuke Kato, Kazuki Kozuka, Jason Kuen, Zhe Lin, Kai-Wei Chang, and Aditya Grover. Lavida: A large diffusion language model for multimodal understanding.arXiv preprint arXiv:2505.16839, 2025. 12
-
[59]
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning.arXiv preprint arXiv:2505.16933, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639, 2025
-
[61]
contributors
Fred Zhangzhi Peng, Shuibai Zhang, and Alex Tong. contributors. open-dllm: Open diffusion large language models
-
[62]
Runpeng Yu, Qi Li, and Xinchao Wang. Discrete diffusion in large language and multimodal models: A survey.arXiv preprint arXiv:2506.13759, 2025
-
[63]
A Survey on Diffusion Language Models
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
DMax: Aggressive Parallel Decoding for dLLMs
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. Dmax: Aggressive parallel decoding for dllms.arXiv preprint arXiv:2604.08302, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Edge-moe: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts
Rishov Sarkar, Hanxue Liang, Zhiwen Fan, Zhangyang Wang, and Cong Hao. Edge-moe: Memory-efficient multi-task vision transformer architecture with task-level sparsity via mixture-of-experts. InICCAD, 2023
2023
-
[66]
Fastermoe: modeling and optimizing training of large-scale dynamic pre-trained models
Jiaao He, Jidong Zhai, Tiago Antunes, Haojie Wang, Fuwen Luo, Shangfeng Shi, and Qin Li. Fastermoe: modeling and optimizing training of large-scale dynamic pre-trained models. InProceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2022
2022
-
[67]
Self-distillation: Towards efficient and compact neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(8):4388–4403, 2021
Linfeng Zhang, Chenglong Bao, and Kaisheng Ma. Self-distillation: Towards efficient and compact neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(8):4388–4403, 2021
2021
-
[68]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
2024
-
[69]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models. arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Sicheng Feng, Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song, Jianke Zhu, Huan Wang, and Xinchao Wang. Can mllms guide me home? a benchmark study on fine-grained visual reasoning from transit maps.arXiv preprint arXiv:2505.18675, 2025
-
[71]
Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios.arXiv preprint arXiv:2507.20198, 2025
-
[72]
Obs-diff: Accurate pruning for diffusion mod- els in one-shot.arXiv preprint arXiv:2510.06751, 2025
Junhan Zhu, Hesong Wang, Mingluo Su, Zefang Wang, and Huan Wang. Obs-diff: Accurate pruning for diffusion models in one-shot.arXiv preprint arXiv:2510.06751, 2025
-
[73]
Sicheng Feng, Kaiwen Tuo, Song Wang, Lingdong Kong, Jianke Zhu, and Huan Wang. Rewardmap: Tackling sparse rewards in fine-grained visual reasoning via multi-stage reinforcement learning.arXiv preprint arXiv:2510.02240, 2025
-
[74]
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Huan Wang, et al. Omnizip: Audio-guided dynamic token compression for fast omnimodal large language models.arXiv preprint arXiv:2511.14582, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Xin Jin, Siyuan Li, Siyong Jian, Kai Yu, and Huan Wang. Mergemix: A unified augmentation paradigm for visual and multi-modal understanding.arXiv preprint arXiv:2510.23479, 2025
-
[76]
Zhenxin Ai and Haiyun He. Pasa: A principled embedding-space watermarking approach for llm-generated text under semantic-invariant attacks.arXiv preprint arXiv:2605.10977, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[77]
Which heads matter for reasoning? rl-guided kv cache compression
Wenjie Du, Li Jiang, Keda Tao, Xue Liu, and Huan Wang. Which heads matter for reasoning? rl-guided kv cache compression. InICML, 2026. 13 Appendix In Appendix A, we discuss limitations and future work. We further provide the impact statement in Appendix B and license statement in Appendix C, and computing resources in Appendix D. A Limitations & Future Wo...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.