De-attribute to Forget for LLM Unlearning
Pith reviewed 2026-06-28 23:46 UTC · model grok-4.3
The pith
LLM unlearning can be reframed as reducing data attribution scores of generated responses instead of maximizing loss on forget sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimizing an LLM via reinforcement learning to reduce the attribution score of its generated responses to the owners of the forget data produces unlearning that maintains better model utility than methods based on maximizing prediction loss.
What carries the argument
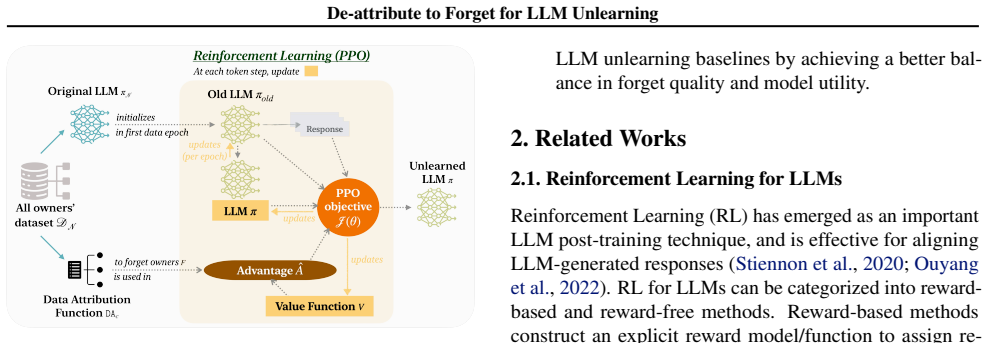
DareU, the reinforcement learning framework driven by data attribution rewards that updates the model by de-attributing its outputs from forget data owners.
If this is right
- Unlearning objectives can avoid direct loss maximization on the forget set and still achieve removal of data influence.
- Model utility after unlearning remains higher because the optimization does not broadly degrade performance on unrelated tasks.
- Attribution-based rewards provide a measurable signal for controlling what the model attributes its outputs to.
- The same de-attribution process can be applied across different forget sets without retraining from scratch.
Where Pith is reading between the lines
- If the classifier approximation holds, the method could be adapted to track and control influence of individual training examples over time.
- Extending the approach to settings with streaming data might allow ongoing adjustment of attribution without full retraining.
- Comparing results against exact attribution methods on smaller models could test how much the classifier approximation affects the outcome.
Load-bearing premise
An LLM classifier gives a sufficiently accurate approximation of true data attribution that optimizing against it removes the influence of forget data without creating new problems.
What would settle it
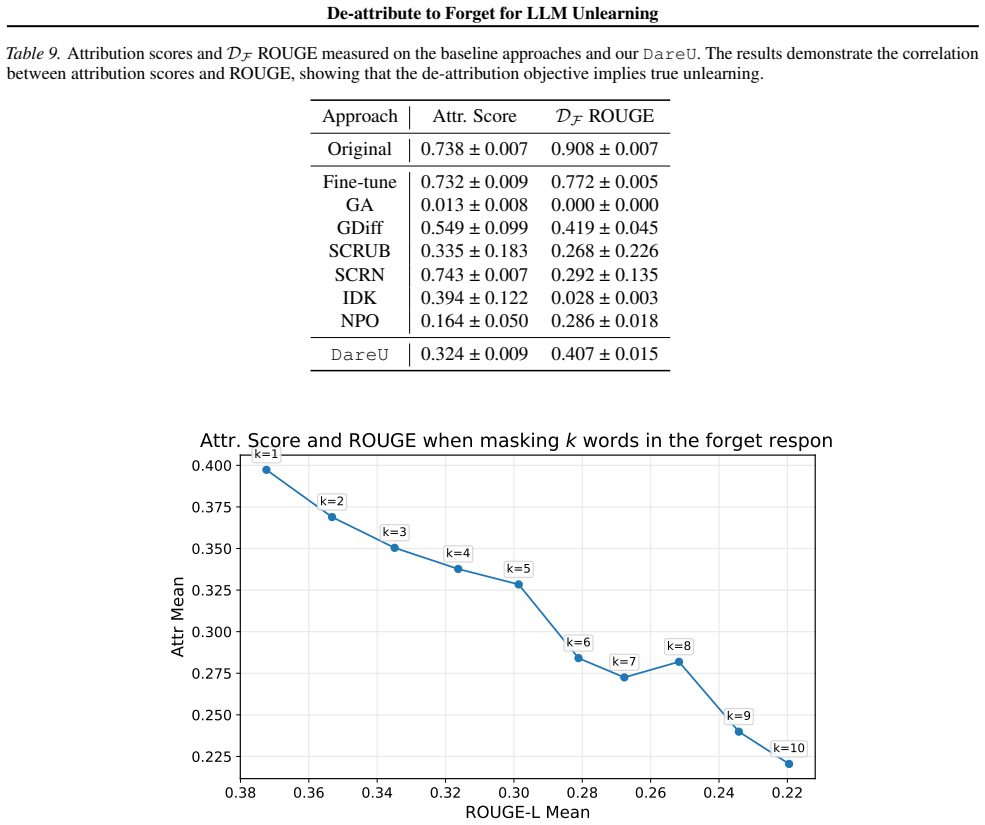
Direct probing of the updated model with questions drawn from the forget set that reveal retained factual knowledge even after the attribution score has been driven low.
Figures



read the original abstract
The rapid development of large language models (LLMs) has raised concerns on the use of inappropriate data for training, which has led to a growing interest in LLM unlearning. Many existing LLM unlearning approaches rely on optimizing prediction loss(es), such as maximizing the loss on the forget set, but often face critical issues like over-forgetting and poor model utility. To address them, this paper novelly frames the optimization objective for LLM unlearning as one of zeroing out data attribution instead. In particular, we propose the first LLM unlearning framework based on data attribution rewards called DareU that performs reinforcement learning to update the LLM by reducing the attribution score of its generated responses (i.e., de-attributing) to the forget data owners. Empirical evaluation using an LLM classifier as an efficient approximation of attribution shows that DareU outperforms existing baselines by achieving effective unlearning while balancing forget quality and model utility well.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DareU, the first LLM unlearning framework that reframes the objective as zeroing out data attribution rather than optimizing prediction losses. It uses reinforcement learning to update the model by minimizing attribution scores of generated responses to forget-set owners, with an LLM classifier serving as an efficient proxy for true attribution; empirical results are claimed to show better balance between forget quality and retained utility than existing baselines.
Significance. If the attribution proxy is shown to be faithful, the approach could mitigate over-forgetting and utility collapse common in loss-based unlearning methods by directly targeting causal influence rather than surface loss, offering a more principled alternative for machine unlearning in LLMs.
major comments (2)
- [Abstract] Abstract: the central claim that optimizing against the LLM-classifier attribution scores produces genuine unlearning rests on the unvalidated assumption that these scores are a faithful proxy for true data attribution (i.e., high scores precisely when a response is causally influenced by the forget set). No correlation with influence functions, membership inference, or leave-one-out retraining is referenced, which is load-bearing for the claim that gradient steps lowering the score achieve de-attribution rather than superficial artifacts.
- [Abstract] Abstract: the statement that DareU 'outperforms existing baselines by achieving effective unlearning while balancing forget quality and model utility well' is presented without any quantitative results, ablation studies, or experimental details on the forget-set size, model scale, or metrics used, preventing assessment of whether the RL updates support the claimed balance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract and the validation of our attribution proxy. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that optimizing against the LLM-classifier attribution scores produces genuine unlearning rests on the unvalidated assumption that these scores are a faithful proxy for true data attribution (i.e., high scores precisely when a response is causally influenced by the forget set). No correlation with influence functions, membership inference, or leave-one-out retraining is referenced, which is load-bearing for the claim that gradient steps lowering the score achieve de-attribution rather than superficial artifacts.
Authors: We agree that direct validation of the LLM classifier proxy against ground-truth attribution methods is important to support the de-attribution claim. The manuscript presents the classifier as a computationally efficient approximation and demonstrates its utility through downstream forget-quality and utility metrics. However, we did not include explicit correlations with influence functions or leave-one-out retraining. We will add a dedicated validation subsection (using smaller-scale models where leave-one-out is tractable) that reports Pearson/Spearman correlations between classifier scores and influence-function estimates, plus membership-inference AUCs, to quantify proxy faithfulness. revision: yes
-
Referee: [Abstract] Abstract: the statement that DareU 'outperforms existing baselines by achieving effective unlearning while balancing forget quality and model utility well' is presented without any quantitative results, ablation studies, or experimental details on the forget-set size, model scale, or metrics used, preventing assessment of whether the RL updates support the claimed balance.
Authors: We acknowledge that the current abstract is qualitative and omits concrete numbers. We will revise the abstract to include key quantitative highlights (e.g., average forget-set accuracy drop of X%, utility retention of Y% on MMLU, model sizes of 7B/13B, forget-set sizes of 1k–5k examples) together with a brief mention of the RL reward formulation and main baselines. This will allow readers to immediately assess the claimed balance. revision: yes
Circularity Check
No significant circularity; attribution proxy treated as external input
full rationale
The paper frames LLM unlearning as zeroing data attribution via RL on scores from a separate LLM classifier used as an efficient approximation. No equation or step reduces the claimed unlearning outcome to a quantity defined by the method itself (e.g., no self-definitional loop where success metric equals the optimized reward by construction). The central premise relies on an external assumption about classifier fidelity rather than a fitted input renamed as prediction or a self-citation chain. This matches the default expectation of self-contained derivation with only minor risk of load-bearing issues.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM classifier serves as an efficient and adequate approximation of data attribution for the forget set.
invented entities (1)
-
DareU framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Alt- man, S., Anadkat, S., et al. GPT-4 technical report. arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
M., Garg, S., Ilyas, A., Madry, A., and Neel, S
Georgiev, K., Rinberg, R., Park, S. M., Garg, S., Ilyas, A., Madry, A., and Neel, S. Attribute-to-delete: Machine unlearning via datamodel matching.arXiv:2410.23232,
-
[3]
Towards unbounded machine unlearning
Kurmanji, M., Triantafillou, P., Hayes, J., and Triantafillou, E. Towards unbounded machine unlearning. InProc. NeurIPS, pp. 1957–1987,
1957
-
[4]
Li, Z., Zhao, W., Li, Y ., and Sun, J. Where did it go wrong? attributing undesirable LLM behaviors via representation gradient tracing.arXiv:2510.02334,
-
[5]
C., and Kolter, J
Maini, P., Feng, Z., Schwarzschild, A., Lipton, Z. C., and Kolter, J. Z. TOFU: A task of fictitious unlearning for LLMs. InICLR 2024 Workshop on Navigating and Ad- dressing Data Problems for Foundation Models,
2024
-
[6]
Rusu, A. A., Colmenarejo, S. G., G¨ulc ¸ehre, C ¸., Desjardins, G., Kirkpatrick, J., Pascanu, R., Mnih, V ., Kavukcuoglu, K., and Hadsell, R. Policy distillation.arXiv:1511.06295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Shi, W., Ajith, A., Xia, M., Huang, Y ., Liu, D., Blevins, T., Chen, D., and Zettlemoyer, L. Detecting pretraining data from large language models. InProc. ICLR, 2024a. Shi, W., Lee, J., Huang, Y ., Malladi, S., Zhao, J., Holtzman, A., Liu, D., Zettlemoyer, L., Smith, N. A., and Zhang, C. MUSE: Machine unlearning six-way evaluation for language models.arX...
-
[10]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V ., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V ., Kha...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Machine unlearning of pre-trained large language models
Yao, J., Chien, E., Du, M., Niu, X., Wang, T., Cheng, Z., and Yue, X. Machine unlearning of pre-trained large language models. InProc. ACL, pp. 8403–8419, 2024a. Yao, J., Chien, E., Du, M., Niu, X., Wang, T., Cheng, Z., and Yue, X. Machine unlearning of pre-trained large language models. InProc. ACL, pp. 8403–8419, 2024b. Yao, Y ., Duan, J., Xu, K., Cai, ...
-
[13]
TinyLlama: An Open-Source Small Language Model
11 De-attribute to Forget for LLM Unlearning Zhang, P., Zeng, G., Wang, T., and Lu, W. Tinyllama: An open-source small language model.arXiv:2401.02385, 2024a. Zhang, R., Lin, L., Bai, Y ., and Mei, S. Negative preference optimization: From catastrophic collapse to effective un- learning. InProc. COLM, 2024b. Zhao, K., Kurmanji, M., Barbulescu, G.-O., Tria...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Fine-Tuning Language Models from Human Preferences
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Rad- ford, A., Amodei, D., Christiano, P. F., and Irving, G. Fine-tuning language models from human preferences. arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
We only report the results on seed 42 due to high computational costs
12 De-attribute to Forget for LLM Unlearning Table 8.Full-parameter unlearning performance of DareU on full-parameter Llama2 × TOFU without LoRA. We only report the results on seed 42 due to high computational costs. Approach DF ROUGE (→)D R ROUGE (→)D test ROUGE (→) ToW (↑) Truth Ratio (↑) MIA (→) Original 0.932 0.926 0.929 0.379 0.401 0.996 Retraining 0...
2024
-
[16]
approximate the LOO scores in different ways without retraining. However, they still incur large computations compared to our efficient approximation using a classifier, especially when invoked for a large number of test instances (Hammoudeh & Lowd, 2024). Apart from these schemes,text watermarkinghas been utilized in recent works (Lau et al., 2024; Lu et al.,
2024
-
[17]
By embedding verifiable watermarks into training data, text watermarking approaches enable computationally efficient data attribution at inference time
for data attribution. By embedding verifiable watermarks into training data, text watermarking approaches enable computationally efficient data attribution at inference time. For example, Lau et al. (2024) adopts an LLM paraphraser to modify the semantics in a verifiable way, and Lu et al. (2025) directly embeds invisible Unicode characters into training ...
2024
-
[18]
While these works have been popular for research on interpretability and explainable AI, they are usually computationally expensive and are less relevant in our unlearning setting
can effectively be used for instance attribution. While these works have been popular for research on interpretability and explainable AI, they are usually computationally expensive and are less relevant in our unlearning setting. Since we focus on identifying whether the forget set belonging to a group of forget owners (instead of individual data instanc...
2024
-
[19]
In this setting, the pre-trained LLM has been fine-tuned for a specific task, resulting in πN , and is further refined by using PPO to learn a policy (in our context, the LLM π)
is a widely adopted reward-based RL algorithm commonly employed for post-training LLMs. In this setting, the pre-trained LLM has been fine-tuned for a specific task, resulting in πN , and is further refined by using PPO to learn a policy (in our context, the LLM π). PPO utilizes an explicit reward model to compute the reward on a trajectory (in our contex...
1999
-
[20]
I don’t know
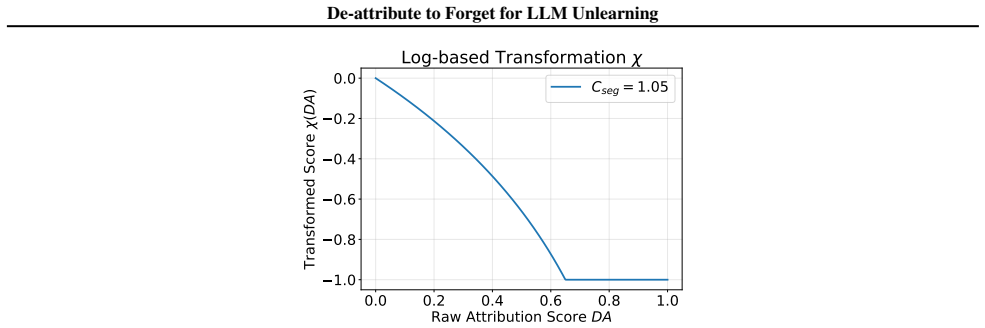
require generating multiple responses for each query and are hence computationally more expensive. Overall, PPO offers a balanced trade-off between update stability and computational cost. Log-based Transformation.In Sec. 4.2.1, we designed the log-based transformation for attribution reward as: clip(ln(1−clip(b, ε,1−ε))/C seg,−1,0). In our implementation...
2024
-
[21]
cannot be computed due to the lack of a perturbed set forDF of 800 samples. Experimental results in Table 11 demonstrate that DareU consistently achieves effective unlearning with high ToW scores across different sizes ofD F, which confirms the scalability ofDareUto unlearnD F of different sizes. F.3. Sensitivity to Hyperparameters In this section, we ana...
-
[22]
This may be due to our design of the distillation regularization term (Sec
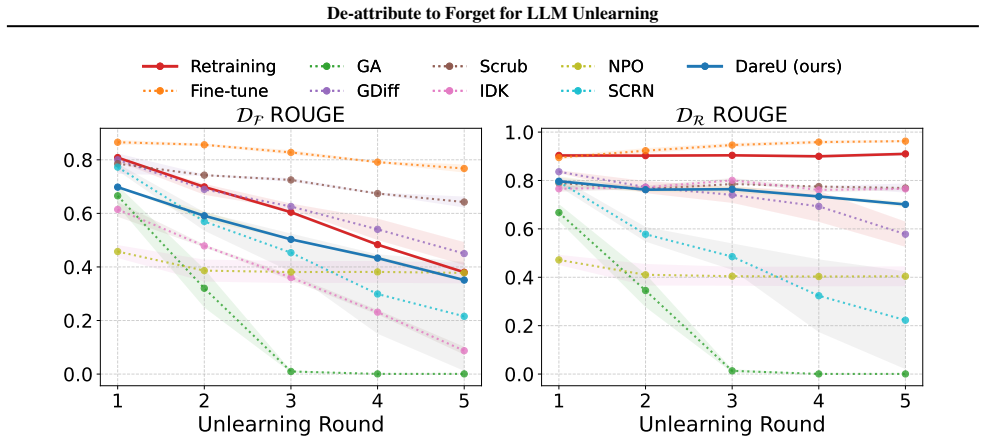
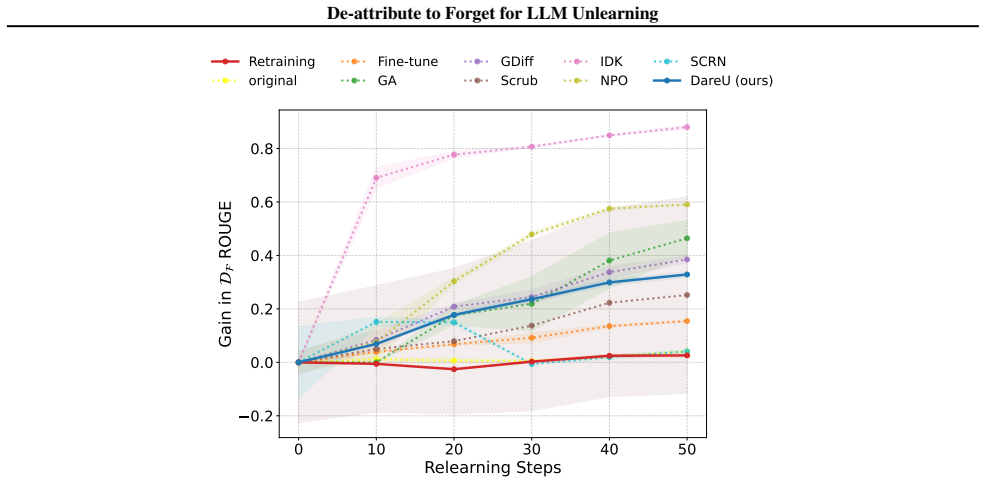
The results show that DareU produces less gibberish than most prediction loss-based unlearning approaches. This may be due to our design of the distillation regularization term (Sec. 4.2). Note that Fine-tune does not effectively unlearn and IDK makes the unlearned model outputs ”I don’t know”, hence producing0 percent gibberish in the generated outputs. ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.