Traceable by Design: An LLM Pipeline and Dashboard for EU Regulatory Consultation Analysis
Pith reviewed 2026-06-28 20:46 UTC · model grok-4.3
The pith
An LLM pipeline extracts 15,368 traceable topic annotations from 4,322 regulatory submissions, each backed by verbatim quotes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
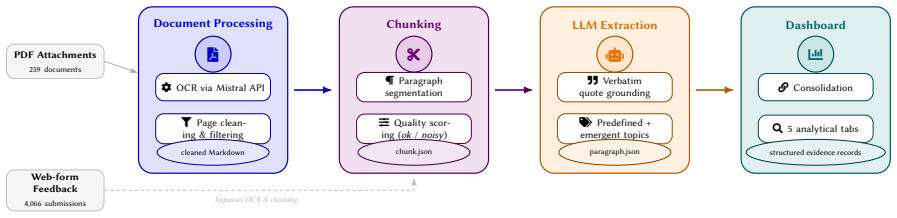
The authors built a domain-generic LLM pipeline that performs structured topic extraction on regulatory consultation submissions and requires every annotation to be supported by a verbatim quote from the source document, demonstrated by processing 4,322 Digital Fairness Act submissions into 15,368 annotations backed by 20,951 quotes while also surfacing emergent concerns such as Age Verification and Digital Ownership that fixed taxonomies miss.
What carries the argument
The LLM pipeline with verbatim grounding, which forces every topic annotation to be accompanied by a direct quote from the original submission text.
If this is right
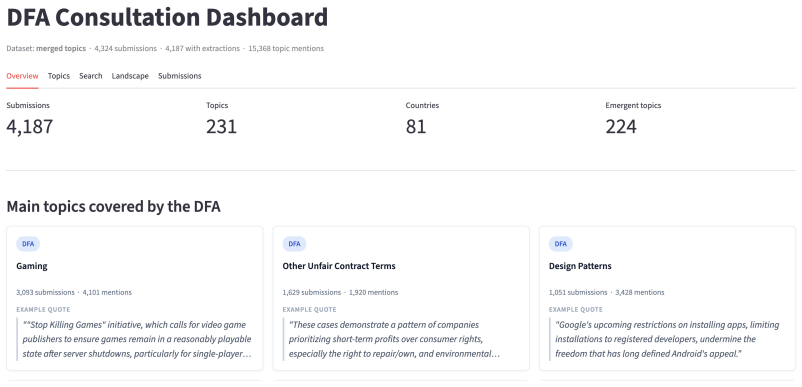
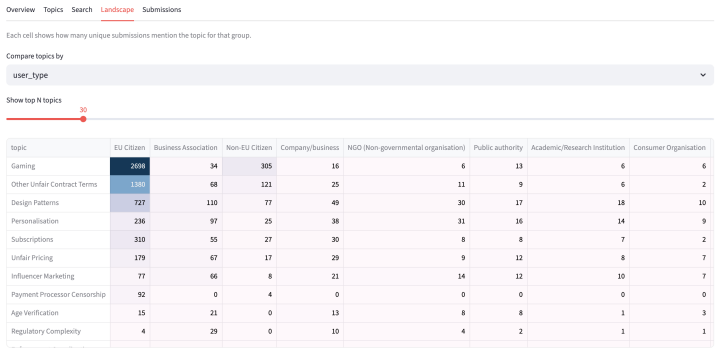
- The dashboard supplies five linked views that range from dataset-wide topic statistics to individual paragraph drill-downs.
- Emergent stakeholder concerns outside the predefined DFA categories can be captured without changing the core pipeline.
- Switching the system to a different consultation requires only a new prompt and dataset.
- Every generated result remains directly traceable to its source document for verification.
Where Pith is reading between the lines
- The same traceable design could reduce manual review effort in future EU or national consultations of similar scale.
- Without built-in grounding, comparable LLM tools risk producing uncheckable summaries that regulators cannot rely on.
- Public release of the code and processed data allows other groups to test the pipeline on additional regulatory datasets.
Load-bearing premise
The large language model produces topic annotations that are factually correct and correctly matched to verbatim quotes in the source documents.
What would settle it
A manual audit of a random sample of the 15,368 annotations that finds a substantial fraction either unsupported by their linked quotes or inaccurate in topic assignment.
Figures
read the original abstract
Public consultations generate large volumes of data in the form of stakeholder submissions that are practically unfeasible to analyse manually. We present an end-to-end LLM-based pipeline and interactive dashboard for structured topic extraction from regulatory consultation submissions, demonstrated on the European Commission's Digital Fairness Act (DFA) public call for evidence as a case study. The system processes raw PDF attachments and web-form responses, extracts topic annotations, and grounds every extraction in a verbatim quote from the source text. Applied to 4,322 DFA submissions, the pipeline produced 15,368 topic annotations supported by 20,951 verbatim evidence quotes. Three principles govern the proposed design: verbatim grounding, full traceability, and transparency by design. The dashboard exposes the full extraction dataset through five analytical views, from dataset-level topic overviews to individual paragraph drill-downs, with every result traceable to its source. Beyond the predefined DFA topic categories, the pipeline generated certain stakeholder concerns, such as Age Verification, Payment Processor Censorship, and Digital Ownership, that a fixed-taxonomy approach would have missed. The pipeline is domain-generic; adapting it to a new consultation requires only a prompt update and a new dataset. A live demo is available at https://dfa-dashboard.thalesbertaglia.com/. The code and processed data are publicly available at https://github.com/thalesbertaglia/dfa-dashboard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an end-to-end LLM-based pipeline and interactive dashboard for structured topic extraction from regulatory consultation submissions, emphasizing verbatim grounding, full traceability, and transparency by design. Demonstrated as a case study on the European Commission's Digital Fairness Act (DFA) public call for evidence, the system processes 4,322 submissions (raw PDFs and web-form responses) to produce 15,368 topic annotations supported by 20,951 verbatim evidence quotes. The pipeline is domain-generic, requiring only a prompt update for new consultations, and includes a live demo plus publicly available code and processed data.
Significance. If the outputs are reliable, the work addresses a clear practical gap in policy analysis by enabling scalable, traceable processing of large consultation datasets that are otherwise infeasible to analyze manually. The explicit design principles, ability to surface emergent concerns (e.g., Age Verification, Payment Processor Censorship) beyond fixed taxonomies, and the public release of code, data, and a functional dashboard are concrete strengths that support reproducibility and potential adoption by regulators or researchers.
major comments (1)
- [Abstract] Abstract: The central claim that the pipeline 'produced 15,368 topic annotations supported by 20,951 verbatim evidence quotes' is presented without any accuracy metrics, inter-annotator agreement, human baseline comparison, or error analysis. This absence is load-bearing for assessing whether the system delivers usable regulatory analysis.
minor comments (1)
- [Methods] The methods description of prompt templates and processing steps could include a short worked example of adapting the pipeline to a second consultation to substantiate the 'domain-generic' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's practical relevance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the pipeline 'produced 15,368 topic annotations supported by 20,951 verbatim evidence quotes' is presented without any accuracy metrics, inter-annotator agreement, human baseline comparison, or error analysis. This absence is load-bearing for assessing whether the system delivers usable regulatory analysis.
Authors: We agree that quantitative evaluation of annotation accuracy is necessary to substantiate claims of usability for regulatory analysis. The manuscript's design prioritizes verbatim grounding and full traceability precisely to enable manual verification of every extraction, rather than relying on opaque model outputs. However, this does not substitute for reported metrics. In the revised version we will add a dedicated evaluation section that includes: (1) a human baseline study on a stratified random sample of 200 submissions (approximately 5% of the corpus), with two independent annotators measuring precision, recall, and inter-annotator agreement against the pipeline outputs; (2) an error analysis categorizing failure modes (e.g., over-extraction, missed nuance, grounding errors); and (3) explicit discussion of limitations. The public release of the full dataset already supports independent validation by others. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an applied LLM pipeline, dashboard, and case study on 4,322 submissions. It contains no equations, fitted parameters, predictions, or derivation chain. The central claims concern system design (verbatim grounding, traceability) and reported counts of annotations/quotes; these are direct outputs of the described processing steps rather than reductions to self-referential inputs. No self-citations, uniqueness theorems, or ansatzes appear in the provided text. The work is self-contained as an engineering demonstration.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
European Commission, Call for evidence for an impact assessment - ares(2025)5829481, 2025
2025
-
[2]
M. A. Livermore, V. Eidelman, B. Grom, Computationally assisted regulatory participation, Notre Dame L. Rev. 93 (2017) 977
2017
-
[3]
Di Porto, P
F. Di Porto, P. Fantozzi, M. Naldi, N. Rangone, Mining eu consultations through ai: Fd porto et al., Artificial Intelligence and Law (2024) 1–38
2024
-
[4]
F. J. Bex, P. J. Van Koppen, H. Prakken, B. Verheij, A hybrid formal theory of arguments, stories and criminal evidence, Artificial Intelligence and Law 18 (2010) 123–152
2010
-
[5]
H. Rashkin, V. Nikolaev, M. Lamm, L. Aroyo, M. Collins, D. Das, S. Petrov, G. S. Tomar, I. Turc, D. Reitter, Measuring attribution in natural language generation models, Computational Linguistics 49 (2023) 777–840. URL: https://aclanthology.org/2023.cl-4.2/. doi:10.1162/coli_a_00486
-
[6]
I. Chalkidis, E. Fergadiotis, P. Malakasiotis, N. Aletras, I. Androutsopoulos, Extreme multi-label legal text classification: A case study in EU legislation, in: N. Aletras, E. Ash, L. Barrett, D. Chen, A. Meyers, D. Preotiuc-Pietro, D. Rosenberg, A. Stent (Eds.), Proceedings of the Natural Legal Lan- guage Processing Workshop 2019, Association for Comput...
-
[7]
Chalkidis, M
I. Chalkidis, M. Fergadiotis, P. Malakasiotis, N. Aletras, I. Androutsopoulos, Legal-bert: The muppets straight out of law school, in: Findings of the association for computational linguistics: EMNLP 2020, 2020, pp. 2898–2904
2020
-
[8]
Chalkidis, A
I. Chalkidis, A. Jana, D. Hartung, M. Bommarito, I. Androutsopoulos, D. Katz, N. Aletras, Lexglue: A benchmark dataset for legal language understanding in english, in: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 4310–4330
2022
-
[9]
C. Goanta, N. Aletras, I. Chalkidis, S. Ranchordás, G. Spanakis, Regulation and NLP (RegNLP): Taming large language models, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Singapore, 2023, pp. 8712–8724. URL: https://aclanthology.org/2023.emnlp-main.539/. doi: 10.18653/...
-
[10]
Surden, Machine learning and law, Washington Law Review 89 (2014) 87–115
H. Surden, Machine learning and law, Washington Law Review 89 (2014) 87–115
2014
-
[11]
Zhong, C
H. Zhong, C. Xiao, C. Tu, T. Zhang, Z. Liu, M. Sun, How does nlp benefit legal system: A summary of legal artificial intelligence, in: Proceedings of ACL 2020, 2020, pp. 5218–5230
2020
-
[12]
Siino, M
M. Siino, M. Falco, D. Croce, P. Rosso, Exploring LLMs applications in Law: A literature review on current legal NLP approaches, IEEE Access 13 (2025) 18253–18276
2025
-
[13]
Romberg, T
J. Romberg, T. Escher, Making sense of citizens’ input through artificial intelligence: A review of methods for computational text analysis to support the evaluation of contributions in public participation, Digital Government: Research and Practice 5 (2024) 1–30
2024
-
[14]
i see something you don’t see
F. Di Porto, T. Grote, G. Volpi, R. Ivernizzi, "i see something you don’t see": A computational analysis of the digital services act and the digital markets act, Stan. Computational Antitrust 1 (2021) 84
2021
-
[15]
Chenene, J
M. Chenene, J. Rouhier, J. Daniélou, M. Sarkar, E. Cabrio, Stakeholder suite: A unified ai framework for mapping actors, topics and arguments in public debates, in: Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 3: System Demonstrations), 2026, pp. 1–20
2026
-
[16]
Lawrence, C
J. Lawrence, C. Reed, Argument mining: A survey, Computational linguistics 45 (2019) 765–818
2019
-
[17]
Habernal, D
I. Habernal, D. Faber, N. Recchia, S. Bretthauer, I. Gurevych, I. Spiecker genannt Döhmann, C. Burchard, Mining legal arguments in court decisions, Artificial Intelligence and Law 32 (2024) 1–38
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.