Does Visual Information Play a Decisive Role in Vision-Language-Action Model Driving Behavior?
Pith reviewed 2026-06-28 22:38 UTC · model grok-4.3
The pith
A multi-level visual perturbation framework reveals that VLA driving models show evaluation-dependent reliance on visuals and uneven grounding across abstraction levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
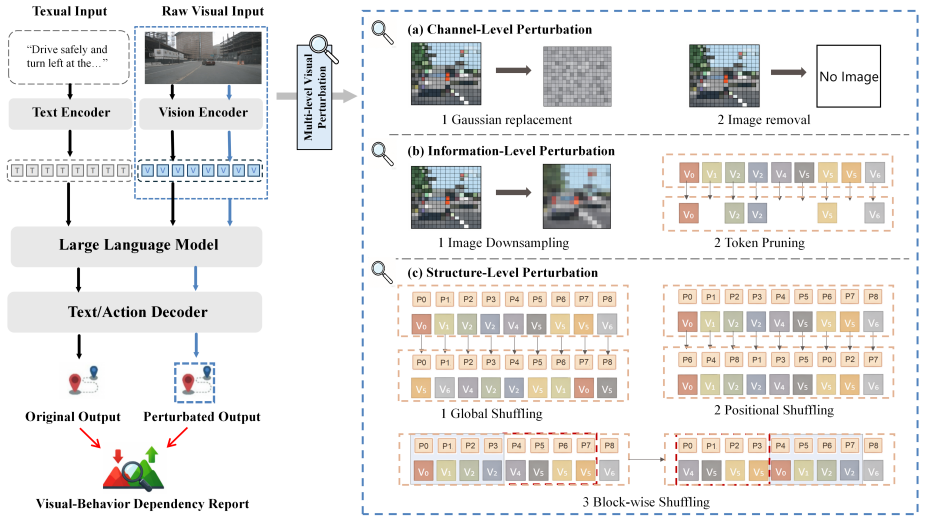
The structured multi-level visual perturbation framework, organized along channel-level degradation, information-level disruption, and structure-level modification, demonstrates that VLA-based driving models exhibit evaluation-dependent dependency patterns on visual information together with uneven visual grounding across abstraction levels.
What carries the argument
Structured multi-level visual perturbation framework that applies controlled changes along channel-level degradation, information-level disruption, and structure-level modification to quantify impacts on model behavior.
If this is right
- VLA driving models display different visual dependency levels in open-loop trajectory prediction compared with closed-loop interactive safety tests.
- Visual grounding within these models is not uniform across abstraction levels.
- Aggregate performance metrics alone cannot capture how visual information shapes driving behavior.
- Safer VLA systems will require structured dependency analyses during model design and evaluation.
Where Pith is reading between the lines
- The same perturbation approach could be adapted to diagnose visual reliance in other multimodal planning tasks outside driving.
- Model developers could use level-specific results to prioritize training data that strengthens weak abstraction layers.
- Uneven grounding points to a possible need for hybrid architectures that route critical decisions through more robust non-visual pathways.
Load-bearing premise
The controlled visual perturbations isolate the contribution of visual information without introducing confounding changes to model internals or non-visual inputs.
What would settle it
If the same perturbation set produced identical behavioral shifts in both open-loop and closed-loop settings with no variation by abstraction level, the reported evaluation-dependent patterns would not hold.
Figures
read the original abstract
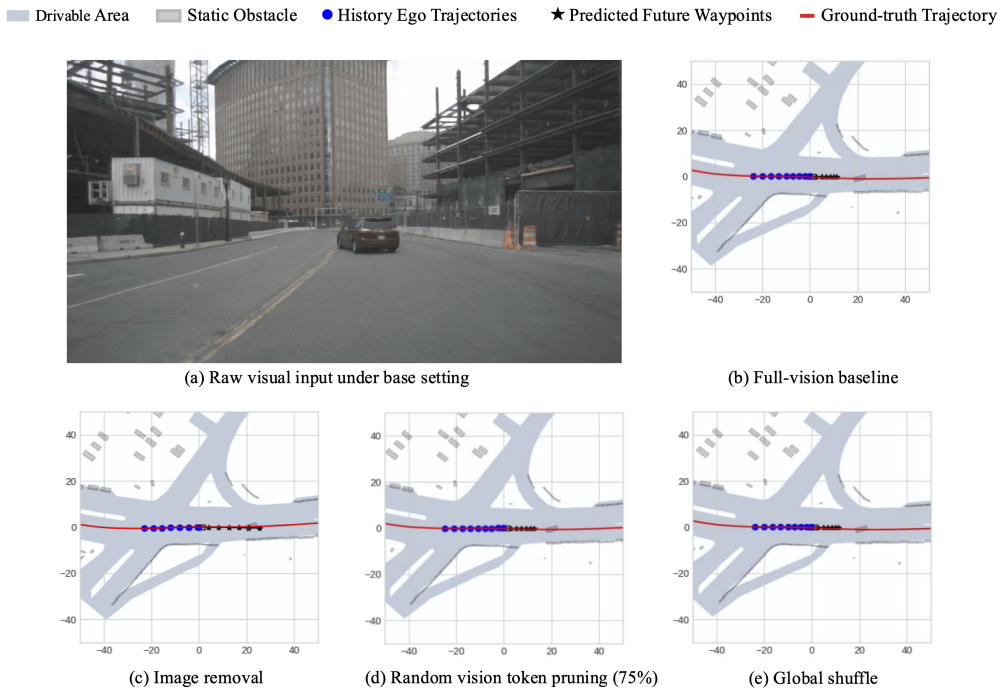
Vision-Language-Action (VLA) models have demonstrated promising capability in autonomous driving, highlighting the potential of unified multimodal architectures for jointly modeling perception and planning. However, how current VLA-based driving behavior is grounded in visual information remains poorly understood. Existing evaluation protocols mainly focus on aggregate performance metrics, lacking structured and practical diagnostics to quantify visual-behavior dependency. In this work, we introduce a structured multi-level visual perturbation framework to analyze visual-behavior dependency in VLA-based driving models systematically. The framework organizes controlled visual perturbations along three complementary dimensions: channellevel degradation, information-level disruption, and structurelevel modification. We apply it to VLA-based driving systems and evaluate behavioral responses under both open-loop trajectory prediction and interactive closed-loop safety evaluation. Experimental results reveal evaluation-dependent dependency patterns and uneven visual grounding across abstraction levels. These findings call for more structured analyses and principled design of VLA driving models to better understand how visual information shapes behavior and develop safer, more robust systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a three-level visual perturbation framework (channel-level degradation, information-level disruption, and structure-level modification) to diagnose visual-behavior dependency in Vision-Language-Action (VLA) models for autonomous driving. It applies the framework to evaluate model responses under both open-loop trajectory prediction and interactive closed-loop safety scenarios, reporting evaluation-dependent dependency patterns and uneven visual grounding across abstraction levels.
Significance. If the perturbations can be shown to isolate visual contributions, the structured multi-level framework would provide a practical diagnostic tool beyond aggregate metrics, directly supporting the claim that visual grounding varies by evaluation setting and abstraction level. The dual use of open-loop and closed-loop evaluations is a concrete strength that strengthens the evaluation-dependent pattern finding.
major comments (1)
- [Sections 3 and 4] Sections 3 (framework) and 4 (experiments): the central attribution of behavioral differences to loss of visual grounding assumes the perturbations leave non-visual pathways (language encoder, action head, planning priors) unchanged. No ablation is described that compares the perturbed visual inputs against a text-only baseline or neutral-token replacement to confirm that tokenization statistics and downstream components remain unaffected; this isolation step is load-bearing for the reported dependency patterns.
minor comments (2)
- [Abstract] Abstract: the summary of results mentions 'evaluation-dependent dependency patterns' without any quantitative metrics, error bars, or dataset identifiers; adding one sentence with key effect sizes would improve clarity.
- [Section 3] The three perturbation dimensions are introduced without an explicit comparison table showing how each dimension maps to specific input modifications; a small summary table would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the importance of rigorously isolating visual contributions. We address the single major comment below.
read point-by-point responses
-
Referee: [Sections 3 and 4] Sections 3 (framework) and 4 (experiments): the central attribution of behavioral differences to loss of visual grounding assumes the perturbations leave non-visual pathways (language encoder, action head, planning priors) unchanged. No ablation is described that compares the perturbed visual inputs against a text-only baseline or neutral-token replacement to confirm that tokenization statistics and downstream components remain unaffected; this isolation step is load-bearing for the reported dependency patterns.
Authors: We agree that explicit verification that the perturbations affect only the visual pathway is necessary to support the attribution of behavioral changes to visual grounding. Although the framework applies perturbations exclusively to the visual input before it reaches the vision encoder (leaving language tokens, the language encoder, and the action head untouched by construction), we did not include a direct text-only or neutral-token ablation to quantify any secondary effects on token statistics or downstream modules. In the revised manuscript we will add this ablation: we will report open-loop and closed-loop performance when the visual input is replaced by a text-only prompt or by neutral visual tokens, confirming that the observed differences arise from visual degradation rather than from changes in non-visual components. revision: yes
Circularity Check
No circularity: empirical perturbation study with independent experimental claims
full rationale
The paper introduces a three-level visual perturbation framework and reports behavioral outcomes from open-loop and closed-loop evaluations on VLA driving models. No derivation chain, equations, or first-principles results are present; claims rest on observed differences under channel/info/structure perturbations rather than any reduction to fitted inputs, self-definitions, or self-citation chains. The framework and metrics are defined independently of the target results, satisfying the self-contained empirical case with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual perturbations at channel, information, and structure levels can be controlled to affect only visual input without side effects on language or action modules
Reference graph
Works this paper leans on
-
[1]
A survey on vision-language-action models for autonomous driving,
S. Jiang, Z. Huang, K. Qian, Z. Luo, T. Zhu, Y . Zhong, Y . Tang, M. Kong, Y . Wang, S. Jiaoet al., “A survey on vision-language-action models for autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4524–4536
2025
-
[2]
Vision- language-action (vla) models: Concepts, progress, applications and challenges,
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee, “Vision- language-action (vla) models: Concepts, progress, applications and challenges,”arXiv preprint arXiv:2505.04769, 2025
-
[3]
Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,
K. Renz, L. Chen, E. Arani, and O. Sinavski, “Simlingo: Vision-only closed-loop autonomous driving with language-action alignment,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[4]
Latentvla: Efficient vision-language models for autonomous driving via latent action prediction,
C. Xie, B. Sun, T. Li, J. Wu, Z. Hao, X. Lang, and H. Li, “Latentvla: Efficient vision-language models for autonomous driving via latent action prediction,”arXiv preprint arXiv:2601.05611, 2026
-
[5]
Steervla: Steering vision-language-action models in long-tail driving scenarios,
T. Gao, C. Tan, C. Glossop, T. Gao, J. Sun, K. Stachowicz, S. Wu, O. Mees, D. Sadigh, S. Levine, and C. Finn, “Steervla: Steering vision-language-action models in long-tail driving scenarios,” 2026
2026
-
[6]
Taking a hint: Leveraging explanations to make vision and language models more grounded,
R. R. Selvaraju, S. Lee, Y . Shen, H. Jin, S. Ghosh, L. Heck, D. Batra, and D. Parikh, “Taking a hint: Leveraging explanations to make vision and language models more grounded,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 2591–2600
2019
-
[7]
Counterfactual vqa: A cause-effect look at language bias,
Y . Niu, K. Tang, H. Zhang, Z. Lu, X.-S. Hua, and J.-R. Wen, “Counterfactual vqa: A cause-effect look at language bias,” inPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 700–12 710
2021
-
[8]
Benchmarking robustness of 3d object detection to common corruptions,
Y . Dong, C. Kang, J. Zhang, Z. Zhu, Y . Wang, X. Yang, H. Su, X. Wei, and J. Zhu, “Benchmarking robustness of 3d object detection to common corruptions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1022–1032
2023
-
[9]
Visual perception challenges in adverse weather for autonomous vehicles: A review of rain and fog impacts,
Y . Qiu, Y . Lu, Y . Wang, and C. Yang, “Visual perception challenges in adverse weather for autonomous vehicles: A review of rain and fog impacts,” in2024 IEEE 7th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), vol. 7, 2024, pp. 1342–1348
2024
-
[10]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma, “Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning,”arXiv preprint arXiv:2506.13757, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Open- drivevla: Towards end-to-end autonomous driving with large vision language action model,
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll, “Open- drivevla: Towards end-to-end autonomous driving with large vision language action model,”arXiv preprint arXiv:2503.23463, 2025
-
[12]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wanget al., “Recogdrive: A reinforced cog- nitive framework for end-to-end autonomous driving,”arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Y . Li, M. Tian, D. Zhu, J. Zhu, Z. Lin, Z. Xiong, and X. Zhao, “Drive- r1: Bridging reasoning and planning in vlms for autonomous driving with reinforcement learning,”arXiv preprint arXiv:2506.18234, 2025
-
[14]
Y . Wang, W. Luo, J. Bai, Y . Cao, T. Che, K. Chen, Y . Chen, J. Di- amond, Y . Ding, W. Dinget al., “Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail,”arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Autodridm: An explainable benchmark for decision-making of vision-language models in autonomous driving,
Z. Tang, Z. Wang, Y . Wang, W. Lian, T. Gao, H. Li, T. Ru, L. Meng, Z. Cui, Y . Zhu, Q. Kang, K. Wang, and Y . Zhang, “Autodridm: An explainable benchmark for decision-making of vision-language models in autonomous driving,” 2026
2026
-
[16]
Balanced multi- modal learning via on-the-fly gradient modulation,
X. Peng, Y . Wei, A. Deng, D. Wang, and D. Hu, “Balanced multi- modal learning via on-the-fly gradient modulation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2022, pp. 8238–8247
2022
-
[17]
Don’t just assume; look and answer: Overcoming priors for visual question answering,
A. Agrawal, D. Batra, D. Parikh, and A. Kembhavi, “Don’t just assume; look and answer: Overcoming priors for visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4971–4980
2018
-
[18]
Shortcut learning in deep neural networks,
R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F. A. Wichmann, “Shortcut learning in deep neural networks,”Nature Machine Intelligence, vol. 2, no. 11, pp. 665–673, 2020
2020
-
[19]
Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6904–6913
2017
-
[20]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
D. Hendrycks and T. Dietterich, “Benchmarking neural network robustness to common corruptions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[21]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. ´Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?”2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14 864–14 873, 2023
2024
-
[22]
J. Tang, M. Feng, J. Liu, Y . Wang, and J. Pu, “Decoupling scene perception and ego status: A multi-context fusion approach for enhanced generalization in end-to-end autonomous driving,”arXiv preprint arXiv:2511.13079, 2025
-
[23]
Impromptu vla: Open weights and open data for driving vision-language-action models,
H. Chi, H.-a. Gao, Z. Liu, J. Liu, C. Liu, J. Li, K. Yang, Y . Yu, Z. Wang, W. Liet al., “Impromptu vla: Open weights and open data for driving vision-language-action models,”arXiv preprint arXiv:2505.23757, 2025
-
[24]
Qwen2-vl: Enhancing vision-language model with ad- vanced visual understanding and multimodal reasoning,
Q. Team, “Qwen2-vl: Enhancing vision-language model with ad- vanced visual understanding and multimodal reasoning,”arXiv preprint, 2024
2024
-
[25]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[26]
Neuroncap: Photorealistic closed- loop safety testing for autonomous driving,
W. Ljungbergh, A. Tonderski, J. Johnander, H. Caesar, K. ˚Astr¨om, M. Felsberg, and C. Petersson, “Neuroncap: Photorealistic closed- loop safety testing for autonomous driving,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 161–177
2024
-
[27]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference ac- celeration for large vision-language models,
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, and B. Chang, “An image is worth 1/2 tokens after layer 2: Plug-and-play inference ac- celeration for large vision-language models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 19–35
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.