QVGGT: Post-Training Quantized Visual Geometry Grounded Transformer
Pith reviewed 2026-06-28 22:53 UTC · model grok-4.3
The pith
QVGGT quantizes the 1.2B-parameter VGGT model to W4A16 precision while keeping all 3D prediction heads accurate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
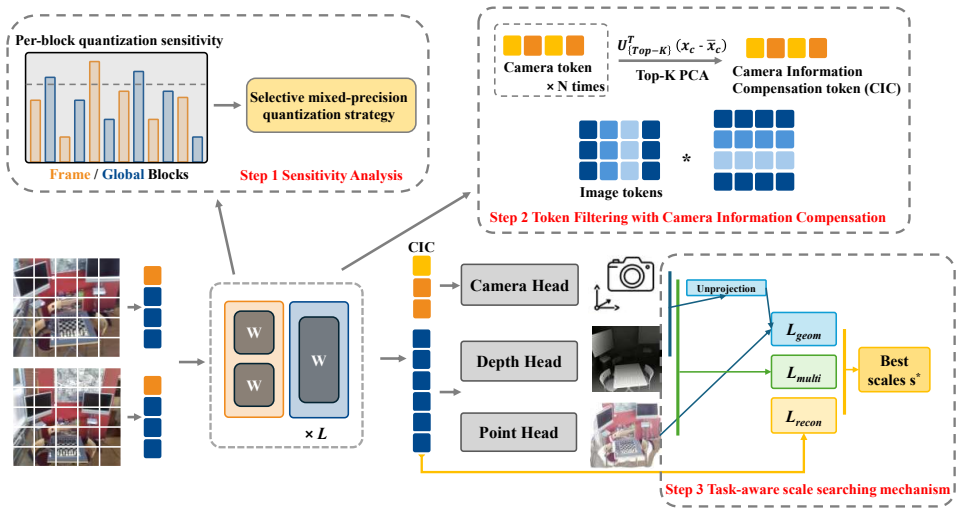
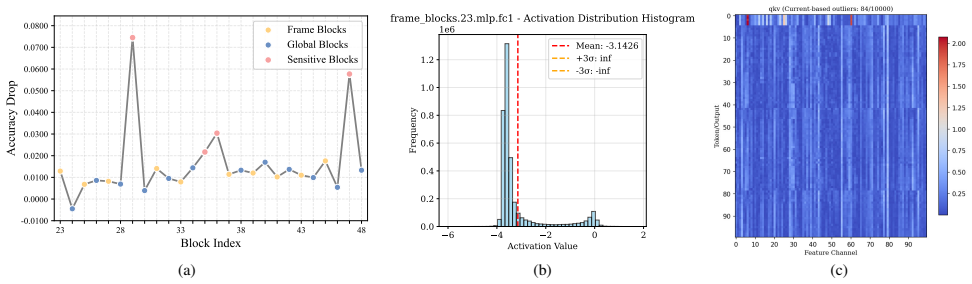
QVGGT achieves near-lossless W4A16 quantization of VGGT through three coordinated steps: per-block sensitivity analysis that selects mixed precision for fragile transformer blocks, token filtering that excludes high-variance camera and register tokens from calibration while restoring their information via a PCA-derived global compensation token, and a task-aware scale search that scores candidate scales by both layer reconstruction error and multi-head geometric consistency among camera poses, depth maps, and point maps.
What carries the argument
Per-block quantization sensitivity analysis that drives selective mixed-precision allocation, combined with PCA-compensated token filtering and multi-head geometric consistency checks for scale selection.
If this is right
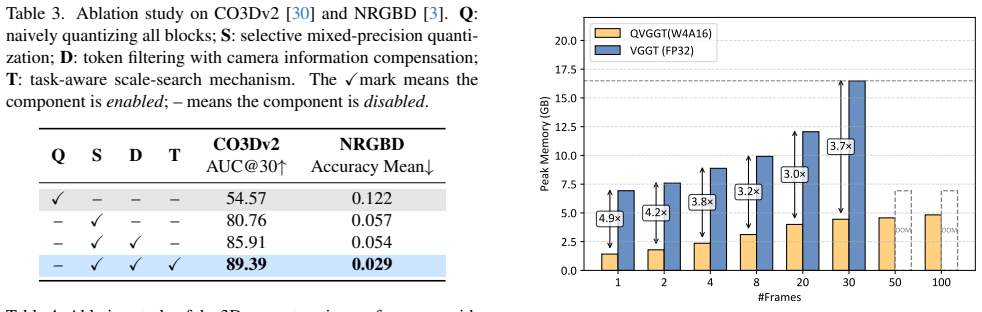
- Memory footprint falls by a factor of 3 to 4.9 compared with the FP32 baseline.
- Real hardware inference runs up to 2.8 times faster than the full-precision model.
- All three 3D output heads retain their original accuracy after quantization.
- Feed-forward 3D reconstruction becomes practical on memory-limited edge platforms such as UAVs and mobile AR devices.
Where Pith is reading between the lines
- The same block-wise sensitivity and consistency machinery could be tested on other large vision transformers that output structured geometric outputs.
- Extending the consistency checks to additional geometric relations might allow even lower average bit widths without retraining.
- If the compensation token proves stable, the method could reduce power draw in battery-powered 3D perception systems.
Load-bearing premise
The sensitivity rankings and geometric consistency checks derived from the calibration set will continue to produce effective scales on data and tasks outside those used during development.
What would settle it
Evaluating the quantized model on a fresh 3D geometry benchmark never seen during calibration and measuring whether any prediction head shows more than a small accuracy drop relative to the original FP32 VGGT.
Figures

read the original abstract
Estimating 3D attributes directly from images has advanced rapidly with the Visual Geometry Grounded Transformer (VGGT), which predicts camera parameters, depth maps, and point clouds in a single forward pass. However, its 1.2B-parameter scale severely limits deployment on resource-constrained platforms such as UAVs and mobile AR devices. To address this limitation, we introduce QVGGT, a tailored quantization framework designed to compress VGGT. Our approach starts from the observation that transformer blocks within VGGT exhibit heterogeneous sensitivity to quantization. We thus analyze per-block quantization sensitivity and propose a selective mixed-precision strategy that allocates higher precision to the most fragile transformer blocks. To address the amplification of quantization error caused by high-variance camera and register tokens, we further introduce token filtering with camera information compensation, which removes these outliers from activation calibration and restores their geometric cues using a PCA-derived global compensation token. Finally, we develop a task-aware scale search mechanism that evaluates candidate quantization scales not only through layer reconstruction but also through multi-head supervision and cross-head geometric consistency among camera poses, depth maps, and point maps. Extensive experiments on multiple geometry perception benchmarks demonstrate that QVGGT achieves near-lossless W4A16 quantization, preserving the accuracy of all 3D prediction heads while delivering 3$\sim$4.9$\times$ memory reduction and up to 2.8$\times$ real hardware speedup over FP32. Our approach makes high-fidelity 3D perception feasible on edge devices, enabling practical deployment of feed-forward 3D reconstruction models in real-world constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QVGGT, a post-training quantization (PTQ) framework for the 1.2B-parameter VGGT model. It claims that per-block sensitivity analysis enables selective mixed-precision allocation, token filtering plus PCA-derived compensation mitigates high-variance camera/register token errors, and a task-aware scale search using multi-head geometric consistency yields near-lossless W4A16 quantization. This preserves accuracy across camera, depth, and point-map heads while delivering 3–4.9× memory reduction and up to 2.8× hardware speedup on geometry benchmarks.
Significance. If the reported near-lossless W4A16 performance generalizes, the work would meaningfully advance practical deployment of feed-forward 3D reconstruction models on edge hardware. The approach is empirically grounded in the specific challenges of geometry transformers (outlier tokens, cross-head consistency) rather than generic PTQ, and the multi-head supervision mechanism is a concrete strength that directly ties quantization to the downstream 3D tasks.
major comments (2)
- [Abstract and experimental results section] The central claim of near-lossless performance rests on calibration-set scale selection (per-block sensitivity, token filtering, PCA compensation, and task-aware search). No experiments test transfer to out-of-distribution inputs (different lighting, camera trajectories, or scene scales), which is required to substantiate that the filtered tokens and global compensation token remain effective beyond the calibration distribution used for all reported benchmarks.
- [Abstract] The abstract states that accuracy of all 3D prediction heads is preserved, yet no quantitative error bars, standard deviations across runs, or per-head absolute/relative error tables are referenced. Without these, it is impossible to verify whether observed differences fall within measurement noise or constitute statistically meaningful preservation.
minor comments (2)
- [Method description] Notation for the PCA compensation token and the multi-head consistency loss should be defined explicitly with equations rather than descriptive text only.
- [Experiments] The paper should include a direct comparison table against standard PTQ baselines (e.g., GPTQ, AWQ) using identical calibration data and the same VGGT backbone to isolate the contribution of the proposed token-filtering and consistency mechanisms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence on generalization and statistical validation of our claims. We address each major comment below and commit to revisions where the manuscript requires strengthening.
read point-by-point responses
-
Referee: [Abstract and experimental results section] The central claim of near-lossless performance rests on calibration-set scale selection (per-block sensitivity, token filtering, PCA compensation, and task-aware search). No experiments test transfer to out-of-distribution inputs (different lighting, camera trajectories, or scene scales), which is required to substantiate that the filtered tokens and global compensation token remain effective beyond the calibration distribution used for all reported benchmarks.
Authors: We agree that explicit evaluation on out-of-distribution inputs would provide stronger substantiation for the robustness of token filtering and PCA-derived compensation. While the reported benchmarks encompass diverse scenes and conditions, we will add targeted OOD experiments (e.g., altered lighting, varied camera trajectories, and different scene scales) in the revised manuscript to directly test transfer beyond the calibration distribution. revision: yes
-
Referee: [Abstract] The abstract states that accuracy of all 3D prediction heads is preserved, yet no quantitative error bars, standard deviations across runs, or per-head absolute/relative error tables are referenced. Without these, it is impossible to verify whether observed differences fall within measurement noise or constitute statistically meaningful preservation.
Authors: We concur that statistical measures are necessary to rigorously support the preservation claim. In the revised manuscript, we will include expanded per-head tables reporting absolute and relative errors for camera, depth, and point-map heads, along with standard deviations computed across multiple runs, to allow assessment of whether differences fall within measurement variability. revision: yes
Circularity Check
No circularity: empirical PTQ method validated on external benchmarks
full rationale
The paper describes an empirical post-training quantization pipeline (per-block sensitivity, token filtering + PCA compensation, task-aware scale search) with no mathematical derivation or closed-form predictions. All reported accuracy, memory, and speedup numbers are measured results on standard geometry benchmarks rather than quantities defined in terms of the method's own fitted parameters or internal calibration outputs. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify core claims; the work is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building rome in a day.Communications of the ACM, 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Si- mon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 2011. 3
2011
-
[2]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Al- istarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.arXiv preprint arXiv:2404.00456, 2024. 2, 3
-
[3]
Neural rgb-d surface reconstruction
Dejan Azinovi ´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InCVPR, 2022. 2, 6, 7, 8
2022
-
[4]
Scene coordinate reconstruction: Pos- ing of image collections via incremental learning of a relo- calizer
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cav- allari, ´Aron Monszpart, Daniyar Turmukhambetov, and Vic- tor Adrian Prisacariu. Scene coordinate reconstruction: Pos- ing of image collections via incremental learning of a relo- calizer. InECCV, 2024. 3
2024
-
[5]
EfficientQAT: Efficient quantization-aware training for large language models
Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, and Ping Luo. EfficientQAT: Efficient quantization-aware training for large language models. In ACL, 2025. 3
2025
-
[6]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, 2017. 1
2017
-
[7]
The case for 4-bit pre- cision: k-bit inference scaling laws
Tim Dettmers and Luke Zettlemoyer. The case for 4-bit pre- cision: k-bit inference scaling laws. InICML, 2023. 6
2023
-
[8]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv:2208.07339,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Quantized visual geome- try grounded transformer.arXiv preprint arXiv:2509.21302,
Weilun Feng, Haotong Qin, Mingqiang Wu, Chuanguang Yang, Yuqi Li, Xiangqi Li, Zhulin An, Libo Huang, Yu- lun Zhang, Michele Magno, et al. Quantized visual geome- try grounded transformer.arXiv preprint arXiv:2509.21302,
-
[10]
Build- ing rome on a cloudless day
Jan-Michael Frahm, Pierre Fite-Georgel, David Gallup, Tim Johnson, Rahul Raguram, Changchang Wu, Yi-Hung Jen, Enrique Dunn, Brian Clipp, Svetlana Lazebnik, et al. Build- ing rome on a cloudless day. InECCV, 2010. 3
2010
-
[11]
Optimal brain compres- sion: A framework for accurate post-training quantization and pruning
Elias Frantar and Dan Alistarh. Optimal brain compres- sion: A framework for accurate post-training quantization and pruning. InNeurIPS, 2022. 2
2022
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022. 2, 3, 7
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Massively parallel multiview stereopsis by surface normal diffusion
Silvano Galliani, Katrin Lasinger, and Konrad Schindler. Massively parallel multiview stereopsis by surface normal diffusion. InICCV, 2015. 3
2015
-
[14]
Cascade cost volume for high-resolution multi-view stereo and stereo matching
Xiaodong Gu, Zhiwen Fan, Siyu Zhu, Zuozhuo Dai, Feitong Tan, and Ping Tan. Cascade cost volume for high-resolution multi-view stereo and stereo matching. InCVPR, 2020. 2
2020
-
[15]
Deep com- pression: Compressing deep neural network with pruning, trained quantization and huffman coding
Song Han, Huizi Mao, and William J Dally. Deep com- pression: Compressing deep neural network with pruning, trained quantization and huffman coding. InICLR, 2016. 2
2016
-
[16]
Cambridge University Press,
Richard Hartley and Andrew Zisserman.Multiple View Ge- ometry in Computer Vision. Cambridge University Press,
-
[17]
Cambridge University Press,
Richard Hartley and Andrew Zisserman.Multiple view ge- ometry in computer vision. Cambridge University Press,
-
[18]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[19]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InCVPR,
-
[20]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InECCV, 2024. 2, 3
2024
-
[21]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Yao Fu, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. InMLSys, 2024. 2, 3, 6, 7
2024
-
[22]
Robust incremental structure-from-motion with hybrid fea- tures
Shaohui Liu, Yidan Gao, Tianyi Zhang, R ´emi Pautrat, Jo- hannes L Sch ¨onberger, Viktor Larsson, and Marc Pollefeys. Robust incremental structure-from-motion with hybrid fea- tures. InECCV, 2025. 2, 3
2025
-
[23]
Llm-qat: Data-free quantization aware training for large language models
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. In Findings of ACL, 2024. 3
2024
-
[24]
SpinQuant: LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. Spinquant–llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Multiview stereo with cascaded epipolar raft
Zeyu Ma, Zachary Teed, and Jia Deng. Multiview stereo with cascaded epipolar raft. InECCV, 2022. 2, 3
2022
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019. 7
2019
-
[28]
Slow learning and fast inference: Ef- ficient graph similarity computation via knowledge distilla- tion
Can Qin, Handong Zhao, Lichen Wang, Huan Wang, Yulun Zhang, and Yun Fu. Slow learning and fast inference: Ef- ficient graph similarity computation via knowledge distilla- tion. InAdvances in Neural Information Processing Systems,
-
[29]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InICCV, 2021. 4, 8
2021
-
[30]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InICCV, 2021. 2, 6, 7, 8, 1
2021
-
[31]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InCVPR, 2016. 3
2016
-
[32]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Sch ¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InECCV, 2016. 3
2016
-
[33]
Scene co- ordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene co- ordinate regression forests for camera relocalization in rgb-d images. InCVPR, 2013. 2, 6, 7
2013
-
[34]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models.arXiv preprint arXiv:2306.11695, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds.arXiv preprint arXiv:2412.06974, 2024. 3
-
[36]
Keda Tao, Haoxuan You, Yang Sui, Can Qin, and Huan Wang. Plug-and-play 1. x-bit kv cache quantization for video large language models.arXiv preprint arXiv:2503.16257,
-
[37]
What makes a ”good” data augmentation in knowledge dis- tillation - a statistical perspective
Huan Wang, Suhas Lohit, Michael N Jones, and Yun Fu. What makes a ”good” data augmentation in knowledge dis- tillation - a statistical perspective. InNeurIPS, 2022. 2
2022
-
[38]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InCVPR, 2024. 2, 3
2024
-
[39]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InCVPR, 2025. 2, 3, 6, 7, 8, 1
2025
-
[40]
Continuous 3d per- ception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d per- ception model with persistent state. InCVPR, 2025. 3, 7
2025
-
[41]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InCVPR, 2024. 2, 3
2024
-
[42]
Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo
Yi Wei, Shaohui Liu, Yongming Rao, Wang Zhao, Jiwen Lu, and Jie Zhou. Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo. InICCV, 2021. 3
2021
-
[43]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chau- mond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R´emi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing. arXiv preprint arXiv:1910.03771, 2019. 7
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[44]
Smoothquant: Accurate and ef- ficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and ef- ficient post-training quantization for large language models. InICML, 2023. 2, 3, 7
2023
-
[45]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InCVPR, 2025. 3
2025
-
[46]
Lianwei Yang, Haisong Gong, Haokun Lin, Yichen Wu, Zhenan Sun, and Qingyi Gu. Dopq-vit: To- wards distribution-friendly and outlier-aware post-training quantization for vision transformers.arXiv preprint arXiv:2408.03291, 2024. 3
-
[47]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024. 3
2024
-
[48]
Zeroquant: Ef- ficient and affordable post-training quantization for large- scale transformers
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xi- aoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Ef- ficient and affordable post-training quantization for large- scale transformers. InNeurIPS, 2022. 2
2022
-
[49]
Mquant: Unleashing the inference potential of multimodal large language models via static quantization
JiangYong Yu, Sifan Zhou, Dawei Yang, Shuoyu Li, Shuo Wang, Xing Hu, Chen Xu, Zukang Xu, Changyong Shu, and Zhihang Yuan. Mquant: Unleashing the inference potential of multimodal large language models via static quantization. InACM MM, 2025. 3
2025
-
[50]
Ptq4vit: Post-training quantization for vi- sion transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, and Guangyu Sun. Ptq4vit: Post-training quantization for vi- sion transformers with twin uniform quantization. InECCV,
-
[51]
Advancing model pruning via bi-level optimization
Yihua Zhang, Yuguang Yao, Parikshit Ram, Pu Zhao, Tian- long Chen, Mingyi Hong, Yanzhi Wang, and Sijia Liu. Advancing model pruning via bi-level optimization. In NeurIPS, 2022. 2
2022
-
[52]
Decoupled knowledge distillation
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. InCVPR, 2022. 2
2022
-
[53]
Atom: Low-bit quantization for efficient and accurate llm serving
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving. InMLSys, 2024. 2, 3
2024
-
[54]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018. 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Obs-diff: Accurate pruning for diffusion mod- els in one-shot.arXiv preprint arXiv:2510.06751, 2025
Junhan Zhu, Hesong Wang, Mingluo Su, Zefang Wang, and Huan Wang. Obs-diff: Accurate pruning for diffusion mod- els in one-shot.arXiv preprint arXiv:2510.06751, 2025. 2 QVGGT: Post-Training Quantized Visual Geometry Grounded Transformer Supplementary Material A. Quantization Implementation Details To facilitate reproducibility, we summarize the key hy- per...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.