R+R: Reassessing Java Security API Misuse in Current LLMs: A Replication on JCA and JSSE APIs with External Security Knowledge
Pith reviewed 2026-06-28 21:58 UTC · model grok-4.3
The pith
Newer large language models still misuse Java security APIs, though added external knowledge reduces the errors in a model-dependent way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
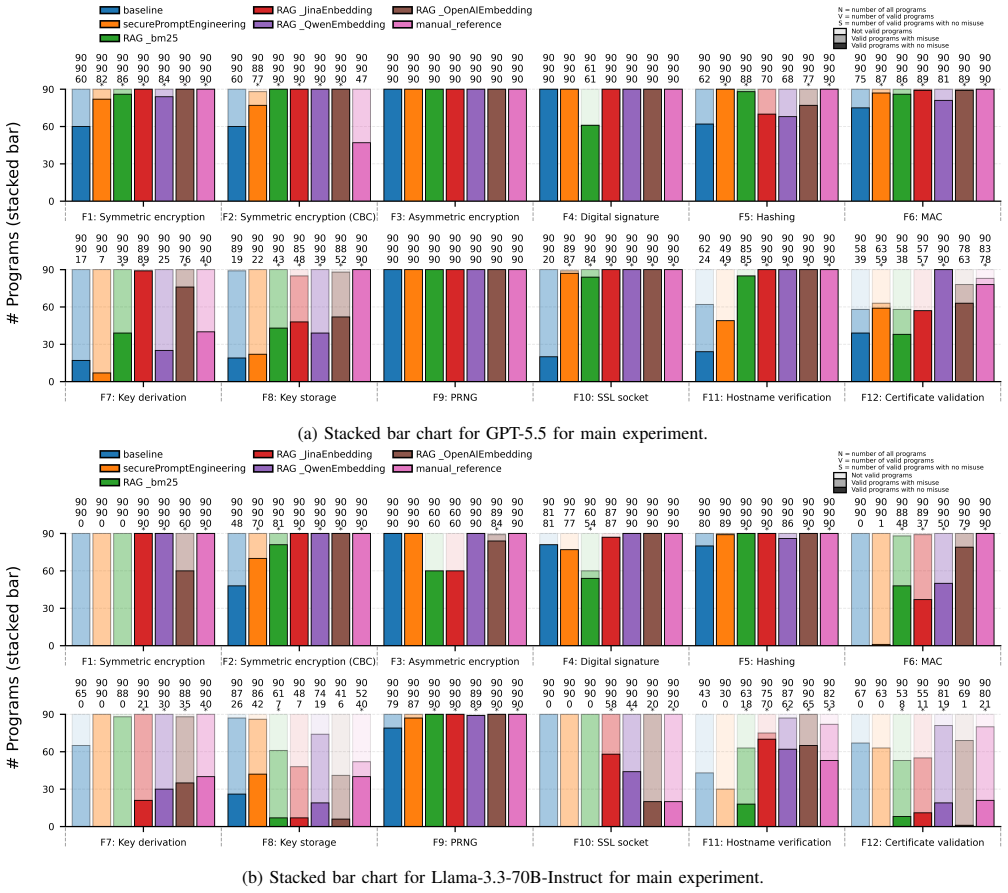
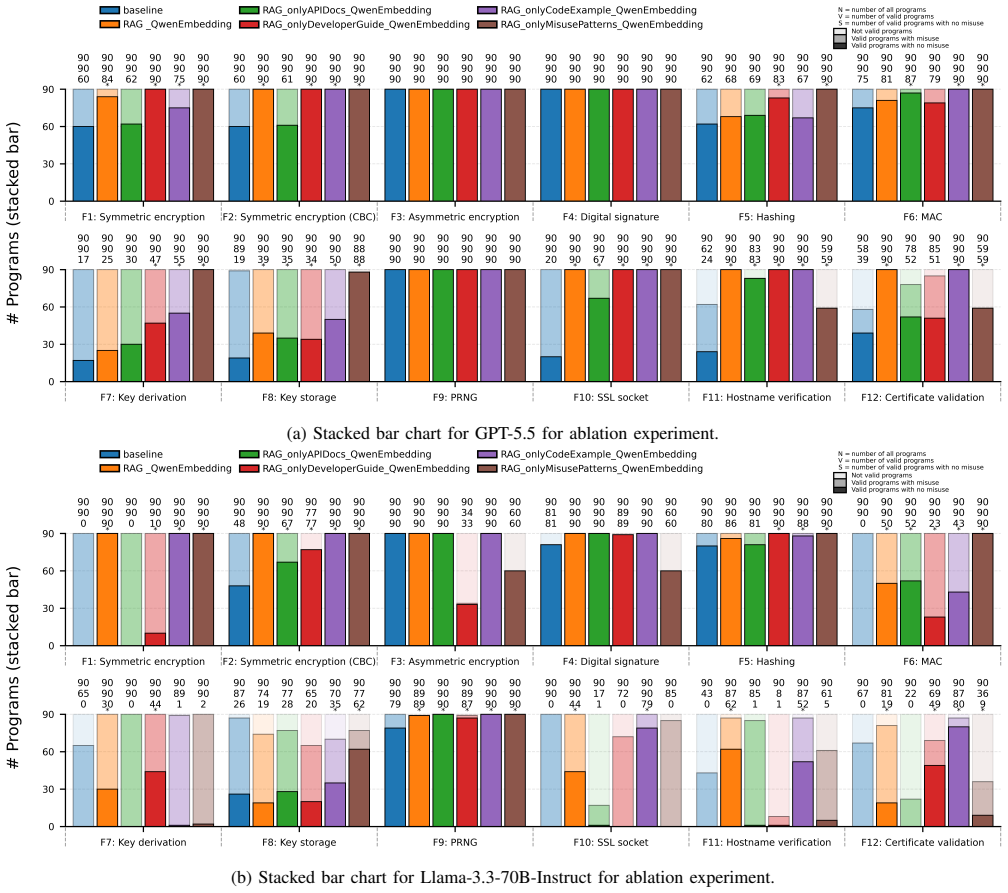
Although newer LLMs perform better in using Java security APIs, the problem of Java security API misuse has not been eliminated. External security knowledge substantially improves the measured outcome, but its effect is model-dependent. For Llama-3.3-70B-Instruct, secure code examples are the most effective single knowledge type. For GPT-5.5, explicit misuse patterns eliminate all detected security API misuses among valid programs, although some outputs remain invalid due to compilation errors or target-API mismatches.
What carries the argument
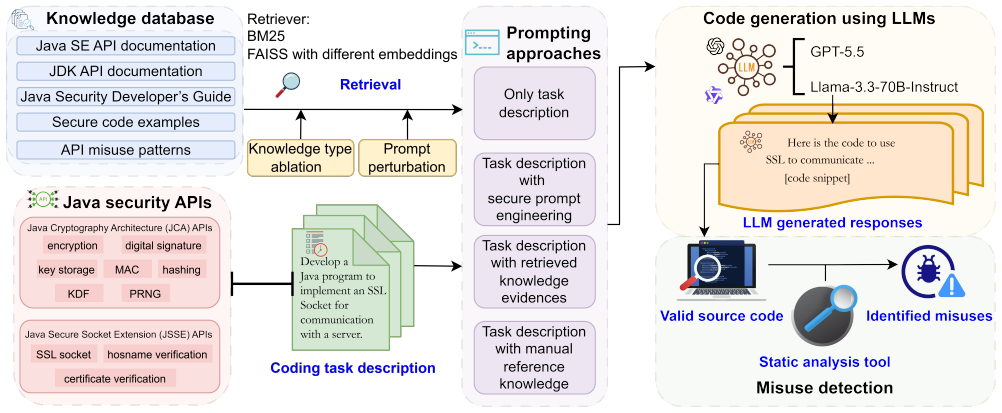
Replication of the original JCA and JSSE API misuse benchmark, now augmented with external security knowledge types including secure code examples, misuse patterns, and developer guides.
If this is right
- Newer models produce fewer misuses than those tested in 2024 but still produce some.
- Secure code examples give the largest single gain for the open-weight Llama model.
- Explicit misuse patterns remove all detected misuses for the GPT-5.5 model among valid programs.
- Developer-guide knowledge and secure prompting become more effective for the frontier proprietary model.
- The value of retrieval-augmented knowledge depends on both the knowledge supplied and the model's base capability.
Where Pith is reading between the lines
- Teams choosing an LLM for security-related coding tasks may need to select both the model and the knowledge type together rather than treating knowledge as universally additive.
- The remaining invalid outputs (compilation failures or API mismatches) point to a separate reliability problem that external security knowledge alone does not solve.
- Future replications could test whether the same knowledge types remain effective after the next round of model updates.
Load-bearing premise
The original benchmark tasks, misuse detection rules, and validity criteria still accurately measure real-world misuse when run on the newer models.
What would settle it
Running the same benchmark on GPT-5.5 and Llama-3.3-70B-Instruct without external knowledge and finding zero detected misuses in all valid outputs.
Figures
read the original abstract
The misuse of Java security APIs is a serious security problem in software development. Research in 2024 has shown that this problem is widespread in LLM-generated code. However, it remains unclear whether this phenomenon persists in current models and how external security knowledge affects it. This paper presents a scoped replication and extension of Mousavi et al.'s study on the Java Cryptography Architecture (JCA) and Java Secure Socket Extension (JSSE) APIs. We focus on two complementary settings: GPT-5.5 as a frontier proprietary coding model, and Llama-3.3-70B-Instruct as a strong open-weight model relevant to self-hosted deployment. The results show that although newer LLMs perform better in using Java security APIs, the problem of Java security API misuse has not been eliminated. External security knowledge substantially improves the measured outcome, but its effect is model-dependent. For Llama-3.3-70B-Instruct, secure code examples are the most effective single knowledge type. For GPT-5.5, explicit misuse patterns eliminate all detected security API misuses among valid programs in our benchmark, although some outputs remain invalid due to compilation errors or target-API mismatches. In addition, developer-guide knowledge becomes much more effective, and secure prompting also provides large gains for GPT-5.5. Overall, these findings confirm the Java security API misuse risk identified in the original study and show that the benefits of retrieval-augmented knowledge depend not only on the knowledge itself and retrieval behavior, but also on model capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper replicates and extends Mousavi et al. (2024) on misuse of Java Cryptography Architecture (JCA) and Java Secure Socket Extension (JSSE) APIs in LLM-generated code. Testing GPT-5.5 and Llama-3.3-70B-Instruct, it reports directional improvements over prior models but finds that misuse persists; external security knowledge (secure code examples, explicit misuse patterns, developer guides) substantially reduces detected misuses in a model-dependent way, with explicit misuse patterns eliminating all detected misuses among valid GPT-5.5 outputs while secure code examples are most effective for Llama.
Significance. If the results hold, the work confirms that Java security API misuse remains a live risk even in current frontier and open-weight LLMs and demonstrates that retrieval-augmented external security knowledge can mitigate it, though gains vary sharply by model and knowledge type. The replication design adds value by testing whether the 2024 findings generalize, and the model-specific patterns provide concrete guidance for secure prompting and RAG in coding assistants.
major comments (2)
- [Abstract] Abstract: the central claim that 'explicit misuse patterns eliminate all detected security API misuses among valid programs' for GPT-5.5 (and that misuse 'has not been eliminated' overall) rests on the assumption that the 2024 detection rules and validity criteria remain complete and accurate for outputs from GPT-5.5 and Llama-3.3-70B-Instruct. The manuscript gives no indication that these rules were re-validated against expert judgment or tested for coverage on the new models' potentially different code structures and partial-fix patterns.
- [Methods / experimental setup] Methods / experimental setup (referenced via the replication description): the benchmark tasks, misuse detection rules, and validity criteria are carried over without reported re-validation or sensitivity analysis for the new models. This is load-bearing because newer LLMs can produce novel error patterns or partial fixes that the prior rules may miss or misclassify, directly affecting the reported counts of 'eliminated' misuses and the model-dependent effect sizes.
minor comments (1)
- [Abstract] The abstract would benefit from stating the exact number of tasks/programs evaluated and the precise definition of 'valid programs' used for the 'eliminate all detected' claim.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the detection methodology in this replication. The two major comments raise a closely related concern about the reuse of the 2024 rules without explicit re-validation for the new models. We address both below and propose concrete revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'explicit misuse patterns eliminate all detected security API misuses among valid programs' for GPT-5.5 (and that misuse 'has not been eliminated' overall) rests on the assumption that the 2024 detection rules and validity criteria remain complete and accurate for outputs from GPT-5.5 and Llama-3.3-70B-Instruct. The manuscript gives no indication that these rules were re-validated against expert judgment or tested for coverage on the new models' potentially different code structures and partial-fix patterns.
Authors: The rules and validity criteria were deliberately carried over unchanged from Mousavi et al. (2024) to enable a direct, apples-to-apples replication. These rules encode objective, API-specification-derived misuse patterns (e.g., use of DES, static IVs, missing hostname verification) rather than model-specific stylistic features. In preparing the replication we performed a manual review of 50 randomly sampled GPT-5.5 and Llama-3.3 outputs and did not observe novel misuse categories that would evade the existing detectors. Nevertheless, we acknowledge that the manuscript does not explicitly document this check or a sensitivity analysis. In the revision we will add a new subsection (tentatively 3.4) that (a) restates the rule provenance, (b) reports the manual spot-check results, and (c) discusses the risk of partial-fix patterns in newer models. revision: yes
-
Referee: [Methods / experimental setup] Methods / experimental setup (referenced via the replication description): the benchmark tasks, misuse detection rules, and validity criteria are carried over without reported re-validation or sensitivity analysis for the new models. This is load-bearing because newer LLMs can produce novel error patterns or partial fixes that the prior rules may miss or misclassify, directly affecting the reported counts of 'eliminated' misuses and the model-dependent effect sizes.
Authors: We agree that the absence of an explicit re-validation discussion is a limitation of the current draft. The benchmark tasks themselves are identical to the original study; only the LLMs and the external-knowledge conditions are new. Because the detection logic operates on static code properties, it is in principle model-agnostic, yet we recognize that empirical confirmation is still warranted. The revision will therefore include (i) a brief sensitivity analysis on a 10 % stratified sample of all generated programs (both valid and invalid) and (ii) an explicit statement that any future extension of the benchmark should re-run the expert validation step. These additions will be placed in Section 3 and referenced from the abstract. revision: yes
Circularity Check
No circularity: empirical replication with direct counts against external benchmark
full rationale
This is a scoped replication study that measures LLM-generated code against fixed benchmark tasks and misuse detection rules carried over from Mousavi et al. (2024). No derivations, equations, fitted parameters, or self-referential definitions appear in the abstract or described methodology. Results consist of direct counts of code properties (secure vs. misuse) under different prompting conditions. The cited 2024 work is by different authors and functions as an external benchmark rather than a self-citation chain. No load-bearing step reduces to a fit, ansatz, or author-overlapping uniqueness claim. The study is therefore self-contained against its stated external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The JCA/JSSE misuse detection rules and task set from Mousavi et al. 2024 remain valid and unbiased when applied to newer models.
Reference graph
Works this paper leans on
-
[1]
2025 Stack Overflow developer survey,
“2025 Stack Overflow developer survey,” accessed: 2026-04-11. [Online]. Available: https://survey.stackoverflow.co/2025/
2025
-
[2]
A survey on large language models for code generation,
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,”ACM Transactions on Software Engineering and Methodology, vol. 35, no. 2, 2026
2026
-
[3]
Evaluating Large Language Models Trained on Code
M. Chenet al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
An investigation into misuse of Java security APIs by large lan- guage models,
Z. Mousavi, C. Islam, K. Moore, A. Abuadbba, and M. A. Babar, “An investigation into misuse of Java security APIs by large lan- guage models,” inProceedings of the 19th ACM Asia Conference on Computer and Communications Security, 2024, pp. 1299–1315
2024
-
[5]
Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions,”Communications of the ACM, vol. 68, no. 2, pp. 96– 105, 2025
2025
-
[6]
A. Mohsin, H. Janicke, A. Wood, I. H. Sarker, L. Maglaras, and N. Janjua, “Can we trust large language models generated code? A framework for in-context learning, security patterns, and code evaluations across diverse LLMs,”arXiv preprint arXiv:2406.12513, 2024
-
[7]
How secure is code generated by ChatGPT?
R. Khoury, A. R. Avila, J. Brunelle, and B. M. Camara, “How secure is code generated by ChatGPT?” in2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2023, pp. 2445–2451
2023
-
[8]
Identifying and mitigating API misuse in large language models,
T. Y . Zhuoet al., “Identifying and mitigating API misuse in large language models,”IEEE Transactions on Software Engineering, 2026
2026
-
[9]
LLM hallucinations in practical code generation: Phenomena, mechanism, and mitigation,
Z. Zhanget al., “LLM hallucinations in practical code generation: Phenomena, mechanism, and mitigation,”Proceedings of the ACM on Software Engineering, vol. 2, no. ISSTA, pp. 481–503, 2025
2025
-
[10]
Security weaknesses of Copilot-generated code in GitHub projects: An empirical study,
Y . Fuet al., “Security weaknesses of Copilot-generated code in GitHub projects: An empirical study,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 8, pp. 1–34, 2025
2025
-
[11]
What is wrong with your code generated by large language models? An extensive study,
S. Douet al., “What is wrong with your code generated by large language models? An extensive study,”Science China Information Sciences, vol. 69, no. 1, p. 112107, 2026
2026
-
[12]
Detecting misuse of security APIs: A systematic review,
Z. Mousavi, C. Islam, M. A. Babar, A. Abuadbba, and K. Moore, “Detecting misuse of security APIs: A systematic review,”ACM Computing Surveys, vol. 57, no. 12, pp. 1–39, 2025
2025
-
[13]
Crysl: An extensible approach to validating the correct usage of cryptographic APIs,
S. Kr ¨uger, J. Sp ¨ath, K. Ali, E. Bodden, and M. Mezini, “Crysl: An extensible approach to validating the correct usage of cryptographic APIs,”IEEE Transactions on Software Engineering, vol. 47, no. 11, pp. 2382–2400, 2019
2019
-
[14]
An em- pirical study of cryptographic misuse in android applications,
M. Egele, D. Brumley, Y . Fratantonio, and C. Kruegel, “An em- pirical study of cryptographic misuse in android applications,” in Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications security, 2013, pp. 73–84
2013
-
[15]
To fix or not to fix: A critical study of crypto-misuses in the wild,
A.-K. Wickert, L. Baumg ¨artner, M. Schlichtig, K. Narasimhan, and M. Mezini, “To fix or not to fix: A critical study of crypto-misuses in the wild,” in2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). IEEE, 2022, pp. 315–322
2022
-
[16]
Retrieval-augmented generation for knowledge- intensive NLP tasks,
P. Lewiset al., “Retrieval-augmented generation for knowledge- intensive NLP tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[17]
Language models are few-shot learners,
T. Brownet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
1901
-
[18]
Benchmarking large language models in retrieval-augmented generation,
J. Chen, H. Lin, X. Han, and L. Sun, “Benchmarking large language models in retrieval-augmented generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 754–17 762
2024
-
[19]
J. Chen, S. Chen, J. Cao, J. Shen, and S.-C. Cheung, “When LLMs meet api documentation: Can retrieval augmentation aid code gener- ation just as it helps developers?”arXiv preprint arXiv:2503.15231, 2025
-
[20]
Prompting techniques for secure code generation: A system- atic investigation,
C. Tony, N. E. D ´ıaz Ferreyra, M. Mutas, S. Dhif, and R. Scandari- ato, “Prompting techniques for secure code generation: A system- atic investigation,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 8, pp. 1–53, 2025
2025
-
[21]
Instruction tuning for secure code generation,
J. He, M. Vero, G. Krasnopolska, and M. Vechev, “Instruction tuning for secure code generation,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[22]
Cosec: On-the-fly security hardening of code LLMs via supervised co-decoding,
D. Liet al., “Cosec: On-the-fly security hardening of code LLMs via supervised co-decoding,” inProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, 2024, pp. 1428–1439
2024
-
[23]
Seccoder: Towards generalizable and robust secure code generation,
B. Zhanget al., “Seccoder: Towards generalizable and robust secure code generation,” inProceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, 2024, pp. 14 557– 14 571
2024
-
[24]
Rescue: Retrieval augmented secure code generation,
J. Shi and T. Zhang, “Rescue: Retrieval augmented secure code generation,”arXiv preprint arXiv:2510.18204, 2025
-
[25]
Sosecure: Safer code gen- eration with RAG and StackOverflow discussions,
M. Mukherjee and V . J. Hellendoorn, “Sosecure: Safer code gen- eration with RAG and StackOverflow discussions,”arXiv preprint arXiv:2503.13654, 2025
-
[26]
CodeRAG-bench: Can retrieval augment code generation?
Z. Z. Wanget al., “CodeRAG-bench: Can retrieval augment code generation?” inFindings of the Association for Computational Lin- guistics: NAACL 2025, 2025, pp. 3199–3214
2025
-
[27]
Give LLMs a security course: Securing retrieval-augmented code generation via knowledge injection,
B. Lin, S. Wang, Y . Qin, L. Chen, and X. Mao, “Give LLMs a security course: Securing retrieval-augmented code generation via knowledge injection,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 3356–3370
2025
-
[28]
What to retrieve for effective retrieval-augmented code generation? An empirical study and beyond,
W. Guet al., “What to retrieve for effective retrieval-augmented code generation? An empirical study and beyond,”arXiv preprint arXiv:2503.20589, 2025
-
[29]
A com- prehensive framework for evaluating API-oriented code generation in large language models,
Y . Wu, P. He, Z. Wang, S. Wang, Y . Tian, and T.-H. Chen, “A com- prehensive framework for evaluating API-oriented code generation in large language models,”arXiv preprint arXiv:2409.15228, 2024
- [30]
-
[31]
Opti- mizing large language model hyperparameters for code generation,
C. Arora, A. I. Sayeed, S. Licorish, F. Wang, and C. Treude, “Opti- mizing large language model hyperparameters for code generation,” arXiv preprint arXiv:2408.10577, 2024
-
[32]
CryptoGuard: High precision detection of crypto- graphic vulnerabilities in massive-sized Java projects,
S. Rahamanet al., “CryptoGuard: High precision detection of crypto- graphic vulnerabilities in massive-sized Java projects,” inProceedings of the 2019 ACM SIGSAC Conference on Computer and Communi- cations Security, 2019, pp. 2455–2472
2019
-
[33]
arXiv preprint arXiv:2404.00610 , year=
C.-M. Chanet al., “RQ-RAG: Learning to refine queries for retrieval augmented generation,”arXiv preprint arXiv:2404.00610, 2024
-
[34]
Robertson and H
S. Robertson and H. Zaragoza,The probabilistic relevance frame- work: BM25 and beyond. Now Publishers Inc, 2009, vol. 4
2009
-
[35]
The FAISS library,
M. Douzeet al., “The FAISS library,”IEEE Transactions on Big Data, 2025
2025
-
[36]
xRAG: Extreme context compression for retrieval- augmented generation with one token,
X. Chenget al., “xRAG: Extreme context compression for retrieval- augmented generation with one token,”Advances in Neural Informa- tion Processing Systems, vol. 37, pp. 109 487–109 516, 2024
2024
-
[37]
Fine-tuning or retrieval? Comparing knowledge injection in LLMs,
O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? Comparing knowledge injection in LLMs,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 237–250
2024
-
[38]
Bridg- ing the preference gap between retrievers and LLMs,
Z. Ke, W. Kong, C. Li, M. Zhang, Q. Mei, and M. Bendersky, “Bridg- ing the preference gap between retrievers and LLMs,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024, pp. 10 438–10 451
2024
-
[39]
Security in the software development lifecycle,
H. Assal and S. Chiasson, “Security in the software development lifecycle,” inFourteenth Symposium on Usable Privacy and Security (SOUPS 2018), 2018, pp. 281–296
2018
-
[40]
Do LLMs consider security? An empirical study on responses to programming questions,
A. Sajadi, B. Le, A. Nguyen, K. Damevski, and P. Chatterjee, “Do LLMs consider security? An empirical study on responses to programming questions,”Empirical Software Engineering, vol. 30, no. 4, p. 101, 2025
2025
-
[41]
A prompt pattern catalog to enhance prompt engi- neering with ChatGPT,
J. Whiteet al., “A prompt pattern catalog to enhance prompt engi- neering with ChatGPT,” inProceedings of the 30th Conference on Pattern Languages of Programs, 2023, pp. 1–31
2023
-
[42]
Surveying the RAG attack surface and defenses: Protecting sensitive company data,
L. V onderhaar, D. Machado, and O. Ochoa, “Surveying the RAG attack surface and defenses: Protecting sensitive company data,” in 2025 IEEE International Conference on Artificial Intelligence Testing. IEEE, 2025, pp. 69–76
2025
-
[43]
Guidelines to prompt large language models for code generation: An empirical characterization,
A. Midolo, A. Giagnorio, F. Zampetti, R. Tufano, G. Bavota, and M. Di Penta, “Guidelines to prompt large language models for code generation: An empirical characterization,”arXiv preprint arXiv:2601.13118, 2026
-
[44]
Statistical methods for research workers,
R. A. Fisher, “Statistical methods for research workers,” inBreak- throughs in Statistics: Methodology and Distribution. Springer, 1970, pp. 66–70
1970
-
[45]
Controlling the false discovery rate: A practical and powerful approach to multiple testing,
Y . Benjamini and Y . Hochberg, “Controlling the false discovery rate: A practical and powerful approach to multiple testing,”Journal of the Royal Statistical Society: Series B (Methodological), vol. 57, no. 1, pp. 289–300, 1995
1995
-
[46]
Dense passage retrieval for open-domain ques- tion answering,
V . Karpukhinet al., “Dense passage retrieval for open-domain ques- tion answering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6769– 6781
2020
-
[47]
Embedding secure coding instruction into the IDE: Complementing early and intermediate CS courses with ESIDE,
M. Whitney, H. R. Lipford, B. Chu, and T. Thomas, “Embedding secure coding instruction into the IDE: Complementing early and intermediate CS courses with ESIDE,”Journal of Educational Com- puting Research, vol. 56, no. 3, pp. 415–438, 2018
2018
-
[48]
Do users write more insecure code with AI assistants?
N. Perry, M. Srivastava, D. Kumar, and D. Boneh, “Do users write more insecure code with AI assistants?” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Secu- rity, 2023, pp. 2785–2799
2023
-
[49]
Large language models for code: Security hardening and adversarial testing,
J. He and M. Vechev, “Large language models for code: Security hardening and adversarial testing,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 1865–1879
2023
-
[50]
Passage retrieval for question answering using sliding windows,
M. Khalid and S. Verberne, “Passage retrieval for question answering using sliding windows,” inColing 2008: Proceedings of the 2nd workshop on Information Retrieval for Question Answering, 2008, pp. 26–33
2008
-
[51]
cAST: Enhancing code retrieval-augmented generation with struc- tural chunking via abstract syntax tree,
Y . Zhang, X. Zhao, Z. Z. Wang, C. Yang, J. Wei, and T. Wu, “cAST: Enhancing code retrieval-augmented generation with struc- tural chunking via abstract syntax tree,” inFindings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 8106–8116
2025
-
[52]
Output format biases in the evaluation of large language models for code translation,
M. Macedo, Y . Tian, F. R. Cogo, and B. Adams, “Output format biases in the evaluation of large language models for code translation,” Empirical Software Engineering, vol. 31, no. 2, p. 41, 2026
2026
-
[53]
Codejudge: Evaluating code generation with large language models,
W. Tong and T. Zhang, “Codejudge: Evaluating code generation with large language models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 20 032–20 051. Appendix A. Details of Corpus Construction and Manual Reference Knowledge The knowledge base contains API documentation, de- veloper guides, code exampl...
2024
-
[54]
Misuse patterns are derived from Mousavi et al
and manual review. Misuse patterns are derived from Mousavi et al. [4] and rewritten for clarity without chang- ing the underlying misuse categories. Each misuse-pattern chunk contains a short description of the misuse, why it matters, and how to avoid it
-
[55]
https://docs.oracle.com/en/java/javase/21/docs/api/index.html
-
[56]
https://docs.oracle.com/en/java/javase/21/docs/specs/security/standa rd-names.html
-
[57]
https://docs.oracle.com/en/java/javase/21/security/index.html
-
[58]
https://www.java.com/en/configure crypto.html
-
[59]
https://foojay.io/today/securing-symmetric-encryption-algorithms-i n-java/, https://cheatsheetseries.owasp.org/cheatsheets/Java Security Che at Sheet.html, https://mkyong.com/java/, https://dev.java/learn/security/intr o/
-
[60]
correct API usage
https://docs.oracle.com/javase/8/docs/technotes/guides/security/jsse/s amples/ For corpora downloaded as HTML files, we split them by H2 headings by default. We set each chunk to be around 500 words [26]. If an H2 section exceeds 500 words, we chunk them by the end of the last paragraphs and make sure the code blocks or tables stay in the same chunk. Ther...
-
[61]
(b) Stacked bar chart for GPT-4o-mini for ablation experiment
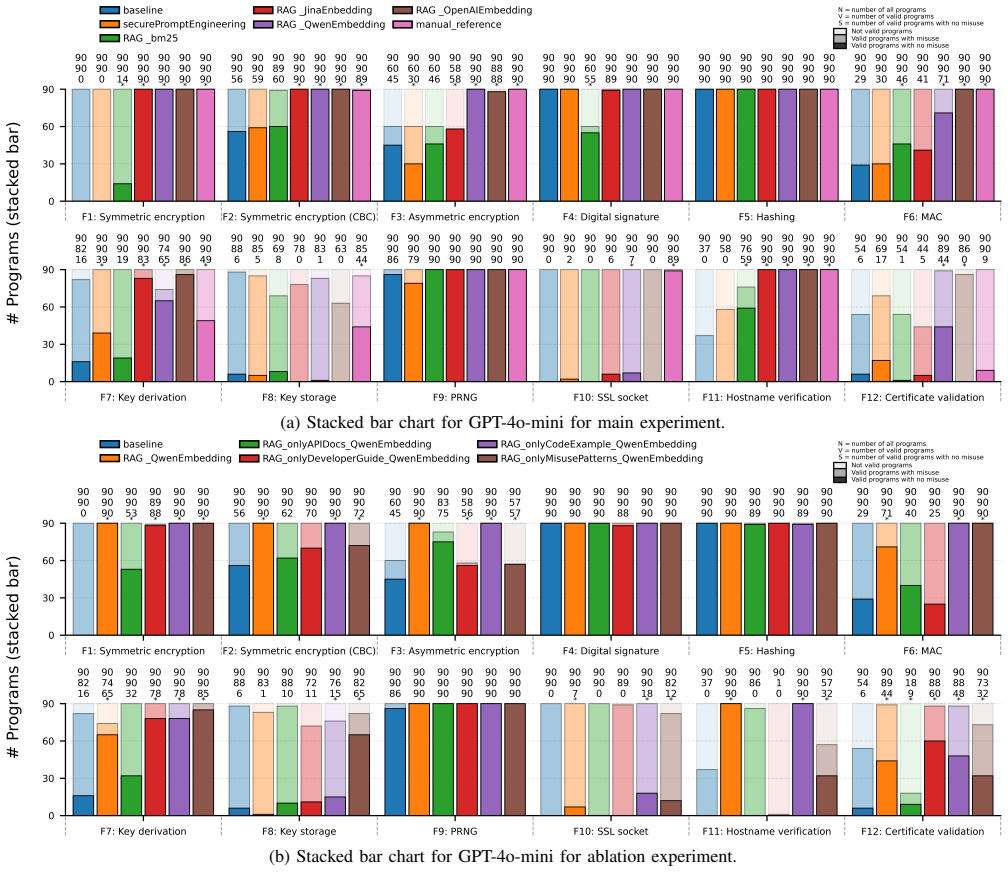
https://www.oracle.com/nz/java/technologies/javase/javase8-archive -downloads.html (a) Stacked bar chart for GPT-4o-mini for main experiment. (b) Stacked bar chart for GPT-4o-mini for ablation experiment. Figure 4: Functionality-level stacked counts for GPT-4o-mini under the main experimental settings and ablation study settings. The stacked bars, cumulat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.