On the Robustness of Multilingual Text Embedding Rankings Across Learning Tasks, Languages, and Benchmark Datasets
Pith reviewed 2026-06-28 22:41 UTC · model grok-4.3
The pith
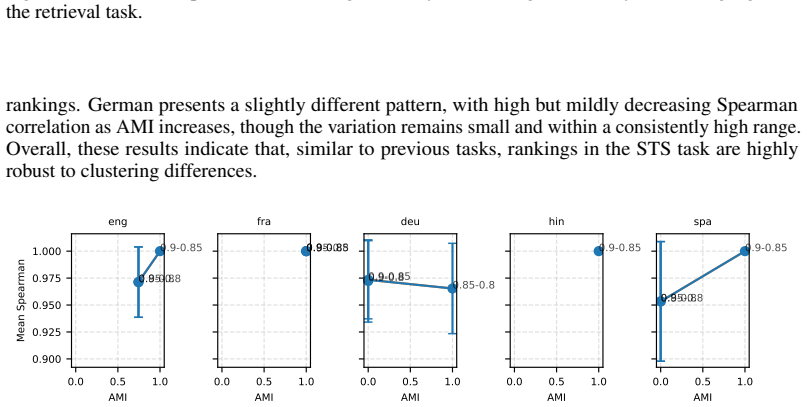
Rankings of multilingual text embedding models shift depending on which datasets are included and how scores are aggregated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
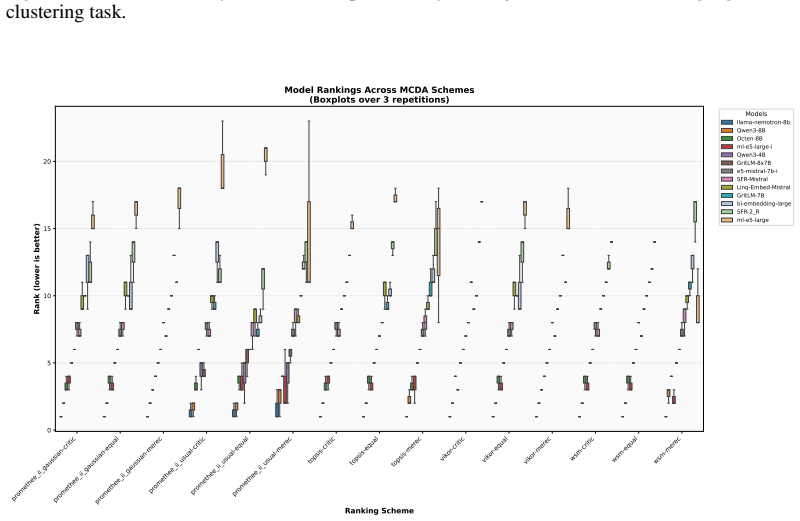
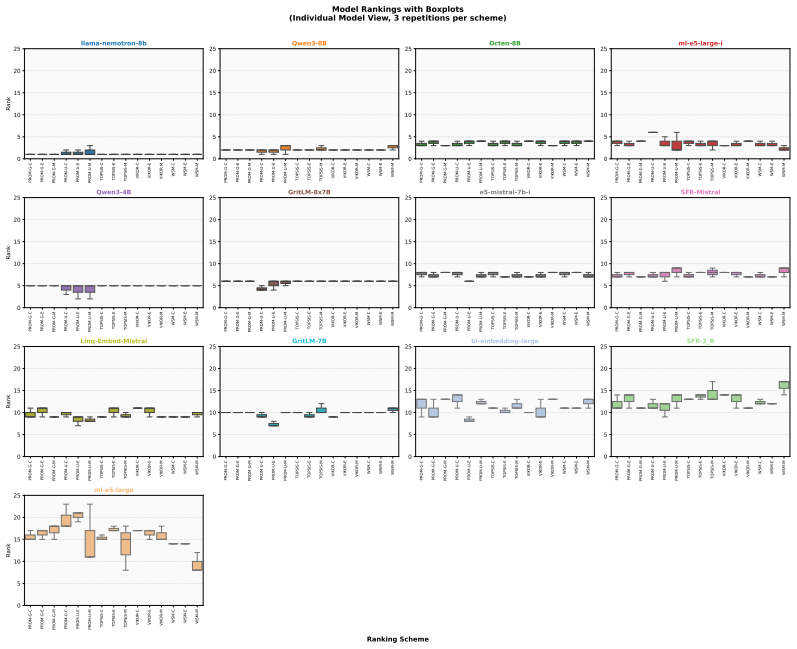
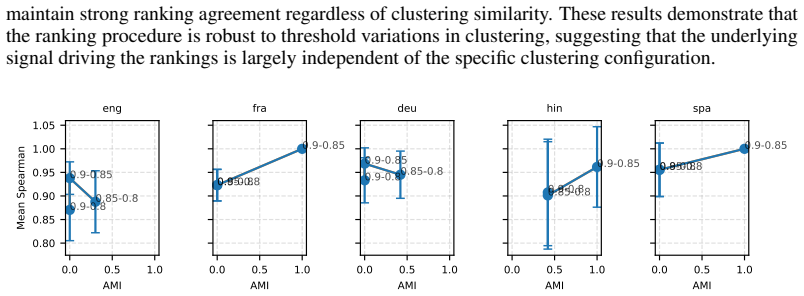
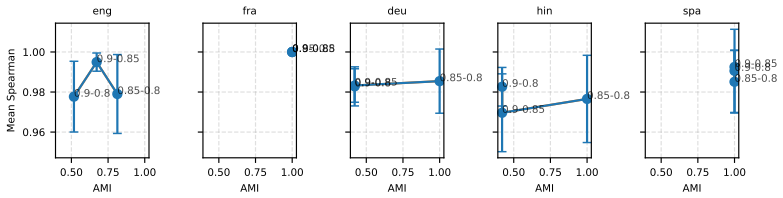
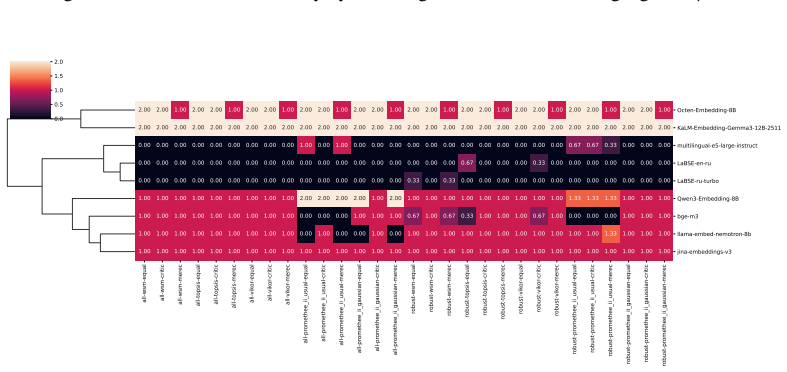
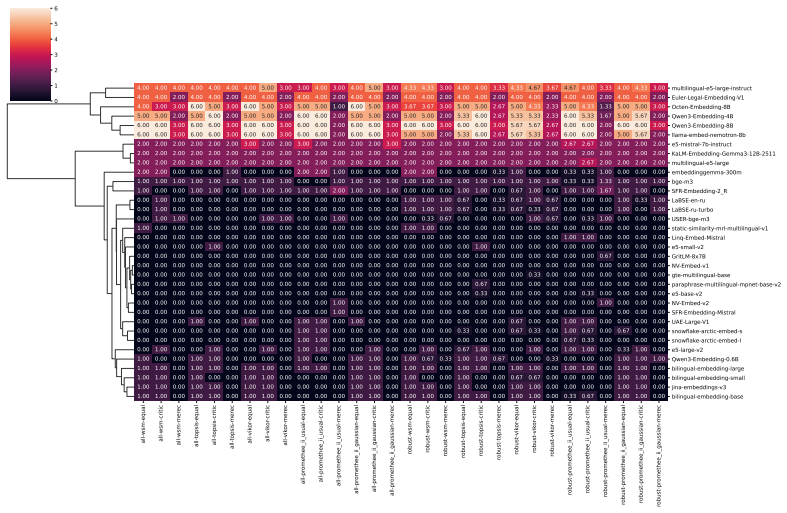
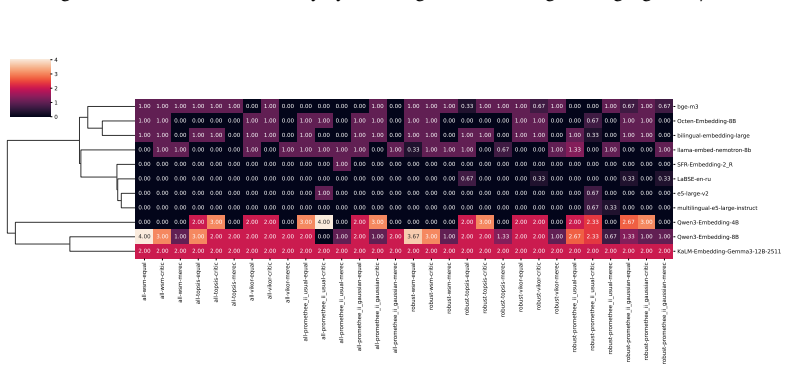
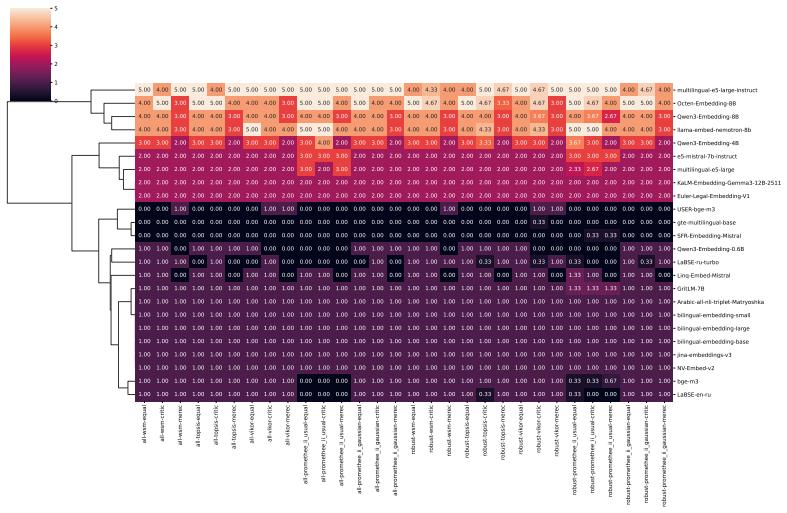
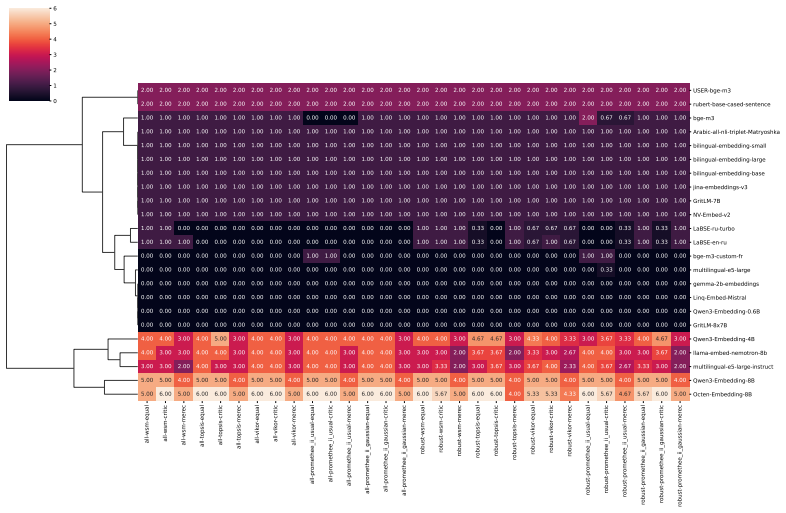
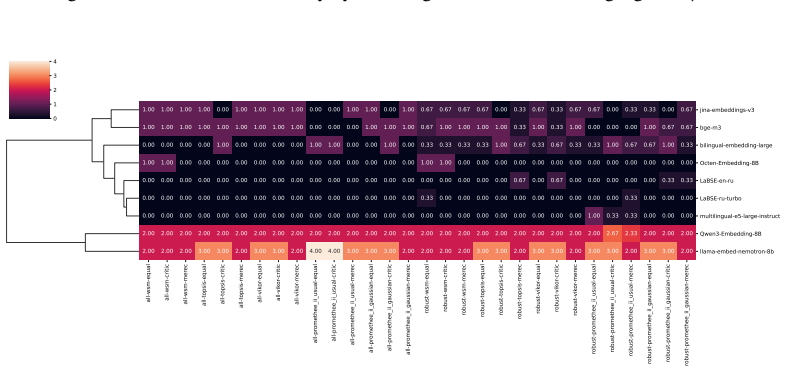
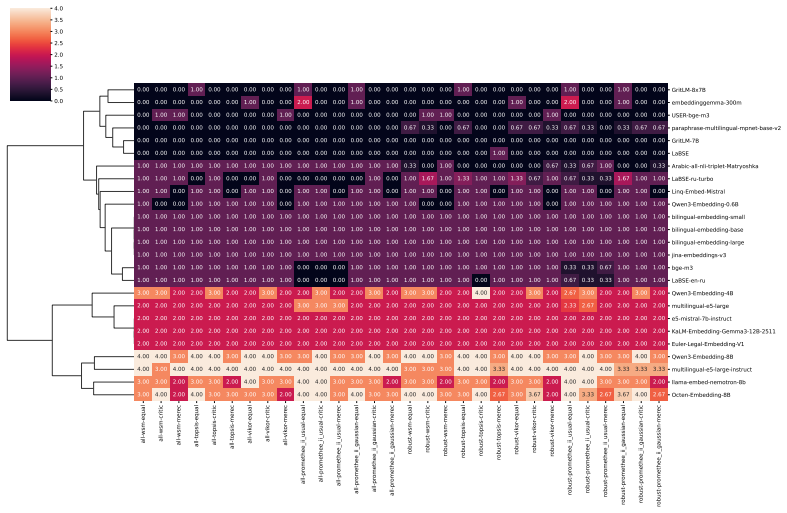
Benchmarking conclusions about which multilingual text embedding models perform best depend on implicit choices of dataset compositions and performance aggregation methods; applying a range of multi-criteria decision-making ranking schemes and the two new robustness indicators shows that only a small subset of models remains consistently strong across tasks, ranking schemes, and data subsamples, although large-scale LLM-based models are often robust top performers except in tasks such as retrieval.
What carries the argument
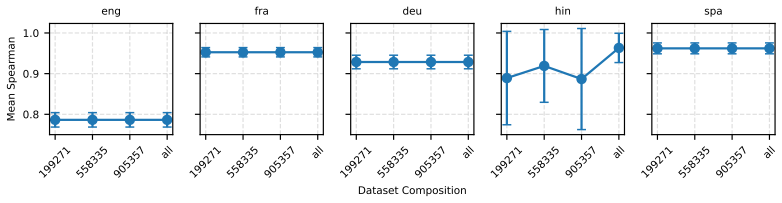
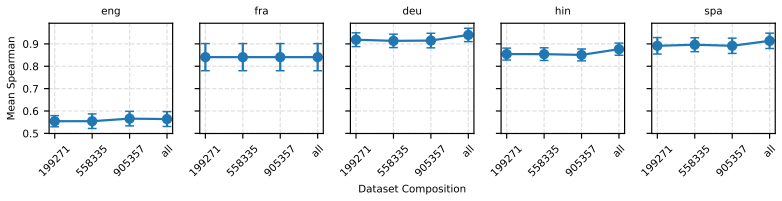
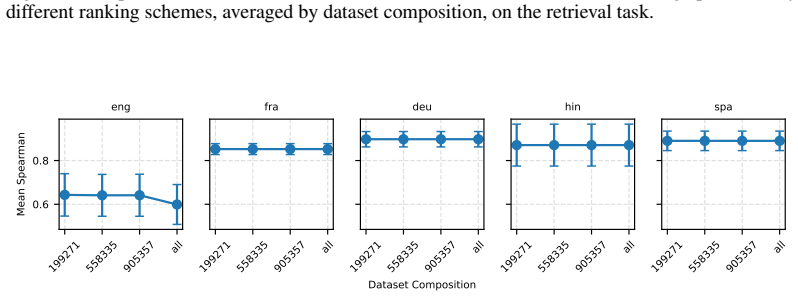
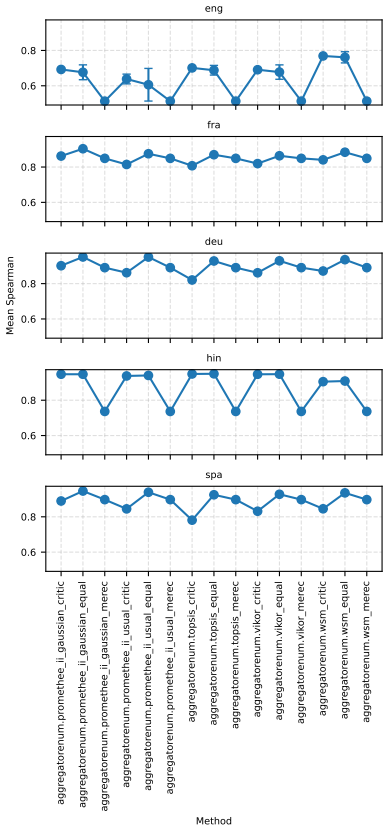
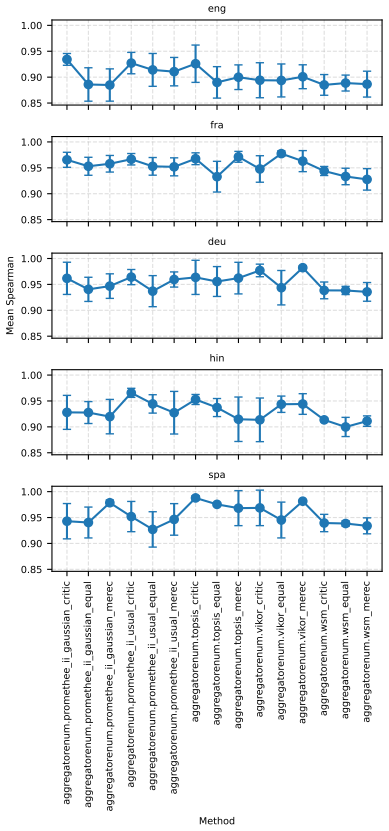
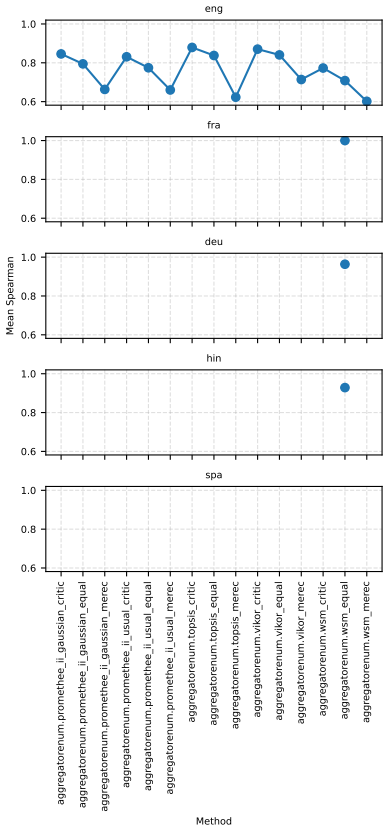
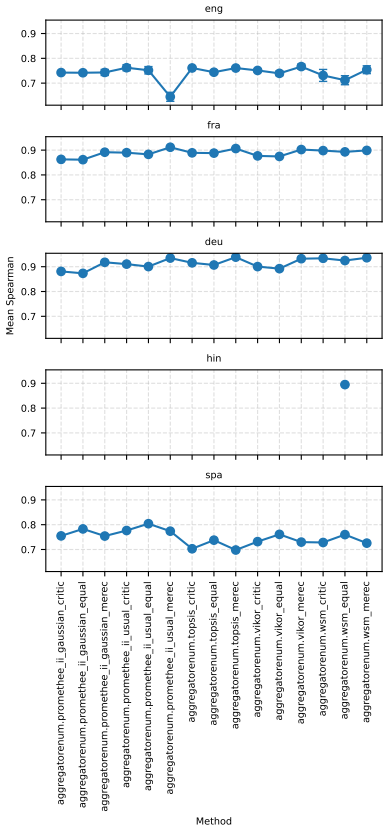
Two robustness indicators—dataset-composition robustness (sensitivity of rankings to changing dataset compositions) and ranking-scheme robustness (sensitivity to aggregation method change)—that quantify stability of model orderings under altered evaluation designs.
If this is right
- Large-scale LLM-based models are often robust top performers across most tasks but not uniformly, for instance in retrieval.
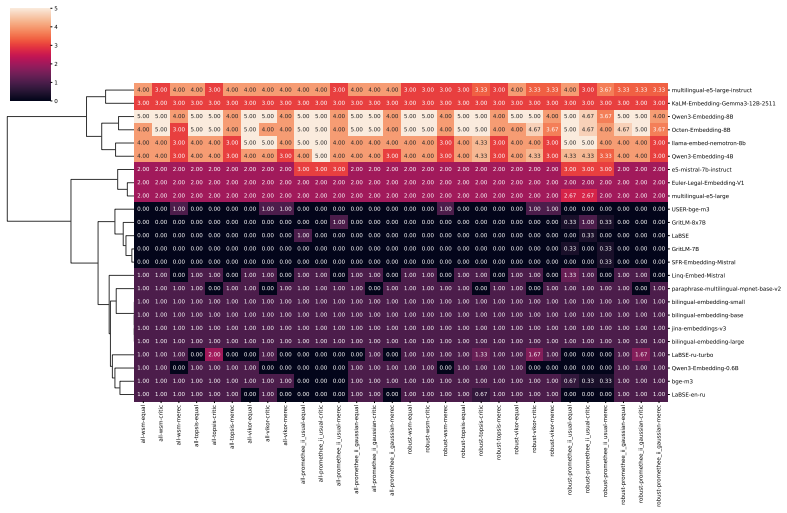
- Only a small subset of models remains consistently strong when tasks, ranking schemes, and data subsamples are varied together.
- Task-specific analyses reveal that stability of model rankings differs by learning task.
- Results released for approximately 230 additional languages extend the sensitivity findings beyond the five languages examined in depth.
Where Pith is reading between the lines
- Evaluators who weight languages or tasks differently from the MTEB default may obtain different model recommendations.
- Applications that rely on a single top-ranked model should test that model on their own data compositions rather than assuming benchmark stability.
- Future benchmark releases could report the two robustness indicators alongside raw scores so users can judge ranking reliability directly.
Load-bearing premise
The MTEB dataset collection and the chosen five languages plus nine tasks supply a representative sample for detecting sensitivity of rankings to composition and aggregation changes.
What would settle it
Re-computing all rankings on every possible subset of the MTEB datasets and every aggregation method and finding that the identical set of models always occupies the top positions would falsify the claim that rankings are sensitive to those choices.
Figures

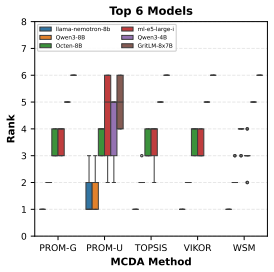
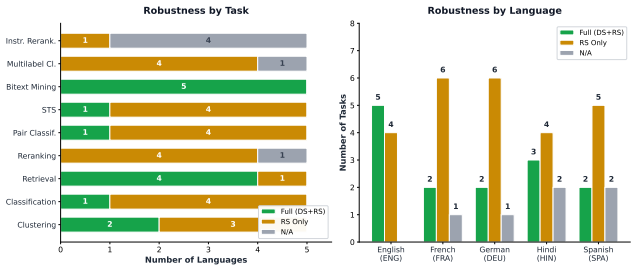
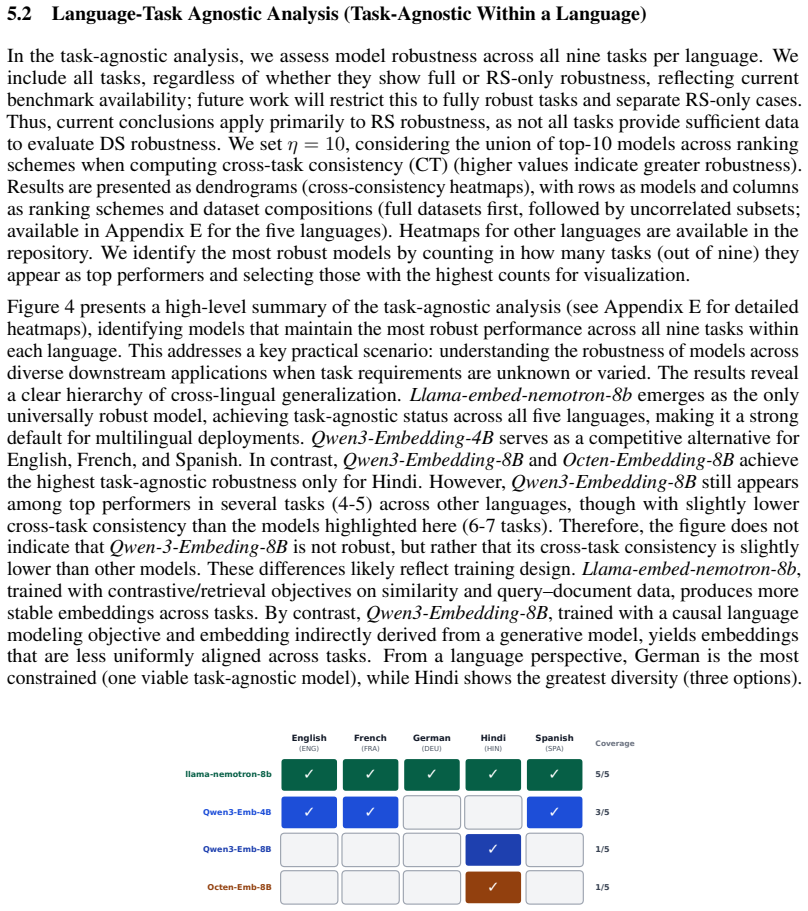
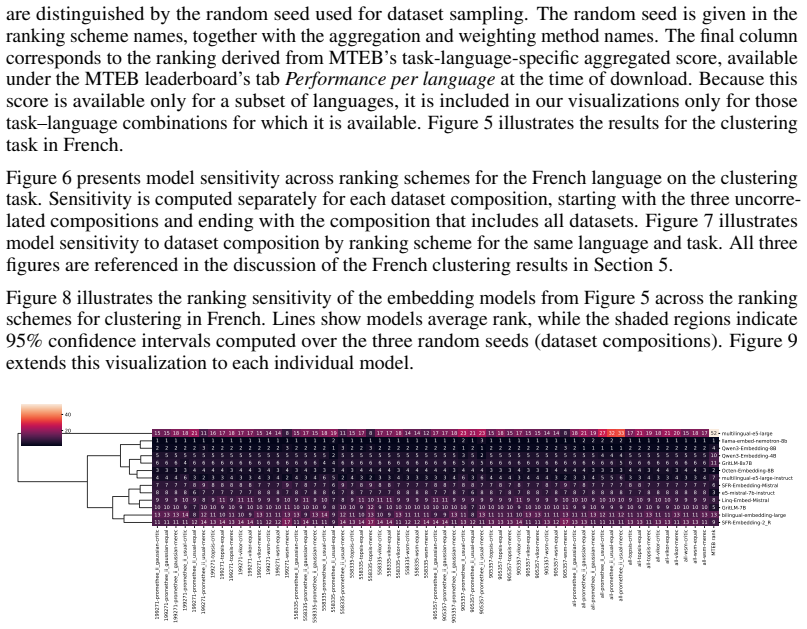

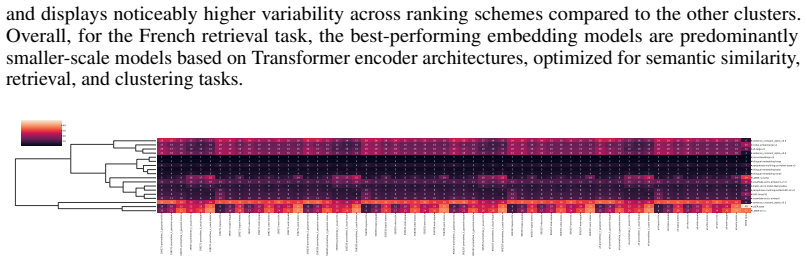



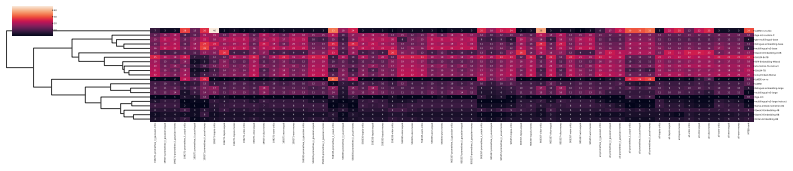

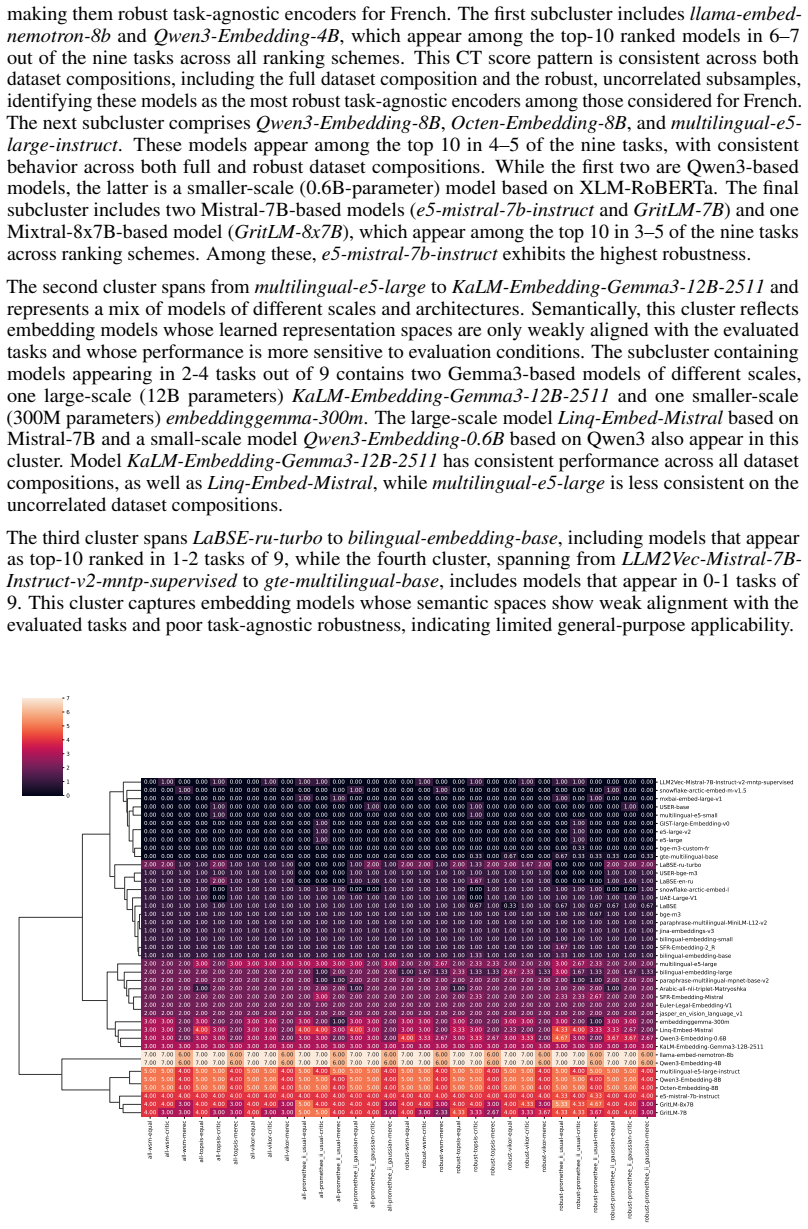

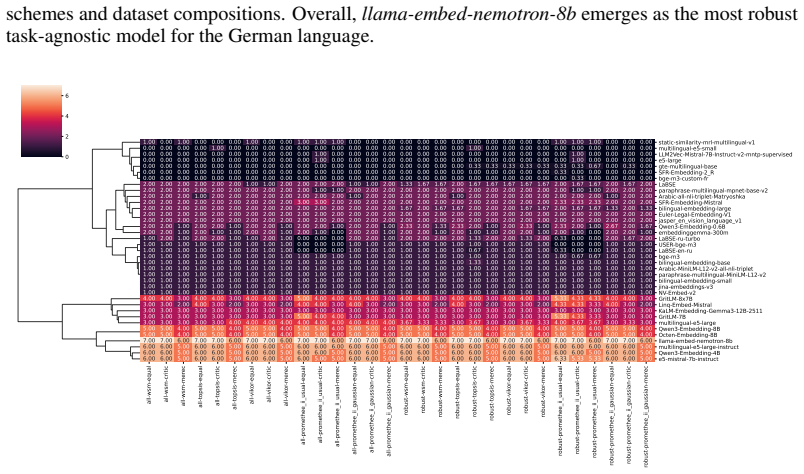


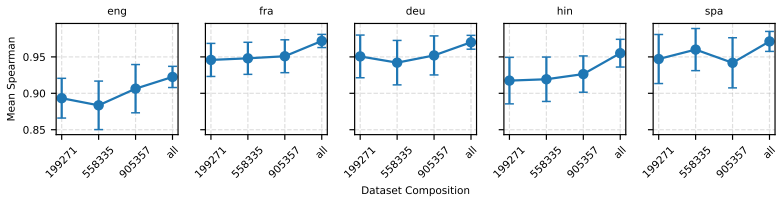
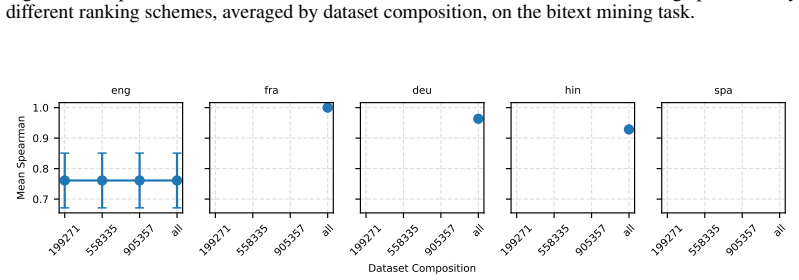
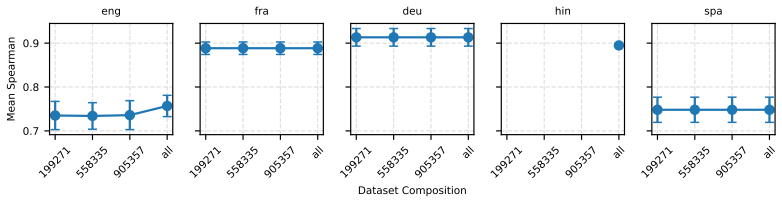
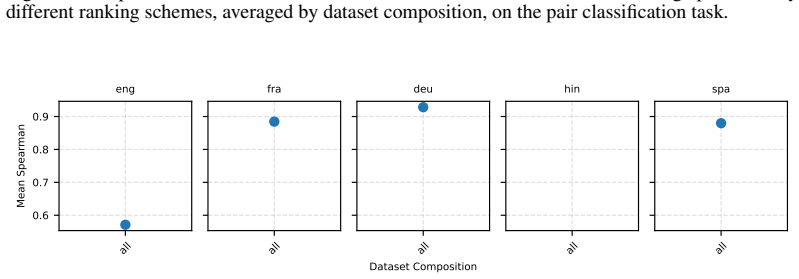
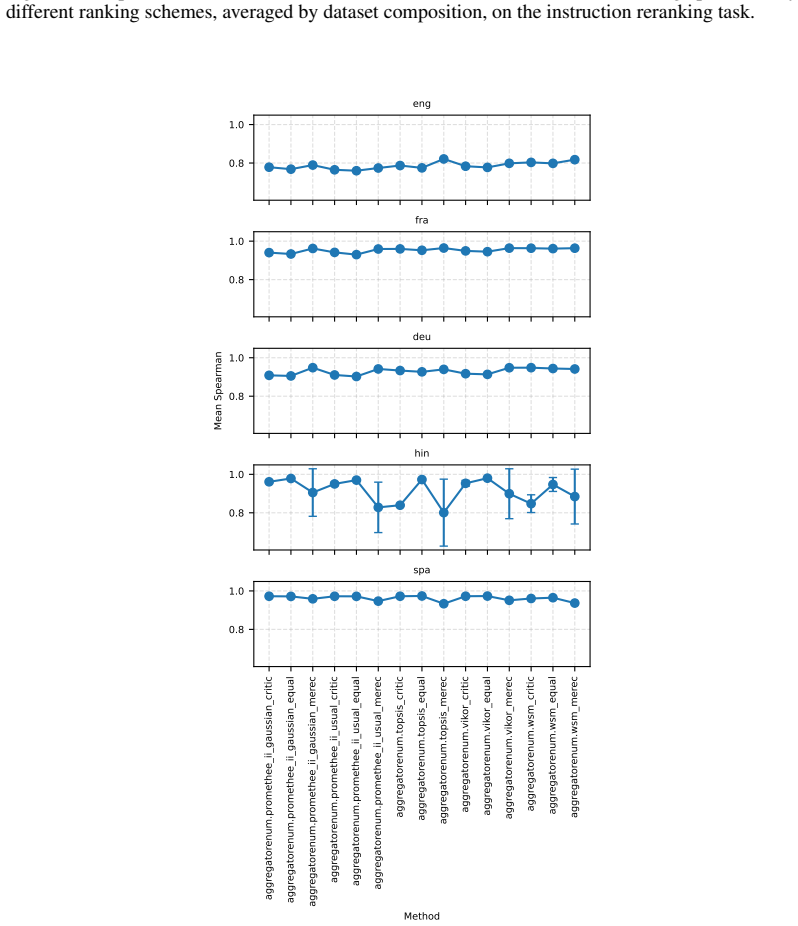
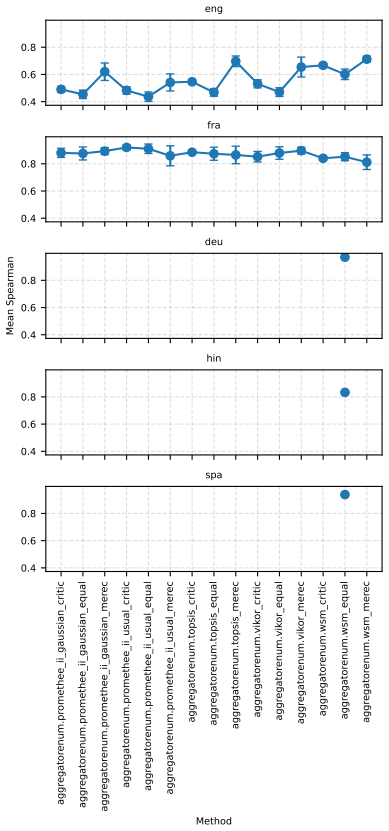
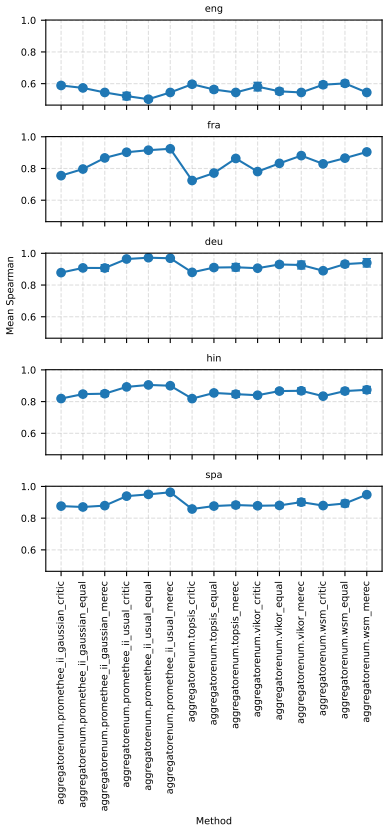
read the original abstract
Large-scale multilingual text embedding models play crucial role in both research and industry, yet their behavior in language-specific, multi-task settings remains insufficiently understood. Although benchmarking platforms such as MTEB report results across more than 250 languages, conclusions about model superiority often depend on implicit choices of dataset compositions and performance aggregation methods. To address this gap, we present a meta-study of multilingual model performance robustness in MTEB, applying a diverse set of multi-criteria decision-making ranking schemes and introducing two robustness indicators: dataset-composition robustness (sensitivity of rankings to changing dataset compositions) and ranking-scheme robustness (sensitivity to aggregation method change). They enable systematic sensitivity analysis of whether benchmarking conclusions remain stable under different evaluation designs. We conduct an in-depth analysis on five languages (English, French, German, Hindi, and Spanish) across nine tasks (e.g., classification, clustering, retrieval) and release results for approximately 230 additional languages. The task-specific analyses show that large-scale LLM-based models are often robust top performers, though not uniformly (e.g., in retrieval task), while task-agnostic results reveal that only a small subset of models remains consistently strong across tasks, ranking schemes, and data subsamples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a meta-study of multilingual text embedding model performance on the MTEB benchmark. It introduces two new indicators—dataset-composition robustness (sensitivity of rankings to dataset composition changes) and ranking-scheme robustness (sensitivity to aggregation method changes)—and applies multi-criteria decision-making ranking schemes to analyze stability. The study focuses on five languages (English, French, German, Hindi, Spanish) across nine tasks, finds that large-scale LLM-based models are often robust top performers in task-specific settings (though not uniformly, e.g., retrieval), and concludes that only a small subset of models remains consistently strong across tasks, schemes, and subsamples in task-agnostic analyses. Extended results for ~230 additional languages are released.
Significance. If the central findings hold, the work offers a systematic framework for assessing how benchmarking conclusions depend on evaluation design choices, which is relevant for reliable model selection in multilingual settings. The release of results for additional languages is a concrete positive contribution that supports reproducibility and further analysis.
major comments (1)
- [meta-study design and analysis scope] The task-agnostic conclusion that only a small subset of models remains consistently strong across tasks, ranking schemes, and data subsamples is load-bearing on the representativeness of the chosen five languages and nine tasks (plus implicit MTEB dataset compositions). The meta-study design applies the new robustness indicators only within this scope; without explicit justification, comparison to the full MTEB variability (250+ languages, dozens of datasets per task), or external validation, the observed consistency may not generalize beyond the selected slice.
minor comments (1)
- [methods] The abstract and methods description omit precise details on dataset subsampling rules, the exact computation of the two robustness indicators, statistical tests applied, and error handling; adding these would strengthen verifiability of the reported sensitivities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our meta-study. We address the major comment below.
read point-by-point responses
-
Referee: [meta-study design and analysis scope] The task-agnostic conclusion that only a small subset of models remains consistently strong across tasks, ranking schemes, and data subsamples is load-bearing on the representativeness of the chosen five languages and nine tasks (plus implicit MTEB dataset compositions). The meta-study design applies the new robustness indicators only within this scope; without explicit justification, comparison to the full MTEB variability (250+ languages, dozens of datasets per task), or external validation, the observed consistency may not generalize beyond the selected slice.
Authors: We appreciate the referee highlighting this point. The five languages (English, French, German, Hindi, Spanish) were selected to span high- and low-resource settings and multiple language families while enabling computationally intensive robustness analyses across nine tasks and multiple ranking schemes; extending the full indicator computation to all 250+ languages would have been prohibitive. The task-agnostic conclusions are scoped to this representative slice, and the manuscript already releases per-language results for ~230 additional languages to support community extensions. We agree that the current version lacks explicit justification for the selection and a limitations discussion on generalizability; we will add both in the revision. revision: yes
Circularity Check
No significant circularity; empirical meta-analysis on public benchmarks
full rationale
The paper defines two new robustness indicators (dataset-composition robustness and ranking-scheme robustness) and applies them to existing MTEB data for five languages and nine tasks. No equations, predictions, or derivations are present that reduce claimed results to fitted parameters, self-citations, or self-definitions by construction. The analysis consists of sensitivity checks on public benchmark outputs using multi-criteria ranking schemes; conclusions about model consistency follow directly from the computed indicators on the chosen data slice without circular reduction. Self-citations, if any, are not load-bearing for uniqueness theorems or ansatzes. This is a standard empirical meta-study whose central claims remain independent of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MTEB benchmark results across languages and tasks form a suitable base for sensitivity analysis of rankings
invented entities (2)
-
dataset-composition robustness indicator
no independent evidence
-
ranking-scheme robustness indicator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
2026
-
[2]
Embedding-informed adaptive retrieval-augmented generation of large language models
Chengkai Huang, Yu Xia, Rui Wang, Kaige Xie, Tong Yu, Julian McAuley, and Lina Yao. Embedding-informed adaptive retrieval-augmented generation of large language models. In Proceedings of the 31st International Conference on Computational Linguistics, pages 1403– 1412, 2025
2025
-
[3]
Enevoldsen et al.,Mmteb: Massive multilingual text embedding benchmark, 2025
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi ´nski, Genta Indra Winata, et al. Mmteb: Massive multilingual text embedding benchmark.arXiv preprint arXiv:2502.13595, 2025
-
[4]
Kenneth Enevoldsen, Márton Kardos, Niklas Muennighoff, and Kristoffer L Nielbo. The scan- dinavian embedding benchmarks: Comprehensive assessment of multilingual and monolingual text embedding.Advances in Neural Information Processing Systems, 37:40336–40358, 2024
2024
-
[5]
What are the best systems? new perspectives on nlp benchmarking.Advances in neural information processing systems, 35:26915–26932, 2022
Pierre Colombo, Nathan Noiry, Ekhine Irurozki, and Stéphan Clémençon. What are the best systems? new perspectives on nlp benchmarking.Advances in neural information processing systems, 35:26915–26932, 2022
2022
-
[6]
V ote’n’rank: Revision of 10 benchmarking with social choice theory
Mark Rofin, Vladislav Mikhailov, Mikhail Florinsky, Andrey Kravchenko, Tatiana Shavrina, Elena Tutubalina, Daniel Karabekyan, and Ekaterina Artemova. V ote’n’rank: Revision of 10 benchmarking with social choice theory. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 670–686, 2023
2023
-
[7]
Generative representational instruction tuning
Niklas Muennighoff, SU Hongjin, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. Generative representational instruction tuning. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[8]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. Llm2vec: Large language models are secretly powerful text encoders.arXiv preprint arXiv:2404.05961, 2024
-
[9]
MTEB: Massive Text Embedding Benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark.arXiv preprint arXiv:2210.07316, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Maintaining mteb: Towards long term usability and reproducibility of embedding benchmarks
Isaac Chung, Imene Kerboua, Marton Kardos, Roman Solomatin, and Kenneth Enevoldsen. Maintaining mteb: Towards long term usability and reproducibility of embedding benchmarks. arXiv preprint arXiv:2506.21182, 2025
-
[11]
Fuzzy multiple attribute decision making methods
Shu-Jen Chen and Ching-Lai Hwang. Fuzzy multiple attribute decision making methods. In Fuzzy multiple attribute decision making: Methods and applications, pages 289–486. Springer, 1992
1992
-
[12]
Multicriteria optimization of civil engineering systems.Faculty of civil engineering, Belgrade, 2(1):5–21, 1998
Serafim Opricovic. Multicriteria optimization of civil engineering systems.Faculty of civil engineering, Belgrade, 2(1):5–21, 1998
1998
-
[13]
L’ingénierie de la décision.Elaboration d’instruments d’aide à la décision
Jean-Pierre Brans, R Nadeau, and M Landry. L’ingénierie de la décision.Elaboration d’instruments d’aide à la décision. La méthode PROMETHEE. In l’Aide à la Décision: Nature, Instruments et Perspectives d’Avenir, pages 183–213, 1982
1982
-
[14]
Determination of objective weights using a new method based on the removal effects of criteria (merec).Symmetry, 13(4):525, 2021
Mehdi Keshavarz-Ghorabaee, Maghsoud Amiri, Edmundas Kazimieras Zavadskas, Zenonas Turskis, and Jurgita Antucheviciene. Determination of objective weights using a new method based on the removal effects of criteria (merec).Symmetry, 13(4):525, 2021
2021
-
[15]
Determining objective weights in multiple criteria problems: The critic method.Computers & operations research, 22(7):763– 770, 1995
Danae Diakoulaki, George Mavrotas, and Lefteris Papayannakis. Determining objective weights in multiple criteria problems: The critic method.Computers & operations research, 22(7):763– 770, 1995
1995
-
[16]
Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks.arXiv preprint arXiv:2511.07025, 2025
-
[17]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Octen-embedding-8b: A fine-tuned multilingual text embedding model, 2025
Octen Team. Octen-embedding-8b: A fine-tuned multilingual text embedding model, 2025
2025
-
[19]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Linq-embed-mistral technical report.arXiv preprint arXiv:2412.03223, 2024
Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy-yong Sohn. Linq-embed-mistral technical report.arXiv preprint arXiv:2412.03223, 2024
-
[22]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wen- zek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 8440–8451, 2020. 11
2020
-
[23]
K., G¨unther, M., Wang, B., Krimmel, M., Wang, F., Mastrapas, G., Koukounas, A., Wang, N., et al
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Andreas Koukounas, Nan Wang, and Han Xiao. jina-embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173, 2024
-
[24]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks.arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[25]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Angle-optimized text embeddings.arXiv preprint arXiv:2309.12871, 2023
Xianming Li and Jing Li. Angle-optimized text embeddings.arXiv preprint arXiv:2309.12871, 2023
-
[27]
Open source strikes bread - new fluffy embeddings model, 2024
Sean Lee, Aamir Shakir, Darius Koenig, and Julius Lipp. Open source strikes bread - new fluffy embeddings model, 2024
2024
-
[28]
Luke Merrick, Danmei Xu, Gaurav Nuti, and Daniel Campos. Arctic-embed: Scalable, efficient, and accurate text embedding models.arXiv preprint arXiv:2405.05374, 2024
-
[29]
NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: Improved techniques for training llms as generalist embedding models.arXiv preprint arXiv:2405.17428, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
EmbeddingGemma: Powerful and Lightweight Text Representations
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, et al. Embeddinggemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Language- agnostic bert sentence embedding
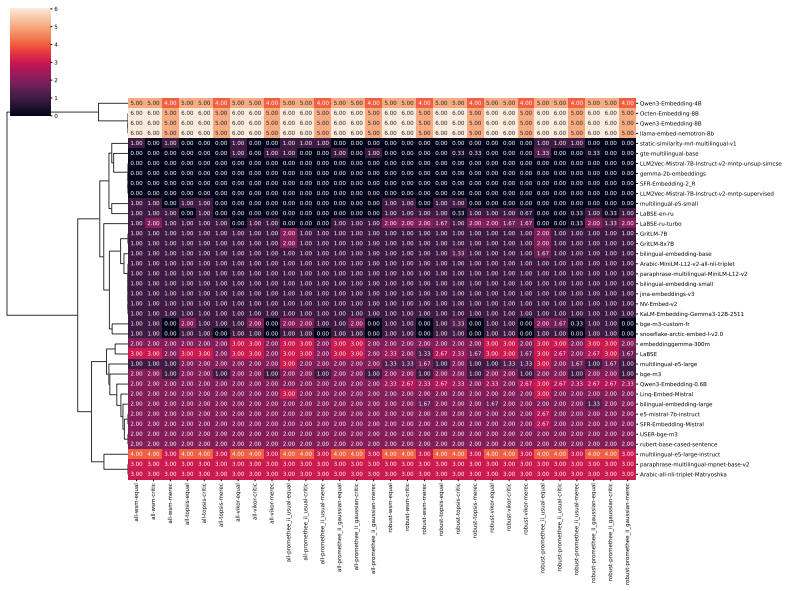
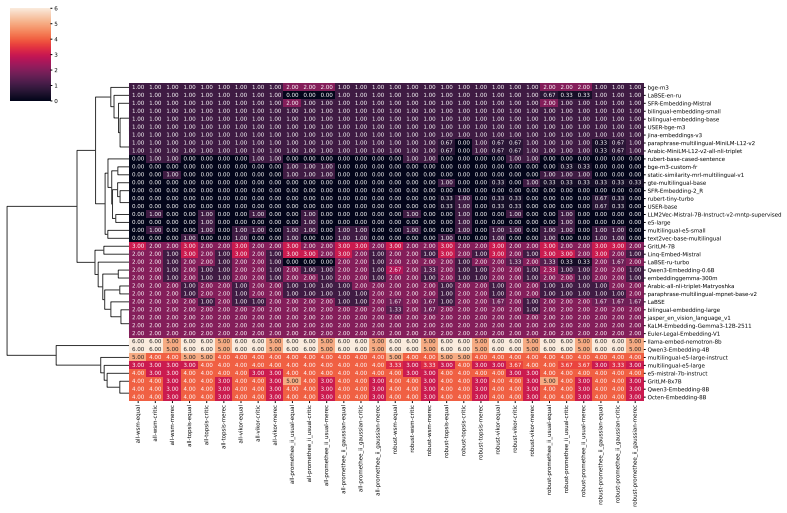
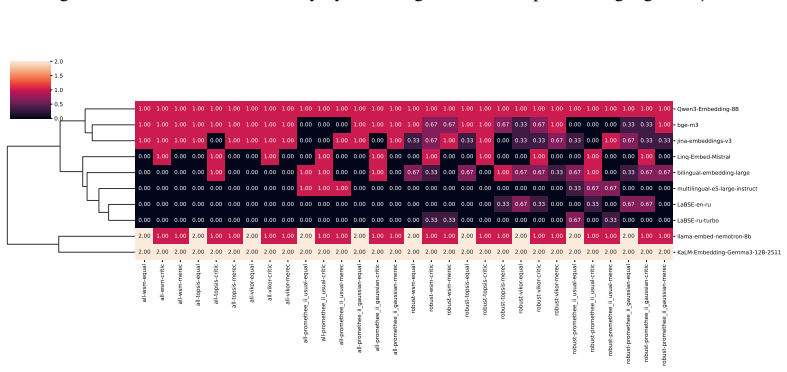
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. Language- agnostic bert sentence embedding. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 878–891, 2022. 12 Table 1: Distribution of datasets by task for ten languages with the largest total number of datas...
2022
-
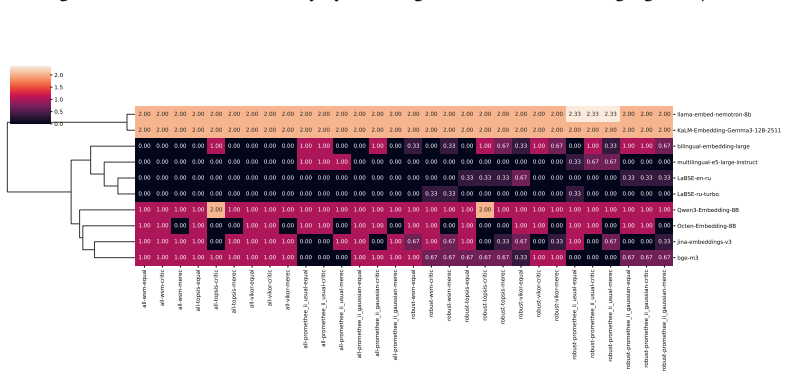
[32]
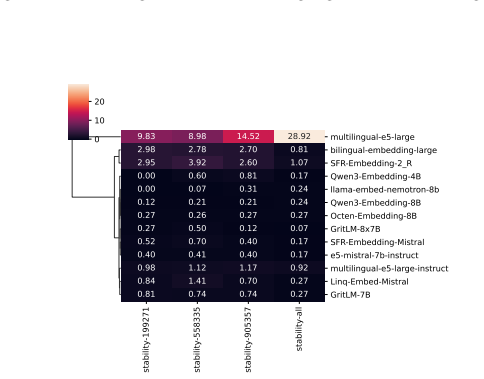
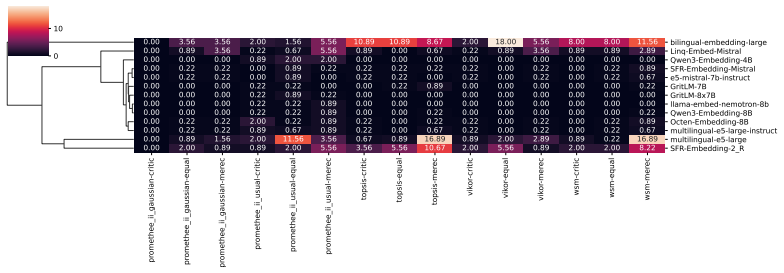
This cluster captures embedding models whose semantic spaces show weak alignment with the evaluated tasks and poor task-agnostic robustness, indicating limited general-purpose applicability. all-wsm-equal all-wsm-critic all-wsm-merec all-topsis-equal all-topsis-critic all-topsis-merec all-vikor-equal all-vikor-critic all-vikor-merec all-promethee_ii_usual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.