Multivariate Distributional Reinforcement Learning Using Sliced Divergences
Pith reviewed 2026-06-28 23:11 UTC · model grok-4.3
The pith
Sliced projections extend one-dimensional divergences to multivariate return distributions while preserving Bellman contractions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sliced Distributional Reinforcement Learning (SDRL) lifts tractable one-dimensional divergences to multivariate return distributions via projections. It proves Bellman contraction for uniform slicing under shared scalar discounting and introduces a maximum-slicing variant that contracts under general dense discount matrices. The method supports Wasserstein, Cramér, and MMD base divergences and characterizes which variants suit the standard single-sample Bellman update.
What carries the argument
Sliced projections that reduce multivariate return distributions to collections of one-dimensional marginals for applying base divergences.
If this is right
- Uniform slicing with scalar discounting guarantees that the distributional Bellman operator is a contraction.
- Maximum slicing extends contraction guarantees to general dense matrix discounting.
- SDRL works with Wasserstein, Cramér, and MMD divergences in the multivariate setting.
- The approach remains compatible with the single-sample Bellman updates standard in distributional RL.
Where Pith is reading between the lines
- SDRL may allow direct modeling of correlated multi-objective or multi-agent returns without collapsing them to expectations.
- The contraction results suggest that SDRL could stabilize learning when returns are vector-valued rather than scalar.
- Extending the slicing idea to learned or adaptive projections might further improve sample efficiency in high-dimensional return spaces.
Load-bearing premise
The sliced projections and chosen base divergences preserve the contraction mapping property of the Bellman operator when lifted to the multivariate case, especially for the maximum-slicing variant under arbitrary dense discount matrices.
What would settle it
A calculation or simulation that shows the maximum-slicing operator fails to be a contraction for a concrete dense discount matrix, or an experiment where SDRL policies diverge from the expected distributional behavior on a multivariate-return task.
Figures

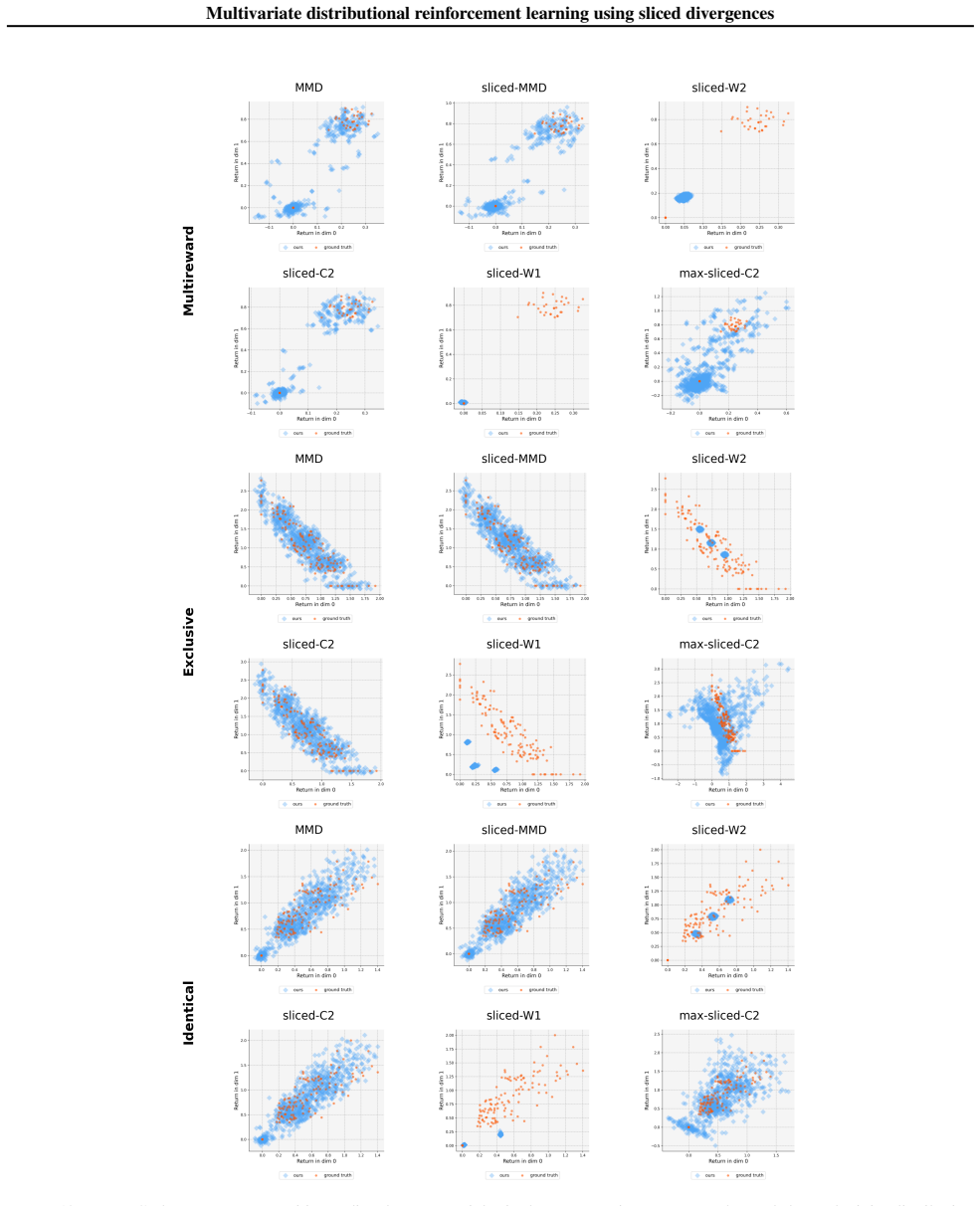
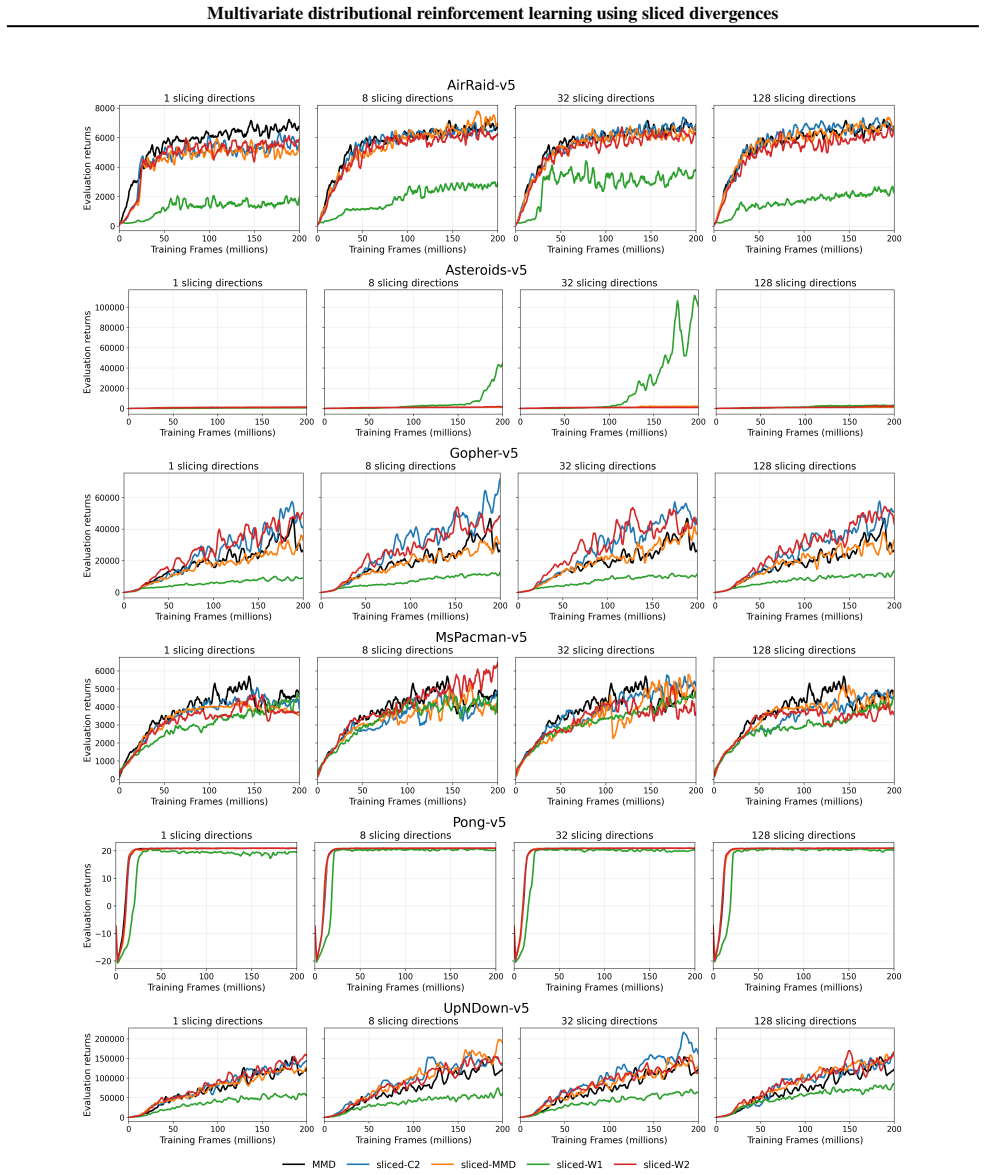
read the original abstract
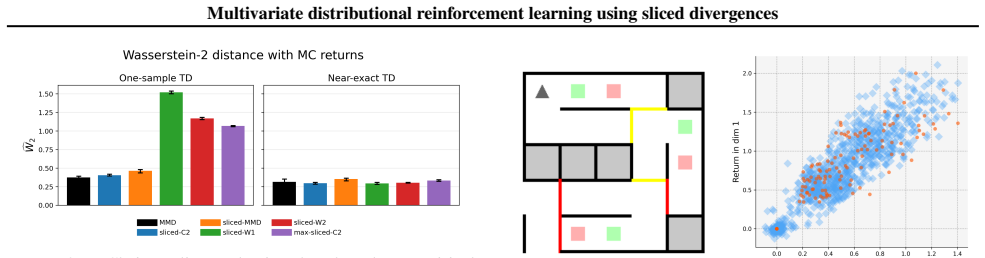
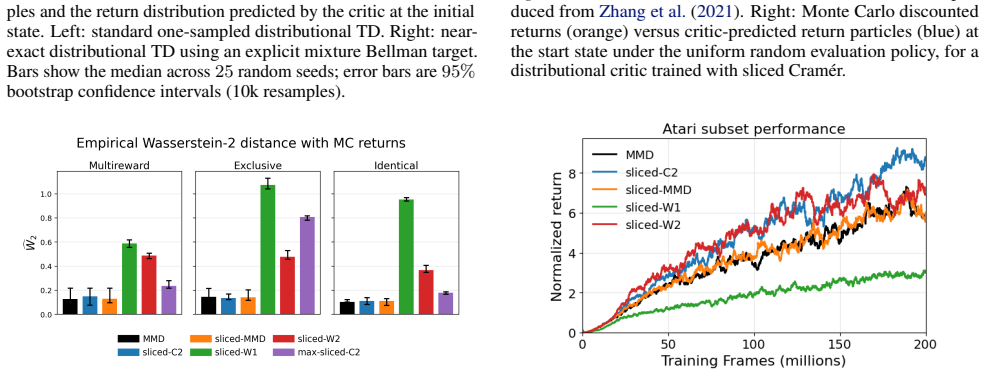
Distributional reinforcement learning (DRL) models the full return distribution rather than expectations, but extending it to multivariate settings remains challenging. Many common metrics do not naturally generalize beyond one dimension or lose computational tractability, and the multivariate case introduces additional difficulties such as general matrix discounting, for which no contraction results are available. We introduce Sliced Distributional Reinforcement Learning (SDRL), which lifts tractable one-dimensional divergences to multivariate return distributions via projections. We prove Bellman contraction for uniform slicing under shared scalar discounting, and introduce a maximum-slicing variant with contraction under general dense discount matrices. SDRL supports a broad class of base divergences; we analyze Wasserstein, Cram\'er, and Maximum Mean Discrepancy (MMD), and characterize which SDRL variants suit the standard single-sample Bellman update used in distributional RL. We evaluate SDRL on a toy chain problem and a gridworld image-based environment as well as a subset of Atari games.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sliced Distributional Reinforcement Learning (SDRL), which lifts one-dimensional divergences (Wasserstein, Cramér, MMD) to multivariate return distributions via projections. It proves Bellman contraction for uniform slicing under shared scalar discounting and for a maximum-slicing variant under general dense discount matrices, analyzes suitability for single-sample Bellman updates, and evaluates on a toy chain, gridworld, and Atari subset.
Significance. If the contraction mappings hold as stated, the work supplies a tractable route to multivariate distributional RL with explicit proofs, which addresses an open gap; the analysis of base divergences and the empirical results on standard environments provide concrete evidence of applicability.
major comments (2)
- [Abstract] Abstract: the claim of contraction for the maximum-slicing variant 'under general dense discount matrices' is load-bearing for the central contribution. The lifting argument for d_max under linear-scaling 1D divergences yields a factor of the operator norm ||Γ||_op; contraction therefore requires ||Γ||_op < 1. The manuscript should state this condition explicitly or show how the proof circumvents it for arbitrary dense Γ (including those with spectral radius ≥1).
- [Proof of maximum-slicing contraction] Proof of maximum-slicing contraction (likely §3 or Theorem on max-slicing): if the argument proceeds by interchanging sup_θ and the Bellman push-forward, the resulting bound must be checked against the precise definition of the sliced distance and the matrix action on the projection directions; any omitted restriction on Γ would undermine the 'general' claim.
minor comments (2)
- [Notation] Notation for the sliced distance d_max should be introduced with an explicit equation before the contraction statements to avoid ambiguity between uniform and maximum variants.
- [Experiments] The experimental section would benefit from reporting the precise discount matrices used in the gridworld and Atari runs so readers can verify that ||Γ||_op < 1 holds in the tested cases.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the contraction properties of the maximum-slicing variant. We address each point below and will make the requested clarifications explicit in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of contraction for the maximum-slicing variant 'under general dense discount matrices' is load-bearing for the central contribution. The lifting argument for d_max under linear-scaling 1D divergences yields a factor of the operator norm ||Γ||_op; contraction therefore requires ||Γ||_op < 1. The manuscript should state this condition explicitly or show how the proof circumvents it for arbitrary dense Γ (including those with spectral radius ≥1).
Authors: We agree that contraction of the maximum-slicing operator requires ||Γ||_op < 1. This is the direct multivariate analogue of the scalar condition γ < 1 and is already necessary for the ordinary Bellman operator to be contractive (even without distributional aspects). The manuscript's claim of 'general dense discount matrices' is intended to mean arbitrary dense Γ that satisfy the standard contraction condition ||Γ||_op < 1; matrices with spectral radius ≥ 1 are excluded because they do not yield a contraction in any case. We will revise the abstract and the statement of the relevant theorem to state the ||Γ||_op < 1 requirement explicitly. revision: yes
-
Referee: [Proof of maximum-slicing contraction] Proof of maximum-slicing contraction (likely §3 or Theorem on max-slicing): if the argument proceeds by interchanging sup_θ and the Bellman push-forward, the resulting bound must be checked against the precise definition of the sliced distance and the matrix action on the projection directions; any omitted restriction on Γ would undermine the 'general' claim.
Authors: The proof interchanges the supremum over directions with the push-forward and then applies the definition of the operator norm to the linear action of Γ on each projected direction. This produces the factor ||Γ||_op in front of the sliced distance, which is < 1 by the standing assumption on Γ. We will insert an explicit verification step in the proof (immediately after the interchange) that confirms the bound holds with respect to the precise definition of the sliced distance, thereby removing any ambiguity about the restriction on Γ. revision: yes
Circularity Check
No circularity: contraction proofs are independent mathematical arguments
full rationale
The paper's derivation chain consists of defining sliced projections to lift 1D divergences and then proving Bellman contraction properties for uniform and maximum-slicing variants under specified discount structures. These steps are presented as direct mathematical results (e.g., contraction under scalar discounting and under general dense matrices for the max variant) without reduction to fitted parameters, self-definitional loops, or load-bearing self-citations. No equations or claims in the provided text equate a 'prediction' or theorem to its own inputs by construction, and the central claims remain externally verifiable via standard contraction mapping arguments on the lifted metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Bellman operator remains a contraction when composed with sliced projections of the chosen base divergences
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=6hZAo6fZvJ. Deshpande, I., Hu, Y .-T., Sun, R., Pyrros, A., Siddiqui, N., Koyejo, S., Zhao, Z., Forsyth, D., and Schwing, A. G. Max-sliced wasserstein distance and its use for gans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10648–10656, 2019. 9 Multivariate distributional...
-
[2]
URL http://jmlr.org/papers/v13/ gretton12a.html. Hessel, M., Modayil, J., Van Hasselt, H., Schaul, T., Os- trovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., and Silver, D. Rainbow: Combining improvements in deep reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. Killingberg, L. and Langseth, H....
-
[3]
Springer, 2008. Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, ˙I., Feng, Y ., Moore, E. W., VanderPlas, J., Laxalde, ...
-
[4]
kernel energy
For return–distribution functionsη i :S × A → P(R d), the supremum lifts S∆p(η1, η2) := sup (s,a) S∆p η1(s, a), η2(s, a) , and MS∆(η1, η2) := sup (s,a) MS∆ η1(s, a), η2(s, a) , are metrics onP(R d)S×A. Proof.(i) is Lemma B.1; (ii) is Lemma B.2; (iii) follows from Lemma B.3 by takingD=S∆ p orD=MS∆. 25 Multivariate distributional reinforcement learning usin...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.