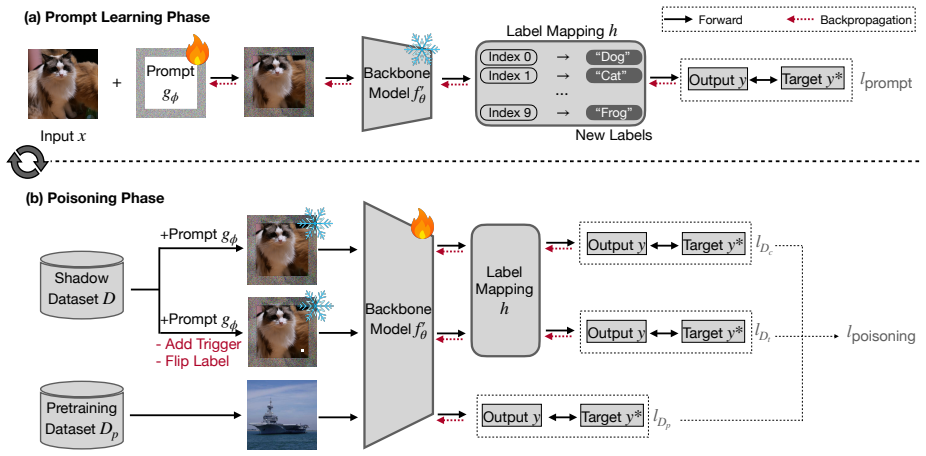
BadBone: Backdoor Attacks Against Backbone Models in Visual Prompt Learning
Pith reviewed 2026-06-28 21:50 UTC · model grok-4.3
The pith
A backdoor embedded in a backbone model via bi-level optimization transfers to any downstream visual prompt learning task without harming clean accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying bi-level optimization to the backbone training objective, BadBone produces a model whose parameters carry a persistent backdoor: when the backdoored backbone is later used for prompt learning on chosen downstream tasks, the trigger causes the desired misbehavior while clean accuracy on both pre-training and downstream data remains intact.
What carries the argument
Bi-level optimization that simultaneously optimizes the backbone for clean performance on the pre-training task while embedding a backdoor that surfaces only after prompt learning is applied on target downstream tasks.
If this is right
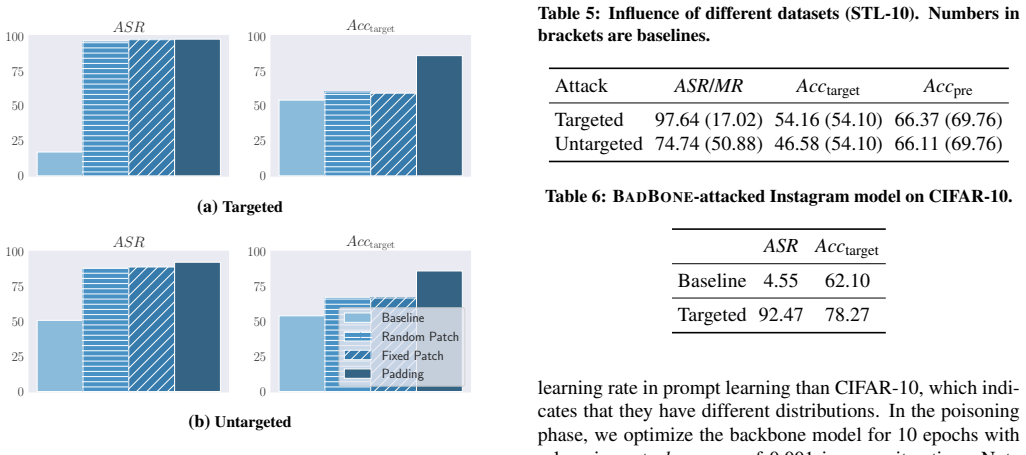
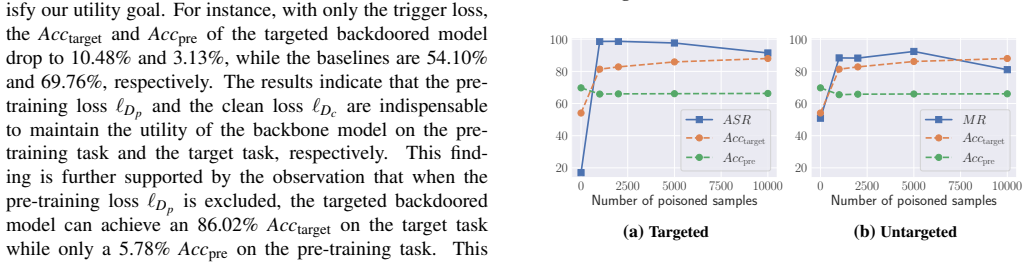
- Targeted backdoors achieve high success rates on chosen downstream tasks after prompt learning.
- Untargeted backdoors also succeed while leaving clean utility unchanged.
- The backdoor persists across the pre-training and downstream phases without degrading reported accuracy.
- Six current model-level defenses, including Neural Cleanse, ABS, MNTD, NAD, CLP, and D-BR, do not remove the embedded trigger.
Where Pith is reading between the lines
- Security of any prompt-learning pipeline now depends on the trustworthiness of the shared backbone rather than only on the prompt-tuning stage.
- Organizations that publish or download backbones may need new verification steps before allowing prompt learning on sensitive tasks.
- If multiple downstream users fine-tune prompts on the same compromised backbone, one planted trigger can affect all of them simultaneously.
Load-bearing premise
An attacker can alter the backbone training process before release and the bi-level optimization will embed a trigger that survives prompt tuning without lowering clean accuracy.
What would settle it
Run prompt learning on the released backdoored backbone for the target downstream tasks and measure whether attack success rate stays near the clean-model baseline.
Figures



read the original abstract
Prompt learning is a new machine learning paradigm that has attracted ample attention due to its simplicity and proven efficacy. Despite its growing adoption, the security vulnerabilities associated with this paradigm remain underexplored. In this work, we take the first step to propose BadBone, a stealthy and adaptive backdoor attack against prompt learning using bi-level optimization. Instead of backdooring the prompt learning process, we aim to compromise a backbone model such that only target downstream tasks employing prompt learning inherit the backdoor vulnerability. Extensive experiments on three different models and three datasets from various domains show that our targeted/untargeted backdoored models achieve high attack performance while maintaining utility on both pre-training and downstream tasks. Moreover, we evaluate our approach against six state-of-the-art model-level defenses, including Neural Cleanse, ABS, MNTD, NAD, CLP, and D-BR. The results demonstrate that these defenses are largely ineffective against our backdoored models and thus leave the effective defense as an important direction for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BadBone, a backdoor attack on backbone models for visual prompt learning. The attack uses bi-level optimization during backbone pre-training to embed a persistent backdoor that is inherited by downstream prompt learners on target tasks, while preserving clean accuracy. Experiments across three models and three datasets demonstrate high attack success for both targeted and untargeted variants; the attack is further shown to evade six model-level defenses (Neural Cleanse, ABS, MNTD, NAD, CLP, D-BR).
Significance. If the experimental results hold, the work is significant for identifying a new attack surface in prompt learning by targeting the shared backbone rather than per-task prompts. The multi-model, multi-dataset evaluation plus defense testing provides concrete evidence of the vulnerability and its resilience. The bi-level optimization approach that maintains utility on both pre-training and downstream stages is a technical strength worth highlighting.
major comments (2)
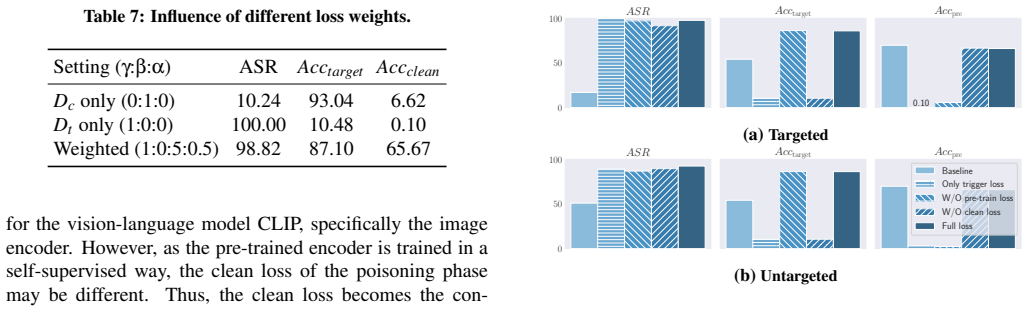
- [§4.2] §4.2 (bi-level optimization formulation): the outer-loop objective that balances attack loss and clean accuracy must be stated explicitly with all weighting coefficients; without these values the claim that the backdoor is 'parameter-free' in effect cannot be verified from the reported results.
- [Table 3] Table 3 (defense evaluation rows): the reported ASR after each defense must be compared against a fixed threshold (e.g., ASR < 10 %) to support the statement that 'these defenses are largely ineffective'; current numbers leave open whether any defense reduces attack success below practical utility.
minor comments (3)
- [§3.1] The threat model paragraph should explicitly state whether the attacker is assumed to know the downstream prompt-learning algorithm or only the backbone architecture.
- [Figure 2] Figure 2 caption: the trigger pattern visualization is referenced but the exact pixel values or generation method are not given in the text; add a short description or supplementary material reference.
- [§5.1] §5.1: the three datasets are named but their domain diversity (e.g., natural vs. medical images) should be quantified with a short table of statistics to justify the 'various domains' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. The comments highlight opportunities to improve clarity in the bi-level optimization details and the defense evaluation. We address each major comment below.
read point-by-point responses
-
Referee: [§4.2] §4.2 (bi-level optimization formulation): the outer-loop objective that balances attack loss and clean accuracy must be stated explicitly with all weighting coefficients; without these values the claim that the backdoor is 'parameter-free' in effect cannot be verified from the reported results.
Authors: We agree that the outer-loop objective requires explicit statement of all weighting coefficients for full reproducibility and verification. The current manuscript describes the bi-level optimization at a high level but does not enumerate the specific coefficients used in experiments. In the revised manuscript we will expand Section 4.2 to present the complete outer-loop objective, including all weighting terms (e.g., the coefficient balancing attack loss against clean accuracy). The phrase 'parameter-free' in the paper refers to the attack not introducing additional trainable parameters beyond standard backbone training; the coefficients are fixed hyperparameters that will now be documented explicitly so readers can verify the reported results. revision: yes
-
Referee: [Table 3] Table 3 (defense evaluation rows): the reported ASR after each defense must be compared against a fixed threshold (e.g., ASR < 10 %) to support the statement that 'these defenses are largely ineffective'; current numbers leave open whether any defense reduces attack success below practical utility.
Authors: We accept that a direct comparison to a practical threshold would strengthen the claim. In the revised manuscript we will augment Table 3 with an additional column or footnote that flags whether each post-defense ASR falls below 10 % and will add a short discussion in the text justifying this threshold as a reasonable indicator of practical attack utility. This change will make the evaluation of defense ineffectiveness more transparent without altering the underlying experimental numbers. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript proposes an empirical backdoor attack (BadBone) via bi-level optimization on backbone pre-training, then validates it with experiments across three models, three datasets, and six defenses. No equations, derivations, predictions, or first-principles results appear that could reduce to inputs by construction. Claims rest on reported attack success rates and clean accuracy preservation, which are external benchmarks rather than self-referential fits or self-citation chains. Self-citations, if present, are not load-bearing for any derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CIFAR.https://www.cs.toronto.edu/~kriz/cifar.ht ml. 2, 5
-
[2]
Exploring Visual Prompts for Adapting Large- scale Models.CoRR abs/2203.17274, 2022
Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Exploring Visual Prompts for Adapting Large- scale Models.CoRR abs/2203.17274, 2022. 1, 2, 5, 6, 12
-
[3]
Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Glober- son, and Alexei A. Efros. Visual Prompting via Image Inpaint- ing. InAnnual Conference on Neural Information Processing Systems (NeurIPS), pages 25005–25017. NeurIPS, 2022. 1, 12
2022
-
[4]
PADA: Example-based Prompt Learning for on-the-fly Adaptation to Unseen Domains.Transactions of the Association for Com- putational Linguistics, 2022
Eyal Ben-David, Nadav Oved, and Roi Reichart. PADA: Example-based Prompt Learning for on-the-fly Adaptation to Unseen Domains.Transactions of the Association for Com- putational Linguistics, 2022. 12
2022
-
[5]
Poisoning and Back- dooring Contrastive Learning
Nicholas Carlini and Andreas Terzis. Poisoning and Back- dooring Contrastive Learning. InInternational Conference on Learning Representations (ICLR), 2022. 2, 12
2022
-
[6]
Understanding and Improving Visual Prompt- ing: A Label-Mapping Perspective.CoRR abs/2211.11635,
Aochuan Chen, Yuguang Yao, Pin-Yu Chen, Yihua Zhang, and Sijia Liu. Understanding and Improving Visual Prompt- ing: A Label-Mapping Perspective.CoRR abs/2211.11635,
-
[7]
DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks
Huili Chen, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks. InInternational Joint Conferences on Artifical Intelligence (IJCAI), pages 4658–
-
[8]
Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Sam- ples
Weixin Chen, Baoyuan Wu, and Haoqian Wang. Effective Backdoor Defense by Exploiting Sensitivity of Poisoned Sam- ples. InAnnual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS, 2022. 11, 12
2022
-
[9]
BadNL: Back- door Attacks Against NLP Models with Semantic-preserving Improvements
Xiaoyi Chen, Ahmed Salem, Michael Backes, Shiqing Ma, Qingni Shen, Zhonghai Wu, and Yang Zhang. BadNL: Back- door Attacks Against NLP Models with Semantic-preserving Improvements. InAnnual Computer Security Applications Conference (ACSAC), pages 554–569. ACSAC, 2021. 12
2021
-
[10]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning.CoRR abs/1712.05526, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
DAPAS : Denoising Autoencoder to Prevent Adversar- ial attack in Semantic Segmentation
Seung Ju Cho, Tae Joon Jun, Byungsoo Oh, and Daeyoung Kim. DAPAS : Denoising Autoencoder to Prevent Adversar- ial attack in Semantic Segmentation. InInternational Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE,
-
[12]
Ng, and Honglak Lee
Adam Coates, Andrew Y . Ng, and Honglak Lee. An Analy- sis of Single-Layer Networks in Unsupervised Feature Learn- ing. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 215–223. JMLR, 2011. 8
2011
-
[13]
Springer Science & Business Media, 2002
Stephan Dempe.Foundations of bilevel programming. Springer Science & Business Media, 2002. 2
2002
-
[14]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 248–255. IEEE, 2009. 5 13
2009
- [15]
-
[16]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representa- tions (ICLR), 2021. 1
2021
-
[17]
PPT: Backdoor Attacks on Pre-trained Models via Poi- soned Prompt Tuning
Wei Du, Yichun Zhao, Boqun Li, Gongshen Liu, and Shilin Wang. PPT: Backdoor Attacks on Pre-trained Models via Poi- soned Prompt Tuning. InInternational Joint Conferences on Artifical Intelligence (IJCAI), pages 680–686. IJCAI, 2022. 1, 5, 12
2022
-
[18]
Elsayed, Ian J
Gamaleldin F. Elsayed, Ian J. Goodfellow, and Jascha Sohl- Dickstein. Adversarial Reprogramming of Neural Networks. InInternational Conference on Learning Representations (ICLR), 2019. 1, 6, 12
2019
-
[19]
STRIP: A Defence Against Trojan Attacks on Deep Neural Networks
Yansong Gao, Change Xu, Derui Wang, Shiping Chen, Damith C Ranasinghe, and Surya Nepal. STRIP: A Defence Against Trojan Attacks on Deep Neural Networks. InAnnual Computer Security Applications Conference (ACSAC), pages 113–125. ACM, 2019. 12
2019
-
[20]
BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Grag. Bad- nets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain.CoRR abs/1708.06733, 2017. 1, 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Wenbo Guo, Lun Wang, Xinyu Xing, Min Du, and Dawn Song. TABOR: A Highly Accurate Approach to Inspect- ing and Restoring Trojan Backdoors in AI Systems.CoRR abs/1908.01763, 2019. 12
-
[22]
W ARP: Word-level Adversarial ReProgramming
Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. W ARP: Word-level Adversarial ReProgramming. InAn- nual Meeting of the Association for Computational Linguistics and International Joint Conference on Natural Language Pro- cessing (ACL/IJCNLP), pages 4921–4933. ACL, 2021. 12
2021
-
[23]
PTR: Prompt Tuning with Rules for Text Classification
Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. PTR: Prompt Tuning with Rules for Text Classification. AI Open, 2022. 1, 12
2022
-
[24]
SPECTRE: Defending Against Backdoor Attacks Using Robust Statistics
Jonathan Hayase, Weihao Kong, Raghav Somani, and Se- woong Oh. SPECTRE: Defending Against Backdoor Attacks Using Robust Statistics. InInternational Conference on Ma- chine Learning (ICML). JMLR, 2021. 12
2021
-
[25]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. InIEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 770–778. IEEE, 2016. 2, 5
2016
-
[26]
Eurosat: A Novel Dataset and Deep Learn- ing Benchmark for Land Use and Land Cover Classification
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A Novel Dataset and Deep Learn- ing Benchmark for Land Use and Land Cover Classification. IEEE Journal of Selected Topics in Applied Earth Observa- tions and Remote Sensing, 2019. 5
2019
-
[27]
Prompt Backdoors in Visual Prompt Learning
Hai Huang, Zhengyu Zhao, Michael Backes, Yun Shen, and Yang Zhang. Prompt Backdoors in Visual Prompt Learning. CoRR abs/2310.07632, 2023. 1, 5, 12
-
[28]
Diversity- Aware Meta Visual Prompting
Qidong Huang, Xiaoyi Dong, Dongdong Chen, Weiming Zhang, Feifei Wang, Gang Hua, and Nenghai Yu. Diversity- Aware Meta Visual Prompting. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). IEEE, 2023. 12
2023
-
[29]
Xijie Huang, Moustafa Alzantot, and Mani B. Srivastava. NeuronInspect: Detecting Backdoors in Neural Networks via Output Explanations.CoRR abs/1911.07399, 2019. 12
-
[30]
BadEn- coder: Backdoor Attacks to Pre-trained Encoders in Self- Supervised Learning
Jinyuan Jia, Yupei Liu, and Neil Zhenqiang Gong. BadEn- coder: Backdoor Attacks to Pre-trained Encoders in Self- Supervised Learning. InIEEE Symposium on Security and Privacy (S&P). IEEE, 2022. 2, 3, 5, 11, 12
2022
-
[31]
Belongie, Bharath Hariharan, and Ser-Nam Lim
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge J. Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual Prompt Tuning. InEuropean Conference on Computer Vision (ECCV), pages 709–727. Springer, 2022. 1, 5, 12
2022
-
[32]
Xu, Jun Araki, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. How Can We Know What Language Models Know.Transac- tions of the Association for Computational Linguistics, 2020. 12
2020
-
[33]
Virapat Kieuvongngam, Bowen Tan, and Yiming Niu. Auto- matic Text Summarization of COVID-19 Medical Research Articles using BERT and GPT-2.CoRR abs/2006.01997,
-
[34]
Minsu Kim, Hyung-Il Kim, and Yong Man Ro. Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition.CoRR abs/2302.08102, 2023. 12
-
[35]
Big Transfer (BiT): General Visual Representation Learning
Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big Transfer (BiT): General Visual Representation Learning. InEuropean Conference on Computer Vision (ECCV), pages 491–507. Springer, 2020. 5
2020
-
[36]
Gopi Krishnamurthy, Francisco Calderon Rodriguez, Shreyas Subramanian, and Sujitha Martin. Foundational vision models and visual prompt engineering for autonomous driving appli- cations.https://aws.amazon.com/blogs/machine- learning/foundational-vision-models-and-visual- prompt- engineering- for- autonomous- driving- applications/, 2023. 1
2023
-
[37]
Defending Deep Neural Networks against Back- door Attack by Using De-trigger Autoencoder.IEEE Access,
Hyun Kwon. Defending Deep Neural Networks against Back- door Attack by Using De-trigger Autoencoder.IEEE Access,
-
[38]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The Power of Scale for Parameter-Efficient Prompt Tuning. InConfer- ence on Empirical Methods in Natural Language Processing (EMNLP), pages 3045–3059. ACL, 2021. 12
2021
-
[39]
Rethinking the Hyperparameters for Fine-tuning
Hao Li, Pratik Chaudhari, Hao Yang, Michael Lam, Avinash Ravichandran, Rahul Bhotika, and Stefano Soatto. Rethinking the Hyperparameters for Fine-tuning. InInternational Confer- ence on Learning Representations (ICLR), 2020. 1
2020
-
[40]
Prefix-Tuning: Optimiz- ing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-Tuning: Optimiz- ing Continuous Prompts for Generation. InAnnual Meeting of the Association for Computational Linguistics and Inter- national Joint Conference on Natural Language Processing (ACL/IJCNLP), pages 4582–4597. ACL, 2021. 1, 12
2021
-
[41]
Neural Attention Distillation: Erasing Back- door Triggers from Deep Neural Networks
Yige Li, Xixiang Lyu, Nodens Koren, Lingjuan Lyu, Bo Li, and Xingjun Ma. Neural Attention Distillation: Erasing Back- door Triggers from Deep Neural Networks. InInternational Conference on Learning Representations (ICLR), 2021. 11, 12
2021
-
[42]
Invisible Backdoor Attack with Sample- Specific Triggers
Yuezun Li, Yiming Li, Baoyuan Wu, Longkang Li, Ran He, and Siwei Lyu. Invisible Backdoor Attack with Sample- Specific Triggers. InIEEE International Conference on Com- puter Vision (ICCV), pages 16443–16452. IEEE, 2021. 12 14
2021
-
[43]
VulnerGAN: A Backdoor Attack Through Vulner- ability Amplification Against Machine Learning-based Net- work Intrusion Detection Systems.Science China Information Sciences, 2022
Guangrui Liu, Weizhe Zhang, Xinjie Li, Kaisheng Fan, and Shui Yu. VulnerGAN: A Backdoor Attack Through Vulner- ability Amplification Against Machine Learning-based Net- work Intrusion Detection Systems.Science China Information Sciences, 2022. 3
2022
-
[44]
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natu- ral Language Processing.ACM Computing Surveys, 2023
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hi- roaki Hayashi, and Graham Neubig. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natu- ral Language Processing.ACM Computing Surveys, 2023. 1, 12
2023
-
[45]
Explicit Visual Prompting for Low-Level Structure Segmen- tations
Weihuang Liu, Xi Shen, Chi-Man Pun, and Xiaodong Cun. Explicit Visual Prompting for Low-Level Structure Segmen- tations. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023. 1, 12
2023
-
[46]
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. GPT Understands, Too. CoRR abs/2103.10385, 2021. 12
-
[47]
ABS: Scanning Neural Networks for Back-Doors by Artificial Brain Stimulation
Yingqi Liu, Wen-Chuan Lee, Guanhong Tao, Shiqing Ma, Yousra Aafer, and Xiangyu Zhang. ABS: Scanning Neural Networks for Back-Doors by Artificial Brain Stimulation. In ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 1265–1282. ACM, 2019. 11, 12
2019
-
[48]
Trojaning Attack on Neural Networks
Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning Attack on Neural Networks. InNetwork and Distributed System Se- curity Symposium (NDSS). Internet Society, 2018. 12
2018
-
[49]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic Gradient Descent with Warm Restarts. InInternational Conference on Learning Representations (ICLR), 2017. 6
2017
- [50]
-
[51]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading Digits in Natural Im- ages with Unsupervised Feature Learning. InAnnual Con- ference on Neural Information Processing Systems (NIPS). NIPS, 2011. 5
2011
-
[52]
A Survey on Transfer Learning.IEEE Transactions on Knowledge and Data En- gineering, 2009
Sinno Jialin Pan and Qiang Yang. A Survey on Transfer Learning.IEEE Transactions on Knowledge and Data En- gineering, 2009. 8
2009
-
[53]
StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery.CoRR abs/2103.17249, 2021
Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery.CoRR abs/2103.17249, 2021. 1
-
[54]
Learning How to Ask: Querying LMs with Mixtures of Soft Prompts
Guanghui Qin and Jason Eisner. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. InConfer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pages 5203–5212. ACL, 2021. 1
2021
-
[55]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021. 1
2021
-
[56]
Hidden Trigger Backdoor Attacks
Aniruddha Saha, Akshayvarun Subramanya, and Hamed Pir- siavash. Hidden Trigger Backdoor Attacks. InAAAI Con- ference on Artificial Intelligence (AAAI), pages 11957–11965. AAAI, 2020. 12
2020
-
[57]
Backdoor Attacks on Self- Supervised Learning
Aniruddha Saha, Ajinkya Tejankar, Soroush Abbasi Kooh- payegani, and Hamed Pirsiavash. Backdoor Attacks on Self- Supervised Learning. InIEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 13327–13336. IEEE, 2022. 2, 3
2022
-
[58]
Ahmed Salem, Michael Backes, and Yang Zhang. Don’t Trig- ger Me! A Triggerless Backdoor Attack Against Deep Neural Networks.CoRR abs/2010.03282, 2020. 12
-
[59]
Dynamic Backdoor Attacks Against Machine Learning Models
Ahmed Salem, Rui Wen, Michael Backes, Shiqing Ma, and Yang Zhang. Dynamic Backdoor Attacks Against Machine Learning Models. InIEEE European Symposium on Security and Privacy (Euro S&P), pages 703–718. IEEE, 2022. 11, 12
2022
-
[60]
You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion.CoRR abs/2007.02220, 2020
Roei Schuster, Congzheng Song, Eran Tromer, and Vitaly Shmatikov. You Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion.CoRR abs/2007.02220, 2020. 12
-
[61]
Backdoor Pre-trained Models Can Transfer to All
Lujia Shen, Shouling Ji, Xuhong Zhang, Jinfeng Li, Jing Chen, Jie Shi, Chengfang Fang, Jianwei Yin, and Ting Wang. Backdoor Pre-trained Models Can Transfer to All. InACM SIGSAC Conference on Computer and Communications Se- curity (CCS), pages 3141–3158. ACM, 2021. 2, 3, 5, 12
2021
-
[62]
Machine Learning Models that Remember Too Much
Congzheng Song, Thomas Ristenpart, and Vitaly Shmatikov. Machine Learning Models that Remember Too Much. InACM SIGSAC Conference on Computer and Communications Secu- rity (CCS), pages 587–601. ACM, 2017. 2
2017
-
[63]
Spectral Sig- natures in Backdoor Attacks
Brandon Tran, Jerry Li, and Aleksander Madry. Spectral Sig- natures in Backdoor Attacks. InAnnual Conference on Neu- ral Information Processing Systems (NeurIPS), pages 8011–
-
[64]
Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, and Felix Hill. Multimodal Few-Shot Learning with Frozen Language Models. InAnnual Confer- ence on Neural Information Processing Systems (NeurIPS), pages 200–212. NeurIPS, 2021. 1, 12
2021
-
[65]
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y . Zhao. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Net- works. InIEEE Symposium on Security and Privacy (S&P), pages 707–723. IEEE, 2019. 11, 12
2019
-
[66]
Dual Modal- ity Prompt Tuning for Vision-Language Pre-Trained Model
Yinghui Xing, Qirui Wu, De Cheng, Shizhou Zhang, Guo- qiang Liang, Peng Wang, and Yanning Zhang. Dual Modal- ity Prompt Tuning for Vision-Language Pre-Trained Model. CoRR abs/2208.08340, 2023. 12
-
[67]
Gunter, and Bo Li
Xiaojun Xu, Qi Wang, Huichen Li, Nikita Borisov, Carl A. Gunter, and Bo Li. Detecting AI Trojans Using Meta Neural Analysis. InIEEE Symposium on Security and Privacy (S&P). IEEE, 2021. 11, 12
2021
-
[68]
Ziqing Yang, Zeyang Sha, Michael Backes, and Yang Zhang. From Visual Prompt Learning to Zero-Shot Transfer: Map- ping Is All You Need.CoRR abs/2303.05266, 2023. 1, 12
-
[69]
Yuanshun Yao, Huiying Li, Haitao Zheng, and Ben Y . Zhao. Latent Backdoor Attacks on Deep Neural Networks. InACM SIGSAC Conference on Computer and Communications Secu- rity (CCS), pages 2041–2055. ACM, 2019. 12
2041
-
[70]
BARTScore: Evaluating Generated Text as Text Generation
Weizhe Yuan, Graham Neubig, and Pengfei Liu. BARTScore: Evaluating Generated Text as Text Generation. InAn- nual Conference on Neural Information Processing Systems (NeurIPS), pages 27263–27277. NeurIPS, 2021. 12
2021
-
[71]
Unified Vision and Language Prompt Learning.CoRR abs/2210.07225, 2022
Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Unified Vision and Language Prompt Learning.CoRR abs/2210.07225, 2022. 1, 12 15
-
[72]
Morley Mao, and Ruoxi Jia
Yi Zeng, Won Park, Z. Morley Mao, and Ruoxi Jia. Rethink- ing the Backdoor Attacks’ Triggers: A Frequency Perspec- tive. InIEEE International Conference on Computer Vision (ICCV), pages 16453–16461. IEEE, 2021. 12
2021
-
[73]
Age Progres- sion/Regression by Conditional Adversarial Autoencoder
Zhifei Zhang, Yang Song, and Hairong Qi. Age Progres- sion/Regression by Conditional Adversarial Autoencoder. In IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 4352–4360. IEEE, 2017. 8
2017
-
[74]
Clean-Label Backdoor Attacks on Video Recognition Models
Shihao Zhao, Xingjun Ma, Xiang Zheng, James Bailey, Jingjing Chen, and Yu-Gang Jiang. Clean-Label Backdoor Attacks on Video Recognition Models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 14443–144528. IEEE, 2020. 12
2020
-
[75]
Data- Free Backdoor Removal Based on Channel Lipschitzness
Runkai Zheng, Rongjun Tang, Jianze Li, and Li Liu. Data- Free Backdoor Removal Based on Channel Lipschitzness. InEuropean Conference on Computer Vision (ECCV), pages 175–191. Springer, 2022. 11, 12 16
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.