Neither Replacement nor Panacea: Comparing LLM-Based Conversational and Graphical Decision Support in Industrial Tasks
Pith reviewed 2026-06-28 20:36 UTC · model grok-4.3
The pith
LLM chat reduces workload for simple factory decisions but not complex ones
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
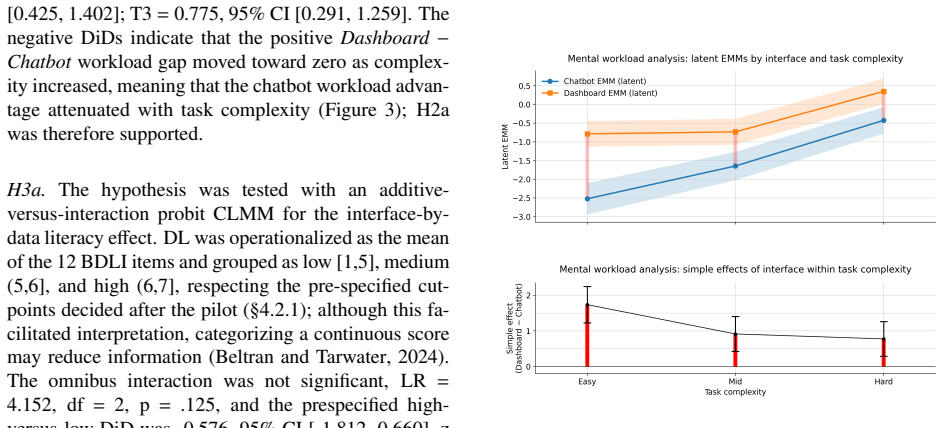
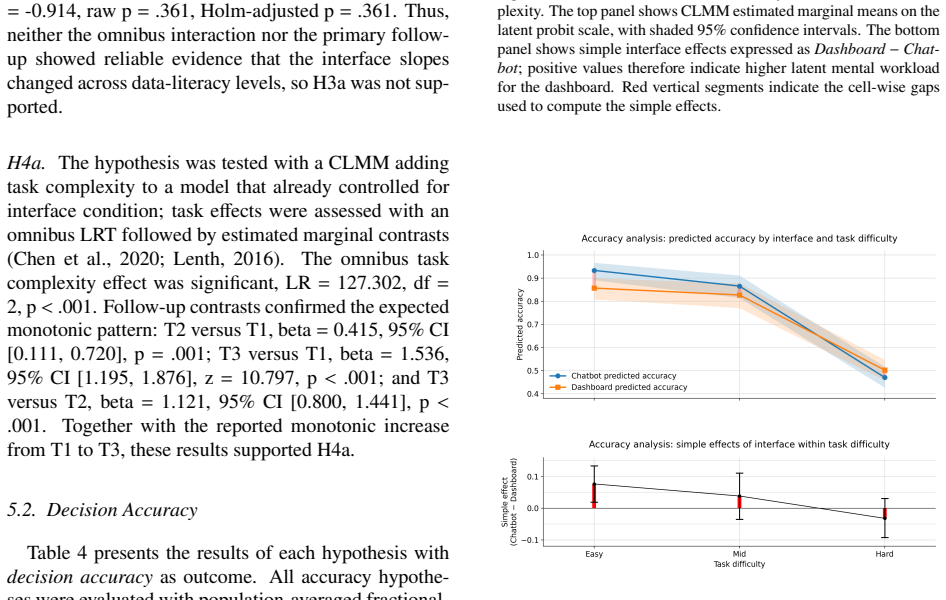
In a mixed factorial experiment with 134 industrial decision-makers, the LLM-based conversational user interface reduced perceived mental workload overall and supported faster completion in less demanding tasks compared to the dashboard, but both advantages diminished as task complexity increased. Neither interface produced a consistent overall advantage in decision accuracy, the conversational interface was not preferred as a sole basis for subsequent decisions, and data literacy did not reliably moderate interface effects.
What carries the argument
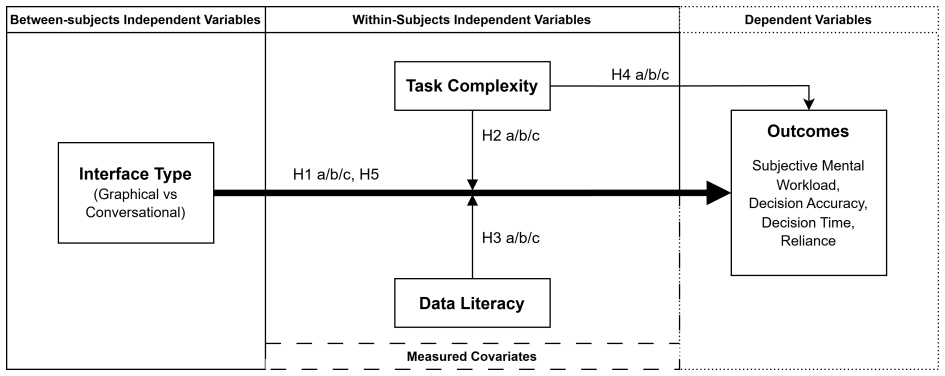
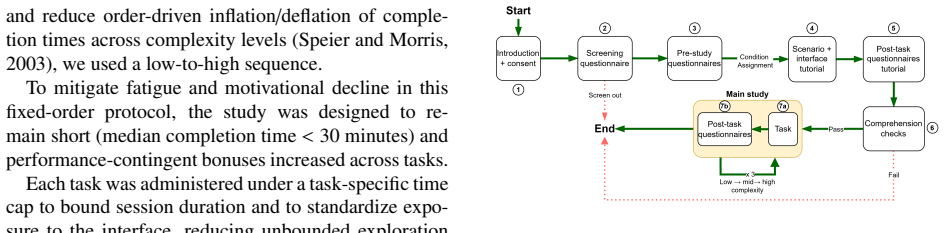
A 2x3 mixed factorial experiment comparing an LLM-based conversational user interface against a graphical dashboard across three tasks of increasing complexity, measuring mental workload, decision accuracy, completion time, and intended reliance.
If this is right
- Conversational interfaces reduce information-access effort in routine industrial tasks.
- Persistent visual representations continue to benefit complex decisions.
- LLM-based conversational agents offer conditional rather than universal benefits.
- Neither interface type produces a consistent accuracy advantage.
- Data literacy does not moderate the effects of interface type.
Where Pith is reading between the lines
- Industrial systems might combine both interface types so users can switch based on task demands.
- The conditional pattern could appear in other data-heavy fields such as logistics if similar complexity levels exist.
- Deployment tests inside operating factories could check whether the controlled-task results hold under real time pressure.
Load-bearing premise
The three tasks of increasing complexity in the 2x3 design validly represent the information-processing demands and decision stakes encountered in actual manufacturing settings.
What would settle it
A study with actual manufacturing operators on live production data that found the conversational interface sustained its workload and speed advantages even on the most complex tasks would challenge the claim of only conditional benefits.
Figures
read the original abstract
Managers in manufacturing settings rely on digital interfaces to interpret operational data for decision-making, but growing data volume and complexity can make relevant insights difficult to identify efficiently. While dashboards remain dominant in industrial contexts, Large Language Model (LLM)-based conversational agents (CAs), accessed through conversational user interfaces (CUIs), may provide more direct access to such data. However, their effectiveness may depend on the information-processing demands of the task. This study compares an LLM-based CA delivered through a CUI with a dashboard in a manufacturing decision-support scenario. In a mixed factorial experiment with a 2x3 design, 134 industrial decision-makers were assigned to one interface condition and completed three tasks of increasing complexity. We examined perceived Mental Workload (MWL), decision accuracy, completion time, and intended reliance, and tested self-reported data literacy as a moderator. Results showed that the CUI reduced perceived MWL overall and supported faster completion in less demanding tasks, but both advantages diminished as task complexity increased. Neither interface produced a consistent overall advantage in decision accuracy, and the CUI was not preferred as a sole basis for subsequent decisions. Furthermore, data literacy did not reliably moderate interface effects. These findings indicate that conversational interaction offers conditional rather than universal benefits for industrial decision support. LLM-based CAs may reduce information-access effort, whereas complex decisions continue to benefit from persistent, inspectable visual representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a 2×3 mixed factorial experiment with 134 industrial decision-makers randomly assigned to either an LLM-based conversational user interface (CUI) or a traditional dashboard condition. Participants completed three manufacturing decision-support tasks described as increasing in complexity; dependent measures were perceived mental workload (MWL), decision accuracy, completion time, and intended reliance, with self-reported data literacy tested as a moderator. The central claim is that CUI advantages in MWL and speed are conditional on task complexity (diminishing as complexity rises), that neither interface shows a consistent accuracy advantage, and that complex decisions continue to benefit from persistent visual representations rather than conversational interaction alone.
Significance. If the experimental tasks validly capture the information-processing demands and decision stakes of actual manufacturing settings, the study supplies empirical evidence from domain practitioners that LLM-based conversational agents provide conditional rather than universal benefits for industrial decision support. This contributes to the HCI and decision-support literature by identifying boundary conditions on CUI effectiveness and by highlighting the continued value of inspectable visual interfaces for higher-complexity tasks. The use of actual industrial decision-makers as participants strengthens external validity relative to student samples common in the field.
major comments (1)
- [Methods] Methods section (task description and design): the three tasks are characterized only as “of increasing complexity” with no reported operationalization of complexity dimensions, pilot validation, or explicit mapping to real manufacturing decision stakes and information-processing loads. Because the central claim—that CUI benefits are conditional and diminish with complexity—depends on these tasks serving as valid proxies, the absence of such validation is load-bearing for the “conditional rather than universal” conclusion.
minor comments (2)
- [Abstract] Abstract: reports no statistical details (effect sizes, p-values, or confidence intervals) for the key MWL, time, and accuracy findings, making it difficult to assess the magnitude and reliability of the reported patterns without reading the full results section.
- [Results] Results section: the description of the data-literacy moderator analysis should clarify whether the null finding reflects absence of an effect or insufficient power, given the sample size of 134.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights an important aspect of methodological transparency. We address the single major comment below and will revise the manuscript to incorporate additional detail.
read point-by-point responses
-
Referee: [Methods] Methods section (task description and design): the three tasks are characterized only as “of increasing complexity” with no reported operationalization of complexity dimensions, pilot validation, or explicit mapping to real manufacturing decision stakes and information-processing loads. Because the central claim—that CUI benefits are conditional and diminish with complexity—depends on these tasks serving as valid proxies, the absence of such validation is load-bearing for the “conditional rather than universal” conclusion.
Authors: We agree that the current manuscript provides insufficient detail on how task complexity was operationalized, which weakens the interpretability of the conditional-effects claim. In the revised version we will expand the Methods section with: (1) the specific dimensions used to scale complexity (number of interdependent variables, volume of data to integrate, and decision consequences), (2) a table mapping each task to representative manufacturing scenarios drawn from industry input, and (3) a brief description of the pilot testing conducted with five industrial practitioners to confirm perceived difficulty ordering. These additions will directly substantiate the claim that CUI advantages diminish with rising complexity without altering the reported results. revision: yes
Circularity Check
No circularity: purely empirical experiment with no derivation chain
full rationale
The paper reports results from a 2x3 mixed factorial experiment with 134 participants on three tasks of increasing complexity, measuring MWL, accuracy, time, and reliance. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described methods. All claims rest on direct experimental observations rather than any reduction to prior fitted values or definitional equivalences. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Visualization and Computer Graphics 20, 1963–1972
A Principled Way of Assessing Visualization Literacy. IEEE Transactions on Visualization and Computer Graphics 20, 1963–1972. URL:http: //ieeexplore.ieee.org/document/6875906/, doi:doi:10.1109/tvcg.2014.2346984. 24 Casner, S., Gore, B., 2010. Measuring and Evaluating Workload: A Primer. Technical Report. Cezar, B.G.d.S., Maçada, A.C.G., 2023. Cognitive Ov...
-
[2]
Multivariate Behav- ioral Research 34, 315–346
The Problem of Units and the Cir- cumstance for POMP. Multivariate Behav- ioral Research 34, 315–346. URL:https: //doi.org/10.1207/S15327906MBR3403_2, doi:doi:10.1207/S15327906MBR3403_2. _eprint: https://doi.org/10.1207/S15327906MBR3403_2. Crescenzi, A., Capra, R., Choi, B., Li, Y ., 2021. Adaptation in Information Search and Decision- Making under Time C...
-
[3]
Dietvorst, B.J., Simmons, J.P., Massey, C., 2018
URL:https://www.sciencedirect.com/ science/article/pii/S0925527318303372, doi:doi:10.1016/j.ijpe.2018.08.019. Dietvorst, B.J., Simmons, J.P., Massey, C., 2018. Overcoming Algorithm Aversion: People Will Use Imperfect Algorithms If They Can (Even Slightly) Modify Them. Management Science 64, 1155–1170. URL:https://pubsonline. informs.org/doi/10.1287/mnsc.2...
-
[4]
Chat or Tap? – Comparing Chatbots with ‘Classic’ Graphical User Interfaces for Mobile Interaction with Autonomous Mobility-on-Demand Systems, in: Proceedings of the 23rd International Conference on Mobile Human-Computer Inter- action, Association for Computing Machinery, New York, NY , USA. pp. 1–13. URL:https:// 25 dl.acm.org/doi/10.1145/3447526.3472036,...
-
[5]
doi:doi:10.1007/s11121-014-0495-x. Hertzum, M., 2021. Reference values and sub- scale patterns for the task load index (TLX): a meta-analytic review. Ergonomics 64, 869–
-
[6]
URL:https://www.tandfonline.com/ doi/full/10.1080/00140139.2021.1876927, doi:doi:10.1080/00140139.2021.1876927. Hettiachchi, D., Sarsenbayeva, Z., Allison, F., Van Berkel, N., Dingler, T., Marini, G., Kostakos, V ., Goncalves, J., 2020. "Hi! I am the Crowd Tasker" Crowdsourcing through Digital V oice Assistants, in: Proceedings of the 2020 CHI Conference ...
-
[7]
1994, Atomic Data and Nuclear Data Tables, 56, 231, doi: 10.1006/adnd.1994.1007
URL:https://www.sciencedirect.com/ science/article/pii/S107158198471007X, doi:doi:10.1006/ijhc.1994.1007. Lee, J.D., See, K.A., 2004. Trust in Automation: Designing for Appropriate Reliance. Human Fac- tors 46, 50–80. URL:https://journals. sagepub.com/action/showAbstract, doi:doi:10.1518/hfes.46.1.50_30392. Lee, S., Kim, S.H., Kwon, B.C., 2017. VLAT: De- ...
-
[8]
Madhavan, P., Wiegmann, D.A., 2007
URL:https://dl.acm.org/doi/10.1145/ 3653708, doi:doi:10.1145/3653708. Madhavan, P., Wiegmann, D.A., 2007. Similari- ties and differences between human–human and hu- man–automation trust: an integrative review. The- oretical Issues in Ergonomics Science 8, 277–301. doi:doi:10.1080/14639220500337708. Magezi, D.A., 2015. Linear mixed-effects models for withi...
-
[9]
Bimanual robot-assisted dressing: A spherical coordinate-based strategy for tight-fitting garments
A simple upgrade or a gradual re- tirement? A critical commentary on NASA- TLX. Ergonomics 0, 1–7. URL:https: //doi.org/10.1080/00140139.2025.2596331, doi:doi:10.1080/00140139.2025.2596331. _eprint: https://doi.org/10.1080/00140139.2025.2596331. Muir, B.M., 1987. Trust between humans and ma- chines, and the design of decision aids. Interna- tional Journal...
-
[10]
Journal of Cleaner Production 391, 136184
Decision-making in the context of Industry 4.0: Evidence from the textile and clothing indus- try. Journal of Cleaner Production 391, 136184. URL:https://www.sciencedirect.com/ science/article/pii/S0959652623003426, doi:doi:10.1016/j.jclepro.2023.136184. Nuamah, J.K., Seong, Y ., Jiang, S., Park, E., Mountjoy, D., 2020. Evaluating effective- ness of infor...
-
[11]
Pörtner, L., Riel, A., Klaassen, V ., Sezgin, D., Kievits, Y ., 2024
URL:https://www.jstor.org/stable/ 2529712, doi:doi:10.2307/2529712. Pörtner, L., Riel, A., Klaassen, V ., Sezgin, D., Kievits, Y ., 2024. Data Literacy Assessment - Measuring Data Literacy Competencies to Leverage Data-Driven Organizations. Procedia CIRP 128, 78–
-
[12]
URL:https://www.sciencedirect.com/ science/article/pii/S2212827124006620, doi:doi:10.1016/j.procir.2024.07.047. Roetzel, P.G., 2019. Information overload in the information age: a review of the literature from business administration, business psychol- ogy, and related disciplines with a bibliometric approach and framework development. Busi- ness Research...
-
[13]
Speier, C., Valacich, J.S., Vessey, I., 1999
URL:https://www.jstor.org/stable/ 30036539, doi:doi:10.2307/30036539. Speier, C., Valacich, J.S., Vessey, I., 1999. The Influence of Task Interruption on Individual Decision Making: An Information Overload Perspective. Decision Sciences 30, 337–360. URL:https://onlinelibrary.wiley.com/ doi/10.1111/j.1540-5915.1999.tb01613.x, doi:doi:10.1111/j.1540-5915.19...
-
[14]
Yigitbasioglu, O.M., Velcu, O., 2012
doi:doi:10.1007/978-3-319-39907-2_45. Yigitbasioglu, O.M., Velcu, O., 2012. A review of dashboards in performance management: Im- plications for design and research. International Journal of Accounting Information Systems 13, 41–
-
[15]
Young, M.S., Brookhuis, K.A., Wickens, C.D., Han- cock, P.A., 2015
URL:https://www.sciencedirect.com/ science/article/pii/S1467089511000443, doi:doi:10.1016/j.accinf.2011.08.002. Young, M.S., Brookhuis, K.A., Wickens, C.D., Han- cock, P.A., 2015. State of science: mental workload in ergonomics. Ergonomics 58, 1–17. URL:https: //doi.org/10.1080/00140139.2014.956151, doi:doi:10.1080/00140139.2014.956151. _eprint: https://d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.