The Terminal Representation in Reinforcement Learning
Pith reviewed 2026-06-28 23:16 UTC · model grok-4.3
The pith
The terminal representation encodes reward-weighted trajectories in RL as a lower-dimensional object that can be used directly without eigenvector computations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The terminal representation (TR) encodes reward-weighted trajectories similarly to the DR, but can be learned as a lower-dimensionality object, and can be used directly for the mentioned applications without eigenvector computations. Eigendecomposition also imposes the assumption of symmetric transition dynamics, which the TR can bypass. The TR is embedded in the top DR eigenvector, allowing it to capture the same underlying knowledge without eigendecomposition. The work develops the theoretical foundations including derivation, convergence of two learning algorithms, use for zero-shot compositionality, and equivalences between alternative reward formulations, along with empirical evidence o
What carries the argument
The terminal representation (TR), a lower-dimensional encoding of reward-weighted trajectories that is embedded in the top eigenvector of the default representation.
If this is right
- The TR supports zero-shot compositionality of representations.
- Two learning algorithms converge to the TR.
- Equivalences hold between alternative reward formulations within the TR.
- The TR enables the listed applications without requiring eigendecomposition.
- Learning, storing, and using the TR requires less computational overhead than the DR.
Where Pith is reading between the lines
- The lower-dimensional nature could make the TR more scalable to high-dimensional state spaces where eigendecomposition becomes prohibitive.
- Bypassing the symmetry assumption opens the possibility of applying these representations in non-reversible environments typical of many real control problems.
- The embedding property suggests potential for hybrid methods that combine TR with existing eigenvector-based techniques when partial symmetry holds.
Load-bearing premise
That the TR is embedded in the top DR eigenvector allowing capture of the same knowledge without eigendecomposition and that two unspecified learning algorithms converge to it while supporting the listed downstream uses.
What would settle it
An experiment demonstrating that the TR does not support direct use for option discovery or exploration without eigenvector computations, or fails to match DR information content under asymmetric transition dynamics.
Figures
read the original abstract
Representation learning is a powerful tool for spatio-temporal abstraction within reinforcement learning (RL). Two well established approaches are through the successor representation (SR) and the default representation (DR). The SR encodes states by the future trajectories they induce, capturing information flow decoupled from reward. The DR builds on this by weighting trajectories with reward, integrating credit-assignment structure into the representation. Eigenvectors of both representations have been used to support a range of downstream tasks -- including option discovery, reward shaping, transfer learning, and exploration. We introduce a structurally distinct formulation: the terminal representation (TR). The TR encodes reward-weighted trajectories similarly to the DR, but can be learned as a lower-dimensionality object, and can be used directly for the mentioned applications without eigenvector computations. Eigendecomposition also imposes the assumption of symmetric transition dynamics, which the TR can bypass. In this work we develop the theoretical foundations of the TR: its derivation, convergence of two learning algorithms, its use for zero-shot compositionality, and equivalences between alternative reward formulations. We further show the TR is embedded in the top DR eigenvector, allowing it to capture the same underlying knowledge without eigendecomposition. Additionally, we provide empirical evidence of the TR as a viable alternative to existing representations in subsidiary applications, while requiring less computational overhead to learn, store, and use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the terminal representation (TR) as a new formulation in reinforcement learning that encodes reward-weighted trajectories similarly to the default representation (DR) but as a lower-dimensional object. It develops theoretical foundations including its derivation, convergence of two learning algorithms, use for zero-shot compositionality, and equivalences between reward formulations. The central claims are that the TR is embedded in the top DR eigenvector (allowing the same knowledge without eigendecomposition), that TR can be used directly for option discovery, reward shaping, transfer learning, and exploration, and that it bypasses the symmetric transition dynamics assumption of eigendecomposition. Empirical evidence is provided that TR is a viable alternative with less computational overhead.
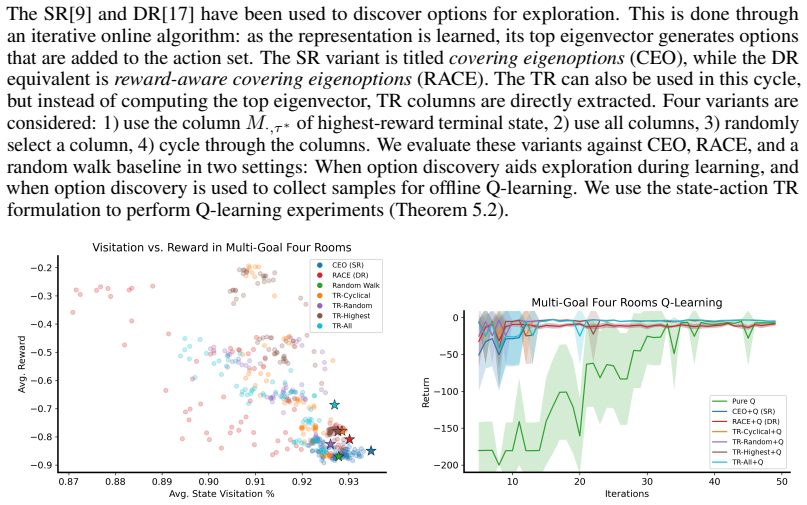
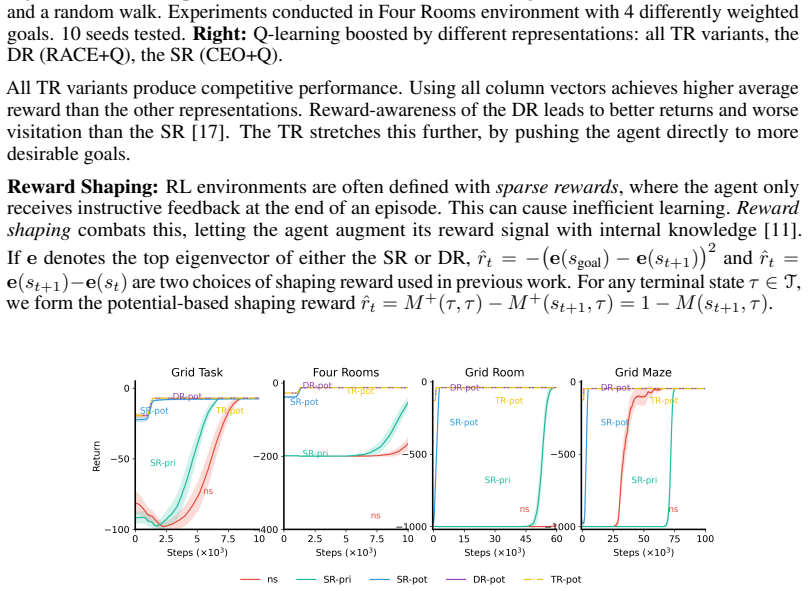
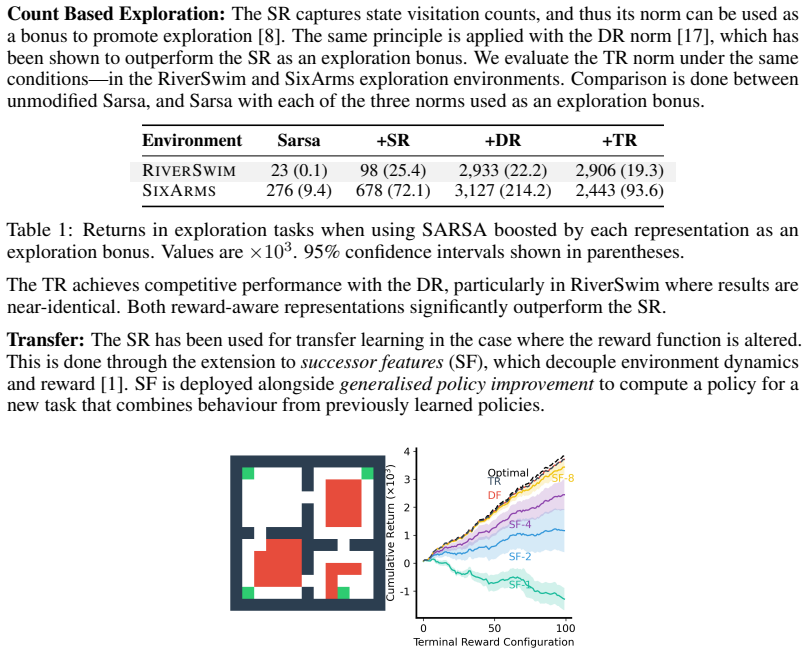
Significance. If the embedding relation and convergence results hold, the TR would offer a lower-dimensional, directly usable alternative to DR/SR eigenvectors for multiple downstream RL tasks, reducing computational costs in learning, storage, and application while avoiding symmetry assumptions. The empirical evidence for subsidiary applications is a positive contribution if the theoretical claims are secured.
major comments (3)
- [theoretical foundations on embedding] The claim that the TR is embedded in the top DR eigenvector (allowing capture of equivalent knowledge without eigendecomposition) is asserted in the abstract and theoretical foundations but no explicit embedding relation, derivation, or equation is provided, which is load-bearing for the dimensionality reduction and bypass of eigendecomposition.
- [section on learning algorithms and convergence] Convergence of the two learning algorithms to the TR is claimed as part of the theoretical foundations but neither the algorithms nor their convergence proofs/derivations are supplied, which is central to the assertion that TR can be learned as a lower-dimensionality object supporting the listed applications.
- [section on equivalences and compositionality] The equivalences between alternative reward formulations and the use for zero-shot compositionality are developed theoretically, but without the embedding and convergence established, it is unclear whether these preserve the representational power claimed relative to the DR.
minor comments (2)
- The two learning algorithms are referenced but not named or described in the abstract or early sections; this should be clarified with pseudocode or definitions.
- Notation for SR, DR, and TR should be introduced with explicit equations in the preliminaries to improve readability before the new derivations.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the manuscript. We address each major comment below and will revise the paper to strengthen the theoretical foundations as requested.
read point-by-point responses
-
Referee: The claim that the TR is embedded in the top DR eigenvector (allowing capture of equivalent knowledge without eigendecomposition) is asserted in the abstract and theoretical foundations but no explicit embedding relation, derivation, or equation is provided, which is load-bearing for the dimensionality reduction and bypass of eigendecomposition.
Authors: We agree that an explicit derivation of the embedding relation is necessary to support the central claims. In the revised manuscript we will add a dedicated derivation subsection that presents the embedding equation relating the TR to the top DR eigenvector, along with the steps showing how this relation permits equivalent knowledge capture without requiring eigendecomposition. revision: yes
-
Referee: Convergence of the two learning algorithms to the TR is claimed as part of the theoretical foundations but neither the algorithms nor their convergence proofs/derivations are supplied, which is central to the assertion that TR can be learned as a lower-dimensionality object supporting the listed applications.
Authors: We acknowledge that the algorithms and their convergence proofs must be supplied explicitly. The revision will include full descriptions of both learning algorithms together with the corresponding convergence derivations, thereby completing the theoretical support for learning the TR directly as a lower-dimensional object. revision: yes
-
Referee: The equivalences between alternative reward formulations and the use for zero-shot compositionality are developed theoretically, but without the embedding and convergence established, it is unclear whether these preserve the representational power claimed relative to the DR.
Authors: With the embedding relation and convergence results added as described above, the equivalences and zero-shot compositionality claims will be shown to preserve the asserted representational power relative to the DR. The revision will include explicit cross-references and additional explanatory text linking these results to the newly provided foundations. revision: yes
Circularity Check
No circularity: derivation presented as independent
full rationale
The abstract and provided text introduce the TR via its own derivation and two learning algorithms whose convergence is claimed to be shown. The embedding of TR in the top DR eigenvector is asserted as a result shown in the work, not presupposed by definition or by fitting a parameter to the target quantity. No equations are supplied that would allow reduction of any prediction to its inputs by construction, and no self-citation chain is invoked to justify the central premises. The paper therefore remains self-contained against external benchmarks with no load-bearing step that collapses to a renaming, ansatz smuggling, or fitted-input prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Successor features for transfer in reinforcement learning.Advances in neural information processing systems, 30, 2017
André Barreto, Will Dabney, Rémi Munos, Jonathan J Hunt, Tom Schaul, Hado P Van Hasselt, and David Silver. Successor features for transfer in reinforcement learning.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013
2013
-
[3]
Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993
Peter Dayan. Improving generalization for temporal difference learning: The successor repre- sentation.Neural Computation, 5(4):613–624, 1993
1993
-
[4]
Golub and Charles F
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4th edition, 2013
2013
-
[5]
Cambridge university press, 2012
Roger A Horn and Charles R Johnson.Matrix analysis. Cambridge university press, 2012
2012
-
[6]
Globally optimal hierarchical rein- forcement learning for linearly-solvable markov decision processes
Guillermo Infante, Anders Jonsson, and Vicenç Gómez. Globally optimal hierarchical rein- forcement learning for linearly-solvable markov decision processes. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 6970–6977, 2022
2022
-
[7]
Machado, Clemens Rosenbaum, Xiaoxiao Guo, Miao Liu, Gerald Tesauro, and Murray Campbell
Marlos C. Machado, Clemens Rosenbaum, Xiaoxiao Guo, Miao Liu, Gerald Tesauro, and Murray Campbell. Eigenoption discovery through the deep successor representation. In International Conference on Learning Representations (ICLR), 2018
2018
-
[8]
Machado, Marc G
Marlos C. Machado, Marc G. Bellemare, and Michael Bowling. Count-based exploration with the successor representation. InAAAI Conference on Artificial Intelligence (AAAI), 2020
2020
-
[9]
Machado, Andre Barreto, Doina Precup, and Michael Bowling
Marlos C. Machado, Andre Barreto, Doina Precup, and Michael Bowling. Temporal abstraction in reinforcement learning with the successor representation.Journal of Machine Learning Research, 24(80):1–69, 2023
2023
-
[10]
Proto-value functions: A laplacian framework for learning representation and control in markov decision processes.Journal of Machine Learning Research, 8(10), 2007
Sridhar Mahadevan and Mauro Maggioni. Proto-value functions: A laplacian framework for learning representation and control in markov decision processes.Journal of Machine Learning Research, 8(10), 2007
2007
-
[11]
Ng, Daishi Harada, and Stuart Russell
Andrew Y . Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transfor- mations: Theory and application to reward shaping. InInternational Conference on Machine Learning (ICML), 1999
1999
-
[12]
Payam Piray and Nathaniel D. Daw. Linear reinforcement learning in planning, grid fields, and cognitive control.Nature Communications, 12(1):4942, 2021
2021
-
[13]
SIAM, revised edition, 2011
Yousef Saad.Numerical Methods for Large Eigenvalue Problems. SIAM, revised edition, 2011
2011
-
[14]
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
1999
-
[15]
Linearly-solvable Markov decision problems.Advances in Neural Informa- tion Processing Systems (NIPS), pages 1369–1376, 2006
Emanuel Todorov. Linearly-solvable Markov decision problems.Advances in Neural Informa- tion Processing Systems (NIPS), pages 1369–1376, 2006
2006
-
[16]
Compositionality of optimal control laws.Advances in neural information processing systems, 22, 2009
Emanuel Todorov. Compositionality of optimal control laws.Advances in neural information processing systems, 22, 2009
2009
-
[17]
Reward-aware proto- representations in reinforcement learning.arXiv preprint arXiv:2505.16217, 2025
Hon Tik Tse, Siddarth Chandrasekar, and Marlos C Machado. Reward-aware proto- representations in reinforcement learning.arXiv preprint arXiv:2505.16217, 2025
-
[18]
v(i) S v(i) T # =β i
John N Tsitsiklis. Asynchronous stochastic approximation and q-learning.Machine learning, 16(3):185–202, 1994. 10 A Theory In this appendix we prove several of the theorems stated in the main text. For clarity we restate the theorems here. A.1 Proof of Theorem 4.1 Theorem 4.1LetM 0 =D T . The update rule Mk+1 =D T +D SMk (5) converges to the TR:lim k→∞ Mk...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.