Interpretability Without Tradeoffs: Disentangling Polysemanticity At Equal Predictive Performance
Pith reviewed 2026-06-28 23:11 UTC · model grok-4.3
The pith
ELUDe disentangles polysemantic neurons into monosemantic features with no change to model predictions or accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
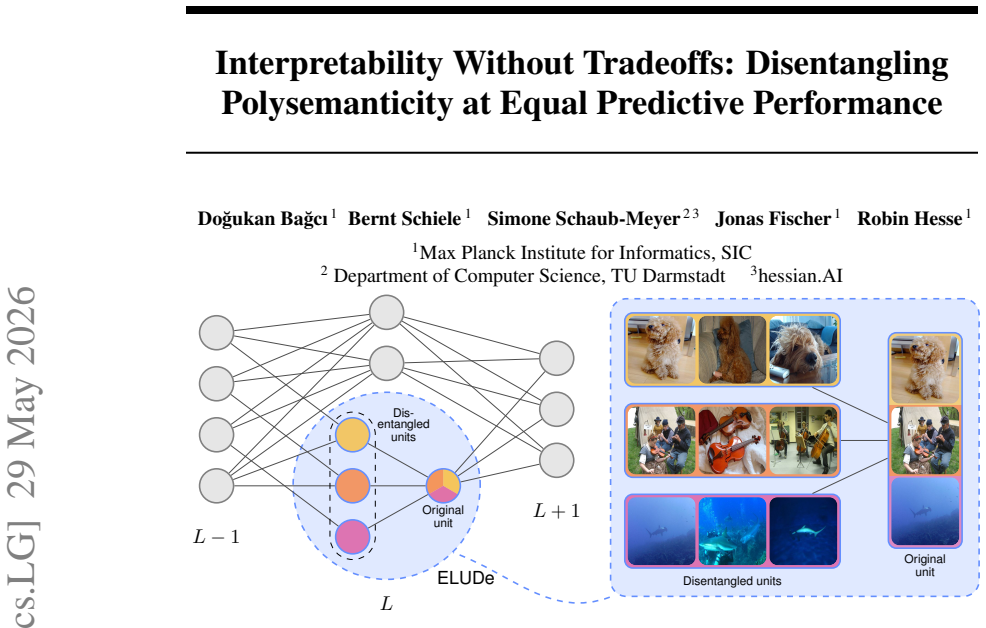
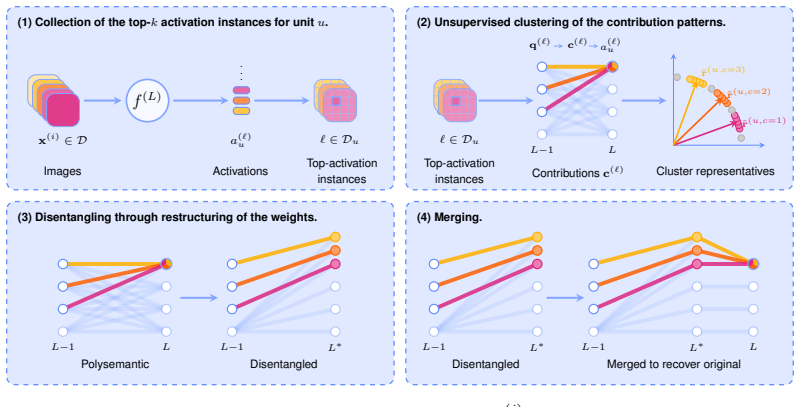
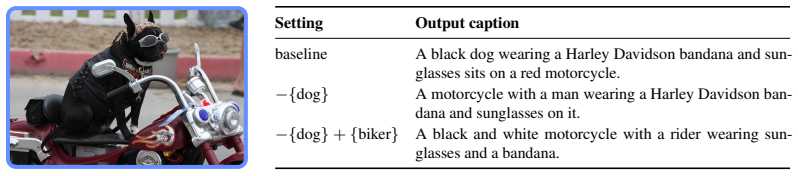
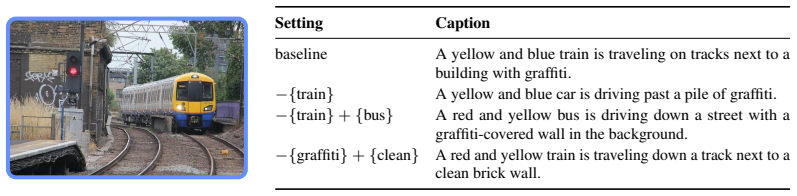
ELUDe is an explicit, lossless, unsupervised method that breaks latent representations in deep neural networks into clear sub-units behaving like interpretable features. It achieves this by re-routing concept-specific contributions between layers while preserving the original computation exactly by construction. The approach applies to pretrained models such as DINOv2 and ViT-B/16, improves interpretability, keeps downstream accuracy unchanged, and supports uses like steering representations.
What carries the argument
ELUDe, which separates polysemantic signals by explicit re-routing of concept-specific contributions between layers while preserving exact functional equivalence.
If this is right
- Interpretability improves on vision models including DINOv2 and supervised ViT-B/16 with no accuracy change.
- The method applies directly to any pretrained model without labels or retraining.
- Representation steering becomes possible as a practical downstream use.
- Functional equivalence holds by design, so performance metrics remain identical.
Where Pith is reading between the lines
- The re-routing principle might generalize to language models if concept contributions can be similarly isolated.
- Pairing ELUDe with other post-hoc methods could produce even finer-grained control over features.
- The lossless property would enable direct comparisons of interpretability before and after under identical conditions.
- Efficiency on very large models would hinge on scalable ways to detect the concept contributions.
Load-bearing premise
That concept-specific contributions can be identified and rerouted between layers to fully separate polysemantic signals into monosemantic features without altering the overall network computation.
What would settle it
Any observable difference in the model's output predictions or accuracy on a held-out test set after applying ELUDe would falsify the claim of lossless disentanglement.
Figures












read the original abstract
Deep neural networks (DNNs) are widely used, but interpreting what they actually learn remains difficult. A major obstacle is that individual neurons often encode multiple unrelated concepts, obscuring the decision process of the network. While prior work, such as sparse autoencoders, can separate these mixed signals into more meaningful, "monosemantic" features, this typically requires altering the model in ways that can degrade downstream performance. To overcome this, we introduce ELUDe (explicit, lossless, unsupervised disentanglement), a method for improving the interpretability of DNNs while preserving their functional equivalence. ELUDe breaks latent representations into clear, inspectable sub-units that behave like interpretable features, while guaranteeing that the model's outputs remain exactly the same. It requires no explicit training, no labels, and can be applied to pretrained models. ELUDe works by reorganizing how information flows between layers, re-routing concept-specific contributions while preserving the original computation by construction. Across several vision models, including DINOv2 and supervised ViT-B/16, ELUDe improves interpretability, keeps downstream accuracy unchanged, runs efficiently, and supports practical uses such as steering model representations. In short, ELUDe offers interpretability (almost) without a tradeoff: clearer, scalable, and actionable model insights with no loss in performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ELUDe, an unsupervised post-hoc method that reorganizes information flow between layers of pretrained DNNs (e.g., DINOv2, supervised ViT-B/16) by re-routing concept-specific contributions. It claims to produce monosemantic sub-units while guaranteeing exact functional equivalence to the original model (outputs unchanged by construction), with no training, no labels, and no degradation in downstream accuracy. The approach is positioned as enabling interpretability improvements and practical interventions such as representation steering.
Significance. If the lossless equivalence and monosemanticity claims hold, the result would be significant for interpretability research: it would remove the usual accuracy-interpretability tradeoff, allow direct application to existing models, and support downstream uses like steering without retraining. The absence of free parameters or invented entities in the high-level description is a strength if the re-routing mechanism is shown to be parameter-free and the equivalence is proven by construction.
major comments (3)
- [Methods (re-routing procedure)] The central claim of exact functional equivalence 'by construction' via re-routing requires an explicit derivation or proof in the methods section showing that the reorganized computation is mathematically identical to the original forward pass; without this, the 'lossless' guarantee cannot be verified and remains an assumption.
- [Experiments] Empirical verification that the resulting sub-units are monosemantic (rather than merely reorganized polysemantic features) is load-bearing for the interpretability claim; the experiments section should include quantitative metrics (e.g., feature activation sparsity, concept purity scores) with controls and statistical tests, not only qualitative examples.
- [Results (accuracy tables)] The claim that downstream accuracy remains exactly unchanged must be supported by reporting both mean and variance across multiple runs or seeds, plus a direct comparison to the unmodified baseline on the same evaluation protocol; any numerical difference, even if small, would contradict the 'exactly the same' guarantee.
minor comments (2)
- [Methods] Notation for the re-routing operation should be defined with explicit equations early in the methods section to avoid ambiguity when describing how contributions are identified and moved between layers.
- [Introduction] The abstract and introduction would benefit from a short related-work paragraph contrasting ELUDe with sparse autoencoders on the specific dimension of functional equivalence.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Methods (re-routing procedure)] The central claim of exact functional equivalence 'by construction' via re-routing requires an explicit derivation or proof in the methods section showing that the reorganized computation is mathematically identical to the original forward pass; without this, the 'lossless' guarantee cannot be verified and remains an assumption.
Authors: We agree that an explicit derivation strengthens the presentation. In the revised manuscript we will add a formal proof in the Methods section. The re-routing decomposes each pre-activation into additive concept-specific contributions and reassigns them to dedicated sub-units; because the subsequent linear transformation receives exactly the same total input, the forward pass is identical by construction. revision: yes
-
Referee: [Experiments] Empirical verification that the resulting sub-units are monosemantic (rather than merely reorganized polysemantic features) is load-bearing for the interpretability claim; the experiments section should include quantitative metrics (e.g., feature activation sparsity, concept purity scores) with controls and statistical tests, not only qualitative examples.
Authors: We acknowledge that quantitative metrics would provide stronger support. While the current experiments rely on qualitative visualizations and steering demonstrations, we will add quantitative evaluations (activation sparsity, concept purity scores, and statistical comparisons against baseline features) in the revised Experiments section. revision: yes
-
Referee: [Results (accuracy tables)] The claim that downstream accuracy remains exactly unchanged must be supported by reporting both mean and variance across multiple runs or seeds, plus a direct comparison to the unmodified baseline on the same evaluation protocol; any numerical difference, even if small, would contradict the 'exactly the same' guarantee.
Authors: ELUDe is fully deterministic and contains no trainable parameters or stochastic operations. Because functional equivalence holds by construction, every output is identical to the original model for any input; therefore downstream accuracy is exactly the same with zero variance. We will clarify this point explicitly in the revised Results section and omit multiple-run statistics, as they are inapplicable. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper presents ELUDe as a reorganization of information flow between layers that re-routes concept-specific contributions while preserving the original computation exactly by construction. No equations, fitted parameters, or derivation chain appear in the provided abstract or description that would reduce any claimed prediction or result to its inputs by definition. The functional equivalence is asserted as a built-in property of the re-routing procedure rather than a statistically forced outcome from data fitting. No self-citation load-bearing steps, uniqueness theorems imported from prior author work, or ansatz smuggling are identifiable from the text. The central claim remains independent of the inputs and does not reduce to renaming or self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achtibat, S
R. Achtibat, S. M. V . Hatefi, M. Dreyer, A. Jain, T. Wiegand, S. Lapuschkin, and W. Samek. AttnLRP: Attention-aware layer-wise relevance propagation for transformers. InICML, pages 135–168, 2024
2024
-
[2]
D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba. Network dissection: Quantifying interpretability of deep visual representations. InCVPR, pages 3319–3327, 2017
2017
-
[3]
Bereska and S
L. Bereska and S. Gavves. Mechanistic interpretability for AI safety - A review.TMLR, 2024
2024
-
[4]
Böhle, M
M. Böhle, M. Fritz, and B. Schiele. B-cos networks: Alignment is all we need for interpretability. InCVPR, pages 10319–10328, 2022
2022
-
[5]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. B. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. S. Chatterji, A. S. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. E. Gill...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Borowski, R
J. Borowski, R. S. Zimmermann, J. Schepers, R. Geirhos, T. S. A. Wallis, M. Bethge, and W. Brendel. Exemplary natural images explain CNN activations better than state-of-the-art feature visualization. InICLR, 2021
2021
-
[7]
Bousselham, A
W. Bousselham, A. W. Boggust, S. Chaybouti, H. Strobelt, and H. Kuehne. LeGrad: An explainability method for vision transformers via feature formation sensitivity. InICCV, pages 20336–20345, 2024
2024
-
[8]
Bricken, A
T. Bricken, A. Templeton, J. Batson, B. Chen, A. Jermyn, T. Conerly, N. Turner, C. Anil, C. Denison, A. Askell, R. Lasenby, Y . Wu, S. Kravec, N. Schiefer, T. Maxwell, N. Joseph, Z. Hatfield-Dodds, A. Tamkin, K. Nguyen, B. McLean, J. E. Burke, T. Hume, S. Carter, T. Henighan, and C. Olah. Towards monosemanticity: Decomposing language models with dictionar...
2023
-
[9]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
2020
-
[10]
Bussmann, P
B. Bussmann, P. Leask, and N. Nanda. BatchTopK sparse autoencoders. InNeurIPS, 2024
2024
-
[11]
Bussmann, N
B. Bussmann, N. Nabeshima, A. Karvonen, and N. Nanda. Learning multi-level features with matryoshka sparse autoencoders. InICML, 2025
2025
-
[12]
R. J. G. B. Campello, D. Moulavi, and J. Sander. Density-based clustering based on hierarchical density estimates. InPAKDD, pages 160–172, 2013
2013
-
[13]
C. Chen, O. Li, D. Tao, A. Barnett, C. Rudin, and J. Su. This looks like that: Deep learning for interpretable image recognition. InNeurIPS, pages 8928–8939, 2019
2019
-
[14]
Costa, T
V . Costa, T. Fel, E. S. Lubana, B. Tolooshams, and D. E. Ba. From flat to hierarchical: Extracting sparse representations with matching pursuit. InNeurIPS, 2025. 10
2025
-
[15]
J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. InCVPR, pages 248–255, 2009
2009
-
[16]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[17]
Dreyer, E
M. Dreyer, E. Purelku, J. Vielhaben, W. Samek, and S. Lapuschkin. PURE: Turning polyseman- tic neurons into pure features by identifying relevant circuits. InCVPRW, pages 8212–8217, 2024
2024
-
[18]
Dunefsky, P
J. Dunefsky, P. Chlenski, and N. Nanda. Transcoders find interpretable LLM feature circuits. In NeurIPS, 2024
2024
-
[19]
Elhage, T
N. Elhage, T. Hume, C. Olsson, N. Schiefer, T. Henighan, S. Kravec, Z. Hatfield-Dodds, R. Lasenby, D. Drain, C. Chen, R. B. Grosse, S. McCandlish, J. Kaplan, D. Amodei, M. Watten- berg, and C. Olah. Toy models of superposition.Transformer Circuits Thread, 2022
2022
- [20]
-
[21]
T. Fel, T. Boissin, V . Boutin, A. M. Picard, P. Novello, J. Colin, D. Linsley, T. Rousseau, R. Cadène, L. Gardes, and T. Serre. Unlocking feature visualization for deeper networks with magnitude constrained optimization. InNeurIPS, 2023
2023
-
[22]
T. Fel, E. S. Lubana, J. S. Prince, M. Kowal, V . Boutin, I. Papadimitriou, B. Wang, M. Watten- berg, D. E. Ba, and T. Konkle. Archetypal SAE: Adaptive and stable dictionary learning for concept extraction in large vision models. InICML, 2025
2025
-
[23]
Fischer, A
J. Fischer, A. Olah, and J. Vreeken. What’s in the box? exploring the inner life of neural networks with robust rules. InICML, 2021
2021
-
[24]
L. Gao, T. D. la Tour, H. Tillman, G. Goh, R. Troll, A. Radford, I. Sutskever, J. Leike, and J. Wu. Scaling and evaluating sparse autoencoders. InICLR, 2025
2025
-
[25]
Gorgun, B
A. Gorgun, B. Schiele, and J. Fischer. VITAL: More understandable feature visualization through distribution alignment and relevant information flow. InICCV, 2025
2025
-
[26]
J. A. Hartigan and M. A. Wong. Algorithm as 136: A k-means clustering algorithm.Journal of the royal statistical society. series c (applied statistics), 28(1):100–108, 1979
1979
-
[27]
Hendrycks, S
D. Hendrycks, S. Basart, N. Mu, S. Kadavath, F. Wang, E. Dorundo, R. Desai, T. Zhu, S. Parajuli, M. Guo, D. Song, J. Steinhardt, and J. Gilmer. The many faces of robustness: A critical analysis of out-of-distribution generalization. InICCV, pages 8320–8329, 2021
2021
-
[28]
Hesse, S
R. Hesse, S. Schaub-Meyer, and S. Roth. Fast axiomatic attribution for neural networks. In NeurIPS, pages 19513–19524, 2021
2021
-
[29]
Hesse, J
R. Hesse, J. Fischer, S. Schaub-Meyer, and S. Roth. Disentangling polysemantic channels in convolutional neural networks. InCVPRW, pages 4799–4803, 2025
2025
-
[30]
Hesse, D
R. Hesse, D. Bagci, B. Schiele, S. Schaub-Meyer, and S. Roth. Beyond accuracy: What matters in designing well-behaved image classification models?TMLR, 2026
2026
-
[31]
Hesse, S
R. Hesse, S. Schaub-Meyer, J. Hesse, B. Schiele, and S. Roth. What is missing? explaining neurons activated by absent concepts. InICML, 2026
2026
-
[32]
Huben, H
R. Huben, H. Cunningham, L. R. Smith, A. Ewart, and L. Sharkey. Sparse autoencoders find highly interpretable features in language models. InICLR, 2024
2024
-
[33]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12):248:1–248:38, 2023. 11
2023
-
[34]
Jumper, R
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera-Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstein, ...
2021
-
[35]
P. W. Koh, T. Nguyen, Y . S. Tang, S. Mussmann, E. Pierson, B. Kim, and P. Liang. Concept bottleneck models. InICML, pages 5338–5348, 2020
2020
-
[36]
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu, and C. Li. LLaV A-OneVision: Easy visual task transfer.TMLR, 2025
2025
-
[37]
T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft COCO: Common objects in context. InECCV, pages 740–755, 2014
2014
-
[38]
H. Liu, W. Xue, Y . Chen, D. Chen, X. Zhao, K. Wang, L. Hou, R. Li, and W. Peng. A survey on hallucination in large vision-language models.arXiv:2402.00253 [cs.CV], 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Makhzani and B
A. Makhzani and B. J. Frey. k-sparse autoencoders. InICLR, 2014
2014
-
[40]
Maser, S
R. Maser, S. Gairola, S. Rao, and B. Schiele. Align once to explain: Feature alignment for scalable b-cosification of foundational vision transformers. InCVPR, pages 9869–9879, 2026
2026
-
[41]
A. Mueller, J. Brinkmann, M. L. Li, S. Marks, K. Pal, N. Prakash, C. Rager, A. Sankara- narayanan, A. S. Sharma, J. Sun, E. Todd, D. Bau, and Y . Belinkov. The quest for the right mediator: Surveying mechanistic interpretability through the lens of causal mediation analysis. arXiv:2408.01416 [cs.LG], 2024
-
[42]
T. P. Oikarinen and T. Weng. Clip-dissect: Automatic description of neuron representations in deep vision networks. InICLR, 2023
2023
-
[43]
C. Olah, L. Schubert, and A. Mordvintsev. Feature visualization.Distill, 2017
2017
-
[44]
C. Olah, N. Cammarata, L. Schubert, G. Goh, M. Petrov, and S. Carter. Zoom in: An introduction to circuits.Distill, 2020
2020
-
[45]
O’Mahony, V
L. O’Mahony, V . Andrearczyk, H. Müller, and M. Graziani. Disentangling neuron representa- tions with concept vectors. InCVPRW, pages 3770–3775, 2023
2023
-
[46]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P. Huang, S. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jégou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without supervis...
2024
-
[47]
M. Pach, S. Karthik, Q. Bouniot, S. J. Belongie, and Z. Akata. Sparse autoencoders learn monosemantic features in vision-language models. InNeurIPS, 2025
2025
-
[48]
Parchami-Araghi, S
A. Parchami-Araghi, S. Rao, J. Fischer, and B. Schiele. Fact: Faithful concept traces for explaining neural network decisions. InNeurIPS, 2025
2025
-
[49]
Paulo and N
G. Paulo and N. Belrose. Sparse autoencoders trained on the same data learn different features. ICLR, 2026
2026
-
[50]
N. Pham, A. Jesslen, B. Schiele, A. Kortylewski, and J. Fischer. Interpretable 3D neural object volumes for robust conceptual reasoning. InICLR, 2026
2026
-
[51]
C. Qin, C. Venhoff, S. Joseph, F. Xiao, and S. Scherer. Sparse CLIP: Co-optimizing inter- pretability and performance in contrastive learning.ICLR, 2026
2026
- [52]
-
[53]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
S. Rajamanoharan, T. Lieberum, N. Sonnerat, A. Conmy, V . Varma, J. Kramár, and N. Nanda. Jumping ahead: Improving reconstruction fidelity with JumpReLU sparse autoencoders. arXiv:2407.14435 [cs.LG], 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Reimers and I
N. Reimers and I. Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InEMNLP-IJCNLP, pages 3980–3990, 2019
2019
-
[55]
Russakovsky, J
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. S. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet large scale visual recognition challenge.IJCV, 115(3):211–252, 2015
2015
-
[56]
Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892,
A. Scherlis, K. Sachan, A. S. Jermyn, J. Benton, and B. Shlegeris. Polysemanticity and capacity in neural networks.arXiv:2210.01892 [cs.NE], 2022
-
[57]
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. InICCV, pages 618–626, 2017
2017
-
[58]
Sharkey, B
L. Sharkey, B. Chughtai, J. Batson, J. Lindsey, J. Wu, L. Bushnaq, N. Goldowsky-Dill, S. Heimer- sheim, A. Ortega, J. I. Bloom, S. Biderman, A. Garriga-Alonso, A. Conmy, N. Nanda, J. Rumbe- low, M. Wattenberg, N. Schoots, J. Miller, W. Saunders, E. J. Michaud, S. Casper, M. Tegmark, D. Bau, E. Todd, A. Geiger, M. Geva, J. Hoogland, D. Murfet, and T. McGra...
2025
-
[59]
Simonyan, A
K. Simonyan, A. Vedaldi, and A. Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. InICLRW, 2014
2014
-
[60]
Steiner, A
A. Steiner, A. Kolesnikov, X. Zhai, R. Wightman, J. Uszkoreit, and L. Beyer. How to train your ViT? Data, augmentation, and regularization in vision transformers.TMLR, 2022
2022
-
[61]
Sundararajan, A
M. Sundararajan, A. Taly, and Q. Yan. Axiomatic attribution for deep networks. In D. Precup and Y . W. Teh, editors,ICML, pages 3319–3328, 2017
2017
-
[62]
G. Team. Gemma 3 technical report.arXiv:2503.19786 [cs.CL], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Q. Team. Qwen3-VL technical report.arXiv:2505.09388 [cs.CL], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Templeton, T
A. Templeton, T. Conerly, J. Marcus, J. Lindsey, T. Bricken, B. Chen, A. Pearce, C. Citro, E. Ameisen, A. Jones, H. Cunningham, N. L. Turner, C. McDougall, M. MacDiarmid, C. D. Freeman, T. R. Sumers, E. Rees, J. Batson, A. Jermyn, S. Carter, C. Olah, and T. Henighan. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet.Transform...
2024
-
[65]
M. Tschannen, A. A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. J. Hénaff, J. Harmsen, A. Steiner, and X. Zhai. SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv:2502.14786 [cs.CV], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Steering language models with activation engineering.arXiv:2308.10248 [cs.CL], 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Y . Wang, H. Li, X. Han, P. Nakov, and T. Baldwin. Do-not-answer: A dataset for evaluating safeguards in LLMs. InEACL, 2024
2024
-
[68]
Wightman
R. Wightman. Pytorch image models, 2019
2019
-
[69]
K. Wittenmayer, S. Rao, A. Parchami-Araghi, B. Schiele, and J. Fischer. CFM: Language- aligned concept foundation model for vision.arXiv:2601.13798 [cs.CV], 2026
-
[70]
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie. ConvNeXt V2: Co- designing and scaling convnets with masked autoencoders. InCVPR, pages 16133–16142, 2023. 13
2023
-
[71]
Z. Wu, A. Arora, A. Geiger, Z. Wang, J. Huang, D. Jurafsky, C. D. Manning, and C. Potts. AxBench: Steering llms? even simple baselines outperform sparse autoencoders. InICML, 2025
2025
-
[72]
M. Xue, Q. Huang, H. Zhang, J. Hu, J. Song, M. Song, and C. Jin. ProtoPFormer: Concentrating on prototypical parts in vision transformers for interpretable image recognition. InIJCAI, pages 1516–1524, 2024
2024
-
[73]
H. Yin, P. Molchanov, J. M. Álvarez, Z. Li, A. Mallya, D. Hoiem, N. K. Jha, and J. Kautz. Dreaming to distill: Data-free knowledge transfer via deepinversion. InCVPR, pages 8712– 8721, 2020
2020
-
[74]
Zaigrajew, H
V . Zaigrajew, H. Baniecki, and P. Biecek. Interpreting CLIP with hierarchical sparse autoen- coders. InICML, 2025
2025
-
[75]
M. E. Zarlenga, P. Barbiero, G. Ciravegna, G. Marra, F. Giannini, M. Diligenti, Z. Shams, F. Precioso, S. Melacci, A. Weller, P. Lió, and M. Jamnik. Concept embedding models: Beyond the accuracy-explainability trade-off. InNeurIPS, 2022
2022
-
[76]
Zhang, J
Y . Zhang, J. Jia, X. Chen, A. Chen, Y . Zhang, J. Liu, K. Ding, and S. Liu. To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images ... for now. In ECCV, pages 385–403, 2024
2024
-
[77]
Zheng, W
L. Zheng, W. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InNeurIPS, 2023
2023
-
[78]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao, Z. Gao, E. Cui, X. Wang, Y . Cao, Y . Liu, X. Wei, H. Zhang, H. Wang, W. Xu, H. Li, J. Wang, N. Deng, S. Li, Y . He, T. Jiang, J. Luo, Y . Wang, C. He, B. Shi, X. Zhang, W. Shao, J. He, Y . Xiong, W. Qu, P. Sun, P. Jiao, H. Lv, L. Wu, K. Zhang, H. Deng, J. Ge, K. Chen, L. W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.