Wall-Clock Complexity for Zeroth-Order Optimization with Tunable Oracle Fidelity
Pith reviewed 2026-06-28 21:18 UTC · model grok-4.3
The pith
In zeroth-order optimization with tunable-fidelity oracles, accelerated methods can take more wall-clock time than non-accelerated methods to reach a target accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
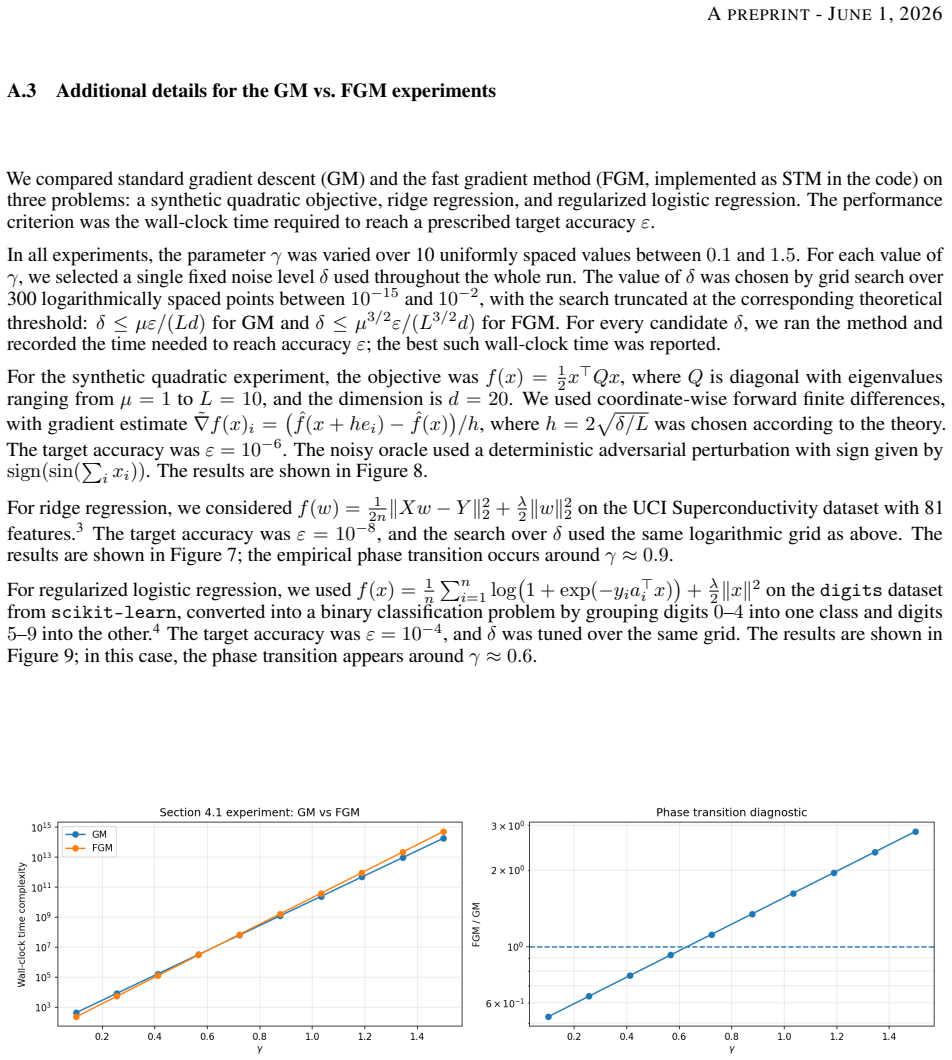
The authors establish an accuracy-aware wall-clock model in which each query at fidelity δ costs c(δ), and the goal is to minimize total time subject to reaching a target accuracy. They demonstrate that accelerated zeroth-order methods can be wall-clock inferior to non-accelerated schemes. They further characterize the conditions under which a constant fidelity strategy is optimal in the Big-O sense, providing a way to convert standard convergence guarantees into practical recommendations for fidelity and batch sizes.
What carries the argument
The accuracy-aware wall-clock complexity model that accounts for query cost c(δ) as a function of fidelity δ and translates convergence rates into total time bounds.
If this is right
- Accelerated methods may require higher total wall-clock time than non-accelerated ones for the same accuracy target.
- Constant fidelity across all queries is optimal in the Big-O sense under specific conditions on the cost and noise models.
- The optimal algorithmic parameters, including batch sizes and fidelities, are explicitly determined by the oracle type and noise model.
- The framework allows direct translation of iteration complexity into wall-clock recommendations.
Where Pith is reading between the lines
- In practice this could mean testing non-accelerated methods first when simulation costs increase sharply with accuracy.
- The model might extend to adaptive fidelity choices that change during optimization, though the paper focuses on fixed strategies.
- It raises the question of how to estimate the cost function c(δ) in real applications without prior knowledge.
Load-bearing premise
The cost function relating fidelity to computational cost and the specific noise model are known in advance and follow the functional forms assumed in the derivations.
What would settle it
Measuring the actual total simulation time for both accelerated and non-accelerated methods on a tunable-fidelity simulator and finding that the accelerated method always finishes faster would falsify the claim of wall-clock inferiority.
Figures










read the original abstract
Zeroth-order (black-box) optimization is applied when gradients are unavailable and objective evaluations rely on expensive simulations. In many such applications, the oracle fidelity is tunable: higher-accuracy queries reduce noise but incur higher computational costs. To capture this trade-off, we study an accuracy-aware wall-clock model where each query with fidelity $\delta$ has a cost $c(\delta)$, and we minimize the total time $T_{\mathrm{total}} = \sum_{k=1}^{N} c(\delta_k)$, subject to a target accuracy constraint. We show how the choice of oracle type, noise model, and optimization scheme induces explicit wall-clock-optimal choices for the algorithmic parameters. For instance, we demonstrate that accelerated methods can be wall-clock inferior to non-accelerated schemes. Furthermore, we characterize the conditions under which a constant fidelity strategy is optimal in the Big-O sense. Our framework provides a unified methodology to translate convergence guarantees into practical fidelity and batching recommendations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a wall-clock complexity model for zeroth-order optimization with tunable oracle fidelity δ. Each query at fidelity δ incurs cost c(δ), and the goal is to minimize total time T_total = ∑ c(δ_k) subject to a target accuracy constraint. The framework translates standard zeroth-order convergence rates into explicit recommendations for fidelity schedules and batch sizes. It shows that, under the model, accelerated methods can be wall-clock inferior to non-accelerated schemes and characterizes conditions under which a constant-fidelity strategy is optimal in the Big-O sense.
Significance. If the assumed functional forms for c(δ) and the noise model hold, the results supply concrete, practical guidance for choosing fidelity and batching parameters in expensive simulation-based zeroth-order problems. The unified translation of convergence guarantees into wall-clock recommendations is a useful bridge between theory and implementation. The derivations appear to rest on standard rates translated into the new objective rather than on self-referential or fitted quantities.
major comments (1)
- [Abstract] Abstract and the derivations of the wall-clock bounds: the claims that accelerated methods are wall-clock inferior and that constant fidelity is Big-O optimal are obtained by minimizing T_total under explicit parametric assumptions on c(δ) and on how noise variance depends on δ. The manuscript should state these functional forms explicitly (e.g., in the model section) and either prove robustness to monotone deviations or clearly delimit the scope of the Big-O statements, because even monotone but non-matching c(δ) can alter the optimal schedule and the acceleration comparison.
minor comments (1)
- Notation for δ, c(δ), and the accuracy constraint should be introduced once and used consistently; any implicit dependence of the noise model on δ should be written explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract and the derivations of the wall-clock bounds: the claims that accelerated methods are wall-clock inferior and that constant fidelity is Big-O optimal are obtained by minimizing T_total under explicit parametric assumptions on c(δ) and on how noise variance depends on δ. The manuscript should state these functional forms explicitly (e.g., in the model section) and either prove robustness to monotone deviations or clearly delimit the scope of the Big-O statements, because even monotone but non-matching c(δ) can alter the optimal schedule and the acceleration comparison.
Authors: We agree that the specific parametric forms for c(δ) and the noise dependence on δ are essential to the concrete wall-clock bounds and comparisons. The general model is introduced in Section 2, but we will revise the manuscript to state the explicit functional forms (e.g., the power-law or other parametric families used for the Big-O results) directly in the model section. We will also add a clarifying remark delimiting the scope of the Big-O optimality claims and the acceleration comparison to these assumed families, without claiming robustness to arbitrary monotone deviations, as the referee correctly observes that such deviations can alter the optimal schedule. revision: yes
Circularity Check
No circularity: derivations translate standard rates under explicit parametric assumptions
full rationale
The paper assumes known functional forms for c(δ) and the noise model, then minimizes T_total subject to accuracy constraints using standard zeroth-order convergence rates. No quoted step reduces a claimed prediction or optimality result to a fitted parameter or self-citation by construction. The framework is self-contained against external benchmarks once the functional forms are granted; the reader's score of 2 reflects only the normal dependence on modeling assumptions rather than any definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lossy compression of matrices by black box optimisation of mixed integer nonlinear programming
Tadashi Kadowaki and Mitsuru Ambai. Lossy compression of matrices by black box optimisation of mixed integer nonlinear programming. Scientific Reports, 12 0 (1): 0 15482, 2022
2022
-
[2]
Black-box sparse adversarial attack via multi-objective optimisation
Phoenix Neale Williams and Ke Li. Black-box sparse adversarial attack via multi-objective optimisation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12291--12301, 2023
2023
-
[3]
Simulator-based surrogate optimisation employing adaptive uncertainty-aware sampling
Yu Liu and Fabricio Oliveira. Simulator-based surrogate optimisation employing adaptive uncertainty-aware sampling. Computers & Chemical Engineering, page 109243, 2025
2025
-
[4]
Black-box optimization with local generative surrogates
Sergey Shirobokov, Vladislav Belavin, Michael Kagan, Andrei Ustyuzhanin, and Atilim Gunes Baydin. Black-box optimization with local generative surrogates. Advances in neural information processing systems, 33: 0 14650--14662, 2020
2020
-
[5]
Optimizing molecules using efficient queries from property evaluations
Samuel C Hoffman, Vijil Chenthamarakshan, Kahini Wadhawan, Pin-Yu Chen, and Payel Das. Optimizing molecules using efficient queries from property evaluations. Nature Machine Intelligence, 4 0 (1): 0 21--31, 2022
2022
-
[6]
Learning supervised pagerank with gradient-based and gradient-free optimization methods
Lev Bogolubsky, Pavel Dvurechenskii, Alexander Gasnikov, Gleb Gusev, Yurii Nesterov, Andrei M Raigorodskii, Aleksey Tikhonov, and Maksim Zhukovskii. Learning supervised pagerank with gradient-based and gradient-free optimization methods. Advances in neural information processing systems, 29, 2016
2016
-
[7]
Optimal inexactness schedules for tunable oracle-based methods
Guillaume Van Dessel and Fran c ois Glineur. Optimal inexactness schedules for tunable oracle-based methods. Optimization Methods and Software, 39 0 (3): 0 664--698, 2024
2024
-
[8]
Randomized gradient-free methods in convex optimization
Alexander Gasnikov, Darina Dvinskikh, Pavel Dvurechensky, Eduard Gorbunov, Aleksandr Beznosikov, and Alexander Lobanov. Randomized gradient-free methods in convex optimization. In Encyclopedia of Optimization, pages 1--15. Springer, 2023
2023
-
[9]
Intermediate gradient methods for smooth convex problems with inexact oracle
Olivier Devolder, Fran c ois Glineur, Yurii Nesterov, et al. Intermediate gradient methods for smooth convex problems with inexact oracle. Technical report, Technical report, CORE-2013017, 2013
2013
-
[10]
Accelerated gradient methods with absolute and relative noise in the gradient
Artem Vasin, Alexander Gasnikov, Pavel Dvurechensky, and Vladimir Spokoiny. Accelerated gradient methods with absolute and relative noise in the gradient. Optimization Methods and Software, 38 0 (6): 0 1180--1229, 2023
2023
-
[11]
overparametrization
Aleksandr Lobanov and Alexander Gasnikov. Accelerated zero-order sgd method for solving the black box optimization problem under “overparametrization” condition. In International Conference on Optimization and Applications, pages 72--83. Springer, 2023
2023
-
[12]
Accelerated zero-order sgd under high-order smoothness and overparameterized regime
Georgii Bychkov, Darina Dvinskikh, Anastasia Antsiferova, Alexander Gasnikov, and Aleksandr Lobanov. Accelerated zero-order sgd under high-order smoothness and overparameterized regime. arXiv preprint arXiv:2411.13999, 2024
-
[13]
Gradient-free optimization of highly smooth functions: improved analysis and a new algorithm
Arya Akhavan, Evgenii Chzhen, Massimiliano Pontil, and Alexandre B Tsybakov. Gradient-free optimization of highly smooth functions: improved analysis and a new algorithm. Journal of Machine Learning Research, 25 0 (370): 0 1--50, 2024
2024
-
[14]
black-box
Aleksandr Lobanov, Nail Bashirov, and Alexander Gasnikov. The “black-box” optimization problem: Zero-order accelerated stochastic method via kernel approximation. Journal of Optimization Theory and Applications, 203 0 (3): 0 2451--2486, 2024
2024
-
[15]
The pagerank citation ranking: Bring order to the web
Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. The pagerank citation ranking: Bring order to the web. In Proc. of the 7th International World Wide Web Conf.--1998, 1999
1998
-
[16]
On solving minimization and min-max problems by first-order methods with relative error in gradients
Artem Vasin, Valery Krivchenko, Dmitry Kovalev, Fedyor Stonyakin, Nazarii Tupitsa, Pavel Dvurechensky, Mohammad Alkousa, Nikita Kornilov, and Alexander Gasnikov. On solving minimization and min-max problems by first-order methods with relative error in gradients. arXiv preprint arXiv:2503.06628, 2025
-
[17]
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron
Sharan Vaswani, Francis Bach, and Mark Schmidt. Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron. In The 22nd international conference on artificial intelligence and statistics, pages 1195--1204. PMLR, 2019
2019
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
The mnist database of handwritten digit images for machine learning research [best of the web]
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE signal processing magazine, 29 0 (6): 0 141--142, 2012
2012
-
[20]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
2016
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[22]
Stochastic intermediate gradient method for convex problems with stochastic inexact oracle
Pavel Dvurechensky and Alexander Gasnikov. Stochastic intermediate gradient method for convex problems with stochastic inexact oracle. Journal of Optimization Theory and Applications, 171 0 (1): 0 121--145, 2016
2016
-
[23]
Fedor Stonyakin, Alexander Tyurin, Alexander Gasnikov, Pavel Dvurechensky, Artem Agafonov, Darina Dvinskikh, Mohammad Alkousa, Dmitry Pasechnyuk, Sergei Artamonov, and Victorya Piskunova. Inexact relative smoothness and strong convexity for optimization and variational inequalities by inexact model. arXiv preprint arXiv:2001.09013, 2020
-
[24]
Inexact model: A framework for optimization and variational inequalities
Fedor Stonyakin, Alexander Tyurin, Alexander Gasnikov, Pavel Dvurechensky, Artem Agafonov, Darina Dvinskikh, Mohammad Alkousa, Dmitry Pasechnyuk, Sergei Artamonov, and Victorya Piskunova. Inexact model: A framework for optimization and variational inequalities. Optimization Methods and Software, 36 0 (6): 0 1155--1201, 2021
2021
-
[25]
Lectures on convex optimization, volume 137
Yurii Nesterov. Lectures on convex optimization, volume 137. Springer, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.