YARD: Y-Architecture Register Decoding for Efficient Hallucination Mitigation in Large Vision-Language Models
Pith reviewed 2026-06-28 23:17 UTC · model grok-4.3
The pith
Y-architecture branches decoder at middle layers and uses register tokens to create an efficient contrastive signal that reduces hallucinations in large vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
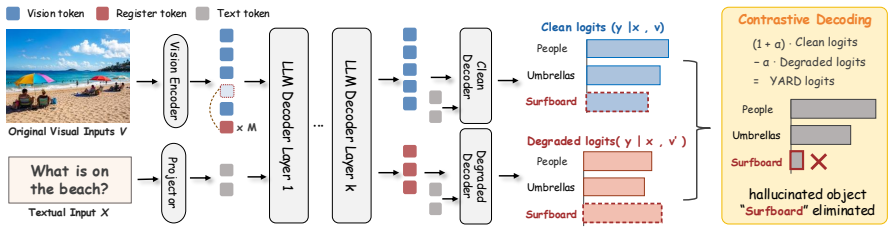
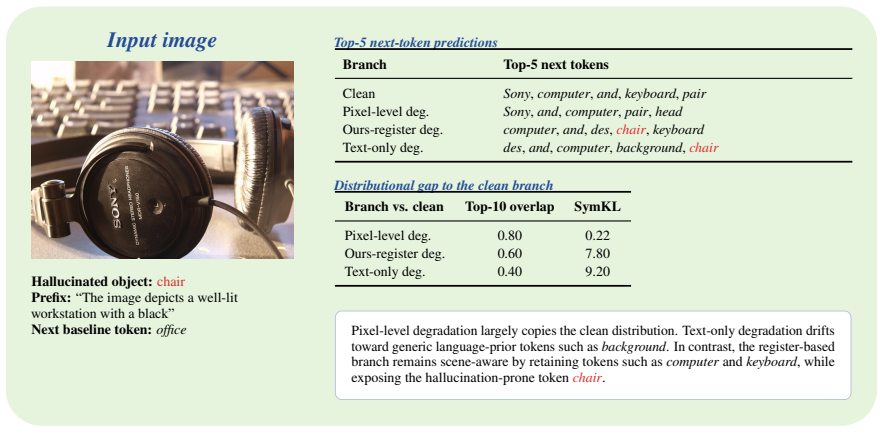
YARD constructs the degraded branch internally by sharing shallow-layer computations and branching exactly at the critical middle stage. For the degraded branch, YARD replaces patch-level visual tokens with register tokens, which preserve global image semantics but lack fine-grained local evidence. This image-aware yet locally under-grounded design provides a faithful contrastive signal without extreme modality mismatch, while the Y-architecture strictly avoids a costly second forward pass.
What carries the argument
The Y-architecture that shares shallow decoder layers and branches at middle layers for a register-token degraded branch to generate the contrastive signal.
If this is right
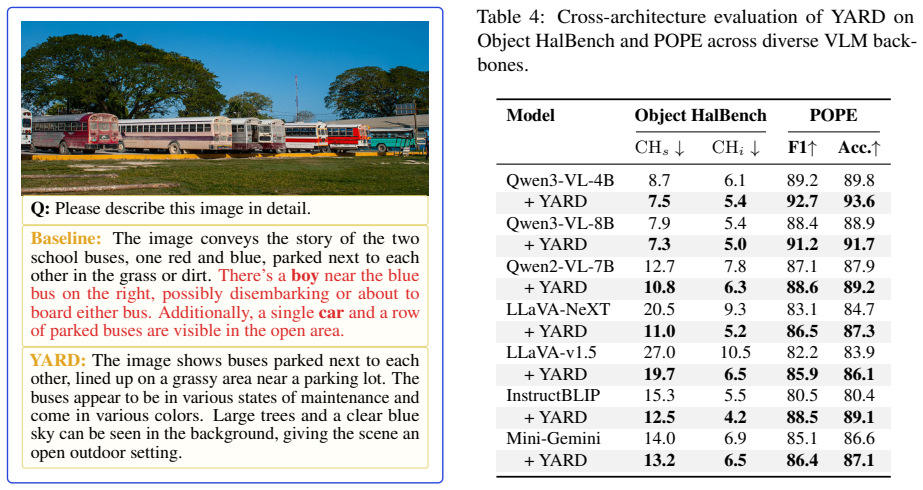
- YARD achieves state-of-the-art hallucination mitigation on generative and discriminative benchmarks across multiple LVLMs.
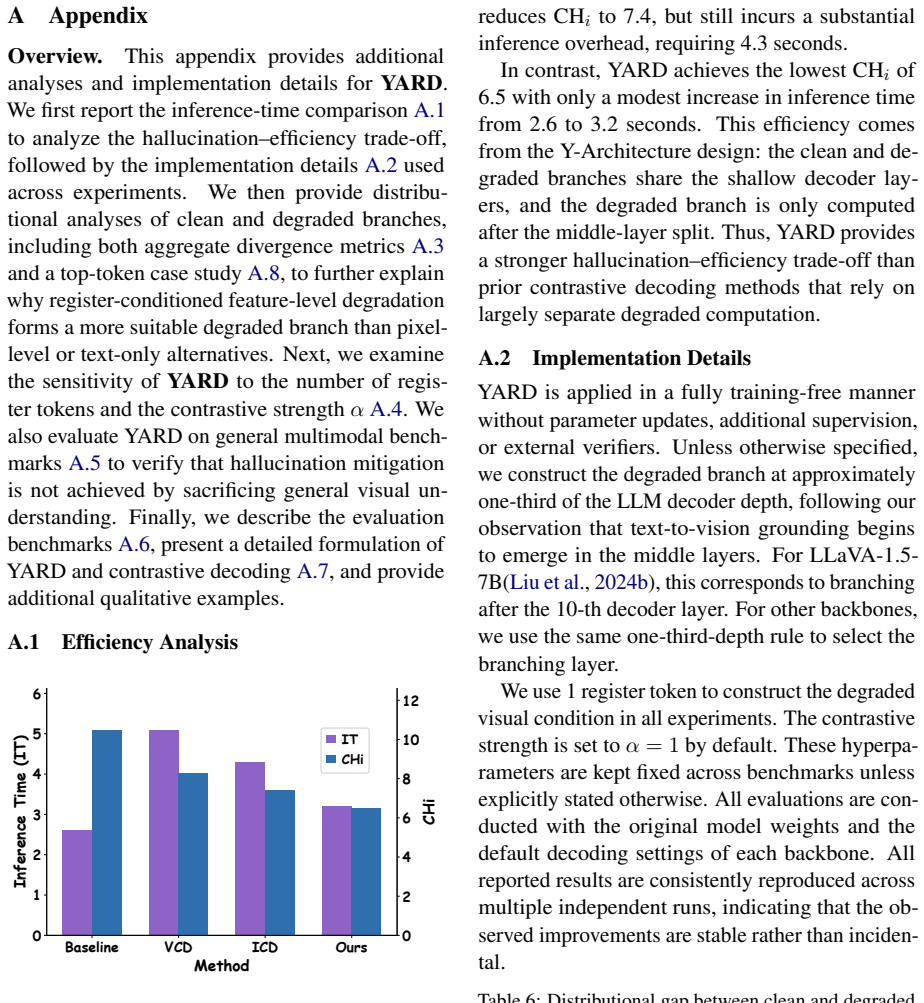
- It reduces inference latency significantly by avoiding a second full forward pass.
- The method prevents language hallucinations that arise from extreme visual degradation.
- Register tokens provide a balanced contrastive signal that maintains global semantics without fine-grained evidence.
Where Pith is reading between the lines
- The approach suggests that internal branching in decoder layers can generalize to other efficiency techniques in multimodal models.
- Future work could test if similar register-based degradation works in pure language models for other contrastive tasks.
- Ablations on different layer branching points might reveal more about where grounding occurs in various architectures.
Load-bearing premise
Reliable text-to-vision grounding predominantly emerges in the middle decoder layers of LVLMs.
What would settle it
An experiment that applies YARD but branches at early or late layers instead of middle ones and measures if hallucination reduction and latency benefits disappear.
Figures








read the original abstract
Contrastive decoding (CD) seeks to mitigate hallucinations in Large Vision-Language Models (LVLMs) by contrasting the output distributions of a standard model and a visually degraded model. However, existing training-free CD methods suffer from sub-optimal degraded branches: completely dropping visual tokens is too extreme and induces language hallucinations, while corrupting input images offers coarse control over visual evidence and suffers from high inference latency due to requiring two full forward passes. To address these dilemmas, we propose YARD, a training-free Y-Architecture Register Decoding framework. Motivated by the observation that reliable text-to-vision grounding predominantly emerges in the middle decoder layers, YARD constructs the degraded branch internally by sharing shallow-layer computations and branching exactly at this critical stage. For the degraded branch, YARD replaces patch-level visual tokens with register tokens, which preserve global image semantics but lack fine-grained local evidence. This image-aware yet locally under-grounded design provides a faithful contrastive signal without extreme modality mismatch, while the Y-architecture strictly avoids a costly second forward pass. Extensive experiments on generative and discriminative hallucination benchmarks demonstrate that YARD consistently achieves state-of-the-art hallucination mitigation across multiple LVLMs, alongside a significant reduction in inference latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes YARD, a training-free Y-Architecture Register Decoding method for hallucination mitigation in LVLMs. It constructs a degraded branch by sharing shallow decoder layers and branching at a middle layer, replacing patch tokens with register tokens (preserving global semantics but lacking fine-grained evidence) to generate a contrastive signal. This avoids the extremes of full visual dropout or image corruption and eliminates a second full forward pass, claiming SOTA performance on generative and discriminative hallucination benchmarks across multiple LVLMs plus reduced inference latency.
Significance. If the results hold, the Y-architecture provides a practical efficiency gain over prior contrastive decoding approaches by internalizing the degraded branch rather than requiring dual full passes. The design choice of register-token substitution for controlled local under-grounding is a targeted contribution to the contrastive signal quality.
major comments (1)
- [Abstract] Abstract: The central design decision to branch exactly at the middle decoder layer rests on the claim that 'reliable text-to-vision grounding predominantly emerges in the middle decoder layers,' yet the manuscript supplies no quantitative localization of grounding emergence, no layer-wise ablation of the branching point, and no cross-model consistency verification. This assumption is load-bearing for the validity of the contrastive signal; if the chosen layer does not mark the onset of stable grounding, the register substitution may either fail to provide sufficient contrast or introduce uncontrolled artifacts.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the substantive comment on the grounding-layer assumption. We address the point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central design decision to branch exactly at the middle decoder layer rests on the claim that 'reliable text-to-vision grounding predominantly emerges in the middle decoder layers,' yet the manuscript supplies no quantitative localization of grounding emergence, no layer-wise ablation of the branching point, and no cross-model consistency verification. This assumption is load-bearing for the validity of the contrastive signal; if the chosen layer does not mark the onset of stable grounding, the register substitution may either fail to provide sufficient contrast or introduce uncontrolled artifacts.
Authors: We agree that the manuscript as submitted does not contain a dedicated quantitative analysis of when text-to-vision grounding emerges across layers. The middle-layer branching choice was selected on the basis of preliminary internal measurements that are not reported in the current version. In the revised manuscript we will add a new subsection (with accompanying figure) that (i) quantifies grounding emergence via layer-wise probing of attention to visual tokens, (ii) reports a full ablation of branching depth on the primary benchmarks, and (iii) repeats the ablation on all three LVLMs evaluated in the paper. These additions will directly address the requested localization, ablation, and cross-model verification. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper motivates the Y-architecture from an observation about grounding emergence in middle decoder layers and introduces register-token substitution in the degraded branch as a structural choice to avoid a second forward pass. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or definitional equivalence; the central claims rest on empirical results across hallucination benchmarks rather than internal renaming or ansatz smuggling. The layer-choice premise is presented as motivation, not derived from the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reliable text-to-vision grounding predominantly emerges in the middle decoder layers
invented entities (1)
-
Y-Architecture Register Decoding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. 2024. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024 a . An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pages 19--35. Springer
2024
- [4]
-
[5]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R Glass, and Pengcheng He. 2024. Dola: Decoding by contrasting layers improves factuality in large language models. In International Conference on Learning Representations, volume 2024, pages 54158--54183
2024
-
[6]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. 2023. Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in neural information processing systems, 36:49250--49267
2023
-
[7]
Timoth \'e e Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. 2024. Vision transformers need registers. In International Conference on Learning Representations, volume 2024, pages 2632--2652
2024
- [8]
-
[9]
Yingqi Fan, Anhao Zhao, Jinlan Fu, Junlong Tong, Hui Su, Yijie Pan, Wei Zhang, and Xiaoyu Shen. 2025. Visipruner: Decoding discontinuous cross-modal dynamics for efficient multimodal llms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18896--18913
2025
-
[10]
Alessandro Favero, Luca Zancato, Matthew Trager, Siddharth Choudhary, Pramuditha Perera, Alessandro Achille, Ashwin Swaminathan, and Stefano Soatto. 2024. Multi-modal hallucination control by visual information grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14303--14312
2024
- [11]
-
[12]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and 1 others. 2025. Mme: A comprehensive evaluation benchmark for multimodal large language models. Advances in Neural Information Processing Systems, 38
2025
-
[13]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, and 1 others. 2024. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern re...
2024
-
[14]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418--13427
2024
-
[15]
Drew A Hudson and Christopher D Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700--6709
2019
- [16]
-
[17]
Nicholas Jiang, Amil Dravid, Alexei Efros, and Yossi Gandelsman. 2025 a . Vision transformers don't need trained registers. Advances in neural information processing systems, 38:56557--56595
2025
-
[18]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. 2025 b . Devils in middle layers of large vision-language models: Interpreting, detecting and mitigating object hallucinations via attention lens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25004--25014
2025
-
[19]
Jieun Kim, Jinmyeong Kim, Yoonji Kim, and Sung-Bae Cho. 2025. Fuzzy contrastive decoding to alleviate object hallucination in large vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20572--20581
2025
- [20]
-
[21]
Sicong Leng, Yun Xing, Zesen Cheng, Yang Zhou, Hang Zhang, Xin Li, Deli Zhao, Shijian Lu, Chunyan Miao, and Lidong Bing. 2025. The curse of multi-modalities: Evaluating hallucinations of large multimodal models across language, visual, and audio. Advances in Neural Information Processing Systems, 38
2025
-
[22]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872--13882
2024
-
[23]
Jiaming Li, Jiacheng Zhang, Zequn Jie, Lin Ma, and Guanbin Li. 2025 a . Mitigating hallucination for large vision language model by inter-modality correlation calibration decoding. arXiv preprint arXiv:2501.01926
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023 a . Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 12286--12312
2023
-
[25]
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. 2025 b . Mini-gemini: Mining the potential of multi-modality vision language models. IEEE Transactions on Pattern Analysis and Machine Intelligence
2025
-
[26]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023 b . Evaluating object hallucination in large vision-language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 292--305
2023
-
[27]
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. 2024 a . A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 b . Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296--26306
2024
-
[29]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024 c . Llavanext: Improved reasoning, ocr, and world knowledge
2024
-
[30]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, and 1 others. 2024 d . Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216--233. Springer
2024
-
[31]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in neural information processing systems, 35:2507--2521
2022
-
[32]
Avshalom Manevich and Reut Tsarfaty. 2024. Mitigating hallucinations in large vision-language models (lvlms) via language-contrastive decoding (lcd). In Findings of the Association for Computational Linguistics: ACL 2024, pages 6008--6022
2024
- [33]
-
[34]
Maxime Oquab, Timoth \'e e Darcet, Th \'e o Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, and 1 others. 2023. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Nhi Pham and Michael Schott. 2024. H-pope: Hierarchical polling-based probing evaluation of hallucinations in large vision-language models. arXiv preprint arXiv:2411.04077
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
2021
-
[37]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object hallucination in image captioning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035--4045
2018
-
[38]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317--8326
2019
-
[39]
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. 2024. Massive activations in large language models. arXiv preprint arXiv:2402.17762
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. 2025. Octopus: Alleviating hallucination via dynamic contrastive decoding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 29904--29914
2025
-
[41]
Barrett Tang, Zile Huang, Chengzhi Liu, Qiang Sun, Harry Yang, and Ser-Nam Lim. 2025. Intervening anchor token: Decoding strategy in alleviating hallucinations for mllms. In International Conference on Learning Representations, volume 2025, pages 27745--27776
2025
- [42]
-
[43]
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and 1 others. 2023. Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, and 1 others. 2024 a . Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. 2024 b . Mitigating hallucinations in large vision-language models with instruction contrastive decoding. In Findings of the Association for Computational Linguistics: ACL 2024, pages 15840--15853
2024
-
[46]
Sangmin Woo, Donguk Kim, Jaehyuk Jang, Yubin Choi, and Changick Kim. 2025. Don’t miss the forest for the trees: Attentional vision calibration for large vision language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 1927--1951
2025
-
[47]
Jiulong Wu, Yucheng Shen, Haixin Sun, and Min Cao. 2025. Mitigating hallucinations in large vision-language models via dual contrastive decoding. In Proceedings of the 7th ACM International Conference on Multimedia in Asia, pages 1--8
2025
-
[48]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient streaming language models with attention sinks. In International Conference on Learning Representations, volume 2024, pages 21875--21895
2024
- [49]
-
[50]
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, and 1 others. 2024. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13807--13816
2024
-
[51]
Xiaofeng Zhang, Yihao Quan, Chen Shen, Chaochen Gu, Xiaosong Yuan, Shaotian Yan, Jiawei Cao, Hao Cheng, Kaijie Wu, and Jieping Ye. 2025 a . Shallow focus, deep fixes: Enhancing shallow layers vision attention sinks to alleviate hallucination in lvlms. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3512--3534
2025
-
[52]
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, Dhruba Ghosh, Yuchang Su, Ludwig Schmidt, and Serena Yeung-Levy. 2024. Why are visually-grounded language models bad at image classification? Advances in Neural Information Processing Systems, 37:51727--51753
2024
-
[53]
Zhi Zhang, Srishti Yadav, Fengze Han, and Ekaterina Shutova. 2025 b . Cross-modal information flow in multimodal large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19781--19791
2025
- [54]
-
[55]
Deyao Zhu, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny, and 1 others. 2024. Minigpt-4: Enhancing vision-language understanding with advanced large language models. In International Conference on Learning Representations, volume 2024, pages 18378--18394
2024
-
[56]
Lanyun Zhu, Deyi Ji, Tianrun Chen, Peng Xu, Jieping Ye, and Jun Liu. 2025. Ibd: Alleviating hallucinations in large vision-language models via image-biased decoding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1624--1633
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.