BenHalluEval: A Multi-Task Hallucination Evaluation Framework for Large Language Models on Bengali
Pith reviewed 2026-06-30 10:49 UTC · model grok-4.3
The pith
BenHalluEval introduces the first dedicated hallucination benchmark for Bengali across four tasks using a dual-track protocol.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
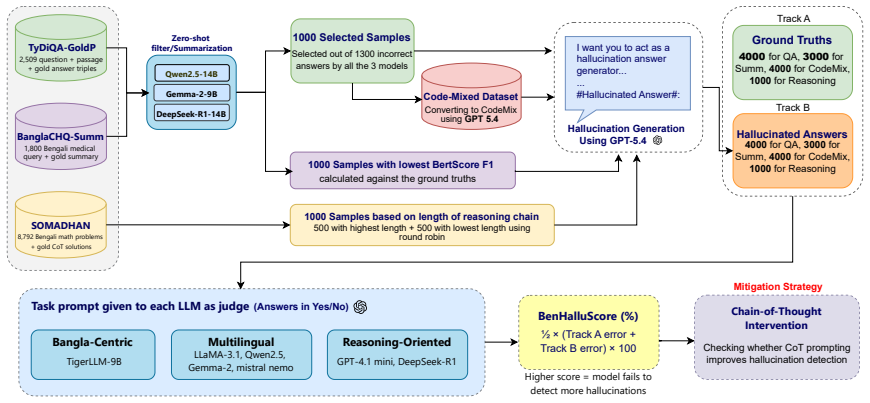
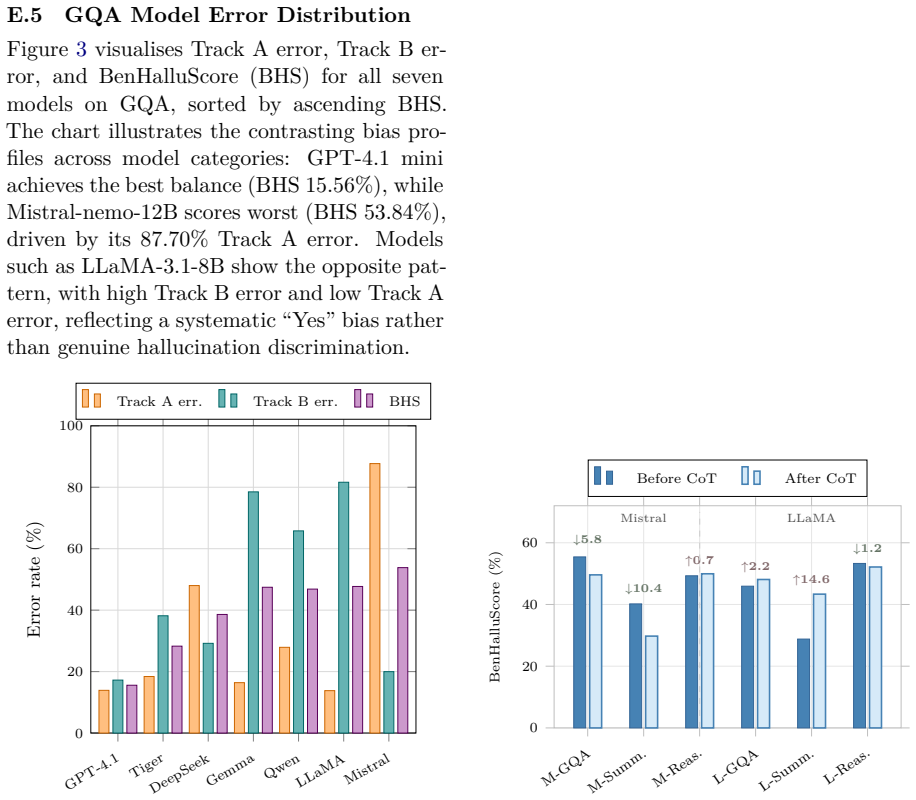
BenHalluEval constructs 12,000 hallucinated candidates using GPT-5.4 across twelve task-specific hallucination types for generative question answering, code-mixed QA, summarization, and reasoning; it evaluates seven LLMs under a dual-track protocol that measures false-positive rate on ground-truth instances in Track A and hallucination detection rate on hallucinated candidates in Track B; the resulting BenHalluScore ranges from 7.72 percent to 55.42 percent across models and tasks, while chain-of-thought prompting shifts response distributions without consistently improving discrimination.
What carries the argument
BenHalluEval dual-track protocol (Track A for false-positive rate on ground-truth, Track B for detection rate on hallucinated candidates) combined with the BenHalluScore calibration metric that jointly penalizes both failure modes.
If this is right
- Models exhibit substantial variation in hallucination calibration across the four tasks.
- Single-track evaluation approaches produce inflated scores from uniform response bias.
- Chain-of-thought prompting shifts response distributions without consistently improving hallucination discrimination.
- Prompting-only strategies are inadequate for low-resource language settings.
Where Pith is reading between the lines
- The same dual-track structure could be applied to other low-resource languages to check whether single-track methods fail there too.
- The generated candidate set could be validated against real model outputs to serve as training data for hallucination detectors.
- Task-specific patterns in the twelve hallucination types might guide targeted mitigation techniques beyond prompting.
Load-bearing premise
The 12,000 hallucinated candidates generated by GPT-5.4 across twelve types are representative of the hallucinations that real LLMs produce when processing Bengali.
What would settle it
Direct comparison of hallucination types and frequencies between the GPT-5.4 generated set and the actual outputs of the seven evaluated LLMs on fresh Bengali inputs from the same task domains.
Figures

read the original abstract
Despite Bengali being the sixth most spoken language in the world, no prior work has systematically evaluated hallucination in large language models (LLMs) for Bengali. We introduce BenHalluEval, a fine-grained hallucination evaluation framework for Bengali covering four tasks: Generative Question Answering (GQA), Bangla-English Code-Mixed QA, Summarization, and Reasoning. We construct 12,000 hallucinated candidates using GPT-5.4 across twelve task-specific hallucination types, drawn from three existing Bengali datasets, and evaluate seven LLMs spanning reasoning-oriented, multilingual, and Bengali-centric categories under a dual-track protocol that independently measures false-positive rate on ground-truth instances (Track A) and hallucination detection rate on hallucinated candidates (Track B). To jointly penalise both failure modes and prevent inflated scores from uniform response bias, we propose BenHalluScore, a dual-track calibration metric that ranges from 7.72% to 55.42% across models and tasks, revealing substantial variation in hallucination calibration. Chain-of-thought prompting, applied as a mitigation strategy, shifts response distributions without consistently improving hallucination discrimination. BenHalluEval establishes the first dedicated hallucination benchmark for Bengali and highlights the inadequacy of single-track and prompting-only evaluation approaches for low-resource language settings. The dataset and code are available at https://anonymous.4open.science/r/BanglaHalluEval-EB77.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BenHalluEval, the first dedicated hallucination evaluation framework for Bengali LLMs across four tasks (Generative QA, Bangla-English code-mixed QA, summarization, reasoning). It constructs 12,000 hallucinated candidates via GPT-5.4 across twelve task-specific types drawn from three existing Bengali datasets, then evaluates seven LLMs (reasoning-oriented, multilingual, Bengali-centric) under a dual-track protocol: Track A measures false-positive rate on ground-truth instances and Track B measures hallucination detection rate on the synthetic candidates. A new dual-track metric, BenHalluScore, is proposed to jointly penalize both failure modes and avoid bias from uniform responses; scores range 7.72–55.42 %. Chain-of-thought prompting is tested as mitigation but shifts distributions without consistent gains in discrimination. The work claims this demonstrates the inadequacy of single-track and prompting-only approaches for low-resource settings and releases the dataset and code.
Significance. If the synthetic candidates prove representative, the work provides the first systematic hallucination benchmark for Bengali and introduces a dual-track calibration metric that addresses a known weakness in prior single-metric evaluations. The explicit release of data and code supports reproducibility. The empirical finding that CoT prompting fails to improve discrimination consistently is a useful negative result for low-resource prompting research.
major comments (2)
- [Data construction] Data construction section: The 12,000 hallucinated candidates are generated exclusively by GPT-5.4, yet no validation (human annotation, overlap statistics, or error-type comparison) is reported showing that these synthetic errors match the distribution, frequency, or linguistic form of hallucinations produced by the seven evaluated models on Bengali inputs. Because Track B and the BenHalluScore calibration rest directly on detection rates against these candidates, this unverified proxy assumption is load-bearing for the central claim that single-track methods are inadequate.
- [Evaluation protocol] Evaluation protocol (§4 or equivalent): The dual-track design and BenHalluScore are well-motivated, but the manuscript does not report per-model, per-task confusion matrices or calibration curves that would allow readers to verify that the reported 7.72–55.42 % range reflects genuine variation rather than artifacts of the GPT-5.4 candidate distribution.
minor comments (2)
- [Metric definition] The abstract states the BenHalluScore range but does not define its exact formula; the main text should include the closed-form expression (including how false-positive and detection rates are combined) in an early section for reproducibility.
- [Task definitions] Task descriptions would benefit from one additional sentence each clarifying how the twelve hallucination types map onto the four tasks, to avoid ambiguity when readers attempt to replicate the candidate generation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where revisions to the manuscript will be made to strengthen the work.
read point-by-point responses
-
Referee: [Data construction] Data construction section: The 12,000 hallucinated candidates are generated exclusively by GPT-5.4, yet no validation (human annotation, overlap statistics, or error-type comparison) is reported showing that these synthetic errors match the distribution, frequency, or linguistic form of hallucinations produced by the seven evaluated models on Bengali inputs. Because Track B and the BenHalluScore calibration rest directly on detection rates against these candidates, this unverified proxy assumption is load-bearing for the central claim that single-track methods are inadequate.
Authors: We acknowledge that the manuscript does not report explicit validation (such as human annotation or direct comparison) demonstrating that the GPT-5.4-generated candidates match the hallucination distributions of the seven evaluated models. The generation follows established hallucination taxonomies drawn from prior literature and is applied at scale to create controlled, task-specific examples, which is a common proxy approach in hallucination benchmarking. Nevertheless, we agree that this assumption merits explicit discussion given its role in the evaluation. In the revision we will add a limitations subsection that (a) states the proxy nature of the synthetic data, (b) reports the distribution of the twelve hallucination types across the 12,000 candidates, and (c) discusses potential implications for generalizability to model-specific error patterns. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol (§4 or equivalent): The dual-track design and BenHalluScore are well-motivated, but the manuscript does not report per-model, per-task confusion matrices or calibration curves that would allow readers to verify that the reported 7.72–55.42 % range reflects genuine variation rather than artifacts of the GPT-5.4 candidate distribution.
Authors: We agree that per-model, per-task confusion matrices and calibration information would improve transparency and allow readers to inspect the underlying Track A and Track B rates. In the revised manuscript we will add these diagnostics as an appendix, including confusion matrices for each of the seven models across the four tasks and, where space permits, calibration curves that plot the relationship between reported BenHalluScore and the raw detection rates. revision: yes
Circularity Check
No circularity in benchmark construction or metric definition
full rationale
The paper constructs 12,000 hallucinated candidates from three existing Bengali datasets using GPT-5.4 across twelve task-specific types, then evaluates seven LLMs under an independent dual-track protocol (Track A on ground-truth, Track B on candidates) and defines BenHalluScore as a calibration metric combining false-positive and detection rates. No quoted step reduces any result to its own inputs by construction, no parameter is fitted on a subset and renamed as a prediction, and no load-bearing claim rests on self-citation or imported uniqueness theorems. The derivation remains self-contained against external datasets and the proposed metric is defined directly from the dual-track measurements without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The twelve task-specific hallucination types cover the relevant failure modes for Bengali LLMs.
Reference graph
Works this paper leans on
-
[1]
XL-sum: Large-scale multilingual abstrac- tive summarization for 44 languages . In Find- ings of the Association for Computational Lin- guistics: ACL-IJCNLP 2021 , pages 4693–4703, Online. Association for Computational Linguis- tics. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Fen...
-
[2]
In Proceedings of the First Workshop on Bangla Language Processing (BLP-2023), pages 85–93, Singapore
BanglaCHQ-summ: An abstractive summarization dataset for medical queries in Bangla conversational speech . In Proceedings of the First Workshop on Bangla Language Processing (BLP-2023), pages 85–93, Singapore. Association for Computational Linguistics. Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. HaluEval: A large-scale hallucin...
2023
-
[3]
In Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers) , pages 3214–3252, Dublin, Ireland
TruthfulQA: Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers) , pages 3214–3252, Dublin, Ireland. Association for Computational Linguistics. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer...
-
[4]
F ActScore: Fine-grained atomic evalua- tion of factual precision in long form text gener- ation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 12076–12100, Singapore. Association for Computational Linguistics. Shrey Pandit, Jiawei Xu, Junyuan Hong, Zhangyang Wang, Tianlong Chen, Kaidi Xu, and Ying Ding...
-
[5]
Addressing Data Scarcity in Bangla Fake News Detection: An LLM-Based Dataset Augmentation Approach
Banglasummeval: Reference-free factual consistency evaluation for bangla summariza- tion. In Proceedings of the Second Workshop on Language Models for Low-Resource Languages (LoResLM 2026), pages 595–608. Nishat Raihan and Marcos Zampieri. 2025. Tigerllm-a family of bangla large language mod- els. In Proceedings of the 63rd Annual Meeting of the Associati...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.