How can embedding models bind concepts?
Pith reviewed 2026-06-28 23:03 UTC · model grok-4.3
The pith
CLIP's binding function is high-complexity, blocking shared generalization across image and text encoders to new concept combinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
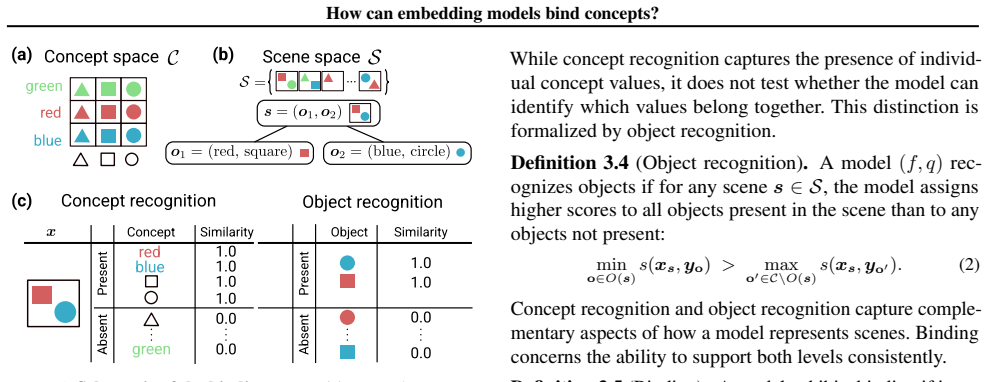
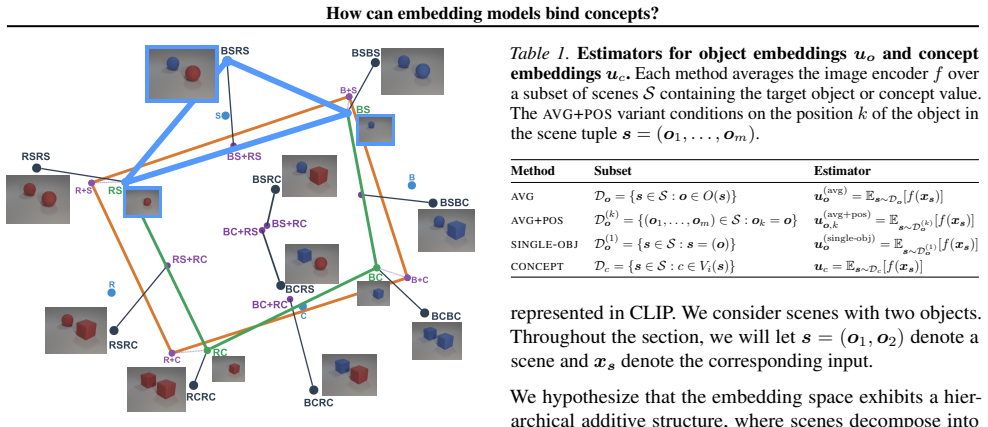
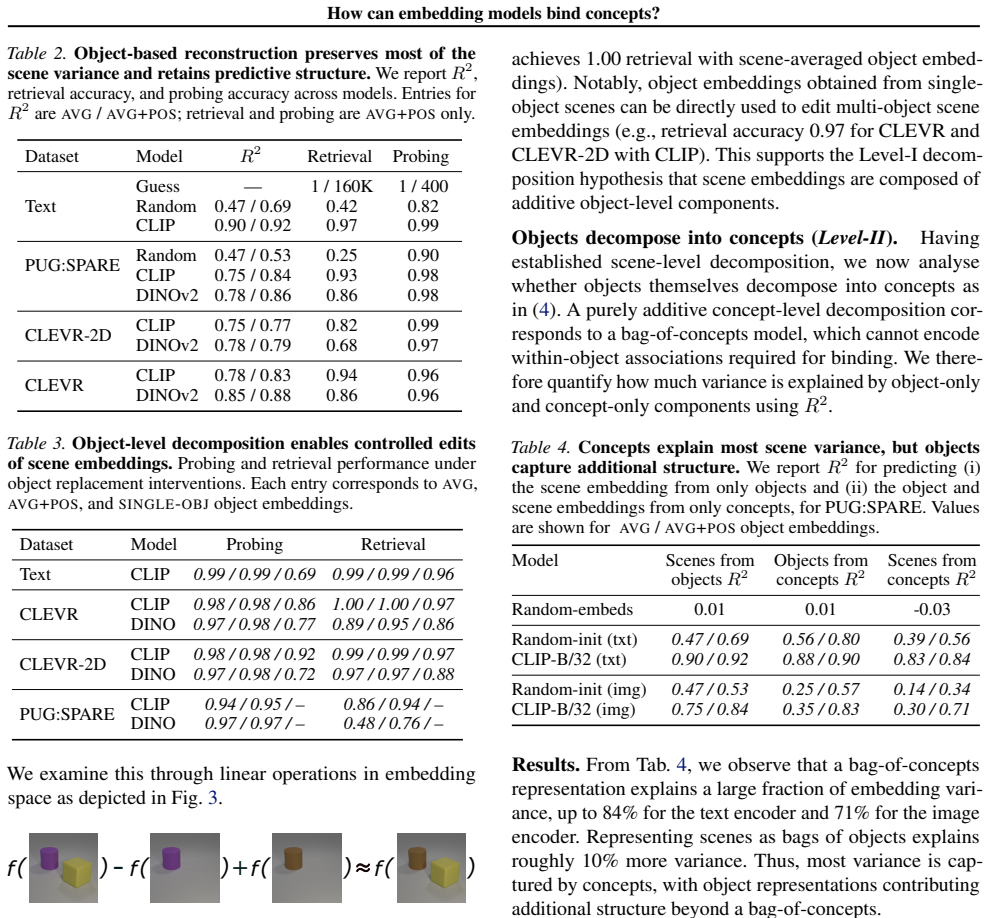
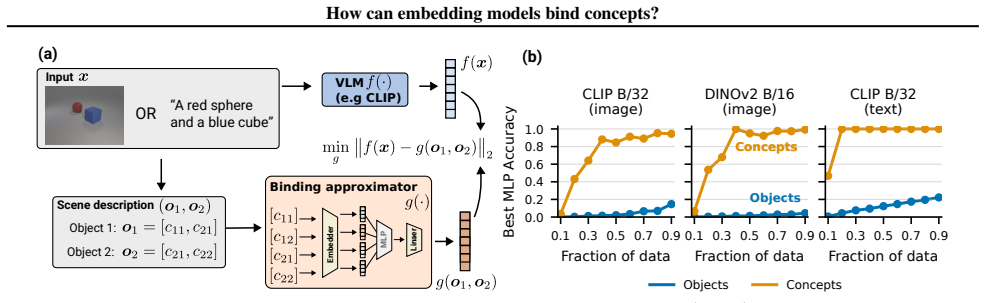
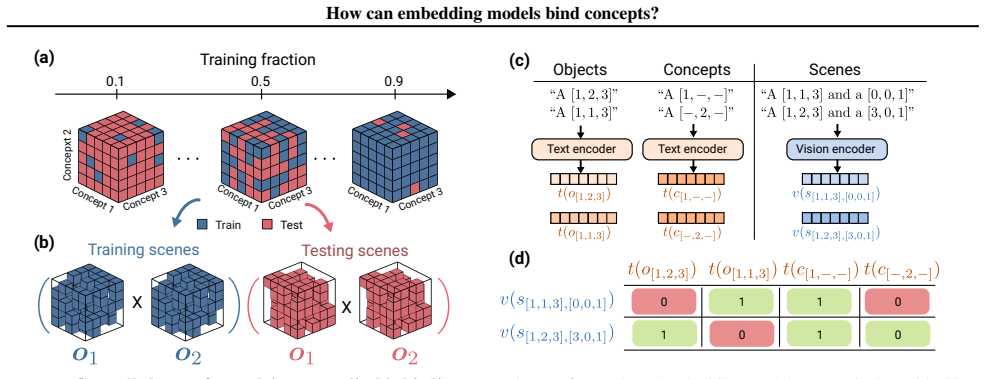
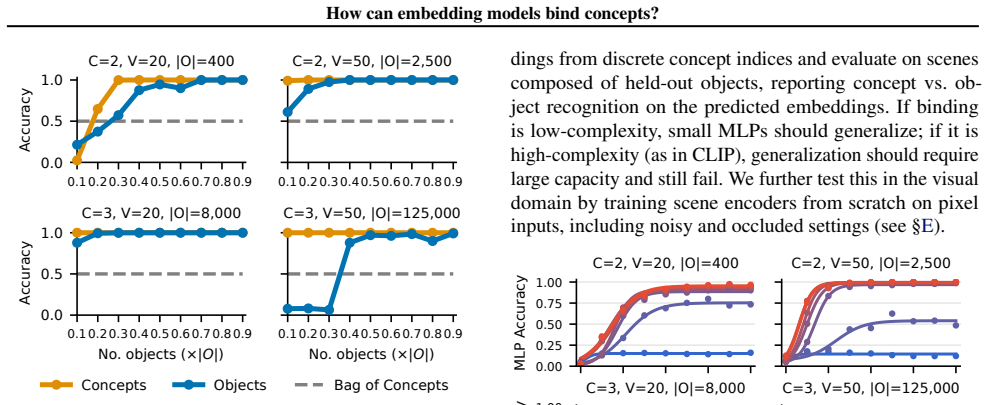
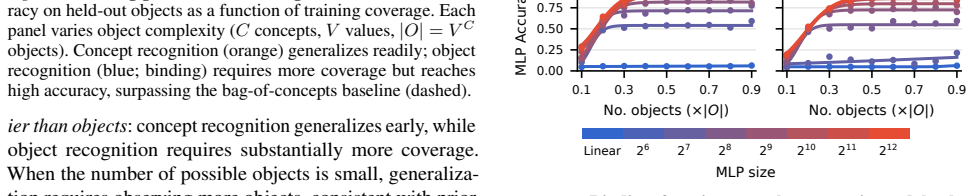
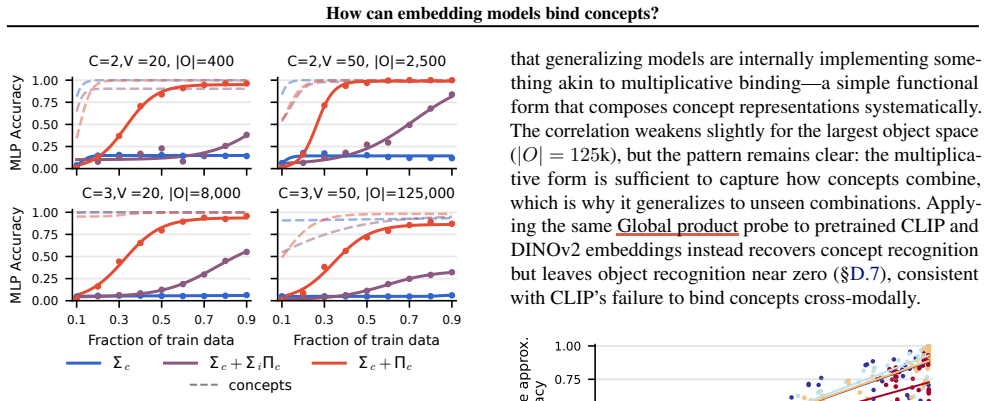
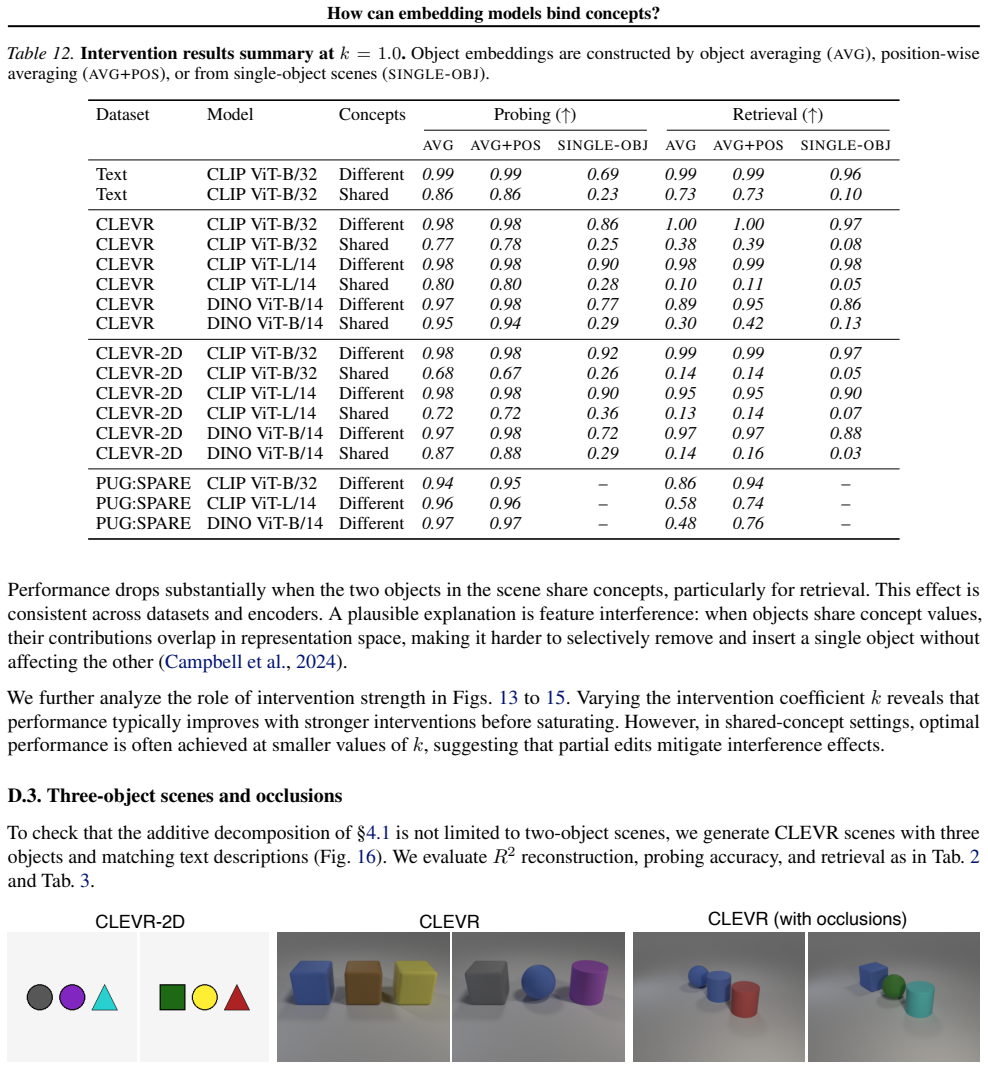
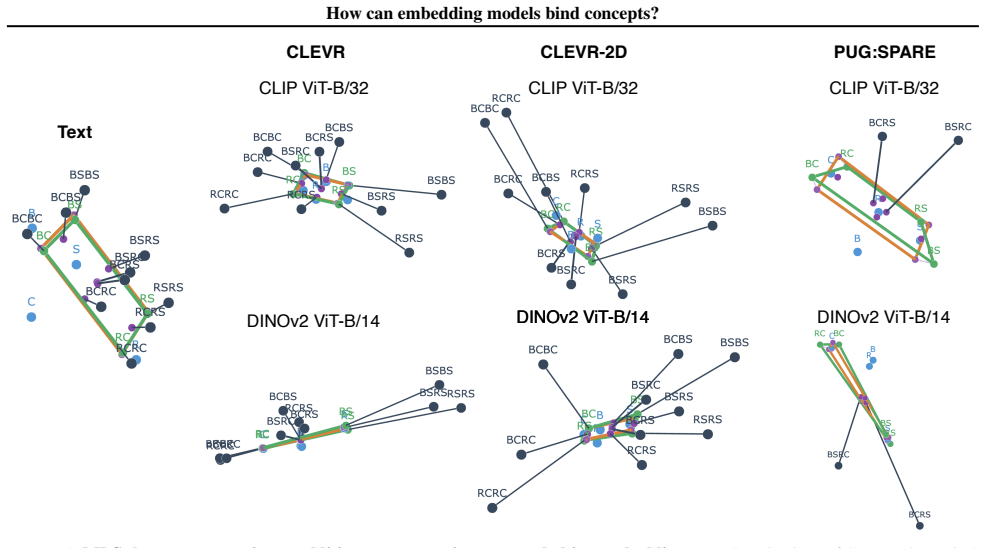
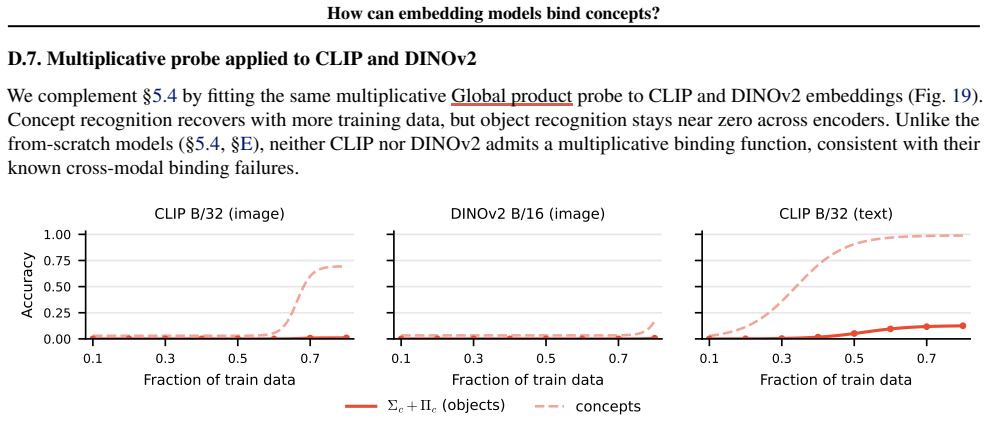
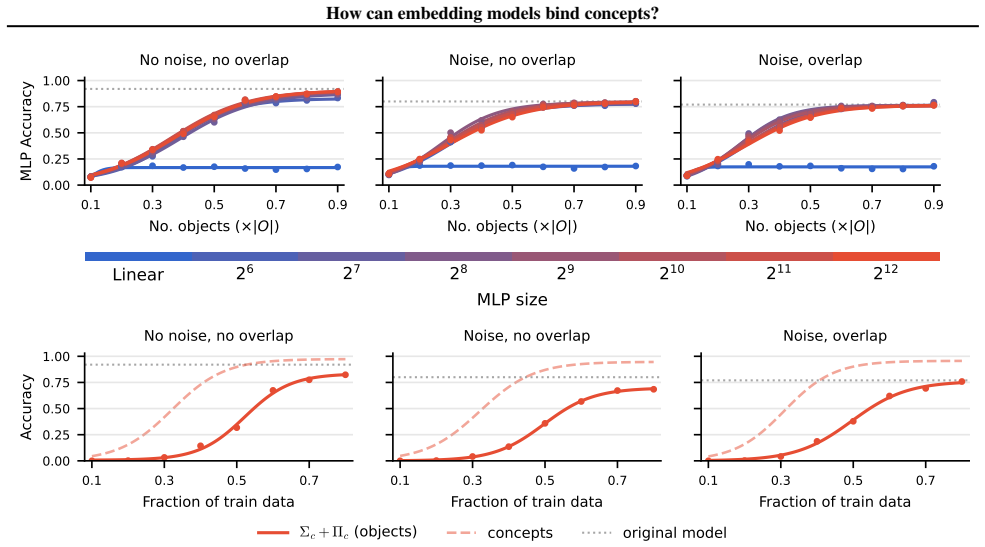
Scene embeddings decompose additively into object representations. CLIP's binding function is high-complexity, which likely prevents the image and text encoders from learning a shared binding mechanism that generalizes to unseen concept combinations. In controlled transformer models trained from scratch, binding generalization emerges with sufficient data coverage through low-complexity binding functions characterized by multiplicative interactions between concepts.
What carries the argument
The binding function that maps input concepts to scene embeddings, analyzed via its additive decomposition and its computational complexity.
Load-bearing premise
The controlled transformer experiments trained from scratch on synthetic scenes are representative of the mechanisms that would appear in large-scale pre-trained models like CLIP when data coverage is increased.
What would settle it
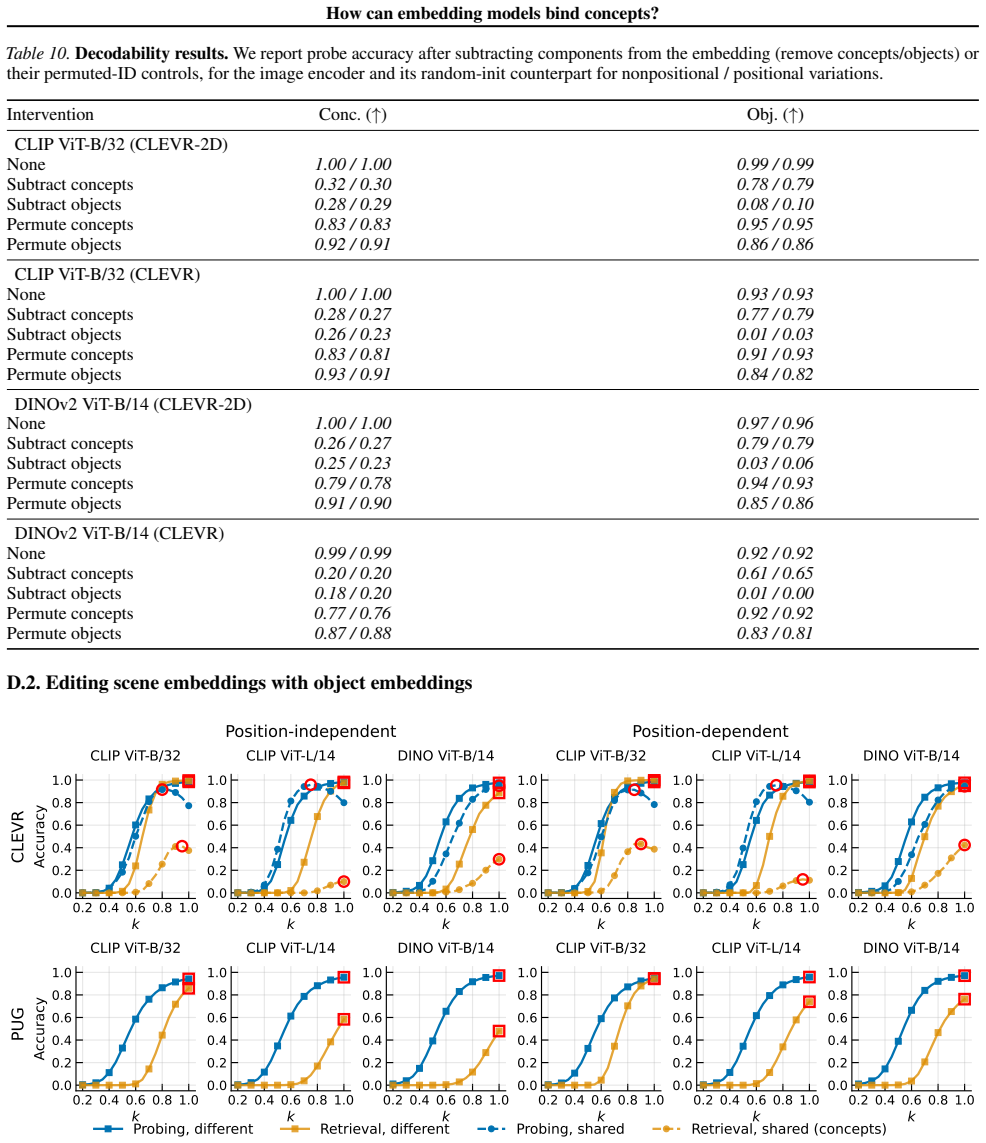
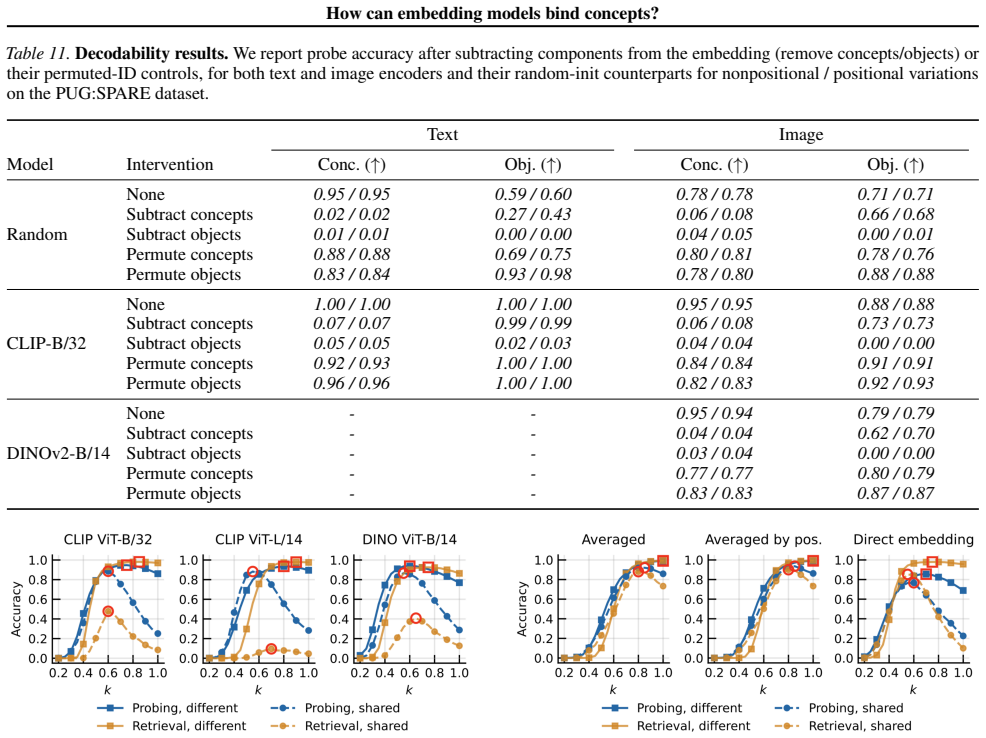
Train a CLIP-scale model on a dataset that systematically increases coverage of concept combinations and check whether its binding function complexity drops and cross-modal binding generalization improves.
Figures





read the original abstract
Humans easily determine which color belongs to which shape in multi-object scenes, an ability known as concept binding. Vision-language embedding models such as CLIP struggle with binding: they recognize individual concepts but fail to represent which concepts form which objects. Although CLIP behaves like a bag-of-concepts model in cross-modal retrieval, object information is recoverable from its image and text embeddings separately. We study this tension through the binding function, which maps concepts to scene embeddings. We find that scene embeddings decompose additively into object representations, explaining why uni-modal probes can recover object information. However, CLIP's binding function is high-complexity, which likely prevents the image and text encoders from learning a shared binding mechanism that generalizes to unseen concept combinations. We then ask whether this limitation is fundamental. We show that it is not. In controlled transformer models trained from scratch, binding generalization emerges with sufficient data coverage. These models learn low-complexity binding functions characterized by multiplicative interactions between concepts, enabling systematic generalization. Code is publicly available at https://github.com/oshapio/binding-concepts-complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines concept binding in vision-language embedding models such as CLIP. It reports that CLIP scene embeddings decompose additively into object representations (allowing uni-modal recovery of objects) yet the binding function itself is high-complexity, which the authors argue prevents the image and text encoders from learning a shared, generalizable binding mechanism for unseen concept combinations. In contrast, controlled transformer models trained from scratch on synthetic scenes learn low-complexity binding functions based on multiplicative interactions; these generalize systematically once data coverage is sufficient. The authors conclude that high-complexity binding is not fundamental and release code at https://github.com/oshapio/binding-concepts-complexity.
Significance. If the controlled-experiment results hold and the representativeness assumption is validated, the work supplies a concrete complexity-based explanation for CLIP's binding failures and demonstrates that low-complexity multiplicative binding is achievable, with direct implications for training objectives that promote systematic generalization. The public code release and use of controlled synthetic data to isolate binding mechanisms are clear strengths that enable reproducibility and targeted follow-up.
major comments (2)
- [Abstract] Abstract, paragraph on controlled models: the claim that high-complexity binding in CLIP 'is not fundamental' is load-bearing for the central thesis yet rests on an untested representativeness assumption; no experiment shows that increasing data coverage under a CLIP-style contrastive objective on real images induces the same low-complexity multiplicative regime or shared encoder binding mechanism.
- [Abstract] Abstract: the additive decomposition result for CLIP embeddings is presented as compatible with high-complexity binding, but the manuscript does not quantify how this decomposition interacts with the reported complexity measures or rule out that real-data statistics force high complexity even under higher coverage.
minor comments (1)
- [Abstract] The abstract states that object information is 'recoverable' from separate encoders but does not specify the probe architecture, training regime, or quantitative recovery metrics; these details are needed for readers to assess the strength of the uni-modal recovery claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on controlled models: the claim that high-complexity binding in CLIP 'is not fundamental' is load-bearing for the central thesis yet rests on an untested representativeness assumption; no experiment shows that increasing data coverage under a CLIP-style contrastive objective on real images induces the same low-complexity multiplicative regime or shared encoder binding mechanism.
Authors: We agree that our experiments do not directly demonstrate the emergence of low-complexity binding under a CLIP-style contrastive objective on real-world images with increased data coverage. The controlled setting with synthetic data and transformers trained from scratch is designed to isolate the binding function and show that low-complexity multiplicative interactions are learnable with sufficient coverage. This supports our claim that high-complexity binding is not fundamental to the problem of concept binding. We will revise the abstract to state that our results indicate high-complexity binding is not fundamental, rather than asserting it definitively based on the controlled models alone. revision: partial
-
Referee: [Abstract] Abstract: the additive decomposition result for CLIP embeddings is presented as compatible with high-complexity binding, but the manuscript does not quantify how this decomposition interacts with the reported complexity measures or rule out that real-data statistics force high complexity even under higher coverage.
Authors: The additive decomposition of scene embeddings into object representations is a linear property that explains why object information can be recovered uni-modally, but it is orthogonal to the complexity of the binding function, which involves how concepts are combined (e.g., via multiplicative interactions). The complexity measures are applied specifically to the binding function. We will update the manuscript to include a more explicit discussion of this distinction, including any relevant quantification where possible, and note that the role of real-data statistics in forcing high complexity is an important direction for future investigation. revision: yes
- Direct experiments training CLIP-style models on real images with varying data coverage to observe the binding complexity regime.
Circularity Check
No circularity; claims rest on independent empirical observations
full rationale
The paper derives its central claims from direct analysis of CLIP embeddings (additive decomposition into object representations) and from training controlled transformers from scratch on synthetic data. No equations or results are shown to reduce by construction to fitted parameters, self-definitions, or prior self-citations. The distinction between high-complexity binding in CLIP and low-complexity multiplicative binding in the controlled models is presented as an observed outcome under varying data coverage, not as a renaming or forced equivalence. The representativeness assumption is stated explicitly but does not create a definitional loop within the reported derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scene embeddings decompose additively into object representations
invented entities (1)
-
binding function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2 Berasi, D., Farina, M., Mancini, M., Ricci, E., and Strisci- uglio, N
URL https://openreview.net/forum? id=3RQ863cRbx. 2 Berasi, D., Farina, M., Mancini, M., Ricci, E., and Strisci- uglio, N. Not only text: Exploring compositionality of visual representations in vision-language models. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pp. 24917–24927, 2025. 2, 4 Bergsma, S., Dey, N. S., Gosal, G., G...
Pith/arXiv arXiv 2025
-
[2]
URL https://openreview.net/forum? id=hKMPz3wkPV. 3, 6 Feng, J. and Steinhardt, J. How do language models bind en- tities in context? InThe Twelfth International Conference on Learning Representations, 2024. URL https:// openreview.net/forum?id=zb3b6oKO77. 2 Feng, J., Russell, S., and Steinhardt, J. Monitoring latent world states in language models with pr...
arXiv 2024
-
[3]
URL https://openreview.net/forum? id=rUK0P1Ejxl. 2 Jarvis, D., Klein, R., Rosman, B., and Saxe, A. M. On the specialization of neural modules, 2024. URL https: //arxiv.org/abs/2409.14981. 2 Jeong, Y ., Uselis, A., Laina, I., Oh, S. J., and Rohrbach, A. When do diffusion models learn to generate multiple objects?, 2026. URL https://arxiv.org/abs/ 2605.0027...
-
[4]
Compositional risk minimiza- tion, 2025
2 Mahajan, D., Pezeshki, M., Arnal, C., Mitliagkas, I., Ahuja, K., and Vincent, P. Compositional risk minimiza- tion, 2025. URL https://arxiv.org/abs/2410. 06303. 2 Montero, M. L., Ludwig, C. J., Costa, R. P., Malhotra, G., and Bowers, J. The role of disentanglement in generalisa- tion. InInternational Conference on Learning Represen- tations, 2021. URL h...
Pith/arXiv arXiv 2025
-
[5]
URL https://proceedings.mlr.press/ v139/radford21a.html. 1, 7, 14 Ren, Y . and Sutherland, D. J. Understanding simplicity bias towards compositional mappings via learning dynamics. arXiv preprint, 2024. 25 Schott, L., von K¨ugelgen, J., Tr¨auble, F., et al. Visual rep- resentation learning does not generalize strongly within the same domain, 2022. URL htt...
arXiv 2024
-
[6]
2 Uselis, A., Dittadi, A., and Oh, S
URL https://openreview.net/forum? id=M2WMUuwoh5. 2 Uselis, A., Dittadi, A., and Oh, S. J. Compositional general- ization requires linear, orthogonal representations in vi- sion embedding models, 2026. URL https://arxiv. org/abs/2602.24264. 2 Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attent...
arXiv 2026
-
[7]
infinite
1, 2 12 How can embedding models bind concepts? Appendix A Notation summary 14 B Details on the controlled models 14 B.1 Scene space and tokenization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.2 Encoders . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 B.3 ...
2021
-
[8]
We collect the unique concept-value tokens that appear in the batch (excluding SOO/EOO/EOS/PAD), subsample up to num concept values take max, and tokenize each as a concept query
Concept retrieval.Concept queries specify a single concept value. We collect the unique concept-value tokens that appear in the batch (excluding SOO/EOO/EOS/PAD), subsample up to num concept values take max, and tokenize each as a concept query
-
[9]
a purple square and a gray circle
Object retrieval.Object queries specify a full object. We parse object blocks from the tokenized scenes, take the set of unique objects present in the batch, subsample up to 1024, and tokenize each as an object query. We then augment the query set with hard negatives (random/perturbed objects and attribute swaps). Concept queries probe whether the model c...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.