Skill Reuse as Compression in Agentic RL
Pith reviewed 2026-06-28 22:46 UTC · model grok-4.3
The pith
Agents generalize better when their successful trajectories are decomposed into a small set of reusable abstract patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
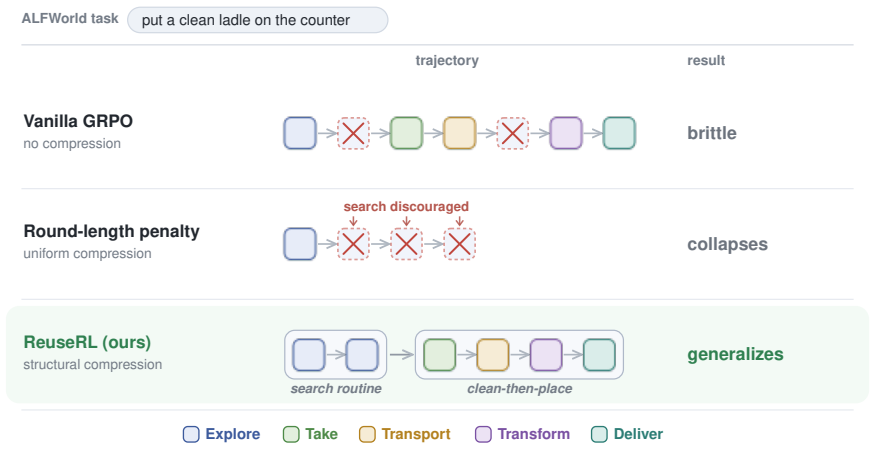
By extracting a shared skill dictionary from successful trajectories and augmenting the RL objective with a segmentation cost that penalizes idiosyncratic behaviors, ReuseRL formalizes skill reuse as compression under the minimum description length principle and proves a corresponding PAC-Bayes generalization bound.
What carries the argument
The segmentation cost based on the shared skill dictionary extracted from successful trajectories, which is added to the RL objective to enforce compressibility.
If this is right
- Improved in-distribution and out-of-distribution success rates in agentic tasks.
- Explicit penalization of non-reusable trajectory patterns leads to more generalizable policies.
- Applicability across diverse environments including ALFWorld, TextWorld-Cooking, and Countdown-Stepwise.
- Grounding in MDL provides a theoretical justification via the PAC-Bayes bound.
Where Pith is reading between the lines
- If the compression approach holds, it could extend to encouraging reusable skills in non-agent reinforcement learning settings.
- The skill dictionary might be learnable online during training rather than extracted only from successful trajectories.
- Similar compression penalties could apply to other sequence modeling tasks outside RL.
Load-bearing premise
That adding the segmentation cost from the skill dictionary to the RL objective will produce the claimed generalization improvement as justified by the PAC-Bayes bound.
What would settle it
Observing no improvement in out-of-distribution success when the segmentation cost is included, or when the extracted dictionary fails to reduce the description length of trajectories.
Figures
read the original abstract
Large language model agents trained with reinforcement learning (RL) often learn brittle, task-specific shortcuts. We hypothesize that agents generalize better when their successful trajectories are structurally compressible, decomposed into a small set of reusable abstract patterns. To formalize this, we introduce ReuseRL, which grounds agentic RL in the Minimum Description Length (MDL) principle. ReuseRL extracts a shared skill dictionary from successful trajectories and augments the RL objective with a segmentation cost, explicitly penalizing idiosyncratic behaviors that encode poorly. We prove a PAC-Bayes generalization bound for this compression penalty. Across ALFWorld, TextWorld-Cooking, and Countdown-Stepwise, ReuseRL improves in- and out-of-distribution success over vanilla GRPO and strong round-length baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReuseRL for agentic RL, grounding training in the Minimum Description Length principle. It extracts a shared skill dictionary from successful trajectories, augments the RL objective (specifically GRPO) with a segmentation cost that penalizes non-compressible behaviors, proves a PAC-Bayes generalization bound for the compression penalty, and reports improved in- and out-of-distribution success rates on ALFWorld, TextWorld-Cooking, and Countdown-Stepwise relative to vanilla GRPO and round-length baselines.
Significance. If the PAC-Bayes derivation is valid and the empirical gains are reproducible with proper statistical controls, the work offers a principled compression-based approach to mitigating brittle shortcuts in LLM agents, linking MDL directly to RL objectives in a way that could generalize across domains.
major comments (3)
- [Abstract] Abstract: the claim that a PAC-Bayes bound is proved cannot be assessed because no derivation steps, assumptions, or explicit form of the bound are supplied; this is load-bearing for the central theoretical contribution.
- [Abstract] Abstract / Method (implied): the segmentation cost derived from the shared skill dictionary and its precise addition to the GRPO objective are not specified, so it is impossible to verify whether the claimed generalization improvement follows from the bound or reduces to a fitted hyperparameter.
- [Abstract] Abstract: no dataset details, number of runs, or statistical reporting (e.g., means, variances, or significance tests) are provided for the reported success-rate improvements, undermining the empirical claim.
minor comments (1)
- [Abstract] Abstract: the definition of out-of-distribution splits and the exact baseline implementations (round-length) should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each point below and propose revisions to improve clarity while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that a PAC-Bayes bound is proved cannot be assessed because no derivation steps, assumptions, or explicit form of the bound are supplied; this is load-bearing for the central theoretical contribution.
Authors: The full derivation, including all assumptions (e.g., bounded loss and prior over policies) and the explicit PAC-Bayes bound form, appears in Section 4. The abstract is intentionally concise, but we agree it should better signal the result. We will revise the abstract to include a one-sentence high-level statement of the bound and its key assumptions. revision: yes
-
Referee: [Abstract] Abstract / Method (implied): the segmentation cost derived from the shared skill dictionary and its precise addition to the GRPO objective are not specified, so it is impossible to verify whether the claimed generalization improvement follows from the bound or reduces to a fitted hyperparameter.
Authors: Section 3.1 defines the segmentation cost as the MDL length of the trajectory under the extracted skill dictionary; Section 3.2 shows its exact additive term in the GRPO objective (Equation 5). The bound in Section 4 is derived directly from this term. We will add a brief clause to the abstract describing the cost and its placement in the objective. revision: yes
-
Referee: [Abstract] Abstract: no dataset details, number of runs, or statistical reporting (e.g., means, variances, or significance tests) are provided for the reported success-rate improvements, undermining the empirical claim.
Authors: Full experimental details (environments, 5 random seeds, means and standard deviations) are reported in Section 5 and the appendix. The abstract summarizes only the headline result. We will append a short clause noting the number of runs and that improvements are reported with standard deviations. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract and available description claim a PAC-Bayes bound and MDL-based segmentation cost added to the GRPO objective, but supply no equations, fitting procedures, or self-citations that reduce any prediction to its inputs by construction. No load-bearing step can be quoted or shown to collapse into a fitted parameter or prior self-result. The central claim therefore remains independent of the inspected text and is consistent with external benchmarks (ALFWorld, TextWorld, Countdown) rather than forced by internal redefinition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Realizable abstractions: Near-optimal hi- erarchical reinforcement learning.arXiv preprint arXiv:2512.04958. Marc-Alexandre Côté, Akos Kádár, Xingdi Yuan, Ben Kybartas, Tavian Barnes, Emery Fine, James Moore, Matthew Hausknecht, Layla El Asri, Mahmoud Adada, and 1 others. 2018. Textworld: A learning environment for text-based games. InWorkshop on Computer...
-
[2]
InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems
Group-in-group policy optimization for LLM agent training. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems. Philip Gage. 1994. A new algorithm for data compres- sion.C Users J., 12(2):23–38. Peter D. Grünwald. 2007.The Minimum Description Length Principle. MIT Press. Yiding Jiang, Evan Liu, Benjamin Eysenbach, J Zico Kolter...
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Neural machine translation of rare words with subword units. InProceedings of the 54th annual meeting of the association for computational linguis- tics (volume 1: long papers), pages 1715–1725. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, and 1 others. 2024. Deepseekmath: Pushing the limits ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Artificial Intelligence, 112(1):181–211
Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 112(1):181–211. Borui Wang, Kathleen McKeown, and Rex Ying. 2025a. Dystil: Dynamic strategy induction with large lan- guage models for reinforcement learning.arXiv preprint arXiv:2505.03209. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Man- d...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InICLR. OpenReview.net. Danlong Yuan, Tian Xie, Shaohan Huang, Zhuocheng Gong, Huishuai Zhang, Chong Luo, Furu Wei, and Dongyan Zhao. 2026. ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Jesse Zhang, Karl Pertsch, Jiefan Yang, and Joseph Lim
Skillvla: Tackling combinatorial diversity in dual-arm manipulation via skill reuse.arXiv preprint arXiv:2603.03836. Jesse Zhang, Karl Pertsch, Jiefan Yang, and Joseph Lim
-
[7]
heat a potato and place it on the counter
Minimum description length skills for acceler- ated reinforcement learning. InSelf-Supervision for Reinforcement Learning Workshop - ICLR 2021. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, page...
2021
-
[8]
Nothing-happens
induce the same unordered role pair. With four operators and six unordered role pairs from {large,near_target,small} , this yields4×6 = 24 operation skills, plus ROLLBACKand RESET, for a total of26. Worked example.Puzzle.{80,2,28,1}with target Ttgt = 54. Heren >59.4islarge,|n−54| ≤5.4is near_target, and all remaining values aresmall. Trajectory with roles...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.