SPECTRA: Synthetic IR Test Collections with Relevance Oracles and Controlled Distractor Diagnostics
Pith reviewed 2026-06-28 20:35 UTC · model grok-4.3
The pith
SPECTRA generates reproducible synthetic IR corpora up to 60,000 documents with controllable distractors and deterministic relevance labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
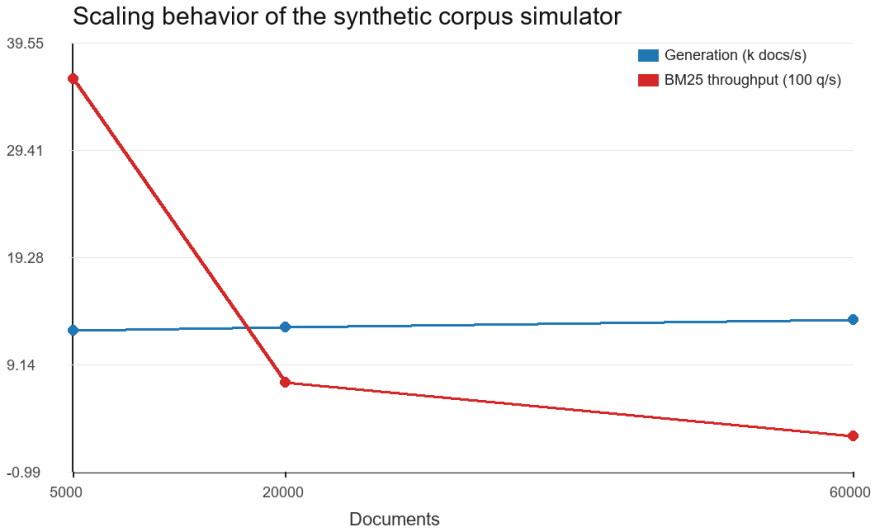
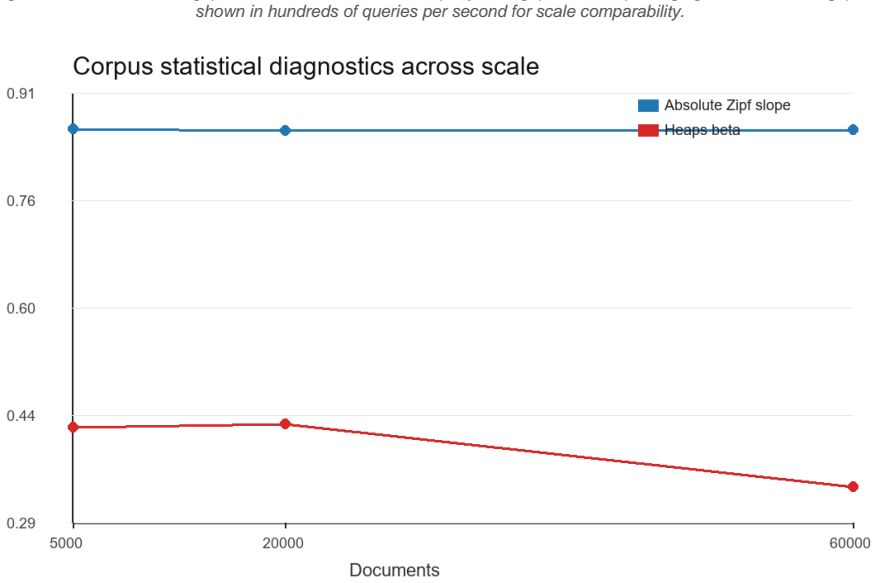
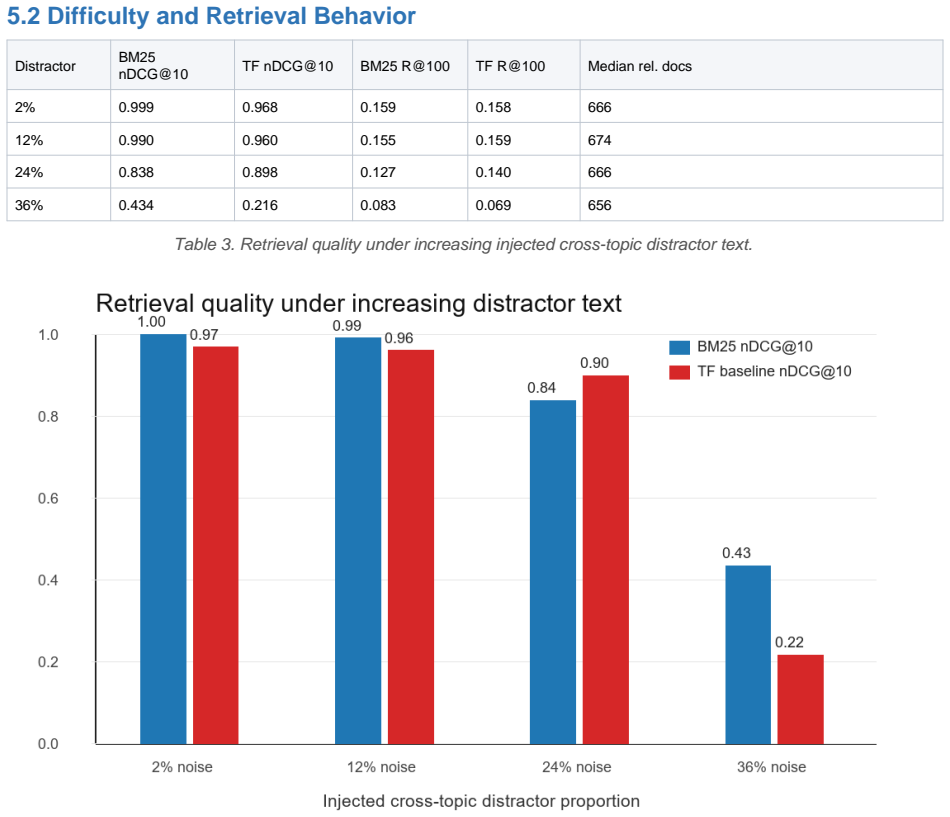
SPECTRA separates latent topical structure, surface text realization, metadata controls, query intent generation, and deterministic relevance oracles to create synthetic corpora and graded relevance labels. The single-process prototype produced collections of up to 60,000 documents and 9.61 million tokens while preserving controllable long-tail vocabulary growth. Generation ran at roughly 12,000 to 14,000 documents per second, estimated Zipf slopes remained near 0.86, and BM25 nDCG@10 fell from 1.00 at 2 percent distractors to 0.43 at 36 percent distractors.
What carries the argument
Separation of latent topical structure, surface text realization, and deterministic relevance oracles.
If this is right
- Controlled increases in cross-topic distractor text can systematically lower BM25 nDCG@10 from 1.00 to 0.43.
- Generation speed stays close to linear up to at least 60,000 documents.
- Vocabulary growth and Zipf slopes near 0.86 can be maintained while relevance labels remain deterministic.
- Such collections can expose retrieval scaling and failure modes before human-judged collections are constructed.
Where Pith is reading between the lines
- The same separation approach could be reused to create test sets for neural rankers or for query-routing experiments.
- Reproducible collections with known distractor levels might let different groups compare failure modes on identical data.
- If the relevance oracles capture the main failure modes of current systems, the collections could serve as an early filter before any human annotation begins.
Load-bearing premise
The synthetic generation process produces statistical properties and relevance relationships sufficiently representative of real-world corpora.
What would settle it
A side-by-side run in which the same retrieval systems show markedly different relative rankings on SPECTRA collections versus matched real-world collections with the same query set.
Figures
read the original abstract
Scalable information retrieval testing needs corpora that are large enough to stress index construction, ranking latency, query routing, and evaluation tooling, yet human-judged test collections remain expensive and may be unavailable when documents are private or still under design. This paper introduces SPECTRA, a reproducible framework for generating synthetic text corpora and retrieval test collections through a separation of latent topical structure, surface text realization, metadata controls, query intent generation, and deterministic relevance oracles. The framework is intended as a diagnostic complement to Cranfield-style and TREC-style evaluation, not as a replacement for human assessment. A single-process Python prototype generated corpora up to 60,000 documents and 9.61 million tokens while preserving controllable long-tail vocabulary growth and producing graded relevance labels for 96 queries. In the local simulation study, generation remained close to linear at roughly 12K to 14K documents per second, estimated Zipf slopes stayed near 0.86 in absolute value, and increasing cross-topic distractor text reduced BM25 nDCG@10 from 1.00 at 2% distractors to 0.43 at 36% distractors. These results show that lightweight synthetic corpora can expose retrieval-system scaling and failure modes before costly collection construction begins.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the SPECTRA framework for generating synthetic information retrieval test collections. It separates latent topical structure, surface text realization, metadata controls, query intent generation, and deterministic relevance oracles to produce reproducible corpora up to 60,000 documents with controllable properties. The prototype achieves generation speeds of 12K-14K documents per second, maintains Zipf slopes near 0.86, and demonstrates that increasing cross-topic distractor text reduces BM25 nDCG@10 from 1.00 at 2% distractors to 0.43 at 36% distractors for 96 queries. The framework is presented as a diagnostic complement to traditional human-judged collections.
Significance. If the generated corpora capture relevant statistical and relevance properties, SPECTRA could enable scalable, reproducible diagnostics for IR system scaling, latency, and failure modes prior to real collection construction. Strengths include the explicit component separation, linear generation scaling, controllable parameters (distractor percentage), and the clear positioning as a complement rather than replacement. The internal consistency of the distractor-nDCG simulation supports the narrow reproducibility claim.
major comments (1)
- [Simulation Study] Simulation Study: the diagnostic utility claim rests on the synthetic data being sufficiently representative; however, beyond the reported Zipf slope and the controlled distractor effect, no comparisons are provided to real collections (e.g., term co-occurrence, document length distributions, or label consistency with TREC-style judgments), leaving the broader applicability preliminary.
minor comments (1)
- [Abstract] Abstract: the statement 'estimated Zipf slopes stayed near 0.86 in absolute value' would benefit from explicit clarification on whether the reported value is the absolute value of the fitted exponent and how the estimation was performed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment below, agreeing that additional discussion of limitations is warranted while defending the paper's intended scope as a controlled diagnostic complement rather than a statistical replica of real collections.
read point-by-point responses
-
Referee: [Simulation Study] Simulation Study: the diagnostic utility claim rests on the synthetic data being sufficiently representative; however, beyond the reported Zipf slope and the controlled distractor effect, no comparisons are provided to real collections (e.g., term co-occurrence, document length distributions, or label consistency with TREC-style judgments), leaving the broader applicability preliminary.
Authors: We acknowledge the validity of this observation: the manuscript reports only the Zipf slope match and the controlled distractor-nDCG effect, without explicit side-by-side statistics against real corpora. This choice follows from the framework's design goals. SPECTRA separates latent structure from surface realization to enable precise control over distractors, vocabulary growth, and oracle labels; matching any particular real collection's term co-occurrence or length distribution would require anchoring to a specific corpus and could undermine the reproducibility and generality claims. Label consistency with TREC-style judgments is not a direct target because our graded labels are produced deterministically from the latent topic assignments rather than from human assessors. We will revise the discussion section to explicitly state these scope limitations, clarify that the current results demonstrate internal validity and parameter sensitivity for diagnostic use, and note that broader statistical fidelity comparisons remain future work. This keeps the contribution focused while addressing the applicability concern. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a generative framework for synthetic corpora and reports direct simulation outputs (e.g., nDCG@10 as a function of explicit distractor percentages) without any fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations. All reported statistics follow from the stated generative process and deterministic oracles; the chain is self-contained against external benchmarks and does not reduce any claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- distractor percentage
- estimated Zipf slope
axioms (1)
- domain assumption Separation of latent topical structure from surface text realization allows independent control over content and form.
Reference graph
Works this paper leans on
-
[1]
The Cranfield tests on index language devices,
C. W. Cleverdon, "The Cranfield tests on index language devices," Aslib Proceedings, vol. 19, no. 6, pp. 173-194, 1967. doi:10.1108/eb050097
-
[2]
E. M. Voorhees and D. K. Harman, Eds., TREC: Experiment and Evaluation in Information Retrieval. Cambridge, MA: MIT Press, 2005
2005
-
[3]
The 34th Text REtrieval Conference (TREC 2025),
I. Soboroff and G. Awad, "The 34th Text REtrieval Conference (TREC 2025)," NIST Special Publication 1348, 2026. doi:10.6028/NIST.SP.1348
-
[4]
S. Robertson and H. Zaragoza, "The probabilistic relevance framework: BM25 and beyond," Foundations and Trends in Information Retrieval, vol. 3, no. 4, pp. 333-389, 2009. doi:10.1561/1500000019
-
[5]
Cumulated gain-based evaluation of IR techniques,
K. Jarvelin and J. Kekalainen, "Cumulated gain-based evaluation of IR techniques," ACM Transactions on Information Systems, vol. 20, no. 4, pp. 422-446, 2002. doi:10.1145/582415.582418
-
[6]
Latent Dirichlet allocation,
D. M. Blei, A. Y. Ng, and M. I. Jordan, "Latent Dirichlet allocation," Journal of Machine Learning Research, vol. 3, pp. 993-1022, 2003
2003
-
[7]
Hawking, B
D. Hawking, B. von Billerbeck, P. Thomas, and N. Craswell, Simulating Information Retrieval Test Collections. Morgan & Claypool, 2020
2020
-
[8]
R. S. Puranik, "Efficient generation and simulation of synthetic text corpora for scalable information retrieval testing," in 2025 IEEE 2nd International Conference on Information Technology, Electronics and Intelligent Communication Systems (ICITEICS), Bengaluru, India, 2025. doi:10.1109/ICITEICS64870.2025.11341224
-
[9]
Synthetic test collections for retrieval evaluation,
H. A. Rahmani, N. Craswell, E. Yilmaz, B. Mitra, and D. Campos, "Synthetic test collections for retrieval evaluation," SIGIR 2024, arXiv:2405.07767, 2024
-
[10]
SynDL: A large-scale synthetic test collection for passage retrieval,
H. A. Rahmani, X. Wang, E. Yilmaz, N. Craswell, B. Mitra, and P. Thomas, "SynDL: A large-scale synthetic test collection for passage retrieval," WWW 2025 resource paper, arXiv:2408.16312, 2025
-
[11]
M. D. Turkmen, M. Kutlu, B. Altun, and G. Cosgun, "GenTREC: The first test collection generated by large language models for evaluating information retrieval systems," arXiv:2501.02408, 2025
-
[12]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
N. Thakur, N. Reimers, A. Ruckle, A. Srivastava, and I. Gurevych, "BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models," arXiv:2104.08663, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
P. Bajaj et al., "MS MARCO: A human generated machine reading comprehension dataset," arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
J. Lin, X. Ma, S.-C. Lin, J.-H. Yang, R. Pradeep, and R. Nogueira, "Pyserini: An easy-to-use Python toolkit to support replicable IR research with sparse and dense representations," SIGIR 2021, arXiv:2102.10073, 2021
-
[15]
Anserini: Reproducible ranking baselines using Lucene,
P. Yang, H. Fang, and J. Lin, "Anserini: Reproducible ranking baselines using Lucene," ACM Journal of Data and Information Quality, vol. 10, no. 4, 2018
2018
-
[16]
InPars: Data augmentation for information retrieval using large language models,
L. Bonifacio, H. Abonizio, M. Fadaee, and R. Nogueira, "InPars: Data augmentation for information retrieval using large language models," arXiv:2202.05144, 2022
-
[17]
Promptagator: Few-shot dense retrieval from 8 examples,
Z. Dai et al., "Promptagator: Few-shot dense retrieval from 8 examples," ICLR 2023, arXiv:2209.11755, 2022
-
[18]
Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho
R. Nogueira, W. Yang, J. Lin, and K. Cho, "Document expansion by query prediction," arXiv:1904.08375, 2019
-
[19]
Harmonizing metadata of language resources for enhanced querying and accessibility,
Z. Liang, "Harmonizing metadata of language resources for enhanced querying and accessibility," in 2024 5th International Conference on Computers and Artificial Intelligence Technology (CAIT), pp. 642-650. IEEE, 2024. Preprint 9
2024
-
[20]
Efficient representations for high-cardinality categorical variables in machine learning,
Z. Liang, "Efficient representations for high-cardinality categorical variables in machine learning," in 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS), pp. 1-11. IEEE, 2025
2025
-
[21]
Automating date format detection for data visualization,
Z. Liang, "Automating date format detection for data visualization," in 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS), pp. 756-764. IEEE, 2025
2025
-
[22]
Enhanced estimation techniques for certified radii in randomized smoothing,
Z. Liang, "Enhanced estimation techniques for certified radii in randomized smoothing," in 2025 8th International Conference on Artificial Intelligence and Big Data (ICAIBD), pp. 375-384. IEEE, 2025
2025
-
[23]
G. K. Zipf, Human Behavior and the Principle of Least Effort. Cambridge, MA: Addison-Wesley, 1949
1949
-
[24]
H. S. Heaps, Information Retrieval: Computational and Theoretical Aspects. Orlando, FL: Academic Press, 1978
1978
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.