A Tight Theory of Error Feedback Algorithms in Distributed Optimization
Pith reviewed 2026-06-28 23:05 UTC · model grok-4.3
The pith
Optimal step sizes and tailored Lyapunov functions deliver tight convergence rates for EF and EF21 error feedback that hold for any number of agents and recover single-agent optima.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the Error Feedback (EF) and Error Feedback 21 (EF21) algorithms, there exist choices of step sizes and Lyapunov functions that produce tight convergence bounds. These bounds are independent of the number of agents and recover the known optimal rates available in the single-agent regime under the problem assumptions of smoothness, (strong) convexity, and properties of the compression operator.
What carries the argument
Optimal Lyapunov functions constructed separately for EF and for EF21, together with their corresponding optimal step sizes, that certify tight convergence independent of agent count.
If this is right
- Convergence rates for both EF and EF21 match the best single-agent rates and do not depend on the number of agents.
- The analyses apply uniformly to any number of agents under the same assumptions used for the single-agent case.
- Optimal step sizes exist that realize these tight bounds for each method.
- The results hold for both the classic EF method and the EF21 variant.
Where Pith is reading between the lines
- Error-feedback mechanisms can be deployed in large-scale distributed systems without incurring an extra rate penalty relative to the centralized setting.
- Further rate improvements for these specific algorithms would require relaxing the underlying smoothness or compression assumptions rather than changing the number of agents.
- The existence of optimal Lyapunov functions for each variant separately suggests that direct comparisons between EF and EF21 can now be made on equal footing using the same proof technique.
Load-bearing premise
Optimal Lyapunov functions can be identified that achieve the claimed tightness under the stated smoothness, convexity, and compression assumptions.
What would settle it
A concrete computation or experiment showing that the convergence rate of EF or EF21 worsens measurably when the number of agents increases, even when the derived optimal step sizes are used.
Figures
read the original abstract
Communication costs are a major bottleneck in distributed learning and first-order optimization. A common approach to alleviate this issue is to compress the gradient information exchanged between agents. However, such compression typically degrades the convergence guarantees of gradient-based methods. Error feedback mechanisms provide a simple and computationally cheap remedy for this issue, but numerous variants have been proposed, and their relative performance remains poorly understood. This paper provides tight convergence analyses for two of the main error-feedback algorithms from the literature, the classic Error Feedback method (EF) and Error Feedback 21 (EF21), by identifying optimal step-size choices and constructing optimal Lyapunov functions tailored to each method. The results hold independently of the number of agents and recover the known best guarantees possible in the single-agent regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to deliver tight convergence analyses for the classic Error Feedback (EF) and Error Feedback 21 (EF21) algorithms in distributed first-order optimization under gradient compression. It does so by deriving optimal step-size schedules and constructing method-specific optimal Lyapunov functions; the resulting rates are independent of the number of agents and recover the best-known single-agent guarantees under standard smoothness/convexity assumptions on the objective and standard properties of the compression operator.
Significance. If the claimed tightness holds, the work supplies a precise comparative theory for two widely used error-feedback schemes, removing ambiguity about their relative merits and confirming that communication compression need not degrade the optimal rate when the right Lyapunov function and step-size are chosen. This is a useful theoretical contribution for the design of communication-efficient distributed methods.
minor comments (3)
- [Abstract] The abstract states that the rates are 'tight' and 'recover the known best guarantees' but does not display the explicit rates or the single-agent reference rates they match; adding these (even as a short table) would strengthen the claim.
- [Section 2 (Preliminaries)] Notation for the compression operator (e.g., its bias and variance parameters) and the precise smoothness/convexity assumptions should be stated once in a dedicated 'Assumptions' paragraph before the main theorems to avoid repeated inline definitions.
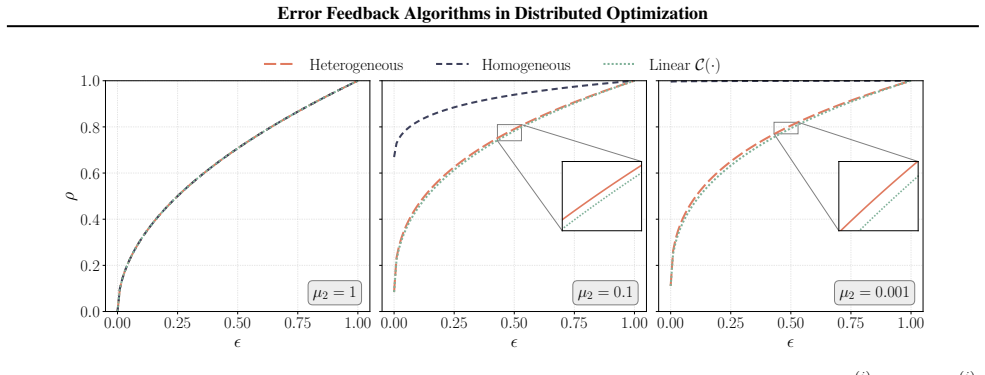
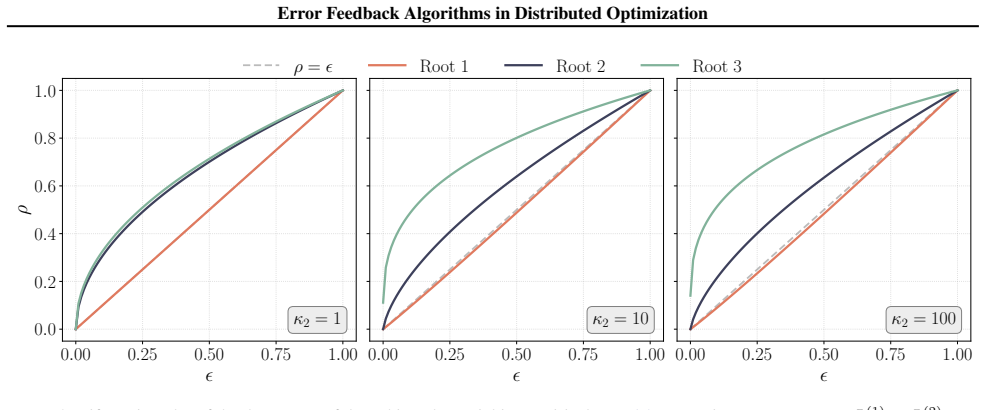
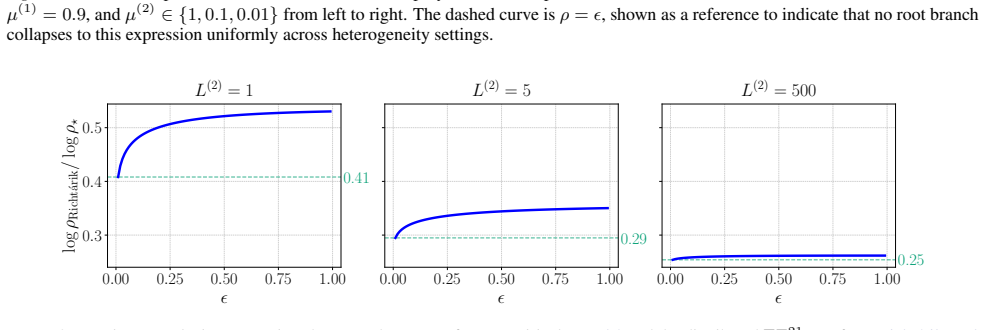
- [Section 5 (Experiments)] Figure captions for the numerical experiments should explicitly state the compression operator, the number of agents, and the step-size rule used, so that readers can directly compare the plotted curves to the derived bounds.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The report contains no specific major comments to address.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contribution is the analytical construction of optimal Lyapunov functions and step-size schedules for EF and EF21 under standard smoothness/convexity assumptions on the objective and compression operators. These constructions are presented as first-principles derivations that recover single-agent rates and remain independent of agent count; no equations or claims in the abstract or described results reduce a claimed rate to a fitted parameter, a self-citation chain, or a renaming of an input quantity. The analyses are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
QSGD : Communication - Efficient SGD via Gradient Quantization and Encoding
Alistarh, D., Grubic, D., Li, J., Tomioka, R., and Vojnovic, M. QSGD : Communication - Efficient SGD via Gradient Quantization and Encoding . Advances in Neural Information Processing Systems (NeurIPS), 30, 2017
2017
-
[3]
The Convergence of Sparsified Gradient Methods
Alistarh, D., Hoefler, T., Johansson, M., Konstantinov, N., Khirirat, S., and Renggli, C. The Convergence of Sparsified Gradient Methods . Advances in Neural Information Processing Systems (NeurIPS), 31, 2018
2018
-
[4]
Tight analyses of first-order methods with error feedback
Berg Thomsen, D., Taylor, A., and Dieuleveut, A. Tight analyses of first-order methods with error feedback. Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[5]
On Biased Compression for Distributed Learning
Beznosikov, A., Horváth, S., Richtárik, P., and Safaryan, M. On Biased Compression for Distributed Learning . Journal of Machine Learning Research, 24 0 (276): 0 1--50, 2023
2023
-
[6]
Project adam: Building an efficient and scalable deep learning training system
Chilimbi, T., Suzue, Y., Apacible, J., and Kalyanaraman, K. Project adam: Building an efficient and scalable deep learning training system. In USENIX Symposium on Operating Systems Design and Implementation ( OSDI 14) , 2014
2014
-
[7]
Ef-bv: A unified theory of error feedback and variance reduction mechanisms for biased and unbiased compression in distributed optimization
Condat, L., Yi, K., and Richt \'a rik, P. Ef-bv: A unified theory of error feedback and variance reduction mechanisms for biased and unbiased compression in distributed optimization. Advances in Neural Information Processing Systems, 35: 0 17501--17514, 2022
2022
-
[8]
Cutler, C. C. Differential quantization of communication signals. US Patent 2,605,361, July 1952. URL https://patents.google.com/patent/US2605361A/en. Filed June 29, 1950; issued July 29, 1952
1952
-
[9]
Contributions to the Complexity Analysis of Optimization Algorithms
Drori, Y. Contributions to the Complexity Analysis of Optimization Algorithms. PhD thesis, Tel-Aviv University, 2014
2014
-
[10]
Bicompfl: Bi-directional compression for stochastic federated learning
Egger, M., Bitar, R., Wachter-Zeh, A., Weinberger, N., and Gunduz, D. Bicompfl: Bi-directional compression for stochastic federated learning. In ICML 2025 Workshop on Machine Learning for Wireless Communication and Networks (ML4Wireless), 2025
2025
-
[11]
Fatkhullin, I., Sokolov, I., Gorbunov, E., Li, Z., and Richtárik, P. EF21 with Bells & Whistles : Practical Algorithmic Extensions of Modern Error Feedback , October 2021. arXiv:2110.03294 [cs, math]
-
[12]
Momentum provably improves error feedback! Advances in Neural Information Processing Systems (NeurIPS), 2023
Fatkhullin, I., Tyurin, A., and Richt \'a rik, P. Momentum provably improves error feedback! Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
Ef21 with bells & whistles: Six algorithmic extensions of modern error feedback
Fatkhullin, I., Sokolov, I., Gorbunov, E., Li, Z., and Richt \'a rik, P. Ef21 with bells & whistles: Six algorithmic extensions of modern error feedback. Journal of Machine Learning Research, 26 0 (189): 0 1--50, 2025
2025
-
[14]
Fazel, M., Hindi, H., and Boyd, S. P. Log-det heuristic for matrix rank minimization with applications to Hankel and Euclidean distance matrices. In American Control Conference (ACC), 2003
2003
-
[15]
Econtrol: Fast distributed optimization with compression and error control
Gao, Y., Islamov, R., and Stich, S. Econtrol: Fast distributed optimization with compression and error control. arXiv preprint arXiv:2311.05645, 2023
-
[16]
Linearly Converging Error Compensated SGD
Gorbunov, E., Kovalev, D., Makarenko, D., and Richtarik, P. Linearly Converging Error Compensated SGD . In Advances in Neural Information Processing Systems ( NeurIPS ) , 2020
2020
-
[17]
M., Taylor, A
Goujaud, B., Moucer, C., Glineur, F., Hendrickx, J. M., Taylor, A. B., and Dieuleveut, A. PEPit : computer-assisted worst-case analyses of first-order optimization methods in Python . Mathematical Programming Computation, 16 0 (3): 0 337--367, 2024
2024
-
[18]
Error feedback for muon and friends.arXiv preprint arXiv:2510.00643,
Gruntkowska, K., Gaponov, A., Tovmasyan, Z., and Richt \'a rik, P. Error feedback for muon and friends. arXiv preprint arXiv:2510.00643, 2025
-
[19]
Harrane, I. E. K., Flamary, R., and Richard, C. On reducing the communication cost of the diffusion lms algorithm. IEEE Transactions on Signal and Information Processing over Networks, 5 0 (1): 0 100--112, 2018
2018
-
[20]
and Yasuda, Y
Inose, H. and Yasuda, Y. A unity bit coding method by negative feedback. Proceedings of the IEEE, 51 0 (11): 0 1524--1535, 2005
2005
-
[21]
Communication-efficient Distributed SGD with Sketching
Ivkin, N., Rothchild, D., Ullah, E., Braverman, V., Stoica, I., and Arora, R. Communication-efficient Distributed SGD with Sketching . Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[22]
Available: http://arxiv.org/abs/1912.04977
Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., Bonawitz, K., Charles, Z., Cormode, G., Cummings, R., D'Oliveira, R. G. L., Rouayheb, S. E., Evans, D., Gardner, J., Garrett, Z., Gascón, A., Ghazi, B., Gibbons, P. B., Gruteser, M., Harchaoui, Z., He, C., He, L., Huo, Z., Hutchinson, B., Hsu, J., Jaggi, M., Javidi, T., Joshi,...
-
[23]
P., Rebjock, Q., Stich, S., and Jaggi, M
Karimireddy, S. P., Rebjock, Q., Stich, S., and Jaggi, M. Error Feedback Fixes SignSGD and other Gradient Compression Schemes . In International Conference on Machine Learning ( ICML ) , 2019
2019
-
[24]
P., Kale, S., Mohri, M., Reddi, S., Stich, S., and Suresh, A
Karimireddy, S. P., Kale, S., Mohri, M., Reddi, S., Stich, S., and Suresh, A. T. Scaffold: Stochastic controlled averaging for federated learning. In International Conference on Machine Learning (ICML), 2020
2020
-
[25]
Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication
Koloskova, A., Stich, S., and Jaggi, M. Decentralized Stochastic Optimization and Gossip Algorithms with Compressed Communication . In International Conference on Machine Learning ( ICML ) , 2019
2019
- [26]
-
[27]
The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning
Ma, S., Bassily, R., and Belkin, M. The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning. In International Conference on Machine Learning, pp.\ 3325--3334. PMLR, 2018
2018
-
[28]
McMahan, B., Moore, E., Ramage, D., Hampson, S., and Arcas, B. A. y. Communication- Efficient Learning of Deep Networks from Decentralized Data . In International Conference on Artificial Intelligence and Statistics (AISTATS) , April 2017
2017
-
[29]
Proxskip: Yes! local gradient steps provably lead to communication acceleration! finally! In International Conference on Machine Learning, pp.\ 15750--15769
Mishchenko, K., Malinovsky, G., Stich, S., and Richt \'a rik, P. Proxskip: Yes! local gradient steps provably lead to communication acceleration! finally! In International Conference on Machine Learning, pp.\ 15750--15769. PMLR, 2022
2022
-
[30]
MOSEK Optimizer API for Python 11.0.21 , 2025
MOSEK ApS . MOSEK Optimizer API for Python 11.0.21 , 2025. URL https://docs.mosek.com/11.0/pythonapi/index.html
2025
-
[31]
Philippenko, C. and Dieuleveut, A. Bidirectional compression in heterogeneous settings for distributed or federated learning with partial participation: tight convergence guarantees. arXiv:2006.14591 [cs, stat], 2020
-
[32]
and Dieuleveut, A
Philippenko, C. and Dieuleveut, A. Preserved central model for faster bidirectional compression in distributed settings. Advances in Neural Information Processing Systems ( NeurIPS ) , 2021
2021
-
[33]
SA-PEF: Step-Ahead Partial Error Feedback for Efficient Federated Learning
Redie, D. K., Arablouei, R., and Werner, S. Sa-pef: Step-ahead partial error feedback for efficient federated learning, 2026. URL https://arxiv.org/abs/2601.20738
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
EF21 : A New , Simpler , Theoretically Better , and Practically Faster Error Feedback
Richt\'arik, P., Sokolov, I., and Fatkhullin, I. EF21 : A New , Simpler , Theoretically Better , and Practically Faster Error Feedback . In Advances in Neural Information Processing Systems ( NeurIPS ) , 2021
2021
-
[35]
1- Bit Stochastic Gradient Descent and its Application to Data - Parallel Distributed Training of Speech DNNs
Seide, F., Fu, H., Droppo, J., Li, G., and Yu, D. 1- Bit Stochastic Gradient Descent and its Application to Data - Parallel Distributed Training of Speech DNNs . In Annual Conference of the International Speech Communication Association , 2014
2014
-
[36]
Stich, S. U. and Karimireddy, S. P. The error-feedback framework: Better rates for SGD with delayed gradients and compressed updates. Journal of Machine Learning Research, 21: 0 1--36, 2020
2020
-
[37]
U., Cordonnier, J.-B., and Jaggi, M
Stich, S. U., Cordonnier, J.-B., and Jaggi, M. Sparsified SGD with Memory . In Advances in Neural Information Processing Systems ( NeurIPS ) . 2018
2018
-
[38]
Scalable distributed DNN training using commodity GPU cloud computing
Strom, N. Scalable distributed DNN training using commodity GPU cloud computing. In Annual Conference of the International Speech Communication Association , 2015
2015
-
[39]
A canonical form for first-order distributed optimization algorithms
Sundararajan, A., Van Scoy, B., and Lessard, L. A canonical form for first-order distributed optimization algorithms. In 2019 American Control Conference (ACC), pp.\ 4075--4080, 2019. doi:10.23919/ACC.2019.8814838
-
[40]
Analysis and design of first-order distributed optimization algorithms over time-varying graphs
Sundararajan, A., Van Scoy, B., and Lessard, L. Analysis and design of first-order distributed optimization algorithms over time-varying graphs. IEEE Transactions on Control of Network Systems, 7 0 (4): 0 1597--1608, 2020. doi:10.1109/TCNS.2020.2988009
-
[41]
Errorcompensatedx: error compensation for variance reduced algorithms
Tang, H., Li, Y., Liu, J., and Yan, M. Errorcompensatedx: error compensation for variance reduced algorithms. Advances in Neural Information Processing Systems, 34: 0 18102--18113, 2021
2021
-
[42]
Lyapunov Functions for First - Order Methods : Tight Automated Convergence Guarantees
Taylor, A., Van Scoy, B., and Lessard, L. Lyapunov Functions for First - Order Methods : Tight Automated Convergence Guarantees . In International Conference on Machine Learning (ICML), 2018
2018
-
[43]
B., Hendrickx, J
Taylor, A. B., Hendrickx, J. M., and Glineur, F. Performance estimation toolbox (PESTO): automated worst-case analysis of first-order optimization methods . In Conference on Decision and Control (CDC), 2017 a
2017
-
[44]
B., Hendrickx, J
Taylor, A. B., Hendrickx, J. M., and Glineur, F. Smooth strongly convex interpolation and exact worst-case performance of first-order methods. Mathematical Programming, 161 0 (1-2): 0 307--345, 2017 b
2017
-
[45]
Ef21-rr: Fast o (1/t) rate for non-convex federated optimization with error feedback
Tian, H., Li, X., Liu, S., and Shi, Y. Ef21-rr: Fast o (1/t) rate for non-convex federated optimization with error feedback. Automatica, 183: 0 112655, 2026
2026
-
[46]
B., and Giselsson, P
Upadhyaya, M., Banert, S., Taylor, A. B., and Giselsson, P. Automated tight Lyapunov analysis for first-order methods. Mathematical Programming, 209 0 (1): 0 133--170, 2025
2025
-
[47]
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron
Vaswani, S., Bach, F., and Schmidt, M. Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron. In The 22nd international conference on artificial intelligence and statistics, pp.\ 1195--1204. PMLR, 2019
2019
-
[48]
Vempala, S. S. The Random Projection Method, volume 65 of DIMACS Series in Discrete Mathematics and Theoretical Computer Science. American Mathematical Society, 2004. ISBN 978-0-8218-3793-1
2004
-
[49]
Error Compensated Quantized SGD and its Applications to Large -scale Distributed Optimization
Wu, J., Huang, W., Huang, J., and Zhang, T. Error Compensated Quantized SGD and its Applications to Large -scale Distributed Optimization . In International Conference on Machine Learning ( ICML ) , 2018
2018
-
[50]
A high-performance software package for semidefinite programs: SDPA 7
Yamashita, M., Fujisawa, K., Nakata, K., Kojima, M., Kobayashi, K., and Goto, K. A high-performance software package for semidefinite programs: SDPA 7. Technical Report B-460, Department of Mathematical and Computing Science, Tokyo Institute of Technology, 2010
2010
-
[51]
Communication- Efficient Distributed Blockwise Momentum SGD with Error - Feedback
Zheng, S., Huang, Z., and Kwok, J. Communication- Efficient Distributed Blockwise Momentum SGD with Error - Feedback . In Advances in Neural Information Processing Systems ( NeurIPS ) , 2019
2019
-
[52]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[53]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[54]
vB =|gr z#E '' b3
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.