BitsMoE: Efficient Spectral Energy-Guided Bit Allocation for MoE LLM Quantization
Pith reviewed 2026-06-30 15:35 UTC · model grok-4.3
The pith
By decomposing MoE layers into shared bases and expert spectral factors and solving an integer linear program for bit allocation, BitsMoE enables accurate ultra-low-bit quantization of MoE LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
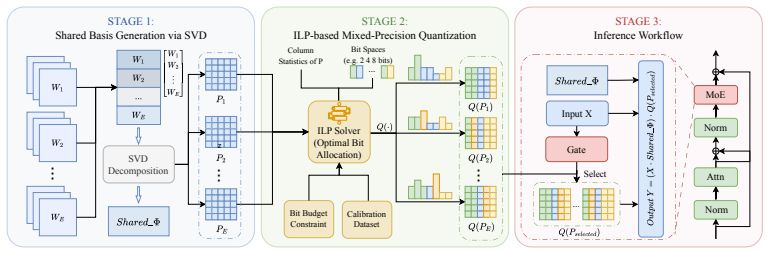
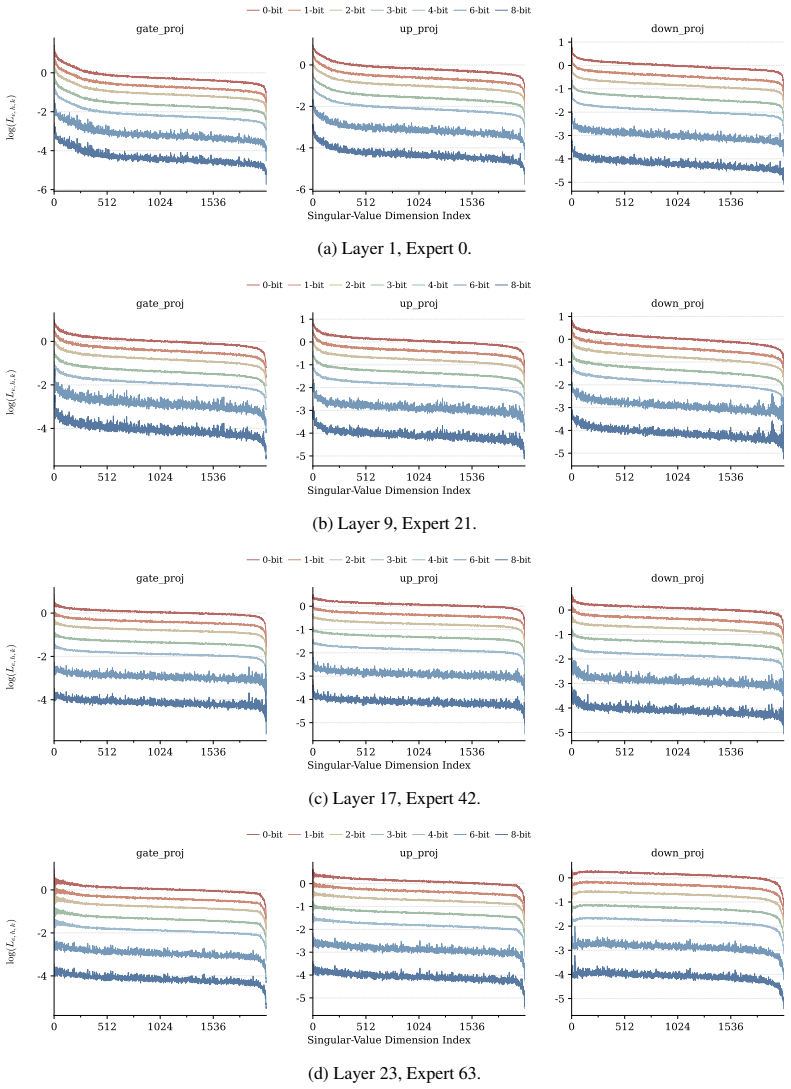
BitsMoE decomposes each MoE layer by SVD into a shared basis and expert-specific spectral factors, retaining the shared basis without quantization to preserve common cross-expert structure and using the expert-specific factors as fine-grained quantization units. To determine the bit-width of each unit, BitsMoE formulates spectrum-wise mixed-precision quantization as an activation-aware reconstruction surrogate and solves an integer linear program that minimizes estimated reconstruction loss under a fixed bit budget. Experiments across multiple MoE LLMs show that BitsMoE substantially reduces downstream task accuracy degradation in ultra-low-bit regimes.
What carries the argument
SVD decomposition of each MoE layer into a shared full-precision basis and expert-specific spectral factors, with bit widths assigned by solving an integer linear program on an activation-aware reconstruction surrogate.
If this is right
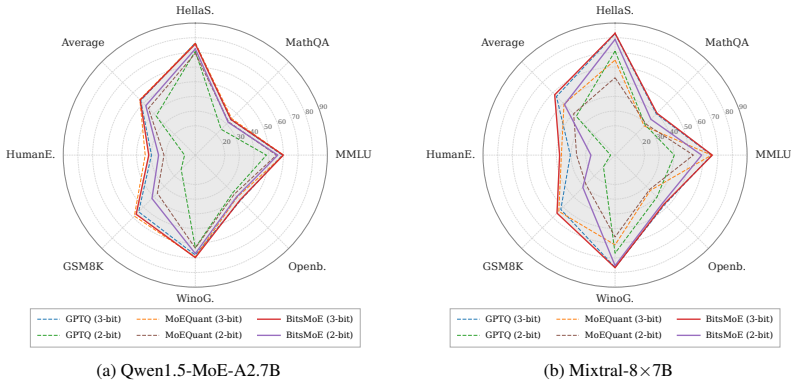
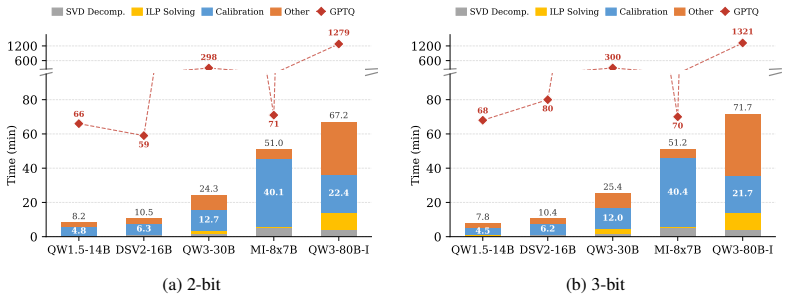
- Under 2-bit quantization on Qwen3-30B-A3B-Base, quantization completes 12.3 times faster than GPTQ.
- Average accuracy on downstream tasks improves by 27.83 percentage points relative to GPTQ at 2 bits.
- Decoding throughput rises by 1.76 times compared with GPTQ at the same bit width.
- Accuracy degradation on downstream tasks remains substantially smaller than with prior MoE quantization methods across the tested ultra-low-bit settings.
Where Pith is reading between the lines
- The shared-basis retention may allow hardware kernels to cache one copy of the common structure and reuse it across all experts during inference.
- The same SVD-plus-ILP pattern could be tested on other sparsely activated architectures such as switch transformers or sparse mixture-of-experts variants.
- Replacing the current surrogate with a more expensive but exact reconstruction loss inside the ILP would provide a direct empirical check on how much optimality is lost by the approximation.
- Extending the framework to dynamic per-token bit allocation rather than static per-factor allocation could further reduce average memory traffic.
Load-bearing premise
The activation-aware reconstruction surrogate used inside the integer linear program accurately predicts the true post-quantization reconstruction loss for the chosen bit allocations across expert factors.
What would settle it
Apply the ILP-selected bit allocations to the model, compute the actual end-to-end task accuracy after quantization, and check whether the ordering of allocations by true loss matches the ordering produced by the surrogate; a mismatch in ranking would falsify the optimality of the solved allocation.
Figures
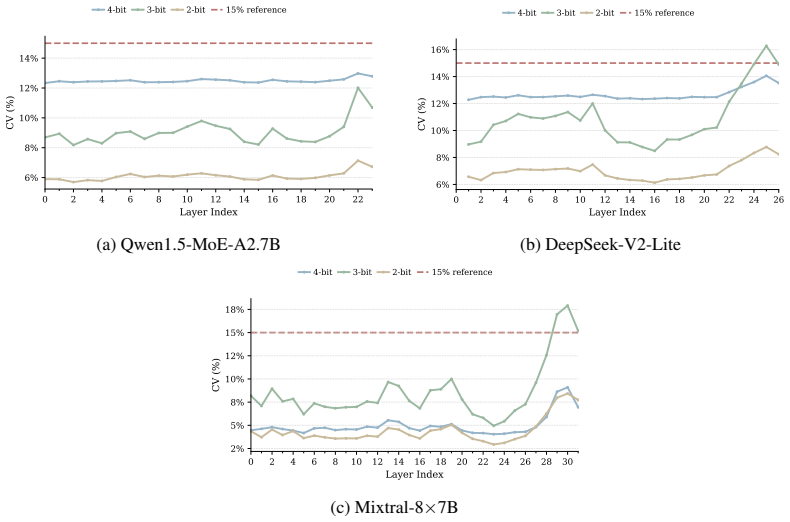
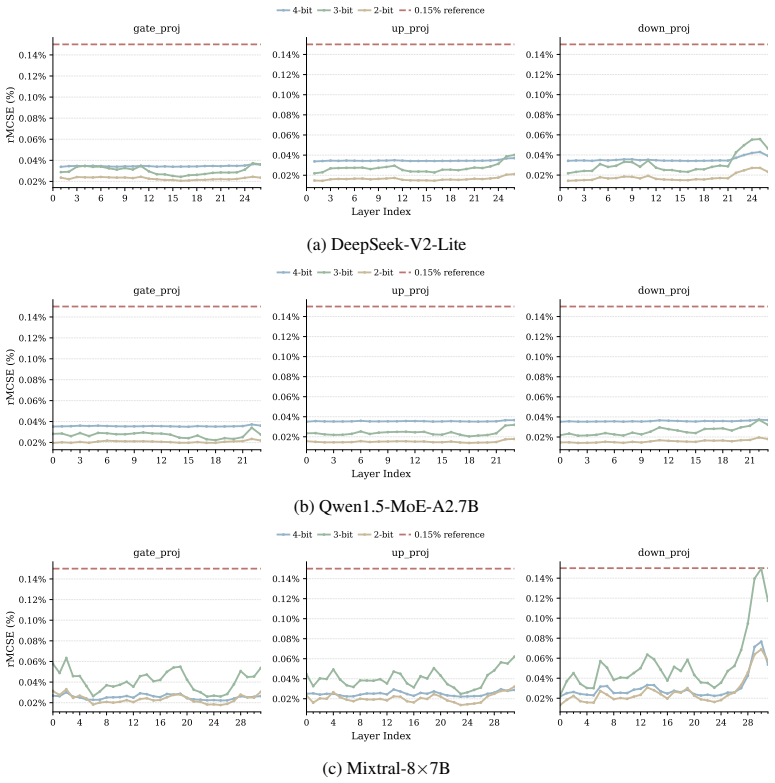
read the original abstract
Mixture-of-Experts (MoE) large language models reduce per-token computation through sparse expert activation, but their deployment remains memory-intensive because all expert weights must be kept resident in memory. Existing MoE compression methods struggle in the ultra-low-bit regime: pruning irreversibly removes model capacity, while coarse-grained quantization fails to allocate bits according to heterogeneous expert and weight-direction importance. We propose BitsMoE, a spectral-energy-guided bit-allocation framework for MoE LLM quantization. BitsMoE decomposes each MoE layer by SVD into a shared basis and expert-specific spectral factors, retaining the shared basis without quantization to preserve common cross-expert structure and using the expert-specific factors as fine-grained quantization units. To determine the bit-width of each unit, BitsMoE formulates spectrum-wise mixed-precision quantization as an activation-aware reconstruction surrogate and solves an integer linear program that minimizes estimated reconstruction loss under a fixed bit budget. Experiments across multiple MoE LLMs show that BitsMoE substantially reduces downstream task accuracy degradation in ultra-low-bit regimes. Under 2-bit quantization on Qwen3-30B-A3B-Base, BitsMoE accelerates quantization by 12.3$\times$, improves average accuracy by 27.83 percentage points, and increases decoding speed by 1.76$\times$ over GPTQ. Our model and code are publicly available at https://github.com/zjiayu064/BitsMoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BitsMoE for ultra-low-bit quantization of MoE LLMs. Each MoE layer is decomposed via SVD into a shared basis (kept unquantized) and expert-specific spectral factors; bit widths for the factors are chosen by solving an integer linear program whose objective is an activation-aware reconstruction surrogate loss, subject to a fixed bit budget. Experiments on models including Qwen3-30B-A3B-Base report that 2-bit BitsMoE yields 12.3× faster quantization, +27.83 pp average accuracy, and 1.76× faster decoding relative to GPTQ.
Significance. If the surrogate loss reliably predicts true post-quantization error, the approach would offer a practical route to memory-efficient deployment of large MoE models while preserving cross-expert structure. Public release of code and models strengthens reproducibility.
major comments (2)
- [Method (ILP objective)] Method section on ILP formulation: the bit-allocation decisions rest entirely on minimizing the activation-aware reconstruction surrogate; the manuscript supplies no ablation, correlation study, or hold-out validation demonstrating that this surrogate predicts actual reconstruction error (or downstream accuracy) after low-bit quantization and dequantization of the spectral factors. This is load-bearing for the headline accuracy and speedup claims.
- [Experiments] Experiments section / abstract results: the reported 12.3× quantization speedup, +27.83 pp accuracy gain, and 1.76× decode speedup on Qwen3-30B-A3B-Base at 2 bits are stated without error bars, number of runs, precise baseline configurations (e.g., GPTQ implementation details), or per-expert bit-allocation statistics, making it impossible to assess whether the gains are robust or driven by the surrogate.
minor comments (1)
- [Method] Notation for the SVD decomposition and spectral factors should be introduced with explicit matrix dimensions and clarified whether the shared basis is truly identical across all experts or only approximately shared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the surrogate validation and experimental reporting. We address each major comment below with honest responses and commit to appropriate revisions.
read point-by-point responses
-
Referee: [Method (ILP objective)] Method section on ILP formulation: the bit-allocation decisions rest entirely on minimizing the activation-aware reconstruction surrogate; the manuscript supplies no ablation, correlation study, or hold-out validation demonstrating that this surrogate predicts actual reconstruction error (or downstream accuracy) after low-bit quantization and dequantization of the spectral factors. This is load-bearing for the headline accuracy and speedup claims.
Authors: We acknowledge that the manuscript does not contain an explicit ablation, correlation analysis, or hold-out validation linking the surrogate loss to post-quantization error or downstream accuracy. The surrogate follows the activation-aware reconstruction objective standard in prior work such as GPTQ, adapted to spectral factors, but this does not substitute for direct validation. In the revised manuscript we will add a dedicated study (including correlation plots and hold-out results) to address this gap. revision: yes
-
Referee: [Experiments] Experiments section / abstract results: the reported 12.3× quantization speedup, +27.83 pp accuracy gain, and 1.76× decode speedup on Qwen3-30B-A3B-Base at 2 bits are stated without error bars, number of runs, precise baseline configurations (e.g., GPTQ implementation details), or per-expert bit-allocation statistics, making it impossible to assess whether the gains are robust or driven by the surrogate.
Authors: We agree that the current presentation lacks sufficient experimental detail. The revised version will specify the exact GPTQ baseline configuration (official implementation, calibration dataset, and hyperparameters), add a supplementary table of per-expert bit allocations, and explicitly state that results are single-run point estimates due to the high cost of repeated quantization on 30B-scale models. Error bars cannot be added without new experiments. revision: partial
Circularity Check
No circularity; bit allocation via ILP on surrogate is independent of reported accuracy gains
full rationale
The paper decomposes MoE layers via SVD, retains the shared basis unquantized, treats expert spectral factors as quantization units, and solves an ILP whose objective is an activation-aware reconstruction surrogate derived from model structure and activations. Downstream accuracy, quantization speedup, and decode speed are measured empirically on tasks and not equivalent by construction to the surrogate or ILP inputs. No self-citations, self-definitional steps, or fitted inputs renamed as predictions appear in the derivation. The central result remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mathqa: Towards interpretable math word problem solving with operation-based formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and ...
2019
-
[2]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated LLMs. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=dfqsW38v1X
2024
-
[3]
Half-quadratic quantization of large machine learning models, November 2023
Hicham Badri and Appu Shaji. Half-quadratic quantization of large machine learning models, November 2023. URLhttps://dropbox.github.io/hqq_blog/
2023
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. A survey on mixture of experts in large language models.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
DRONE: Data-aware low-rank compression for large NLP models
Patrick CHen, Hsiang-Fu Yu, Inderjit S Dhillon, and Cho-Jui Hsieh. DRONE: Data-aware low-rank compression for large NLP models. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=sthiz9zeXGG
2021
-
[8]
MoEQuant: Enhancing quantization for mixture-of-experts large language models via expert-balanced sampling and affinity guidance
Zhixuan Chen, Xing Hu, Dawei Yang, Zukang Xu, XUCHEN, Zhihang Yuan, Sifan Zhou, and JiangyongYu. MoEQuant: Enhancing quantization for mixture-of-experts large language models via expert-balanced sampling and affinity guidance. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=0epuNvt5Dj
2025
-
[9]
Burr, Liu Liu, and Meng Wang
Mohammed Nowaz Rabbani Chowdhury, Kaoutar El Maghraoui, Hsinyu Tsai, Naigang Wang, Geoffrey W. Burr, Liu Liu, and Meng Wang. Efficient quantization of mixture-of-experts with theoretical generalization guarantees. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=yiMlVBAoQi
2026
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024. URL https://arxiv.org/abs/2412. 19437
2024
-
[12]
MxMoE: Mixed-precision quantization for moe with accuracy and performance co-design
Haojie Duanmu, Xiuhong Li, Zhihang Yuan, Size Zheng, Jiangfei Duan, Xingcheng Zhang, and Dahua Lin. MxMoE: Mixed-precision quantization for moe with accuracy and performance co-design. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=pXoZLGMNDm
2025
-
[13]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[14]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Marlin: Mixed- precision auto-regressive parallel inference on large language models
Elias Frantar, Roberto L Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. Marlin: Mixed- precision auto-regressive parallel inference on large language models. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, pages 239–251, 2025. 11
2025
-
[16]
Lee, Shengjie Sun, Wei Xue, and Yike Guo
Hao Gu, Wei Li, Lujun Li, Zhu Qiyuan, Mark G. Lee, Shengjie Sun, Wei Xue, and Yike Guo. Delta decompression for moe-based LLMs compression. InForty-second Interna- tional Conference on Machine Learning, 2025. URL https://openreview.net/forum? id=ziezViPoN1
2025
-
[17]
Gurobi Optimizer Reference Manual, 2024
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2024. URL https://www. gurobi.com
2024
-
[18]
Pad-net: An efficient framework for dynamic networks
Shwai He, Liang Ding, Daize Dong, Boan Liu, Fuqiang Yu, and Dacheng Tao. Pad-net: An efficient framework for dynamic networks. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14354–14366, 2023
2023
-
[19]
Measuring massive multitask language understanding, 2021.URL https://arxiv
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021.URL https://arxiv. org/abs, page 20, 2009
2021
-
[20]
Language model compression with weighted low-rank factorization
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization. InInternational Conference on Learn- ing Representations, 2022. URLhttps://openreview.net/forum?id=uPv9Y3gmAI5
2022
-
[21]
Milo: Efficient quantized moe inference with mixture of low-rank compensators
Beichen Huang, Yueming Yuan, ZELEI SHAO, and Minjia Zhang. Milo: Efficient quantized moe inference with mixture of low-rank compensators. InEighth Conference on Machine Learning and Systems, 2025. URLhttps://openreview.net/forum?id=NXVXiJmhe1
2025
-
[22]
Mixture compressor for mixture-of-experts LLMs gains more
Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, and XIAOJUAN QI. Mixture compressor for mixture-of-experts LLMs gains more. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=hheFYjOsWO
2025
-
[23]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
On the assessment of monte carlo error in simulation-based statistical analyses.The American Statistician, 63(2):155–162, 2009
Elizabeth Koehler, Elizabeth Brown, and Sebastien J-PA Haneuse. On the assessment of monte carlo error in simulation-based statistical analyses.The American Statistician, 63(2):155–162, 2009
2009
-
[25]
Lee, Shengjie Sun, Wei Xue, and Yike Guo
Wei Li, Lujun Li, Hao Gu, You-Liang Huang, Mark G. Lee, Shengjie Sun, Wei Xue, and Yike Guo. Moe-SVD: Structured mixture-of-experts LLMs compression via singular value decomposition. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=acJ3vdFljk
2025
-
[26]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[27]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
A survey on inference optimization techniques for mixture of experts models
Jiacheng Liu, Peng Tang, Wenfeng Wang, Yuhang Ren, Xiaofeng Hou, Pheng-Ann Heng, Minyi Guo, and Chao Li. A survey on inference optimization techniques for mixture of experts models. CoRR, 2024
2024
-
[29]
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li. Not all experts are equal: Efficient expert pruning and skipping for mixture-of- experts large language models.arXiv preprint arXiv:2402.14800, 2024
-
[30]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering.arXiv preprint arXiv:1809.02789, 2018. 12
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Evan Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishir...
2025
-
[32]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[33]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[34]
Omniquant: Omnidirectionally calibrated quanti- zation for large language models
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quanti- zation for large language models. InICLR, 2024. URL https://openreview.net/forum? id=8Wuvhh0LYW
2024
-
[35]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Unveiling super experts in mixture-of-experts large language models
Zunhai Su, Qingyuan Li, Hao Zhang, Weihao Ye, Qibo Xue, YuLei Qian, Yuchen Xie, Ngai Wong, and Kehong Yuan. Unveiling super experts in mixture-of-experts large language models. arXiv preprint arXiv:2507.23279, 2025
-
[37]
Eleutherai/lm-evaluation-harness: v0.4.9.1, August 2025
Lintang Sutawika, Hailey Schoelkopf, Leo Gao, Baber Abbasi, Stella Biderman, Jonathan Tow, ben fattori, Charles Lovering, farzanehnakhaee70, Jason Phang, Anish Thite, Fazz, Aflah, Niklas, Thomas Wang, sdtblck, nopperl, gakada, tttyuntian, researcher2, Julen Etxaniz, Chris, Hanwool Albert Lee, Leonid Sinev, Zdenˇek Kasner, Kiersten Stokes, Khalid, KonradSz...
-
[38]
Qwen1.5-moe: Matching 7b model performance with 1/3 activated parameters, February 2024
Qwen Team. Qwen1.5-moe: Matching 7b model performance with 1/3 activated parameters, February 2024. URLhttps://qwenlm.github.io/blog/qwen-moe/
2024
-
[39]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019
2019
-
[40]
ExLlamaV2
turboderp-org. ExLlamaV2. https://github.com/turboderp-org/exllamav2, 2023. GitHub repository. Accessed: 2026-05-05
2023
-
[41]
SVD-LLM: Truncation-aware singular value decomposition for large language model compression
Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. SVD-LLM: Truncation-aware singular value decomposition for large language model compression. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=LNYIUouhdt
2025
-
[42]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickaël Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InICML, pages 38087–38099, 2023. URL https://proceedings.mlr.press/v202/ xiao23c.html
2023
-
[43]
KBVQ-moe: KLT- guided SVD with bias-corrected vector quantization for moe large language models
Zukang Xu, Zhixiong Zhao, Xing Hu, Zhixuan Chen, and Dawei Yang. KBVQ-moe: KLT- guided SVD with bias-corrected vector quantization for moe large language models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https:// openreview.net/forum?id=veFs5UfYq9. 13
2026
-
[44]
Openmoe: An early effort on open mixture-of-experts language models
Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou, and Yang You. Openmoe: An early effort on open mixture-of-experts language models. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/ forum?id=1YDeZU8Lt5
2024
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, and Bo Yuan. Moe-i-squared: Compressing mixture of experts models through inter-expert pruning and intra-expert low-rank decomposition.arXiv preprint arXiv:2411.01016, 2024
-
[48]
Codequant: Unified clustering and quantization for enhanced outlier smoothing in low-precision mixture-of-experts
Xiangyang Yin, Xingyu Liu, Tianhua Xia, Bo Bao, Vithursan Thangarasa, Valavan Manoharara- jah, Eric Sather, and Sai Qian Zhang. Codequant: Unified clustering and quantization for enhanced outlier smoothing in low-precision mixture-of-experts. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. URL https://openreview.net/ forum?i...
2026
-
[49]
ASVD: Activation-aware singular value decomposition for compressing large language models,
Zhihang Yuan, Yuzhang Shang, Yue Song, Dawei Yang, Qiang Wu, Yan Yan, and Guangyu Sun. ASVD: Activation-aware singular value decomposition for compressing large language models,
-
[50]
URLhttps://openreview.net/forum?id=HyPofygOCT
-
[51]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830, 2019. 14 A Positioning BITSMOE Among MoE Compression Methods Table 5: Positioning of BITSMOE relative to representative MoE compression paradigms. ✓ and ✗ indicate whether each feature is a primary d...
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[52]
Component costL e,h,k(b)Reconstruction-loss surrogate for assigningbbits to component(e, h, k)
The remaining symbols are auxiliary coefficients in the piecewise distortion model. Component costL e,h,k(b)Reconstruction-loss surrogate for assigningbbits to component(e, h, k). ILP variablesy e,h,k,b,Y (h),C (h),Ω (h) Binary bit-assignment variable and its projection-wise collections, withC e,h,k,b :=L e,h,k(b)and Ωe,h,k,b :=b. Bit budgetsb eq,B,B bit ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.