DLLM-JEPA: Joint Embedding Predictive Architectures for Masked Diffusion Language Models
Pith reviewed 2026-06-30 11:46 UTC · model grok-4.3
The pith
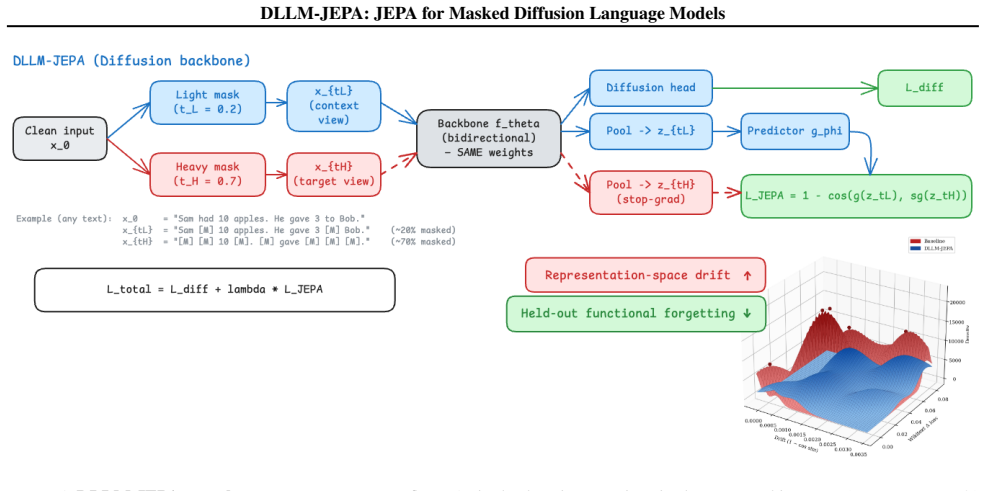
DLLM-JEPA adapts JEPA to masked diffusion language models by using different masking rates for distinct views without paired data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
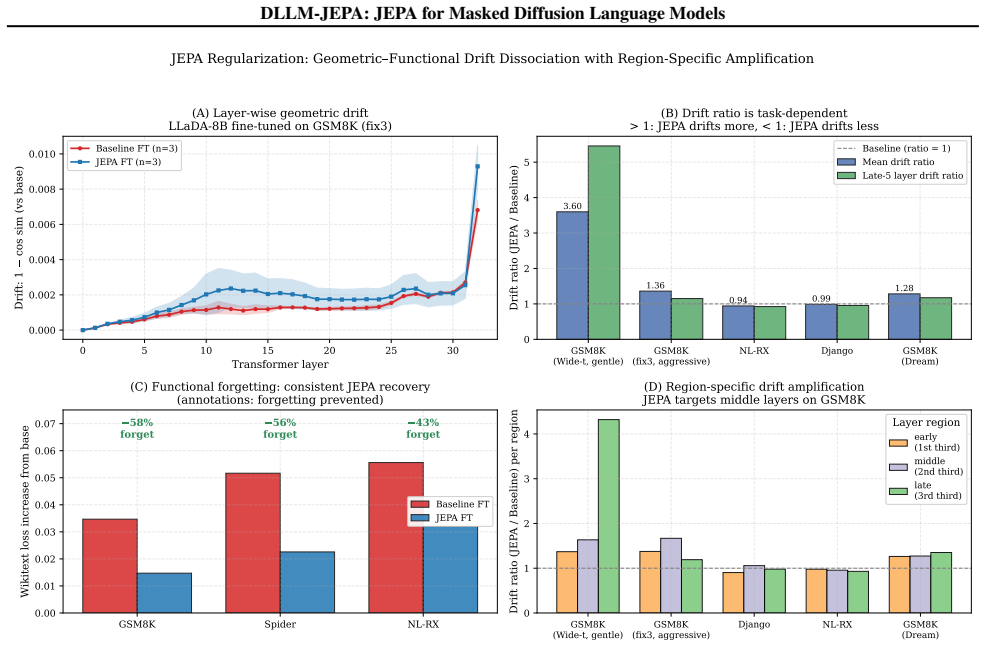
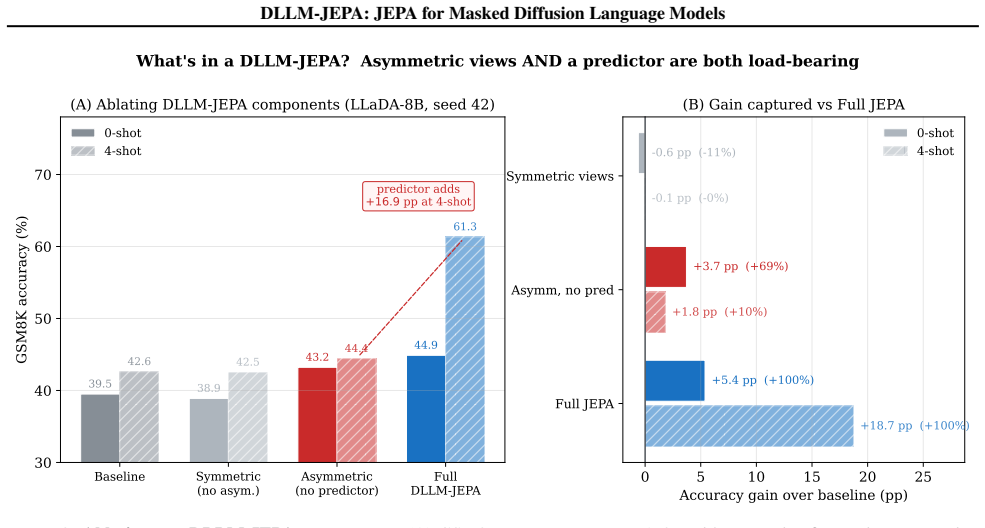
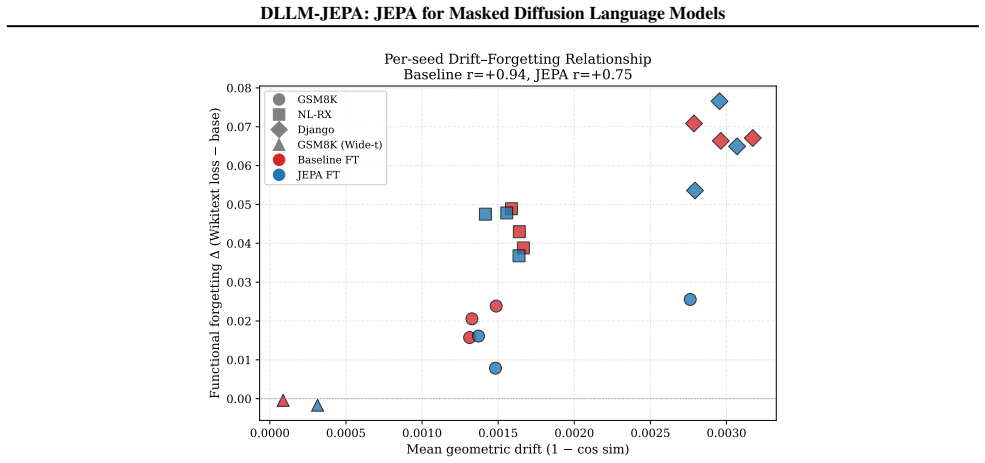
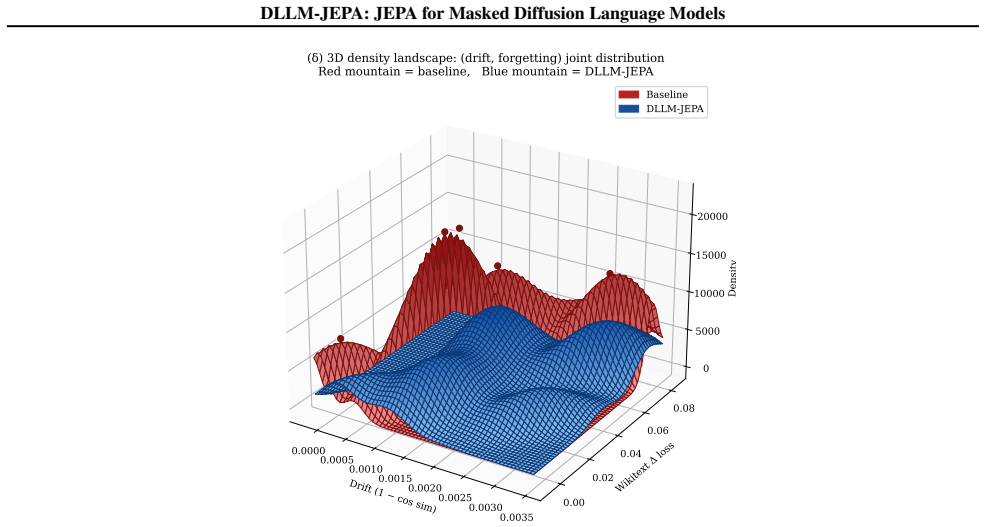
DLLM-JEPA pairs JEPA with masked-diffusion language models so that different masking rates on the same input generate the required views for the predictor in one forward pass, improving over diffusion-only fine-tuning in every evaluated pair up to +18.7 pp on LLaDA-8B GSM8K, driving Wikitext loss below the pre-trained base, and preserving MMLU while the baseline does not.
What carries the argument
Bidirectional attention in masked diffusion models combined with different masking rates to produce two semantically distinct views for JEPA predictor training without external pairs.
Load-bearing premise
Different masking rates applied to the same input in a bidirectional diffusion model produce two semantically distinct views that are sufficient to train a JEPA predictor without any external paired data.
What would settle it
Running the predictor training with identical masking rates on both views and observing no accuracy or generalization difference would falsify the claim that distinct views from masking rates are what enable the gains.
Figures
read the original abstract
Joint Embedding Predictive Architectures (JEPAs) have reshaped self-supervised representation learning in vision. The recent LLM-JEPA ported JEPA to autoregressive language models but inherited two steep costs from the causal-attention substrate: it demands explicit multi-view data (e.g., text-code pairs), and it requires two gradient-carrying forward passes per step. We introduce DLLM-JEPA, which pairs JEPA with masked-diffusion language models to eliminate both costs at once. The bidirectional attention of diffusion models yields two semantically distinct views of the same input via different masking rates -- no explicit pairs needed -- and supports a single gradient-carrying forward pass, cutting training FLOPs by 33% relative to LLM-JEPA. DLLM-JEPA improves over diffusion-only fine-tuning in every (task, architecture) combination we evaluate: up to +18.7 pp on LLaDA-8B GSM8K and +11.4 pp on Dream-7B GSM8K, with consistent positive gains on Spider, NL-RX-SYNTH, and Django. Beyond accuracy, DLLM-JEPA exhibits a dual-win property: on LLaDA-8B with the Wide-t configuration, it simultaneously raises GSM8K accuracy (67.1 vs. 65.2, +1.8 pp), drives held-out Wikitext loss below the pre-trained base, and preserves MMLU accuracy at base level across three fine-tuning seeds -- whereas an L2-to-base parameter anchor matches baseline accuracy with no task gain. Layer-wise probing reveals the mechanism: a geometric-functional drift dissociation in which the fine-tuned backbone moves further from the pre-trained weights than the baseline yet forgets less on held-out Wikitext, with the amplification concentrated in middle transformer layers. The pattern appears on Dream-7B as well, indicating the phenomenon is not specific to a single backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DLLM-JEPA, which adapts Joint Embedding Predictive Architectures to masked diffusion language models. It claims that bidirectional attention enables two semantically distinct views of the same input via different masking rates (eliminating the need for explicit paired data) and supports a single gradient-carrying forward pass (cutting FLOPs by 33% vs. LLM-JEPA). DLLM-JEPA is reported to outperform diffusion-only fine-tuning on every evaluated (task, architecture) pair, with gains up to +18.7 pp on LLaDA-8B GSM8K and +11.4 pp on Dream-7B GSM8K, plus consistent gains on Spider, NL-RX-SYNTH, and Django. It further claims a 'dual-win' property (improved GSM8K accuracy, lower held-out Wikitext loss than the pre-trained base, and preserved MMLU) and supports this with layer-wise probing showing geometric-functional drift dissociation concentrated in middle layers.
Significance. If the empirical gains and mechanistic claims hold after verification, the work would be significant for self-supervised representation learning in language models: it removes two key costs of prior JEPA adaptations (paired data and dual forward passes) while delivering measurable task improvements and a dual-win regularization effect. The layer-wise analysis offers a concrete, falsifiable account of how the auxiliary loss alters fine-tuning dynamics relative to parameter anchoring.
major comments (2)
- [Abstract / §1] The central claim that different masking rates produce 'semantically distinct views' whose embeddings are sufficiently independent for JEPA to learn useful invariances (Abstract, §1) is load-bearing for attributing the reported gains to the JEPA predictor rather than to standard diffusion denoising. Because both views are generated from identical token sequences under bidirectional attention, the only source of difference is the mask pattern; the manuscript should supply either (a) quantitative evidence that the resulting view embeddings are less correlated than noise-level variants or (b) an ablation replacing the JEPA predictor with a simple consistency loss to isolate the contribution.
- [Results tables / §4] Table 3 (or equivalent results table) reports point improvements without accompanying standard errors, number of seeds, or statistical tests; the +18.7 pp and +11.4 pp gains on GSM8K are therefore difficult to interpret as robust. The dual-win claim on LLaDA-8B Wide-t likewise requires seed-level variance to confirm that Wikitext loss is reliably below the pre-trained base while MMLU remains at base level.
minor comments (2)
- [§3] Notation for the two masking rates (e.g., p1 and p2) and the precise form of the JEPA predictor loss should be introduced with an equation in §3 rather than left implicit in the abstract.
- [§3.2] The claim of '33% FLOPs reduction' relative to LLM-JEPA should be accompanied by an explicit FLOPs breakdown (forward vs. backward passes, sequence length, batch size) to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and agree that the requested additions will strengthen the paper. Both comments can be addressed through targeted revisions and additional analyses.
read point-by-point responses
-
Referee: [Abstract / §1] The central claim that different masking rates produce 'semantically distinct views' whose embeddings are sufficiently independent for JEPA to learn useful invariances (Abstract, §1) is load-bearing for attributing the reported gains to the JEPA predictor rather than to standard diffusion denoising. Because both views are generated from identical token sequences under bidirectional attention, the only source of difference is the mask pattern; the manuscript should supply either (a) quantitative evidence that the resulting view embeddings are less correlated than noise-level variants or (b) an ablation replacing the JEPA predictor with a simple consistency loss to isolate the contribution.
Authors: We agree that the independence of the two views is central to the attribution of gains and that the manuscript currently motivates this property via bidirectional attention and differing mask rates without supplying the requested quantitative support. The paper does not include embedding correlation measurements or the suggested ablation. In revision we will add (a) a comparison of pairwise embedding correlations between differently masked views versus same-view noise perturbations, and (b) an ablation that replaces the JEPA predictor with a simple consistency loss while keeping all other factors fixed. revision: yes
-
Referee: [Results tables / §4] Table 3 (or equivalent results table) reports point improvements without accompanying standard errors, number of seeds, or statistical tests; the +18.7 pp and +11.4 pp gains on GSM8K are therefore difficult to interpret as robust. The dual-win claim on LLaDA-8B Wide-t likewise requires seed-level variance to confirm that Wikitext loss is reliably below the pre-trained base while MMLU remains at base level.
Authors: The manuscript already states that the dual-win results for LLaDA-8B are reported across three fine-tuning seeds. We nevertheless agree that all tables should report standard errors, explicit seed counts for every experiment, and appropriate statistical tests. In the revision we will update every results table and the associated text to include these elements so that the robustness of the GSM8K gains and the dual-win property can be directly assessed. revision: yes
Circularity Check
No circularity: empirical gains rest on experiments, not self-referential definitions or fitted predictions
full rationale
The manuscript introduces DLLM-JEPA as an architectural combination of JEPA-style prediction with masked diffusion LMs, asserting that different masking rates on bidirectional attention produce usable distinct views. This is presented as an enabling assumption rather than a derived result. All reported gains (e.g., +18.7 pp on GSM8K) are framed as experimental outcomes across task-architecture pairs, with no equations, uniqueness theorems, or first-principles derivations that reduce the claimed predictor or loss to the input masking schedule by construction. No self-citation chains, ansatz smuggling, or renaming of known patterns appear as load-bearing steps. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Revisiting Feature Prediction for Learning Visual Representations from Video
A. Bardes, Q. Garrido, J. Ponce, X. Chen, M. Rabbat, Y . Le- Cun, M. Assran, and N. Ballas. Revisiting feature predic- tion for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Huang, K., Fu, T., Gao, W., Zhao, Y ., Roohani, Y ., Leskovec, J., Coley, C
0-shot 4-shot 0 5 10 15 20 25 Accuracy gain over baseline (pp) Symmetric views Asymm, no pred Full JEPA -0.6 pp (-11%) -0.1 pp (-0%) +3.7 pp (+69%) +1.8 pp (+10%) +5.4 pp (+100%) +18.7 pp (+100%) (B) Gain captured vs Full JEPA 0-shot 4-shot What's in a DLLM-JEPA? Asymmetric views AND a predictor are both load-bearing Figure 3.Ablating two DLLM-JEPA compon...
- [4]
-
[5]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and L. Kong. Dream 7B: Diffusion large language models. arXiv preprint arXiv:2508.15487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
This isnota matched comparison—the two methods use differ- ent backbones (AR vs
alongside the improvements we obtain with DLLM-JEPA on the same task names. This isnota matched comparison—the two methods use differ- ent backbones (AR vs. masked-diffusion), differentmodel scales(1B vs. 7–8B), different pre-training corpora, dif- ferent baseline recipes, and in one case a different metric variant. We present the table solely as a refere...
-
[10]
(tL, tH) sensitivity on LLaDA-8B GSM8K (aggressive, seed 42). (tL, tH)0-shot 4-shot (0.1,0.5)43.59 44.05 (0.2,0.5)42.00 46.40 (0.2,0.7)(default) 44.88 61.33 (0.3,0.9)40.11 42.76 nism; after SQL-cleaning, both rise into the 20–25% range with DLLM-JEPA providing a clean +4.26 pp improvement. 0-shot results for completeness.The main-table 4-shot protocol is ...
2025
-
[11]
Dream-7B (Ye et al., 2025): 28 layers, hidden dim
2025
-
[12]
Seeds.Multi-seed results use seeds {42,123,777} . Seeds are matched between baseline and DLLM-JEPA within each task / configuration cell so that any difference is attributable to the objective. Hardware and wall-clock.8×NVIDIA A100 80GB on a single node, 80 GB HBM each. Per-run training wall- clock: GSM8K ∼45 min (LLaDA-8B aggressive), ∼1.0 h (Dream-7B ag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.