Diffusion Image Generation with Explicit Modeling of Data Manifold Geometry
Pith reviewed 2026-07-02 23:08 UTC · model grok-4.3
The pith
Integrating discrete patch tokenization into a continuous diffusion score function explicitly models data manifold geometry and improves image generation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
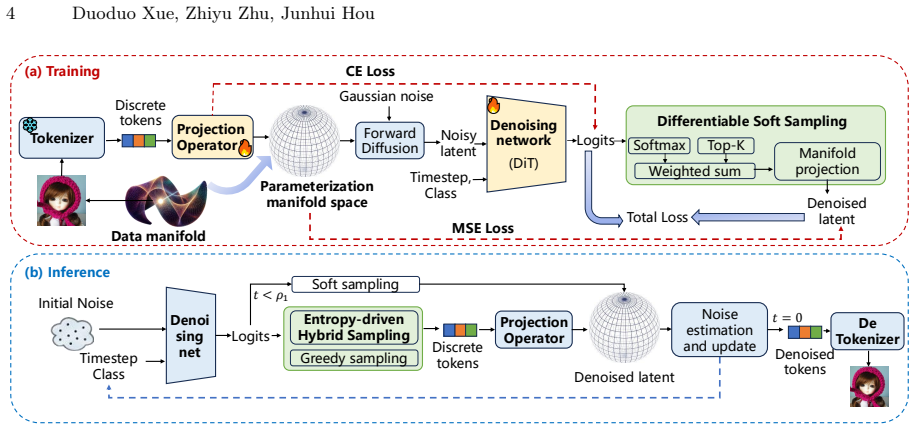
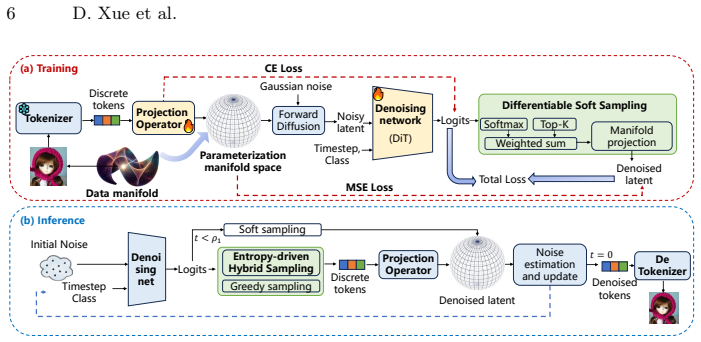
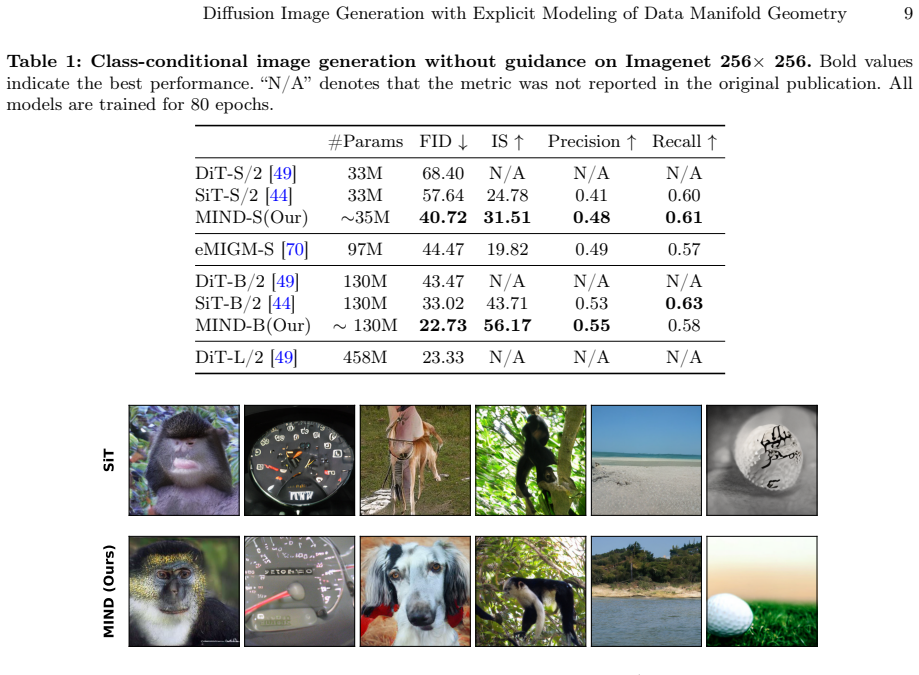
By embedding discrete patch tokenization inside the continuous diffusion score function and training it differentiably with soft top-k aggregation, the model learns a parameterization that respects manifold geometry; this yields FID of 22.73 after 80 epochs without guidance (versus 43.47 for vanilla DiT-B/2) and FID of 2.06 for the 130M-parameter MIND-B with guidance (versus 3.1B-parameter LlamaGen).
What carries the argument
Integration of discrete patch tokenization into the continuous diffusion score function via soft top-k aggregation, which quantifies manifold structure while preserving differentiability and parallel generation.
If this is right
- The base model halves FID relative to the DiT-B/2 baseline after identical 80-epoch training without guidance.
- MIND-B with 130M parameters reaches FID 2.06 with guidance, beating a 3.1B-parameter model.
- MIND-XL with 715M parameters further lowers FID to 1.95.
- Average FID drops 15.95 relative to DiT and 9.06 relative to SiT across reported settings.
- Multi-stage transition sampling dynamically adapts the schedule during inference.
Where Pith is reading between the lines
- The same tokenization-plus-score-function pattern could be tested on non-image domains such as audio or 3D shapes to check whether manifold geometry benefits transfer.
- If the soft top-k mechanism proves stable, it might allow hybrid discrete-continuous architectures in other score-based or flow-based generative models.
- Lower parameter counts achieving competitive FID suggest that explicit manifold modeling may reduce the need for ever-larger transformer backbones.
Load-bearing premise
That discrete patch tokenization can be stably inserted into the continuous score function without causing instability or mode collapse that would erase the reported FID gains.
What would settle it
Training the proposed integration on ImageNet-256x256 and measuring whether FID remains at or above the DiT baseline or whether training diverges.
Figures






read the original abstract
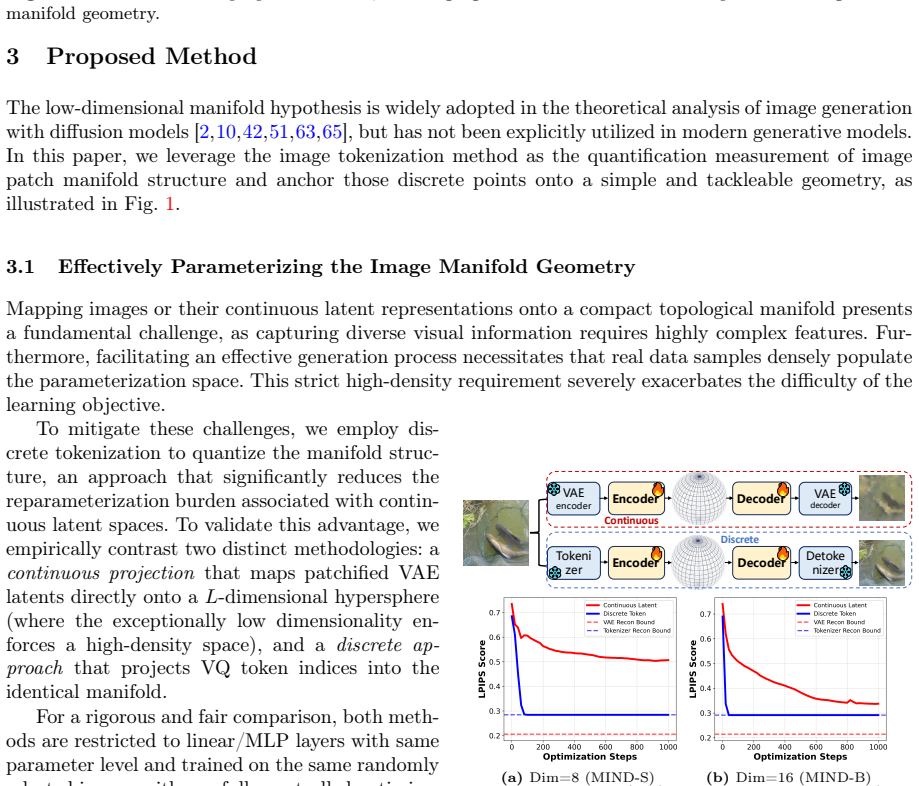
Image generative models aim to sample data points from the underlying data manifold, a task that requires learning and decoding a dense, low-dimensional, and compact parameterization space. To achieve this, we propose the Data Manifold-aware Image diffusioN moDel (MIND), a novel framework that explicitly models manifold geometry by integrating discrete patch tokenization into the score function of a continuous diffusion model. This approach successfully leverages both the structural quantification capabilities of discrete tokens and the parallel generation flexibility of continuous diffusion. Moreover, we enable end-to-end differentiable training via a novel soft top-$k$ aggregation mechanism and introduce dual-branch high-frequency feature embedding layers to alleviate the spectral bias of transformer backbones on low-dimensional inputs. Furthermore, for inference, we design a multi-stage transition sampling scheme that dynamically adjusts the sampling scheme based on timestep. Extensive experiments on ImageNet 256$\times$256 demonstrate the effectiveness of MIND. After 80-epoch training, our base model achieves an FID of 22.73 without guidance, nearly halving the 43.47 FID of the vanilla DiT-B/2 baseline. The proposed method reduces FID by 15.95 and 9.06 on average compared with the baselines DiT and SiT, respectively. For image generation on ImageNet-256$\times$256 with guidance, the proposed MIND-B with only 130M parameters achieves an FID of 2.06, superpassing the LlamaGen-3B with 3.1B parameters. The proposed MIND-XL with 715M parameters further reduces the FID to 1.95. Our MIND introduces a fresh perspective on diffusion-based image generation, paving the way for future research and innovation in this community. The code will be publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Data Manifold-aware Image diffusioN moDel (MIND), which integrates discrete patch tokenization into the score function of a continuous diffusion model using a soft top-k aggregation mechanism to explicitly model data manifold geometry. Additional components include dual-branch high-frequency feature embeddings to address spectral bias and a multi-stage transition sampling scheme. On ImageNet-256×256, the base model reports FID 22.73 without guidance (vs. 43.47 for DiT-B/2) after 80 epochs, average FID reductions of 15.95 and 9.06 versus DiT and SiT baselines, and with guidance MIND-B (130M params) reaches FID 2.06, outperforming LlamaGen-3B (3.1B params); MIND-XL further reaches 1.95.
Significance. If the empirical results hold under scrutiny, the work provides a concrete mechanism for blending discrete structural tokens with continuous diffusion, potentially improving geometric fidelity and parameter efficiency in generative models. The reported ability of a 130M model to surpass a 3.1B baseline is noteworthy and could motivate further hybrid discrete-continuous designs.
major comments (2)
- [Abstract and experimental results section] Abstract and experimental results section: the headline FID claims (22.73 vs. 43.47 without guidance; 2.06 with guidance) are presented as direct evidence that the discrete-continuous integration captures manifold geometry, yet no ablation isolates the soft top-k aggregation or dual-branch embedding from the multi-stage sampling or other training choices. Without such controls it is impossible to confirm that the reported gains are attributable to the proposed manifold modeling rather than ancillary implementation details.
- [Method section describing framework integration] Method section describing framework integration: the soft top-k aggregation is introduced to enable end-to-end differentiability when inserting discrete patch tokens into the continuous score function, but the manuscript provides no analysis (e.g., stability bounds, mode-coverage diagnostics, or gradient-norm monitoring) addressing the risk that this hybrid construction could induce instability or mode collapse, which would undermine both the geometric claim and the FID attribution.
minor comments (2)
- [Abstract] Abstract: 'superpassing' is a typographical error and should read 'surpassing'.
- [Abstract] Abstract: the acronym expansion 'Data Manifold-aware Image diffusioN moDel' contains inconsistent capitalization that should be standardized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We provide point-by-point responses to the major comments and indicate the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and experimental results section] Abstract and experimental results section: the headline FID claims (22.73 vs. 43.47 without guidance; 2.06 with guidance) are presented as direct evidence that the discrete-continuous integration captures manifold geometry, yet no ablation isolates the soft top-k aggregation or dual-branch embedding from the multi-stage sampling or other training choices. Without such controls it is impossible to confirm that the reported gains are attributable to the proposed manifold modeling rather than ancillary implementation details.
Authors: We agree that the current presentation would benefit from explicit ablations to isolate the effects of the soft top-k aggregation and dual-branch embeddings. In the revised manuscript, we will include additional ablation experiments that compare the full MIND model against variants without these components, while keeping the multi-stage sampling and other training settings consistent. This will provide clearer attribution of the performance gains to the manifold modeling aspects. revision: yes
-
Referee: [Method section describing framework integration] Method section describing framework integration: the soft top-k aggregation is introduced to enable end-to-end differentiability when inserting discrete patch tokens into the continuous score function, but the manuscript provides no analysis (e.g., stability bounds, mode-coverage diagnostics, or gradient-norm monitoring) addressing the risk that this hybrid construction could induce instability or mode collapse, which would undermine both the geometric claim and the FID attribution.
Authors: The manuscript does not currently include dedicated analysis on stability or mode collapse risks. We will add gradient norm monitoring results and mode coverage discussions based on our training logs to the revised version. However, we note that the strong empirical performance, including high sample diversity in the reported FID scores, provides indirect evidence against significant mode collapse. Formal stability bounds are beyond the scope of this work but could be explored in future research. revision: partial
Circularity Check
No circularity: empirical architecture proposal with external baseline comparisons
full rationale
The paper introduces the MIND framework via architectural choices (discrete patch tokenization integrated into continuous diffusion score function, soft top-k aggregation, dual-branch embeddings, multi-stage sampling) and validates via direct FID measurements on ImageNet-256x256 against independent external baselines (DiT-B/2, SiT, LlamaGen). No derivation chain, first-principles prediction, or fitted parameter is presented that reduces to its own inputs by construction. No self-citations are load-bearing for any uniqueness claim. The central results are empirical performance deltas, not algebraic identities or renamed known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Continuous diffusion score functions can be augmented with discrete token information to better capture data manifold geometry
Reference graph
Works this paper leans on
-
[1]
In: NeurIPS
Austin, J., Johnson, D.D., Ho, J., Tarlow, D., van den Berg, R.: Structured de- noising diffusion models in discrete state-spaces. In: NeurIPS. pp. 17981–17993 (2021) 16 D. Xue et al
2021
- [2]
-
[3]
In: ICLR (2022)
Bao, F., Li, C., Zhu, J., Zhang, B.: Analytic-dpm: an analytic estimate of the optimal reverse variance in diffusion probabilistic models. In: ICLR (2022)
2022
-
[4]
In: CVPR
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: CVPR. pp. 22563–22575 (2023)
2023
-
[5]
In: ICLR (2019)
Brock, A., Donahue, J., Simonyan, K.: Large scale GAN training for high fidelity natural image synthesis. In: ICLR (2019)
2019
-
[6]
In: CVPR
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked gener- ative image transformer. In: CVPR. pp. 11305–11315 (2022)
2022
-
[7]
In: ICML
Chen, M., Huang, K., Zhao, T., Wang, M.: Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data. In: ICML. pp. 4672–4712 (2023)
2023
-
[8]
arXiv preprint arXiv:2504.07963 (2025)
Chen, S., Ge, C., Zhang, S., Sun, P., Luo, P.: Pixelflow: Pixel-space generative models with flow. arXiv preprint arXiv:2504.07963 (2025)
-
[9]
In: NeurIPS
Cui, H., Pehlevan, C., Lu, Y.M.: A solvable model of learning generative diffusion: theory and insights. In: NeurIPS. pp. 5253–5296 (2025)
2025
-
[10]
In: NeurIPS
De Bortoli, V., Mathieu, E., Hutchinson, M., Thornton, J., Teh, Y.W., Doucet, A.: Riemannian score-based generative modelling. In: NeurIPS. pp. 2406–2422 (2022)
2022
-
[11]
In: CVPR
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. pp. 248–255 (2009)
2009
-
[12]
In: NeurIPS
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: NeurIPS. pp. 8780–8794 (2021)
2021
-
[13]
In: CVPR
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: CVPR. pp. 12873–12883 (2021)
2021
-
[14]
In: NeurIPS
Geng,Z.,Deng,M.,Bai,X.,Kolter,J.Z.,He,K.:Meanflowsforone-stepgenerative modeling. In: NeurIPS. pp. 75460–75482 (2025)
2025
-
[15]
In: CVPR
Geng,Z., Lu,Y.,Wu,Z.,Shechtman,E.,Kolter,J.Z.,He,K.:Improvedmeanflows: On the challenges of fastforward generative models. In: CVPR. pp. 30467–30476 (2026)
2026
-
[16]
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Commun. ACM63(11), 139–144 (2020)
2020
-
[17]
In: NeurIPS
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS. pp. 6840–6851 (2020)
2020
-
[18]
In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications (2021)
2021
-
[19]
In: ICML
Hoogeboom, E., Heek, J., Salimans, T.: Simple diffusion: End-to-end diffusion for high resolution images. In: ICML. pp. 13213–13232 (2023)
2023
-
[20]
In: ICLR (2026)
Huang, Y., Wang, S.H., Bertozzi, A.L., Wang, B.: RMFlow: Refined mean flow by a noise-injection step for multimodal generation. In: ICLR (2026)
2026
-
[21]
In: NeurIPS
Jo, J., Hwang, S.J.: Continuous diffusion model for language modeling. In: NeurIPS. pp. 97394–97430 (2025)
2025
-
[22]
In: CVPR
Kang, M., Zhu, J.Y., Zhang, R., Park, J., Shechtman, E., Paris, S., Park, T.: Scaling up gans for text-to-image synthesis. In: CVPR. pp. 10124–10134 (2023)
2023
-
[23]
In: NeurIPS
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. In: NeurIPS. pp. 26565–26577 (2022) Manifold-Aware Image Diffusion Model 17
2022
-
[24]
In: NeurIPS
Karras, T., Aittala, M., Kynkäänniemi, T., Lehtinen, J., Aila, T., Laine, S.: Guid- ing a diffusion model with a bad version of itself. In: NeurIPS. pp. 52996–53021 (2024)
2024
-
[25]
In: CVPR
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: CVPR. pp. 4396–4405 (2019)
2019
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence43(11), 3964–3979 (2021)
Kobyzev, I., Prince, S.J., Brubaker, M.A.: Normalizing flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence43(11), 3964–3979 (2021)
2021
-
[27]
arXiv preprint arXiv:2602.10099 (2026)
Kumar, A., Patel, V.M.: Learning on the manifold: Unlocking standard diffusion transformers with representation encoders. arXiv preprint arXiv:2602.10099 (2026)
-
[28]
In: NeurIPS
Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., Lehtinen, J.: Ap- plying guidance in a limited interval improves sample and distribution quality in diffusion models. In: NeurIPS. pp. 122458–122483 (2024)
2024
-
[29]
In: CVPR
Lee, D., Kim, C., Kim, S., Cho, M., Han, W.S.: Autoregressive image generation using residual quantization. In: CVPR. pp. 11523–11532 (2022)
2022
-
[30]
arXiv preprint arXiv:2504.10483 , year=
Leng, X., Singh, J., Hou, Y., Xing, Z., Xie, S., Zheng, L.: Repa-e: Unlock- ing vae for end-to-end tuning with latent diffusion transformers. arXiv preprint arXiv:2504.10483 (2025)
-
[31]
In: NeurIPS
Li, T., Tian, Y., Li, H., Deng, M., He, K.: Autoregressive image generation without vector quantization. In: NeurIPS. vol. 37, pp. 56424–56445 (2024)
2024
-
[32]
Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction
Liu, Y., Qu, L., Zhang, H., Wang, X., Jiang, Y., Gao, Y., Ye, H., Li, X., Wang, S., Du, D.K., et al.: Detailflow: 1d coarse-to-fine autoregressive image generation via next-detail prediction. arXiv preprint arXiv:2505.21473 (2025)
-
[33]
Transactions on Machine Learning Research (2024)
Loaiza-Ganem, G., Ross, B.L., Hosseinzadeh, R., Caterini, A.L., Cresswell, J.C.: Deep generative models through the lens of the manifold hypothesis: A survey and new connections. Transactions on Machine Learning Research (2024)
2024
-
[34]
In: ICML
Lou, A., Meng, C., Ermon, S.: Discrete diffusion modeling by estimating the ratios of the data distribution. In: ICML. pp. 32819–32848 (2024)
2024
-
[35]
In: ECCV
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In: ECCV. pp. 23–40 (2024)
2024
-
[36]
In: NeurIPS
Ma, X., Zhao, F., Ling, P., Qiu, H., Wei, Z., Yu, H., Huang, J., Zeng, Z., Ma, L.: Towards better & faster autoregressive image generation: From the perspective of entropy. In: NeurIPS. pp. 31466–31497 (2025)
2025
-
[37]
In: CVPR
Ma, Z., Wei, L., Wang, S., Zhang, S., Tian, Q.: Deco: Frequency-decoupled pixel diffusion for end-to-end image generation. In: CVPR. pp. 43600–43610 (2026)
2026
-
[38]
In: ICML
Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML. pp. 8162–8171 (2021)
2021
-
[39]
In: NeurIPS
van den Oord, A., Vinyals, O., Kavukcuoglu, K.: Neural discrete representation learning. In: NeurIPS. pp. 6309–6318 (2017)
2017
-
[40]
In: ICCV
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV. pp. 4195–4205 (2023)
2023
-
[41]
In: ICLR (2021)
Pope, P., Zhu, C., Abdelkader, A., Goldblum, M., Goldstein, T.: The intrinsic dimension of images and its impact on learning. In: ICLR (2021)
2021
-
[42]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[43]
In: NeurIPS
Sahoo, S., Arriola, M., Schiff, Y., Gokaslan, A., Marroquin, E., Chiu, J., Rush, A., Kuleshov, V.: Simple and effective masked diffusion language models. In: NeurIPS. pp. 130136–130184 (2024)
2024
-
[44]
In: ICLR (2022) 18 D
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. In: ICLR (2022) 18 D. Xue et al
2022
-
[45]
In: ACM SIGGRAPH 2022 Conference Proceedings (2022)
Sauer, A., Schwarz, K., Geiger, A.: Stylegan-xl: Scaling stylegan to large diverse datasets. In: ACM SIGGRAPH 2022 Conference Proceedings (2022)
2022
-
[46]
In: ICCV
Shi, F., Luo, Z., Ge, Y., Yang, Y., Shan, Y., Wang, L.: Scalable image tokenization with index backpropagation quantization. In: ICCV. pp. 16037–16046 (2025)
2025
-
[47]
In: NeurIPS
Shi, J., Han, K., Wang, Z., Doucet, A., Titsias, M.K.: Simplified and generalized masked diffusion for discrete data. In: NeurIPS. pp. 103131–103167 (2024)
2024
-
[48]
In: ICLR (2021)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
2021
-
[49]
In: ICML
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. In: ICML. pp. 32211–32252 (2023)
2023
-
[50]
In: NeurIPS
Song, Y., Ermon, S.: Generative modeling by estimating gradients of the data distribution. In: NeurIPS. p. 11895–11907 (2019)
2019
-
[51]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
In: Proceedings of The 27th International Conference on Artificial Intelligence and Statistics
Tang, R., Yang, Y.: Adaptivity of diffusion models to manifold structures. In: Proceedings of The 27th International Conference on Artificial Intelligence and Statistics. pp. 1648–1656 (2024)
2024
-
[53]
In: NeurIPS
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: scalable image generation via next-scale prediction. In: NeurIPS. pp. 84839–84865 (2024)
2024
-
[54]
In: ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy (2025)
Wang, P., Zhang, H., Zhang, Z., Chen, S., Ma, Y., Qu, Q.: Diffusion models learn low-dimensional distributions via subspace clustering. In: ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy (2025)
2025
-
[55]
In: CVPR
Wang, S., Tian, Z., Huang, W., Wang, L.: Ddt: Decoupled diffusion transformer. In: CVPR. pp. 40633–40642 (2026)
2026
-
[56]
Transactions on Machine Learning Research (2025)
Xiong, J., Liu, G., Huang, L., Wu, C., Wu, T., Mu, Y., Yao, Y., Shen, H., Wan, Z., Huang, J., et al.: Autoregressive models in vision: A survey. Transactions on Machine Learning Research (2025)
2025
-
[57]
In: ICCV
Xiong, T., Liew, J.H., Huang, Z., Feng, J., Liu, X.: Gigatok: Scaling visual tok- enizers to 3 billion parameters for autoregressive image generation. In: ICCV. pp. 18770–18780 (2025)
2025
-
[58]
In: ICML
You, Z., Ou, J., Zhang, X., Hu, J., ZHOU, J., Li, C.: Effective and efficient masked image generation models. In: ICML. pp. 72730–72746 (2025)
2025
-
[59]
In: ICLR (2022)
Yu, J., Li, X., Koh, J.Y., Zhang, H., Pang, R., Qin, J., Ku, A., Xu, Y., Baldridge, J., Wu, Y.: Vector-quantized image modeling with improved VQGAN. In: ICLR (2022)
2022
-
[60]
In: ICLR (2024)
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A.G., Gong, B., Yang, M.H., Essa, I., Ross, D.A., Jiang, L.: Language model beats diffusion - tokenizer is key to visual gener- ation. In: ICLR (2024)
2024
-
[61]
In: ICLR (2025)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. In: ICLR (2025)
2025
-
[62]
In: CVPR
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
2018
-
[63]
In: NeurIPS
Zheng,A.,Wen,X.,Zhang,X.,Ma,C.,Wang,T.,YU,G.,Zhang,X.,QI,X.:Vision foundation models as effective visual tokenizers for autoregressive generation. In: NeurIPS. pp. 62656–62675 (2025)
2025
-
[64]
In: ICLR (2026) Manifold-Aware Image Diffusion Model 19
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. In: ICLR (2026) Manifold-Aware Image Diffusion Model 19
2026
-
[65]
Feature" level inherently retains all continuous architectural benefits (including our dual-branch high-frequency embeddings), the strict superiority of “Logits
Zhu, L., Wei, F., Lu, Y., Chen, D.: Scaling the codebook size of vqgan to 100,000 with a utilization rate of 99%. In: NeurIPS. pp. 12612–12635 (2024) Diffusion Image Generation with Explicit Modeling of Data Manifold Geometry (Supplementary Material) Duoduo Xue1, Zhiyu Zhu1,2, Junhui Hou1 1 Department of Computer Science, City University of Hong Kong, Chi...
2024
-
[66]
MIND-B, implemented with CFG intervals like eMIGM, incurs a sampling cost that matches DiT and is significantly lower than eMIGM
The tokenizer in MIND-B does not need extra training latency using pre- encoded tokens, with decoding costs on par with VAEs in DiT/SiT architectures. MIND-B, implemented with CFG intervals like eMIGM, incurs a sampling cost that matches DiT and is significantly lower than eMIGM. Moreover, we test the convergence speed using the experiment settings in Tab...
-
[67]
Diffusion & Noise Settings Noise Scale Factorc1 0.6 0.8 Signal Scale Factorc2 1.0 1.0 Training Timestep Range (t)t∈[0.2,0.95]t∈[0.2,0.95]
-
[68]
Embedding & Vocabulary Vocabulary SizeV16,384 8192 Embedding DimensionL16 8 Embedding Subspace 4 2
-
[69]
Network Architecture Total Parameters(M) 130.48 35.21 Number of Blocks 14 14 Hidden Size 768 384 Attention Heads 12 6 Condition Embedding Dimension 128 128
-
[70]
Training & Optimization Optimizer DeepSpeed AdamW Base Learning Rate1.0×10 −3 1.0×10−3 Batch Size 1024 2048 Training Epochs 80 80
2048
-
[71]
Inference Timestep schedule Linear Linear Temperatureτ0.99 0.99 Sampling steps 250 250 η0.99 0.99 (Top-p, Top-k,ρ1,ρ2)(cfg= 1.0) (200, 0.3, 0, 0.9) (100, 0.8, 0.3, 0.9) (Top-p, Top-k,ρ1,ρ2)(cfg= 1.5) (100, 0.8, 0.1, 0.9) (100, 0.8, 0.2, 0.99) (Top-p, Top-k,ρ1,ρ2)(cfg= 2.0) (100, 0.8, 0.1, 0.9) (300, 0.8, 0.3, 0.9) Table S-9:Training and Inference Paramete...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.