Positional Encodings Anchor Spatial Structure in Vision Transformers: A Geometric Perspective on Robustness
Pith reviewed 2026-06-29 08:34 UTC · model grok-4.3
The pith
Positional encodings shift Vision Transformers to index-anchored spatial organization that stays stable under content perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
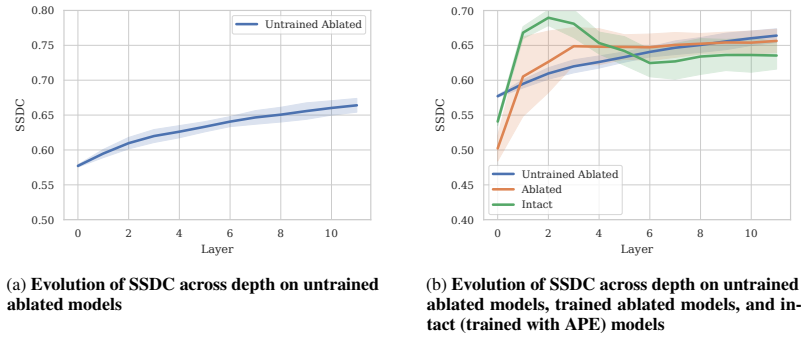
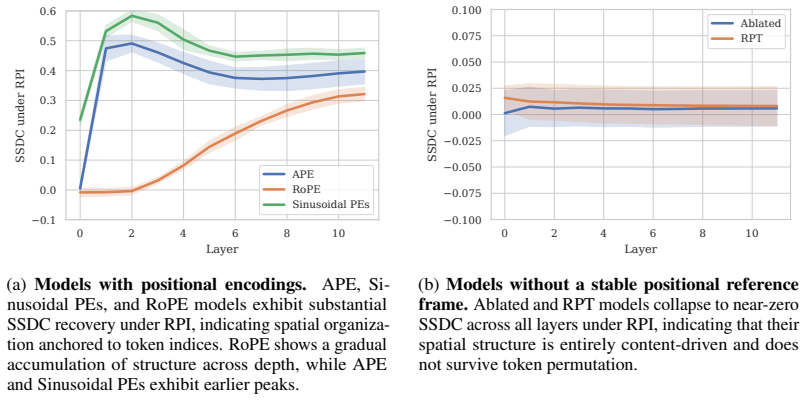
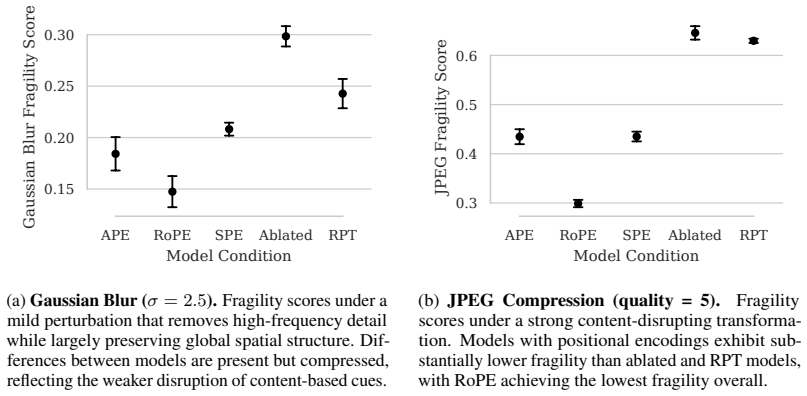
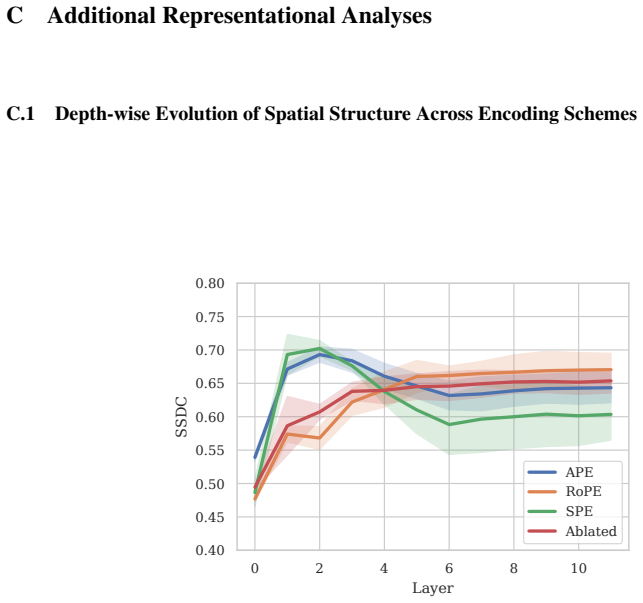
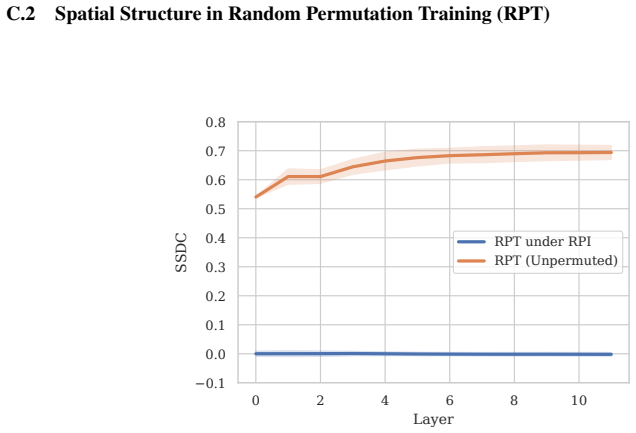
All positional encodings considered are associated with a consistent shift toward an index-anchored spatial organization; representations remain stable under content-disrupting perturbations and exhibit substantially improved robustness to such distributional shifts. Different encodings produce distinct depth-wise trajectories of spatial structure, yet their robustness properties remain largely similar, indicating that robustness depends primarily on the existence of a stable positional reference frame.
What carries the argument
The Spatial Similarity Distance Correlation (SSDC) metric, which measures the degree to which token representations exhibit spatial structure anchored to fixed indices rather than to visual content.
If this is right
- ViTs without positional encodings develop only content-driven spatial structure that collapses under token permutation.
- Models equipped with any of the tested positional encodings maintain spatial organization under the same permutations.
- Robustness to distributional shifts that disrupt content improves once a stable positional reference frame is present.
- Depth-wise trajectories of spatial structure differ across encoding schemes, but the resulting robustness levels stay comparable.
Where Pith is reading between the lines
- New encoding designs could be evaluated primarily by how reliably they supply a fixed reference frame rather than by their internal functional form.
- The same index-anchoring effect may appear in non-vision transformers if positional signals are supplied consistently across sequence positions.
- SSDC could be applied to intermediate layers of other vision models to test whether spatial stability predicts robustness on additional tasks such as detection or segmentation.
Load-bearing premise
The SSDC metric accurately quantifies the spatial structure responsible for robustness, and the associations observed indicate that a stable positional reference frame, rather than details of any particular encoding, is the main driver of the robustness gain.
What would settle it
Training a Vision Transformer with positional encoding yet finding no measurable gain in robustness to content-disrupting shifts, or finding that SSDC scores fail to track robustness levels across models.
Figures
read the original abstract
Positional embeddings (PEs) in Vision Transformers (ViTs) are known to impact performance and robustness, but their role in shaping internal spatial representations is not well understood. In this work, we study how different forms of PEs influence the representational geometry of ViTs and how these changes relate to robustness under content-disrupting distribution shifts. We introduce a metric, the Spatial Similarity Distance Correlation (SSDC), to quantify spatial structure in token representations. Using this metric, we show that ViTs trained without PEs still develop non-trivial spatial structure, but this structure is driven by visual content and collapses under token permutation. In contrast, we find that all PEs considered (learned absolute, sinusoidal, and rotary) are associated with a consistent shift toward an index-anchored spatial organization. Representations in these models remain stable under perturbations that disrupt content, and exhibit substantially improved robustness to such distributional shifts. We further show that while different PEs produce distinct depth-wise trajectories of spatial structure, their robustness properties are largely similar (with secondary variation across encoding schemes), suggesting that robustness appears to depend on the presence of a stable positional reference frame more than it depends on the specific encoding mechanism. These results offer a geometric account of how positional encodings shape internal representations, with implications for the principled design of future encoding schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that positional encodings (learned absolute, sinusoidal, rotary) in Vision Transformers induce a consistent shift toward index-anchored spatial organization in token representations, as measured by the new Spatial Similarity Distance Correlation (SSDC) metric. Without PEs, structure is content-driven and collapses under token permutation; with PEs, representations remain stable under content-disrupting perturbations and show substantially improved robustness to distributional shifts. Different PEs exhibit distinct depth-wise trajectories but largely similar robustness, implying that a stable positional reference frame (rather than specific encoding details) is the primary driver.
Significance. If the empirical associations hold after proper validation, the work supplies a geometric account of how PEs shape ViT internal representations and links this structure to robustness gains. The SSDC metric, if shown to be reliable and non-circular, could become a useful diagnostic for representational geometry in transformers. The result that robustness is largely insensitive to PE variant once a reference frame is present would have direct implications for principled PE design.
major comments (2)
- [Abstract] Abstract: the claims that all tested PEs produce index-anchored structure, that this structure is stable under content disruption, and that it yields robustness gains are stated at a high level with no experimental details, dataset descriptions, controls, statistical tests, or validation of the SSDC metric itself. Without these, it is impossible to assess whether the reported associations support the central geometric interpretation.
- [Abstract] The manuscript treats SSDC as quantifying the spatial structure that drives robustness, yet provides no ablation, comparison to alternative metrics, or perturbation analysis showing that SSDC scores are not confounded by other representational properties. This assumption is load-bearing for the claim that the reference frame (rather than PE-specific details) is the causal factor.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The concerns focus on the level of detail in the abstract and the need for further validation of the SSDC metric. We address each point below and agree to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that all tested PEs produce index-anchored structure, that this structure is stable under content disruption, and that it yields robustness gains are stated at a high level with no experimental details, dataset descriptions, controls, statistical tests, or validation of the SSDC metric itself. Without these, it is impossible to assess whether the reported associations support the central geometric interpretation.
Authors: We agree the abstract is high-level. The full manuscript reports experiments on ImageNet-1k (and additional datasets in the supplement), using standard ViT-B/16 and ViT-S/16 architectures. Controls include no-PE baselines, token-permutation tests to isolate content-driven vs. index-anchored structure, and depth-wise trajectory analyses. Statistical support includes Pearson correlations and significance tests between SSDC and robustness metrics (reported in Sections 4 and 5). SSDC validation appears via its differential behavior under permutation (collapses without PEs, stable with PEs) and its alignment with robustness gains. We will revise the abstract to concisely note the primary dataset, the no-PE control, and the key quantitative robustness improvement (e.g., average accuracy lift under shifts). revision: yes
-
Referee: [Abstract] The manuscript treats SSDC as quantifying the spatial structure that drives robustness, yet provides no ablation, comparison to alternative metrics, or perturbation analysis showing that SSDC scores are not confounded by other representational properties. This assumption is load-bearing for the claim that the reference frame (rather than PE-specific details) is the causal factor.
Authors: We acknowledge the absence of explicit ablations against alternative metrics. The manuscript demonstrates SSDC's specificity through (i) its increase with depth only when PEs are present, (ii) invariance to content permutation exclusively in PE models, and (iii) similar robustness across PE variants despite distinct depth trajectories. Nevertheless, direct comparisons to other measures (e.g., mean pairwise cosine similarity) and additional perturbation tests (beyond permutation) are not included. We will add an appendix with these ablations and a sensitivity analysis to confirm SSDC isolates the index-anchored component. This revision will directly support the claim that a stable reference frame, rather than PE-specific details, drives the observed robustness. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is empirical in nature: it introduces the SSDC metric to measure spatial structure in token representations, then reports observed associations between different positional encodings (learned absolute, sinusoidal, rotary) and shifts toward index-anchored organization, along with corresponding robustness gains under content-disrupting shifts. No load-bearing step reduces by the paper's own equations to a fitted input, self-definition, or self-citation chain; the central claims rest on experimental comparisons rather than mathematical identities or ansatzes smuggled via prior work. The derivation chain is self-contained against external benchmarks because the metric and robustness evaluations are defined and measured independently of the target conclusions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[2]
The Eleventh International Conference on Learning Representations , year=
Conditional Positional Encodings for Vision Transformers , author=. The Eleventh International Conference on Learning Representations , year=
-
[3]
Advances in Neural Information Processing Systems , editor=
Do Vision Transformers See Like Convolutional Neural Networks? , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[4]
International Conference on Learning Representations , year=
How much Position Information Do Convolutional Neural Networks Encode? , author=. International Conference on Learning Representations , year=
-
[5]
Thirty-seventh Conference on Neural Information Processing Systems , year=
The Impact of Positional Encoding on Length Generalization in Transformers , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[6]
Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining , booktitle =. 2021 , pages =. doi:10.1109/ICCV48922.2021.00986 , url =
-
[7]
d’Ascoli, Stéphane and Touvron, Hugo and Leavitt, Matthew L and Morcos, Ari S and Biroli, Giulio and Sagun, Levent , title =. 2022 , month =. doi:10.1088/1742-5468/ac9830 , url =
-
[8]
I ncorporating R esidual and N ormalization L ayers into A nalysis of M asked L anguage M odels
Kobayashi, Goro and Kuribayashi, Tatsuki and Yokoi, Sho and Inui, Kentaro. I ncorporating R esidual and N ormalization L ayers into A nalysis of M asked L anguage M odels. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.373
-
[9]
Proceedings of the 38th International Conference on Machine Learning , pages =
Attention is not all you need: pure attention loses rank doubly exponentially with depth , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
2021
-
[10]
Understanding Robustness of Transformers for Image Classification , doi =
Bhojanapalli, Srinadh and Chakrabarti, Ayan and Glasner, Daniel and Li, Daliang and Unterthiner, Thomas and Veit, Andreas , year =. Understanding Robustness of Transformers for Image Classification , doi =
-
[11]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Vision Transformers Are Robust Learners , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2022 , month=. doi:10.1609/aaai.v36i2.20103 , number=
-
[13]
Wichmann and Wieland Brendel , booktitle=
Robert Geirhos and Patricia Rubisch and Claudio Michaelis and Matthias Bethge and Felix A. Wichmann and Wieland Brendel , booktitle=. ImageNet-trained. 2019 , url=
2019
-
[14]
Heo, Byeongho and Park, Song and Han, Dongyoon and Yun, Sangdoo , title =. 2024 , isbn =. doi:10.1007/978-3-031-72684-2_17 , booktitle =
-
[15]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Towards Robust Vision Transformer , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[16]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.