Multimodal Music Recommendation System using LLMs
Pith reviewed 2026-06-29 05:16 UTC · model grok-4.3
The pith
Integrating audio embeddings, lyric features, LLM-generated metadata, and listening ratios into an LLM-based sequential recommender lifts recall up to 95% over ID-only baselines on music data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
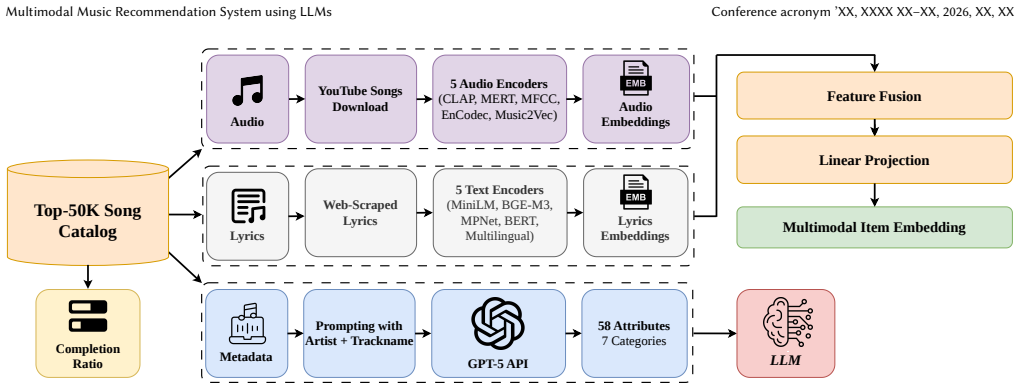
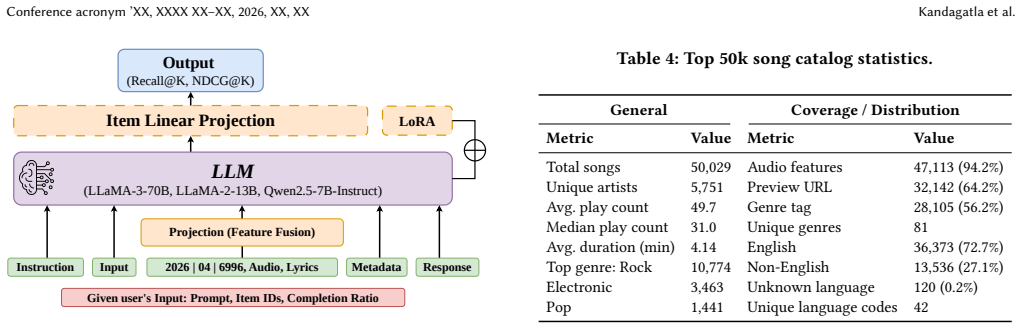
The authors propose enriching the E4SRec sequential recommendation framework with multimodal features drawn from pretrained audio and text models, MGPHot LLM annotations, and listening ratios, then evaluate the extensions on LastFM-1K using backbones including SASRec, BERT4Rec, GRU4Rec and LLMs such as LLaMa-2-13B, Qwen2.5-7B-Instruct, and LLaMa-3-70B. This yields improvements of up to 95% in Recall and 79% in NDCG over ID-only baselines, while showing that naive multimodal fusion does not always improve results and releasing the resulting large-scale multimodal music benchmark.
What carries the argument
E4SRec sequential recommendation framework extended by multimodal item representations from pretrained audio/lyric models plus MGPHot-generated metadata.
If this is right
- Content-based signals can produce large lifts in session-based music recommendation when added to interaction-history models.
- Different backbone encoders can be swapped into the multimodal E4SRec setup while retaining the gains.
- Naive concatenation or simple fusion of modalities does not guarantee further additive improvements.
- A publicly released multimodal version of LastFM-1K supports additional experiments on content-aware music rec.
Where Pith is reading between the lines
- The same enrichment strategy could be tested in video or product recommendation if comparable pretrained content embeddings are available.
- More sophisticated cross-modal fusion layers may be required to avoid the non-additive results observed with naive integration.
- The benchmark release makes it possible to measure whether the reported gains hold when the underlying music catalog or user population changes.
Load-bearing premise
The three content signals extracted from pretrained models can be added to E4SRec without introducing substantial noise that would demand custom fusion architectures beyond the tested extensions.
What would settle it
Re-running the experiments after removing the pretrained embeddings and MGPHot metadata, or testing the same pipeline on a different music listening dataset, and finding that the Recall and NDCG gains largely disappear.
Figures


read the original abstract
Music recommendation systems typically treat songs as opaque tokens, relying on collaborative interaction histories which overlooks semantic or acoustic content. Prior work has explored LLM-augmented, multimodal, and text-enhanced approaches to sequential recommendation, and while some methods partially combine semantic, acoustic, or engagement signals, none jointly model all three within a unified LLM-based sequential reasoning framework that grounds recommendations in actual song content. In this work, we propose a multimodal framework for session-based music recommendation that enriches the LastFM-1K dataset with three complementary signals: (1) audio and lyric embeddings extracted using pretrained music and text representation models, (2) LLM-generated semantic metadata using the MGPHot annotation schema, and (3) listening completion ratios. We adopt the E4SRec framework by extending it with multimodal features and different item ID encoder backbones, including SASRec, BERT4Rec, and GRU4Rec. We further extend the LLM backbone option with LLaMa-2-13B, Qwen2.5-7B-Instruct, and LLaMa-3-70B in both zero-shot and fine-tuned settings. Our experiments show that integrating content-based features improves over ID-only baselines up to 95% in terms of Recall and 79% in terms of NDCG. Moreover, our experiments show that naive multimodal fusion does not always yield additive improvements, highlighting challenges in cross-modal integration. We release a large-scale multimodal benchmark for music recommendation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multimodal extension to the E4SRec sequential recommendation framework for music, enriching LastFM-1K with three signals (pretrained audio/lyric embeddings, MGPHot LLM-generated metadata, and listening completion ratios) and testing multiple backbones (SASRec, BERT4Rec, GRU4Rec, plus LLaMa-2-13B/Qwen2.5-7B/LLaMa-3-70B in zero-shot and fine-tuned modes). It reports gains of up to 95% Recall and 79% NDCG over ID-only baselines while noting that naive multimodal fusion is not always additive, and releases the resulting benchmark.
Significance. If the headline gains prove robust under controlled conditions, the work would provide a concrete demonstration that jointly modeling acoustic, semantic, and engagement signals inside an LLM-based sequential model can substantially outperform ID-only baselines in music recommendation; the released multimodal benchmark would also be a reusable asset for the community.
major comments (2)
- [Abstract] Abstract: the central empirical claim (up to 95% Recall / 79% NDCG gains) is presented without statistical significance tests, exact baseline hyper-parameter configurations, or explicit controls for data leakage between the pretrained embedding models and the recommendation splits; these omissions are load-bearing for attributing the gains to the multimodal signals rather than experimental artifacts.
- [Abstract] Abstract: the explicit caveat that 'naive multimodal fusion does not always yield additive improvements' indicates that the reported peak numbers may be specific to particular backbone+fusions combinations (SASRec/BERT4Rec/GRU4Rec or the listed LLMs) rather than a general property of integrating the three signals; without ablations that isolate each signal and each fusion strategy, the improvement cannot be confidently attributed to the multimodal enrichment itself.
minor comments (2)
- The manuscript would benefit from a dedicated methods subsection that precisely defines the fusion operator (concatenation, attention, etc.) used when extending E4SRec with the three signals.
- Consider reporting per-backbone and per-fusion results in a single table so readers can directly compare the contribution of each signal.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments point-by-point below, agreeing where revisions are needed and providing clarifications on experimental controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (up to 95% Recall / 79% NDCG gains) is presented without statistical significance tests, exact baseline hyper-parameter configurations, or explicit controls for data leakage between the pretrained embedding models and the recommendation splits; these omissions are load-bearing for attributing the gains to the multimodal signals rather than experimental artifacts.
Authors: We agree these details strengthen attribution. Hyper-parameter configurations for baselines (SASRec, BERT4Rec, GRU4Rec) and LLM variants are specified in Section 4.2 and Appendix A. We will add statistical significance testing (paired t-tests over 5 random seeds) to the main results tables. For data leakage, the audio/lyric embeddings come from fixed pretrained models trained on external corpora (e.g., large music audio datasets and general text corpora) with no overlap to LastFM-1K interaction splits; MGPHot metadata generation uses only public song attributes without test-set leakage. We will insert an explicit control statement in Section 3.2 and update the abstract to reference these. revision: yes
-
Referee: [Abstract] Abstract: the explicit caveat that 'naive multimodal fusion does not always yield additive improvements' indicates that the reported peak numbers may be specific to particular backbone+fusions combinations (SASRec/BERT4Rec/GRU4Rec or the listed LLMs) rather than a general property of integrating the three signals; without ablations that isolate each signal and each fusion strategy, the improvement cannot be confidently attributed to the multimodal enrichment itself.
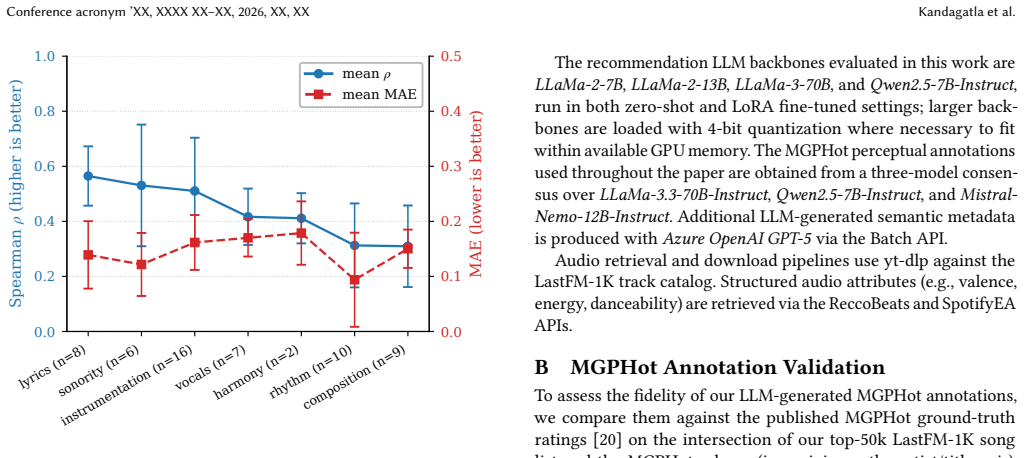
Authors: The manuscript already reports results across multiple backbones and fusion variants, with the explicit caveat underscoring that gains are configuration-dependent rather than universal. This supports attribution to the multimodal signals when effective fusion occurs. To isolate contributions further, we will add targeted ablations (removing one signal at a time: audio-only, lyrics-only, metadata-only, completion-ratio-only) and compare fusion strategies (early concatenation vs. late fusion) in a new subsection of the experiments. revision: yes
Circularity Check
No significant circularity; empirical results only
full rationale
The paper describes an empirical framework that extends the existing E4SRec model with multimodal features (audio/lyric embeddings, MGPHot metadata, listening ratios) extracted from pretrained models and evaluates performance on LastFM-1K against ID-only baselines. No equations, derivations, or mathematical predictions are present. All reported gains (Recall/NDCG) are direct experimental outcomes rather than quantities fitted or renamed from the inputs. Self-citations, if any, are not load-bearing for the central claim, which rests on controlled comparisons. This matches the default case of a self-contained empirical study with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM fine-tuning hyperparameters
axioms (1)
- domain assumption Pretrained music and text representation models produce embeddings that are relevant and compatible for music recommendation tasks.
Reference graph
Works this paper leans on
-
[1]
Davide Abbattista, Vito Walter Anelli, Tommaso Di Noia, Craig Macdonald, and Aleksandr Petrov. 2024. Enhancing Sequential Music Recommendation with Personalized Popularity Awareness. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). ACM, Bari, Italy, 1168–1173. doi:10.1145/ 3640457.3691719
-
[2]
O. Celma. 2010.Music Recommendation and Discovery in the Long Tail. Springer. Available at http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html
2010
-
[3]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Seungheon Doh, Keunwoo Choi, and Juhan Nam. 2025. Talkplay: Multimodal mu- sic recommendation with large language models.arXiv preprint arXiv:2502.13713 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Wei-Wei Du, Takuma Udagawa, and Kei Tateno. 2025. Not Just What, But When: Integrating Irregular Intervals to LLM for Sequential Recommendation. In Proceedings of the Nineteenth ACM Conference on Recommender Systems. 637–642
2025
-
[6]
Ramin Giahi, Kehui Yao, Sriram Kollipara, Kai Zhao, Vahid Mirjalili, Jianpeng Xu, Topojoy Biswas, Evren Korpeoglu, and Kannan Achan. 2025. Vl-clip: Enhancing multimodal recommendations via visual grounding and llm-augmented clip embeddings. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 482–491
2025
-
[7]
Casper Hansen, Christian Hansen, Lucas Maystre, Rishabh Mehrotra, Brian Brost, Federico Tomasi, and Mounia Lalmas. 2020. Contextual and sequential user embeddings for large-scale music recommendation. InProceedings of the 14th ACM Conference on Recommender Systems. 53–62
2020
-
[8]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
- [9]
- [10]
-
[11]
Yizhi Li, Ruibin Yuan, Ge Zhang, Yinghao Ma, Xingran Chen, Hanzhi Yin, Cheng- hao Xiao, Chenghua Lin, Anton Ragni, Emmanouil Benetos, et al. 2024. Mert: Acoustic music understanding model with large-scale self-supervised training. InInternational Conference on Learning Representations, Vol. 2024. 12181–12204
2024
- [12]
-
[13]
Yutong Li and Xinyi Zhang. 2025. MDSBR: Multimodal Denoising for Session- based Recommendation. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 268–278
2025
-
[14]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. Llara: Large language-recommendation assistant. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1785–1795
2024
-
[15]
Enze Liu, Bowen Zheng, Wayne Xin Zhao, and Ji-Rong Wen. 2025. Bridging Textual-Collaborative Gap through Semantic Codes for Sequential Recommenda- tion. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 1788–1798
2025
- [16]
-
[17]
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, Oriol Nieto, et al. 2015. librosa: Audio and music signal analysis in python.SciPy2015, 18-24 (2015), 7
2015
-
[18]
Marta Moscati, Emilia Parada-Cabaleiro, Yashar Deldjoo, Eva Zangerle, and Markus Schedl. 2022. Music4All-Onion–A Large-Scale Multi-faceted Content- Centric Music Recommendation Dataset. InProceedings of the 31st ACM Interna- tional Conference on Information & Knowledge Management. 4339–4343
2022
-
[19]
Shanlei Mu, Yaliang Li, Wayne Xin Zhao, Siqing Li, and Ji-Rong Wen. 2021. Knowledge-guided disentangled representation learning for recommender sys- tems.ACM Transactions on Information Systems (TOIS)40, 1 (2021), 1–26
2021
-
[20]
Sergio Oramas, Fabien Gouyon, Steve Hogan, Camilo Landau, and Andreas Ehmann. 2025. Mgphot: A dataset of musicological annotations for popular music (1958–2022).Transactions of the International Society for Music Information Retrieval8, 1 (2025)
2025
-
[21]
Sergio Oramas, Oriol Nieto, Mohamed Sordo, and Xavier Serra. 2017. A deep multimodal approach for cold-start music recommendation. InProceedings of the 2nd workshop on deep learning for recommender systems. 32–37
2017
- [22]
-
[23]
Claudio Pomo, Matteo Attimonelli, Danilo Danese, Fedelucio Narducci, and Tommaso Di Noia. 2025. Do recommender systems really leverage multimodal content? a comprehensive analysis on multimodal representations for recommen- dation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 2377–2387
2025
- [24]
- [25]
-
[26]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[27]
BPR: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618(2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[28]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[29]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Yan-Martin Tamm and Anna Aljanaki. 2024. Comparative analysis of pretrained audio representations in music recommender systems. InProceedings of the 18th ACM Conference on Recommender Systems. 934–938
2024
-
[31]
Viet-Anh Tran, Guillaume Salha-Galvan, Bruno Sguerra, and Romain Hennequin
-
[32]
InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24)
Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). ACM, Bari, Italy, 486–496. doi:10.1145/3640457.3688139
-
[33]
Kunal Vaswani, Yudhik Agrawal, and Vinoo Alluri. 2021. Multimodal fusion based attentive networks for sequential music recommendation. In2021 IEEE seventh international conference on multimedia big data (BigMM). IEEE, 25–32
2021
-
[34]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval. 165–174
2019
-
[35]
Yu Wang, Lei Sang, Yi Zhang, and Yiwen Zhang. 2025. Intent representation learning with large language model for recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1870–1879
2025
-
[36]
Minz Won, Yun-Ning Hung, and Duc Le. 2024. A foundation model for music informatics. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1226–1230
2024
-
[37]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[38]
Jinfeng Xu, Zheyu Chen, Jinze Li, Shuo Yang, Hewei Wang, Yijie Li, Mengran Li, Puzhen Wu, and Edith CH Ngai. 2025. Mdvt: Enhancing multimodal recommen- dation with model-agnostic multimodal-driven virtual triplets. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3378–3389
2025
-
[39]
Feng Yu, Yanqiao Zhu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2020. TAGNN: Target attentive graph neural networks for session-based recommenda- tion. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 1921–1924
2020
-
[40]
Zheng Yuan, Fajie Yuan, Yu Song, Youhua Li, Junchen Fu, Fei Yang, Yunzhu Pan, and Yongxin Ni. 2023. Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited. InSIGIR. doi:10.1145/3539618. 3591932
-
[41]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448. Conference acronym ’XX, XXXX XX–XX, 2026, XX, XX Kandagatla et al. lyrics (n=8)sonori...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.