ChurnNet: A Optimized Modern AI for Churn Prediction
Pith reviewed 2026-06-28 23:33 UTC · model grok-4.3
The pith
Traditional machine learning models outperform a modern multi-task time series model for customer churn prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that conventional machine learning methods can still outperform the Unified Multi-Task Time Series Model for churn prediction in terms of predictive performance, data efficiency, and computational resource requirements for training and deployment, with findings consistent across multiple datasets and various churn labeling techniques.
What carries the argument
The Unified Multi-Task Time Series Model, presented as a representative modern approach able to capture complex temporal dynamics and inter-variable relationships in time-series data for binary classification.
If this is right
- Traditional methods require less data to reach competitive results on churn tasks.
- They need fewer computational resources both to train and to deploy in production.
- They deliver better predictive performance than the tested modern model.
- The advantage remains stable when churn labels are defined in different ways.
Where Pith is reading between the lines
- For many binary classification problems in business, established methods may remain preferable unless the data exhibits strong temporal structure that simpler models cannot capture.
- The result suggests a need for more systematic head-to-head tests of new architectures against well-tuned classical baselines before deployment decisions.
- Companies focused on customer retention could achieve faster and cheaper implementation by starting with Random Forests or XGBoost rather than complex time-series models.
Load-bearing premise
The Unified Multi-Task Time Series Model functions as a fair and representative test case for modern AI methods on this task, and any performance difference is not caused by implementation details, hyperparameter choices, or dataset artifacts.
What would settle it
Showing that the Unified Multi-Task Time Series Model achieves strictly higher accuracy, precision, or recall than Random Forests, XGBoost, and SVMs on the same datasets and labeling schemes would falsify the central claim.
Figures
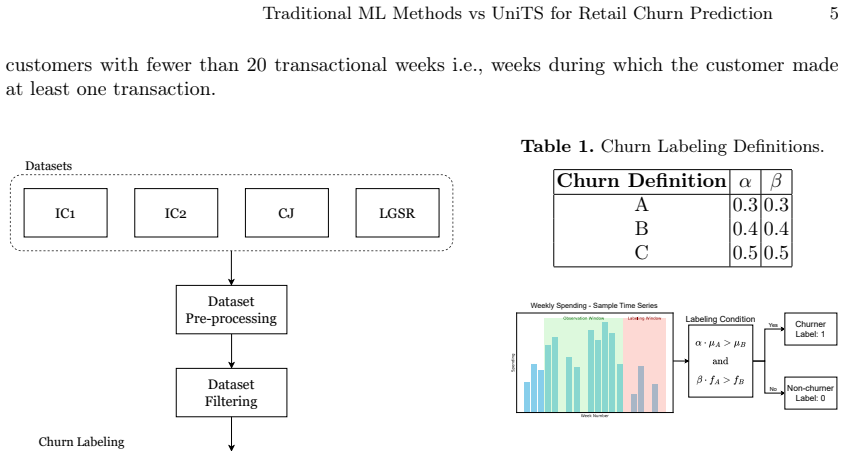
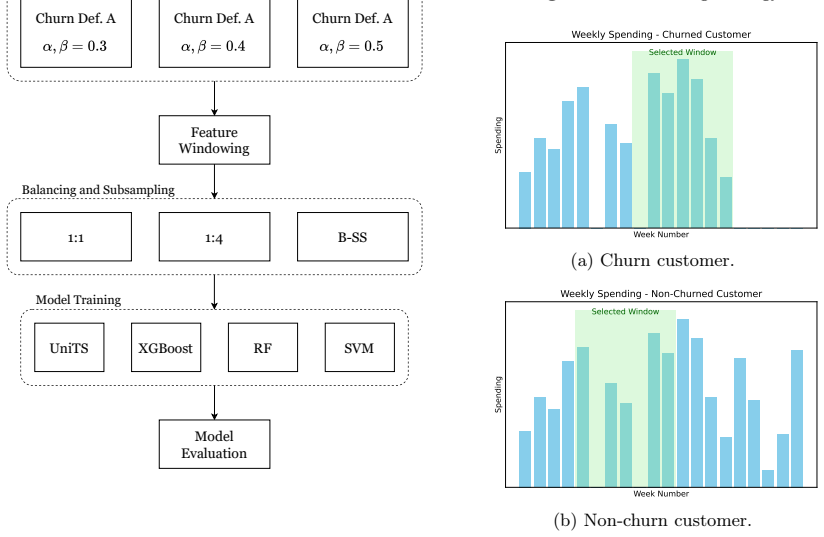
read the original abstract
Increased competition and the growing similarity of products and services offered by retailers have lowered the barriers for customers to switch to competitors. Accurate churn prediction can be a valuable tool for driving effective personalized marketing campaigns and helping to reduce customer attrition. This study evaluates the performance of traditional machine learning techniques, namely, Random Forests, XGBoost, and Support Vector Machines, and compares them with the Unified Multi-Task Time Series Model for churn prediction, a binary time-series classification task. Despite the strong capacity of the latter to model complex temporal dynamics and inter-variable relationships, our results indicate that for churn prediction, conventional methods can still outperform it in terms of predictive performance, data efficiency, and computational resource requirements for training and deployment. These findings are consistent across multiple datasets and various churn labeling techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates traditional machine learning techniques (Random Forests, XGBoost, SVM) against the Unified Multi-Task Time Series Model on churn prediction as a binary time-series classification task. It claims that conventional methods outperform the modern model in predictive performance, data efficiency, and computational requirements for training/deployment, with consistency across multiple datasets and churn labeling techniques.
Significance. If the head-to-head comparison is shown to be fair and the gaps are robust, the result would indicate that modern time-series architectures do not automatically confer advantages for this task and could guide practitioners toward simpler, more efficient baselines. The abstract, however, contains no quantitative metrics, dataset details, or statistical tests, so the magnitude and reliability of the claimed superiority cannot be assessed from the provided text.
major comments (2)
- [Abstract] Abstract: the central claim of consistent outperformance is asserted without any reported metrics (accuracy, AUC, F1, etc.), statistical tests, dataset sizes, or ablation results, so the degree to which the data supports the claim cannot be verified.
- [Abstract] Abstract / Methods: no information is supplied on the Unified Multi-Task Time Series Model architecture depth, sequence-length handling, training schedule, regularization, or hyperparameter search procedure; without these details the performance, data-efficiency, and compute gaps cannot be attributed to intrinsic model limitations rather than implementation artifacts.
minor comments (1)
- The manuscript title refers to 'ChurnNet' yet the abstract and claim focus exclusively on the Unified Multi-Task Time Series Model; the relationship between the two should be clarified.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract and methods sections require additional quantitative details and implementation specifics to strengthen the manuscript. We have revised accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent outperformance is asserted without any reported metrics (accuracy, AUC, F1, etc.), statistical tests, dataset sizes, or ablation results, so the degree to which the data supports the claim cannot be verified.
Authors: We agree that the abstract should include supporting quantitative evidence. The revised abstract now reports key metrics (AUC, F1, accuracy) from the main experiments, notes dataset sizes, and references the statistical tests performed. These values were already present in the results tables but are now summarized upfront. revision: yes
-
Referee: [Abstract] Abstract / Methods: no information is supplied on the Unified Multi-Task Time Series Model architecture depth, sequence-length handling, training schedule, regularization, or hyperparameter search procedure; without these details the performance, data-efficiency, and compute gaps cannot be attributed to intrinsic model limitations rather than implementation artifacts.
Authors: We accept this point. The revised Methods section now specifies the model depth and layer configuration, sequence-length padding/truncation strategy, training schedule (epochs, learning rate, optimizer), regularization (dropout, weight decay), and the grid/random search procedure with the exact hyperparameter ranges explored. This makes the comparison transparent. revision: yes
Circularity Check
No circularity; empirical head-to-head comparison is self-contained
full rationale
The paper reports an empirical evaluation of Random Forests, XGBoost, SVM versus the Unified Multi-Task Time Series Model on churn prediction across datasets and labeling schemes. The central claim (traditional methods outperform on performance, data efficiency, and compute) is grounded in observed metrics rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that reduce the result to its inputs by construction. The comparison is externally falsifiable by re-running the experiments with stated hyperparameters and data splits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2022 2nd International Conference on Computer, Control and Robotics (ICCCR)
Agbemadon, K.B., Couturier, R., Laiymani, D.: Churn detection using machine learning in the retail industry. In: 2022 2nd International Conference on Computer, Control and Robotics (ICCCR). pp. 172–178 (March 2022).https://doi.org/10.1109/ICCCR54399.2022.9790213,
-
[2]
Baghla, S., Gupta, G.: Performance evaluation of various classification techniques for customer churn prediction in e-commerce. Microprocessors and Microsystems94, 104680 (2022).https: //doi.org/https://doi.org/10.1016/j.micpro.2022.104680,https://www.sciencedirect.com/ science/article/pii/S0141933122002101
-
[3]
SN Computer Science5(4), 404 (2024)
Barsotti, A., Gianini, G., Mio, C., Lin, J., Babbar, H., Singh, A., Taher, F., Damiani, E.: A decade of churn prediction techniques in the telco domain: A survey. SN Computer Science5(4), 404 (2024). https://doi.org/10.1007/s42979-024-02722-7
-
[4]
The Journal of Economic Perspectives26(2), 177–198 (2012)
Basker, E.: Supersize it: The growth of retail chains and the rise of the big-box store. The Journal of Economic Perspectives26(2), 177–198 (2012)
2012
-
[5]
Ecological Informatics60, 101137 (2020)
Benkendorf, D.J., Hawkins, C.P.: Effects of sample size and network depth on a deep learning approach to species distribution modeling. Ecological Informatics60, 101137 (2020)
2020
-
[6]
Boukrouh, I., Azmani, A.: Explainable machine learning models applied to predicting customer churn for e-commerce. IAES International Journal of Artificial Intelligence (IJ-AI)14(1), 286– 297 (2025).https://doi.org/10.11591/ijai.v14.i1.pp286-297,https://ijai.iaescore.com/ index.php/IJAI/article/view/25293,
-
[7]
Machine learning45(1), 5–32 (2001)
Breiman, L.: Random forests. Machine learning45(1), 5–32 (2001)
2001
-
[8]
Expert Systems with Applications28(3), 479–486 (2005)
Buckinx, W., Van den Poel, D.: Customer retention in the non-contractual retail setting: the role of purchase behavior. Expert Systems with Applications28(3), 479–486 (2005)
2005
-
[9]
In: International Conference on Data Mining (2019)
Chen, L., Wang, Y.: B2c e-commerce customer churn prediction based on k-means and svm. In: International Conference on Data Mining (2019)
2019
-
[10]
In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining
Chen, T., Guestrin, C.: Xgboost: A scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. pp. 785–794 (2016)
2016
-
[11]
Colli, N.C., Saif, S.S., Maggiore, G., Distante, D.: Artificial intelligence for customer churn prediction in non-contractual retail environments: A systematic literature review (2025), manuscript under peer review
2025
-
[12]
Coolwijk, S., Ziabari, S.S.M., Angileri, F.: Vision transformer approach to customer churn prediction radar chart image classification for non-subscription based e-commerce. In: Information Integration and Web Intelligence: 26th International Conference, IiWAS 2024, Bratislava, Slovak Republic, De- cember 2–4, 2024, Proceedings, Part II. p. 75–80. Springe...
-
[13]
Machine learning20(3), 273–297 (1995)
Cortes, C., Vapnik, V.: Support-vector networks. Machine learning20(3), 273–297 (1995)
1995
-
[14]
Gan, L.: Xgboost-based e-commerce customer loss prediction. Computational Intelligence and Neu- roscience2022(1), 1858300 (2022).https://doi.org/https://doi.org/10.1155/2022/1858300, https://onlinelibrary.wiley.com/doi/abs/10.1155/2022/1858300,
-
[15]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=nBOdYBptWW
Gao, S., Koker, T., Queen, O., Hartvigsen, T., Tsiligkaridis, T., Zitnik, M.: Units: A unified multi- task time series model. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=nBOdYBptWW
2024
-
[16]
IEEE Access10, 34567–34589 (2022).https://doi.org/10.1109/ACCESS.2022.3141592
Geiler, S., Affeldt, S., Nadif, M.: Machine learning techniques for customer churn prediction: A review. IEEE Access10, 34567–34589 (2022).https://doi.org/10.1109/ACCESS.2022.3141592
-
[17]
Gupta,R.,Sharma,N.:Churndetectionusingmachinelearningintheretailindustry.In:Proceedings of ICMLC (2021)
2021
-
[18]
International Journal of Retail & Distribution Management44(7), 694–712 (2016)
Hagberg, J., Sundstrom, M., Egels-Zandén, N.: The digitalization of retailing: an exploratory frame- work. International Journal of Retail & Distribution Management44(7), 694–712 (2016)
2016
-
[19]
2023, Astronomy and Com- puting, 44, 100728, doi:10.1016/j.ascom.2023.100728
J, S., Gangadhar, C., Arora, R.K., Renjith, P., Bamini, J., Chincholkar, Y.d.: E-commerce customer churn prevention using machine learning-based business intelligence strategy. Measurement: Sensors 27(2023).https://doi.org/10.1016/j.measen.2023.100728,https://www.sciencedirect.com/ science/article/pii/S2665917423000648
-
[20]
Expert Systems with Applications150, 113255 (2020)
Lee, H.J., Cho, S.B.: Machine learning-based customer churn prediction in home appliance rental business. Expert Systems with Applications150, 113255 (2020)
2020
-
[21]
IEEE Open Journal of the Computer Society5, 27–38 (2024).https://doi.org/10.1109/ OJCS.2023.3336904
Lee, N.T., Lee, H.C., Hsin, J., Fang, S.H.: Prediction of customer behavior changing via a hybrid approach. IEEE Open Journal of the Computer Society5, 27–38 (2024).https://doi.org/10.1109/ OJCS.2023.3336904
-
[22]
Manzoor, A., Qureshi, M.A., Kidney, E., Longo, L.: A review on machine learning methods for customer churn prediction and recommendations for business practitioners. IEEE Access12, 70434– 70463 (2024).https://doi.org/10.1109/ACCESS.2024.3402092 Traditional ML Methods vs UniTS for Retail Churn Prediction 15
-
[23]
Expert Systems with Applications40(16), 6225–6232 (2013)
Miguéis, V., Camanho, A., Falcão e Cunha, J.: Customer attrition in retailing: An application of mul- tivariate adaptive regression splines. Expert Systems with Applications40(16), 6225–6232 (2013). https://doi.org/https://doi.org/10.1016/j.eswa.2013.05.069,https://www.sciencedirect. com/science/article/pii/S0957417413003679,
-
[25]
Pondel, M., Wuczynski, M., Gryncewicz, W., Łysik, Ł., Hernes, M., Rot, A., Kozina, A.: Deep learn- ing for customer churn prediction in e-commerce decision support. vol. 1, p. 3 – 12 (2021).https:// doi.org/10.52825/bis.v1i.42,https://www.tib-op.org/ojs/index.php/bis/article/view/42
-
[26]
Rachid, A.D., Abdellah, A., Belaid, B., Rachid, L.: Clustering prediction techniques in defining and predicting customers defection: The case of e-commerce context. International Journal of Electrical and Computer Engineering (IJECE)8(4), 2367–2383 (2018).https://doi.org/10.11591/ijece. v8i4.pp2367-2383,https://ijece.iaescore.com/index.php/IJECE/article/view/8531
-
[27]
Rahib, M.A.A., Saha, N., Mia, R., Sattar, A.: Customer data prediction and analysis in e- commerce using machine learning. Bulletin of Electrical Engineering and Informatics13(4), 2624–2633 (2024).https://doi.org/10.11591/eei.v13i4.6420,https://www.beei.org/index. php/EEI/article/view/6420,
-
[28]
Journal of Marketing67(1), 77–99 (2003)
Reinartz, W., Kumar, V.: The impact of customer relationship characteristics on profitable lifetime duration. Journal of Marketing67(1), 77–99 (2003)
2003
-
[29]
Applied Computing and Informatics (2023)
Rodríguez, M., García, J.: Comparison of deep learning algorithms to predict customer churn within a local retail industry. Applied Computing and Informatics (2023)
2023
-
[30]
In: 2021 International Conference on Digital Society and Intelligent Systems (DSInS)
Rudd, D.H., Huo, H., Xu, G.: Causal analysis of customer churn using deep learning. In: 2021 International Conference on Digital Society and Intelligent Systems (DSInS). pp. 319–324 (2021). https://doi.org/10.1109/DSInS54396.2021.9670561
-
[31]
Seema, Gupta, G.: Development of fading channel patch based convolutional neural network models for customer churn prediction. International Journal of System Assurance Engineering and Man- agement15(1), 391–411 (January 2024).https://doi.org/10.1007/s13198-022-01759-,https: //ideas.repec.org/a/spr/ijsaem/v15y2024i1d10.1007_s13198-022-01759-2.html,
-
[32]
Shahabikargar, M., Beheshti, A., Zhang, X., Foo, J., Jolfaei, A.: A comprehensive survey on customer churn analysis studies. Journal of Information and Telecommunication0(0), 1–47 (2025).https: //doi.org/10.1080/24751839.2025.2528440,https://doi.org/10.1080/24751839.2025.2528440
-
[33]
Journal of Retailing and Consumer Services58, 102345 (2021)
Singh, R., Kapoor, M.: Understanding customer attrition at an individual level: a new model in grocery retail context. Journal of Retailing and Consumer Services58, 102345 (2021)
2021
-
[34]
v5i1.155,https://bright-journal.org/Journal/index.php/JADS/article/view/155,
Sunarya, P., Rahardja, U., Chen, S., Lic, Y.M., Hardini, M.: Deciphering digital social dynamics: A comparative study of logistic regression and random forest in predicting e-commerce customer behavior.JournalofAppliedDataSciences5(1),100–113(2024).https://doi.org/10.47738/jads. v5i1.155,https://bright-journal.org/Journal/index.php/JADS/article/view/155,
-
[35]
In: International Conference on Learning Representations (2023)
Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., Long, M.: Timesnet: Temporal 2d-variation modeling for general time series analysis. In: International Conference on Learning Representations (2023)
2023
-
[36]
arXiv preprint arXiv:2202.06258 (2022)
Wu, H., Wu, J., Xu, J., Wang, J., Long, M.: Flowformer: Linearizing transformers with conservation flows. arXiv preprint arXiv:2202.06258 (2022)
-
[37]
Journal of Retail Analytics18, 122–135 (2022)
Zhang, R., Kim, J.: Customer churn in retail e-commerce business: spatial and machine learning approach. Journal of Retail Analytics18, 122–135 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.