A Pre-Training Analogue of Grokking in Language Models: Tracing Delayed Grammatical Generalization
Pith reviewed 2026-06-28 22:57 UTC · model grok-4.3
The pith
Language models show delayed generalization on grammatical tasks long after relevant phrases first appear in pre-training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
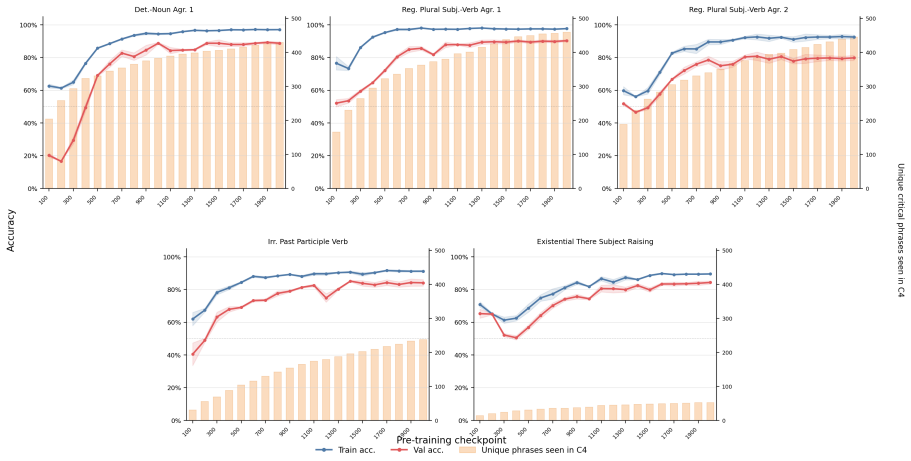
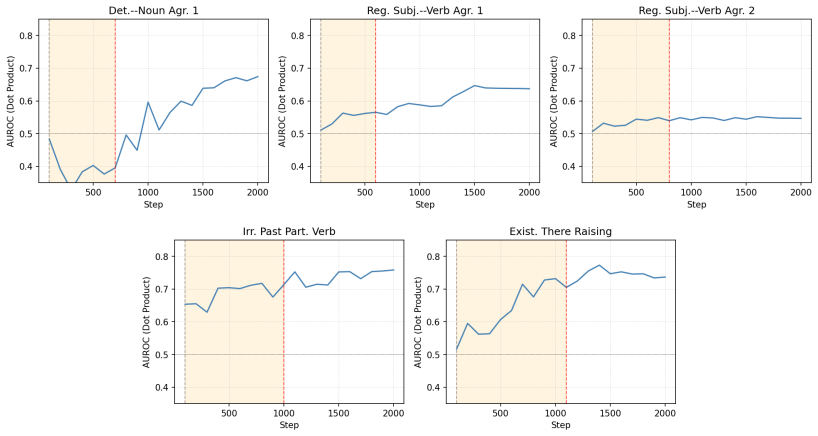
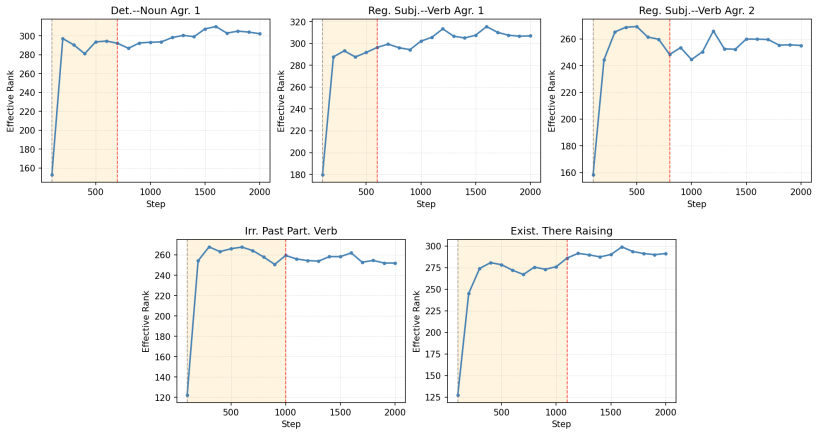
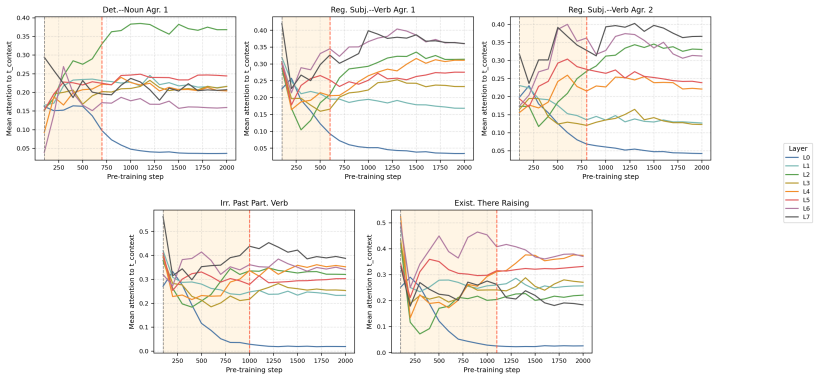
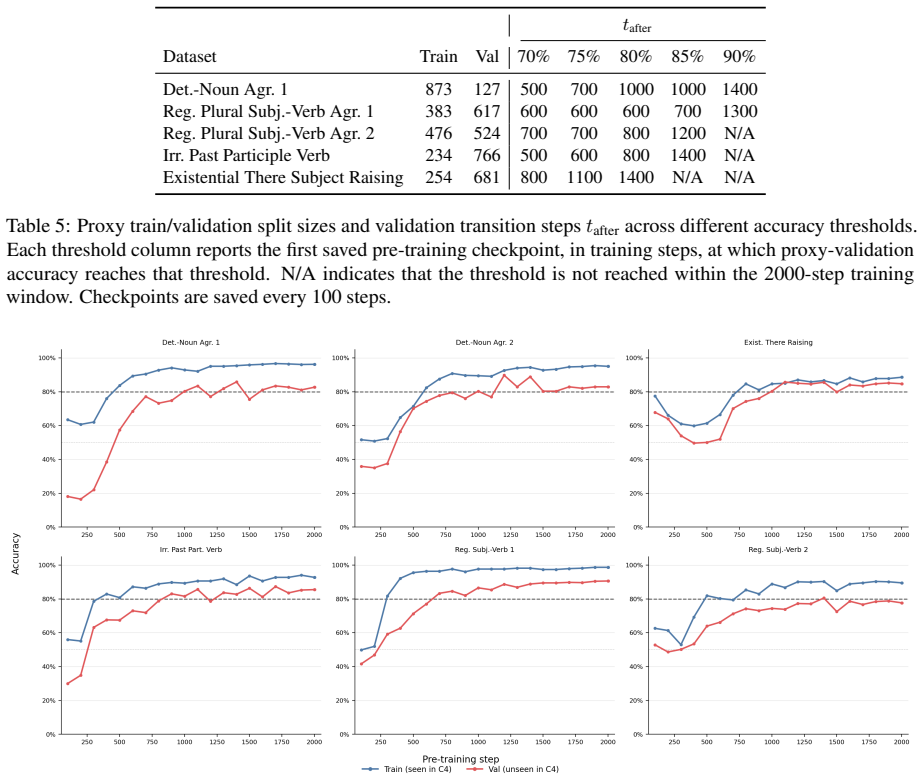
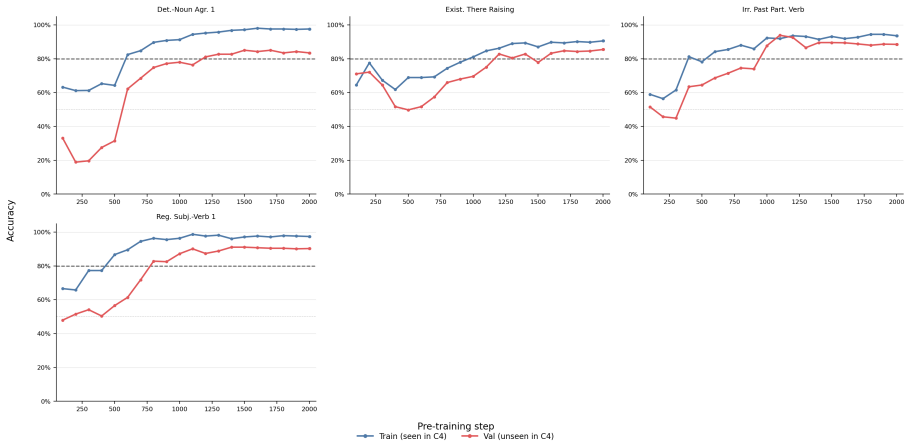
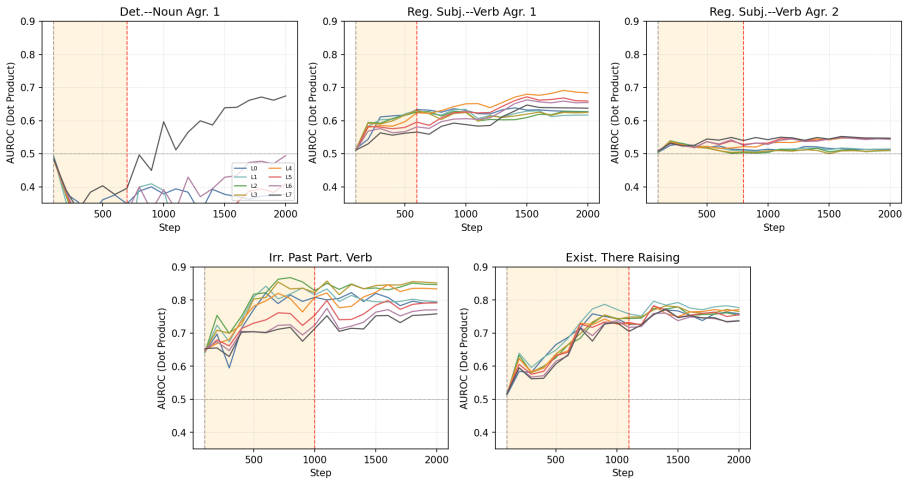
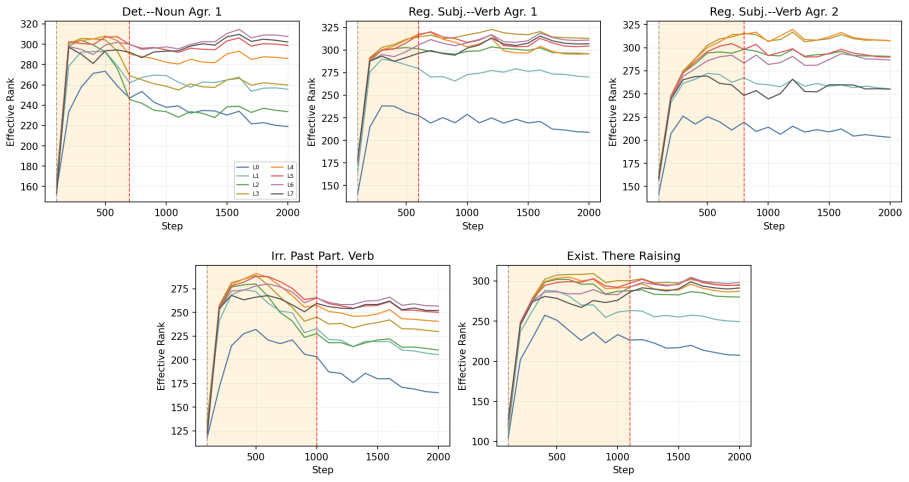
Across five grammatical phenomena, delayed generalization is observed on the proxy-validation split. After the generalization point, grammatical concept vectors become more predictive of acceptability judgments and occupy a higher-dimensional subspace. Attention from the critical token concentrates on the relevant context token in only a small number of heads.
What carries the argument
The exposure-based proxy-train and proxy-validation split, which assigns each BLiMP minimal pair according to whether its critical phrase has already appeared in the pre-training window.
If this is right
- Grammatical generalization on unseen minimal pairs occurs only after sufficient exposure to the critical phrase.
- Concept vectors extracted from model activations become stronger predictors of acceptability once generalization has taken place.
- The linear subspace spanned by these concept vectors expands in dimension after the generalization threshold.
- A small subset of attention heads carries most of the relevant token-to-context information at the generalization point.
Where Pith is reading between the lines
- The same exposure-tracking method could be applied to other emergent capabilities to test whether delayed generalization is a general feature of pre-training.
- If the proxy split is reliable, training schedules that deliberately increase the frequency of rare critical phrases might shorten the delay before generalization.
- Changes in concept-vector dimensionality and predictiveness could serve as internal signals that generalization is about to occur on a given phenomenon.
Load-bearing premise
Whether a critical phrase has appeared in the pre-training window cleanly isolates the effect of data exposure from all other patterns that happen to co-occur in the corpus.
What would settle it
No correlation between the first appearance of a critical phrase in the pre-training data and the timing of generalization on the corresponding proxy-validation examples would falsify the exposure-driven account.
Figures
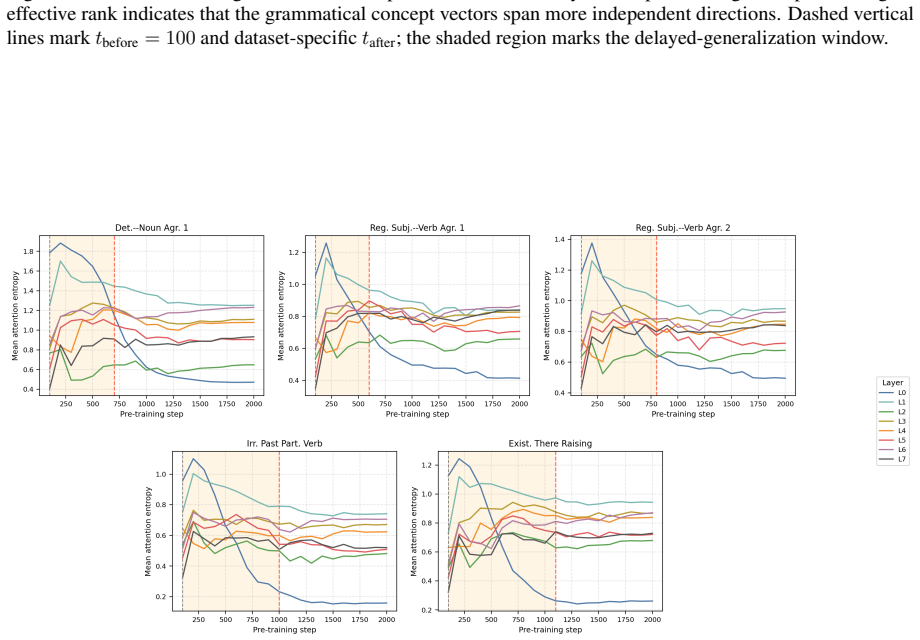
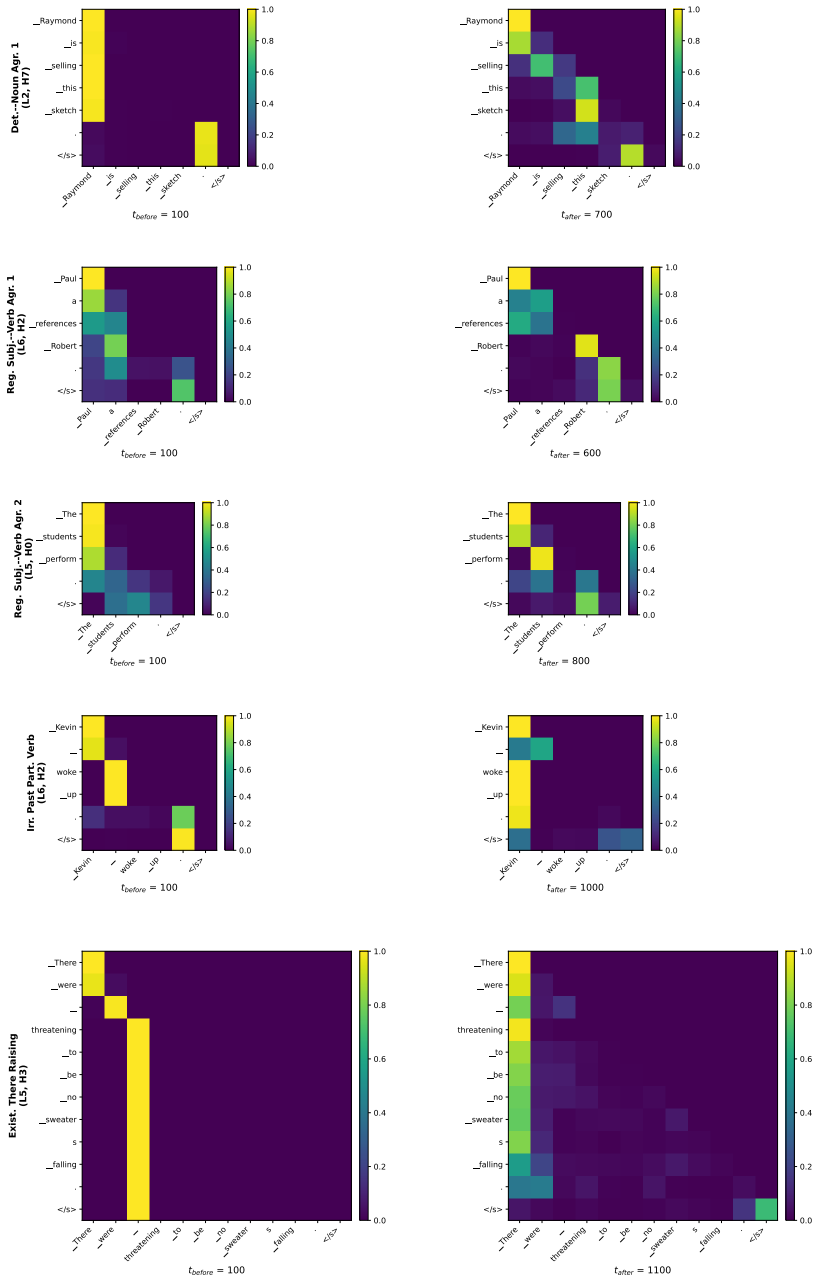
read the original abstract
Grokking, the phenomenon in which neural networks generalize long after fitting their training data, has been studied in supervised settings on many epochs. LLM pre-training instead involves next-token prediction over an unlabeled corpus, with limited data repetition and no explicit train/validation split. To address this, we propose an exposure-based framework that enables the study of grokking-like dynamics during LLM pre-training. We ground our evaluation in BLiMP minimal pairs, which provide controlled grammatical contrasts. For every BLiMP minimal pair, we identify a critical phrase, the smallest continuous span that captures the grammatical contrast and the phenomenon-relevant context. Examples whose critical phrase appears in the pre-training window are assigned to the proxy-train split; the remaining examples are assigned to the proxy-validation split. Across five grammatical phenomena, we observe delayed generalization. Analyzing pre-training checkpoints before and after generalization shows that grammatical concept vectors become more predictive of grammatical acceptability and occupy a higher-dimensional subspace after generalization. We also find that attention from the critical token to the relevant context token is concentrated in a small number of heads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an exposure-based framework to study grokking-like delayed generalization during LLM pre-training. For BLiMP minimal pairs, it identifies a critical phrase capturing the grammatical contrast, assigns examples to a proxy-train split if the phrase appears in the pre-training window and to proxy-validation otherwise, and reports delayed generalization on the proxy-validation set across five grammatical phenomena. Checkpoint analysis shows grammatical concept vectors become more predictive of acceptability and occupy higher-dimensional subspaces after generalization, with attention from the critical token concentrated in a small number of heads.
Significance. If the proxy framework validly isolates exposure effects and the reported patterns hold with quantitative support, the work supplies a concrete method for tracing delayed generalization in large-scale unsupervised pre-training and links internal representation changes to grammatical acquisition, extending grokking studies beyond supervised toy settings.
major comments (2)
- [Abstract / Methods (proxy split)] Abstract / proxy-split definition: the assignment of examples to proxy-train versus proxy-validation rests solely on whether the critical phrase appears in the pre-training window. This definition does not include reported controls for lexical overlap, syntactic neighbors, or semantic similarity outside the phrase span; if such confounders drive incremental corpus statistics, the observed delay on proxy-validation cannot be attributed to a grokking-like mechanism triggered by exposure to the grammatical contrast.
- [Abstract / Results] Results (delayed generalization claims): the abstract states that delayed generalization is observed across five phenomena, yet supplies no quantitative metrics (e.g., accuracy curves, delay measured in tokens or steps, error bars, or statistical tests comparing pre- and post-generalization performance). Without these, the magnitude and reliability of the central empirical claim cannot be evaluated.
minor comments (1)
- [Abstract] Clarify the exact procedure for identifying the 'critical phrase' (smallest continuous span) for each BLiMP phenomenon so that the proxy splits are reproducible.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, proposing revisions to strengthen the manuscript where the concerns identify gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract / Methods (proxy split)] Abstract / proxy-split definition: the assignment of examples to proxy-train versus proxy-validation rests solely on whether the critical phrase appears in the pre-training window. This definition does not include reported controls for lexical overlap, syntactic neighbors, or semantic similarity outside the phrase span; if such confounders drive incremental corpus statistics, the observed delay on proxy-validation cannot be attributed to a grokking-like mechanism triggered by exposure to the grammatical contrast.
Authors: The proxy split is intentionally defined around the critical phrase—the minimal span encoding the grammatical contrast—to isolate the effect of exposure to that contrast during pre-training. BLiMP minimal pairs already constrain lexical and semantic differences outside the contrast by design. Nevertheless, we acknowledge that explicit additional controls (e.g., lexical-overlap matching and embedding-based similarity filtering on non-critical tokens) would further rule out incremental corpus statistics as an alternative explanation. We will add these controls and corresponding analyses in the revised manuscript. revision: yes
-
Referee: [Abstract / Results] Results (delayed generalization claims): the abstract states that delayed generalization is observed across five phenomena, yet supplies no quantitative metrics (e.g., accuracy curves, delay measured in tokens or steps, error bars, or statistical tests comparing pre- and post-generalization performance). Without these, the magnitude and reliability of the central empirical claim cannot be evaluated.
Authors: The main text and supplementary figures contain the requested quantitative elements: accuracy curves with error bars, delay measured in tokens, and statistical comparisons of pre- versus post-generalization performance. To improve the abstract's informativeness while remaining within length limits, we will incorporate concise quantitative highlights (e.g., average delay across the five phenomena and post-generalization accuracy lift) in the revised abstract. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The proxy-train and proxy-validation assignment is defined solely from independent data exposure (critical phrase presence in the pre-training window), with no equations or self-citations reducing the reported delayed generalization, concept vector predictiveness, or subspace dimensionality to a fitted parameter or self-defined quantity from the same performance measure. All observations are empirical measurements on external BLiMP benchmarks across checkpoints; the methodology is self-contained against those benchmarks with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption BLiMP minimal pairs provide controlled grammatical contrasts that can be isolated via a single critical phrase span.
invented entities (2)
-
critical phrase
no independent evidence
-
proxy-train split
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
BL i MP : The Benchmark of Linguistic Minimal Pairs for E nglish
Warstadt, Alex and Parrish, Alicia and Liu, Haokun and Mohananey, Anhad and Peng, Wei and Wang, Sheng-Fu and Bowman, Samuel R. BL i MP : The Benchmark of Linguistic Minimal Pairs for E nglish. Transactions of the Association for Computational Linguistics. 2020. doi:10.1162/tacl_a_00321
-
[9]
Grokking in
Ziyue Li and Chenrui Fan and Tianyi Zhou , booktitle=. Grokking in. 2026 , url=
2026
-
[10]
NeurIPS ML Safety Workshop , year=
Unifying Grokking and Double Descent , author=. NeurIPS ML Safety Workshop , year=
-
[11]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Deep double descent: Where bigger models and more data hurt , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2021 , publisher=
2021
-
[12]
2024 , url=
Grokking Tickets: Lottery Tickets Accelerate Grokking , author=. 2024 , url=
2024
-
[13]
International Conference on Learning Representations , year=
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , author=. International Conference on Learning Representations , year=
-
[14]
arXiv preprint arXiv:2301.02679 , year=
Grokking modular arithmetic , author=. arXiv preprint arXiv:2301.02679 , year=
-
[15]
The Eleventh International Conference on Learning Representations , year=
Progress measures for grokking via mechanistic interpretability , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Grokking of Hierarchical Structure in Vanilla Transformers
Murty, Shikhar and Sharma, Pratyusha and Andreas, Jacob and Manning, Christopher. Grokking of Hierarchical Structure in Vanilla Transformers. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.38
-
[17]
GaLore: Memory-Efficient
Jiawei Zhao and Zhenyu Zhang and Beidi Chen and Zhangyang Wang and Anima Anandkumar and Yuandong Tian , booktitle=. GaLore: Memory-Efficient. 2024 , url=
2024
-
[18]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[19]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Tracing the Representation Geometry of Language Models from Pretraining to Post-training , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[20]
The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models
Razzhigaev, Anton and Mikhalchuk, Matvey and Goncharova, Elizaveta and Oseledets, Ivan and Dimitrov, Denis and Kuznetsov, Andrey. The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models. Findings of the Association for Computational Linguistics: EACL 2024. 2024. doi:10.18653/v1/2024.findings-eacl.58
-
[21]
International Conference on Learning Representations , year=
Pointer Sentinel Mixture Models , author=. International Conference on Learning Representations , year=
-
[22]
What Does BERT Look at? An Analysis of BERT ' s Attention
Clark, Kevin and Khandelwal, Urvashi and Levy, Omer and Manning, Christopher D. What Does BERT Look at? An Analysis of BERT ' s Attention. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4828
-
[23]
Forty-first International Conference on Machine Learning , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[24]
Proceedings of the 15th European Signal Processing Conference , pages=
The effective rank: A measure of effective dimensionality , author=. Proceedings of the 15th European Signal Processing Conference , pages=
-
[25]
Fifty shapes of BL i MP : syntactic learning curves in language models are not uniform, but sometimes unruly
Bunzeck, Bastian and Zarrie , Sina. Fifty shapes of BL i MP : syntactic learning curves in language models are not uniform, but sometimes unruly. Proceedings of the 2024 CLASP Conference on Multimodality and Interaction in Language Learning. 2024
2024
-
[26]
Language Models ``Grok'' to Copy
Lv, Ang and Xie, Ruobing and Sun, Xingwu and Kang, Zhanhui and Yan, Rui. Language Models ``Grok'' to Copy. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2025. doi:10.18653/v1/2025.naacl-short.61
-
[27]
Filtered Corpus Training ( F i CT ) Shows that Language Models Can Generalize from Indirect Evidence
Patil, Abhinav and Jumelet, Jaap and Chiu, Yu Ying and Lapastora, Andy and Shen, Peter and Wang, Lexie and Willrich, Clevis and Steinert-Threlkeld, Shane. Filtered Corpus Training ( F i CT ) Shows that Language Models Can Generalize from Indirect Evidence. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00720
-
[28]
doi: 10.18653/v1/2021.acl-long.144
Finlayson, Matthew and Mueller, Aaron and Gehrmann, Sebastian and Shieber, Stuart and Linzen, Tal and Belinkov, Yonatan. Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Process...
-
[29]
Linguistic Minimal Pairs Elicit Linguistic Similarity in Large Language Models
Zhou, Xinyu and Chen, Delong and Cahyawijaya, Samuel and Duan, Xufeng and Cai, Zhenguang. Linguistic Minimal Pairs Elicit Linguistic Similarity in Large Language Models. Proceedings of the 31st International Conference on Computational Linguistics. 2025
2025
-
[30]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[31]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[32]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets , author=. arXiv preprint arXiv:2201.02177 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.