Robust Shielding for Safe Reinforcement Learning
Pith reviewed 2026-06-28 22:19 UTC · model grok-4.3
The pith
Shielding framework for robust MDPs is sound and optimal, admitting exactly the policies that meet LTL safety thresholds under worst-case transitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a novel shielding framework for robust MDPs (RMDPs), i.e., MDPs with sets of transition probabilities. We define safety as the satisfaction of a linear temporal logic (LTL) formula with a certain threshold probability under the worst-case transition probabilities of the RMDP. We prove that our shielding framework is both sound and optimal for the RMDP: every policy admissible by the shield is safe, and conversely, every safe RMDP policy is admissible by the shield. We combine our approach with existing sampling methods for learning transition probabilities of MDPs with probably approximately correct (PAC) guarantees. This combination enables the construction of shields for MDPs
What carries the argument
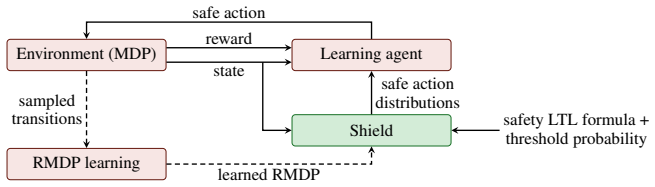
The shielding framework on RMDPs that enforces LTL safety specifications with a probability threshold under worst-case transition sets, shown to be sound and optimal.
If this is right
- Every policy the shield admits satisfies the LTL safety condition with the required probability under worst-case transitions.
- Every safe policy in the RMDP is admitted by the shield.
- When transition sets are obtained via PAC sampling, the shield supplies safety guarantees for the original MDP with high probability.
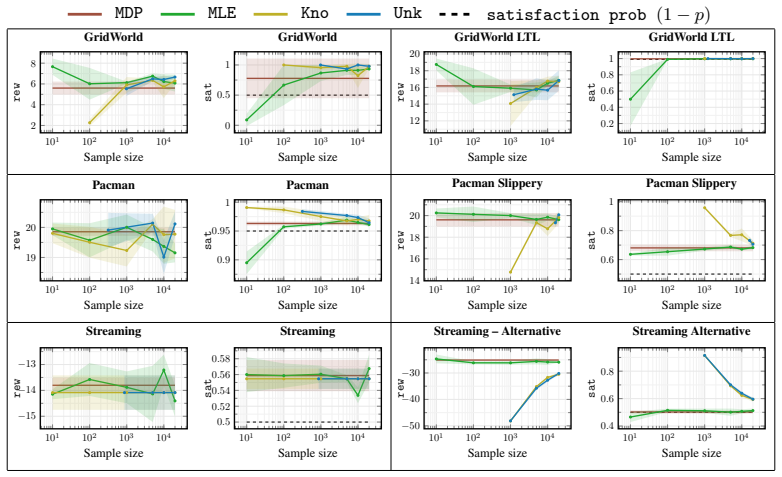
- As the number of samples grows, the shield becomes less restrictive and expected returns approach those of the optimal safe policy.
Where Pith is reading between the lines
- The same soundness and optimality arguments could be reused for other temporal logics or uncertainty representations beyond probability intervals.
- An online version that updates the RMDP sets and shield during learning would reduce initial restrictiveness compared with the offline construction shown.
- The framework suggests that robust shielding could be combined with model-free RL algorithms to produce safe policies directly from interaction data.
Load-bearing premise
The safety-relevant transition dynamics of the underlying MDP can be faithfully represented as sets of probabilities in an RMDP, and sampling methods exist that deliver PAC guarantees on those sets without requiring knowledge of the true transitions.
What would settle it
A policy that the shield admits yet fails the LTL formula with probability below the threshold for some transition probability inside the RMDP set, or a policy that satisfies the LTL condition for every probability in the set yet is rejected by the shield.
Figures
read the original abstract
Shielding is an effective approach to formally guarantee the safety of reinforcement learning agents in Markov decision processes (MDPs). However, existing shielding techniques typically assume knowledge of the safety-relevant transition dynamics - a requirement that is seldom met in practice. To address this limitation, we introduce a novel shielding framework for robust MDPs (RMDPs), i.e., MDPs with sets of transition probabilities. We define safety as the satisfaction of a linear temporal logic (LTL) formula with a certain threshold probability under the worst-case transition probabilities of the RMDP. We prove that our shielding framework is both sound and optimal for the RMDP: every policy admissible by the shield is safe, and conversely, every safe RMDP policy is admissible by the shield. We combine our approach with existing sampling methods for learning transition probabilities of MDPs with probably approximately correct (PAC) guarantees. This combination enables the construction of shields for MDPs that, with high confidence, guarantee safety while remaining minimally restrictive. Our experiments show that our shields for learned RMDPs guarantee safety in unknown MDPs while recovering strong expected return as the number of samples increases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a shielding framework for robust MDPs (RMDPs) with interval transition probabilities. Safety is defined via satisfaction of an LTL formula above a given probability threshold under worst-case transitions inside the sets. The authors prove that a shield constructed from a given RMDP is both sound (every admissible policy is safe) and optimal (every safe policy is admissible). They combine the framework with PAC sampling methods to learn the sets from an unknown MDP and report experiments showing that the resulting shields enforce safety while recovering expected return as sample count grows.
Significance. If the claims hold, the work is significant for extending formal shielding to the common practical case of unknown dynamics, using PAC guarantees to obtain high-confidence safety shields that remain minimally restrictive. The explicit soundness and optimality proofs for the exact-RMDP case, together with the sampling integration, constitute a clear technical contribution over prior shielding methods that assume known transitions.
major comments (2)
- [§4] §4 (combination with PAC sampling): the soundness and optimality theorems are stated and proved only for an exact given RMDP. No subsequent theorem or lemma supplies an explicit high-confidence bound showing that the worst-case LTL probability under the learned sets remains above the required threshold; path-dependent quantification in LTL can compound per-transition PAC error in ways not controlled by standard single-step PAC results.
- [Definition 3] Definition 3 (RMDP safety): the threshold probability is taken with respect to the worst-case transitions inside the sets, yet the text does not state how this threshold is adjusted (or not) to absorb the PAC approximation error when the sets themselves are learned; this choice is load-bearing for the “with high confidence” claim in the abstract.
minor comments (2)
- [§3] Notation for the robust value function and the shield construction could be introduced earlier and used consistently in the proofs.
- [Experiments] Experimental plots would benefit from reporting the empirical violation rate of the LTL specification across repeated trials rather than only average return.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need for an explicit connection between the PAC guarantees and the LTL safety threshold under learned interval sets. We address the major comments point by point below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [§4] §4 (combination with PAC sampling): the soundness and optimality theorems are stated and proved only for an exact given RMDP. No subsequent theorem or lemma supplies an explicit high-confidence bound showing that the worst-case LTL probability under the learned sets remains above the required threshold; path-dependent quantification in LTL can compound per-transition PAC error in ways not controlled by standard single-step PAC results.
Authors: We agree that the soundness and optimality results apply to a fixed RMDP and that the manuscript lacks an explicit theorem deriving a high-confidence bound on the LTL probability for the PAC-learned intervals. The combination section relies on the fact that the true MDP lies inside the learned RMDP with high probability, but does not address error compounding for path-dependent LTL properties. We will add a new lemma in §4 that adjusts the safety threshold using the PAC confidence parameter and a suitable concentration inequality (e.g., via union bound over relevant finite paths) to control the compounded error. revision: yes
-
Referee: [Definition 3] Definition 3 (RMDP safety): the threshold probability is taken with respect to the worst-case transitions inside the sets, yet the text does not state how this threshold is adjusted (or not) to absorb the PAC approximation error when the sets themselves are learned; this choice is load-bearing for the “with high confidence” claim in the abstract.
Authors: The referee is correct that Definition 3 defines safety for a given RMDP without specifying any adjustment to the probability threshold when the intervals are obtained from PAC sampling. This omission leaves the high-confidence claim in the abstract without full formal support. We will revise the text immediately after Definition 3 and in §4 to state explicitly how the threshold is raised (or the PAC parameter chosen) to absorb the approximation error, thereby making the overall guarantee rigorous. revision: yes
Circularity Check
No circularity; proofs derive directly from RMDP safety definitions
full rationale
The paper defines safety for RMDPs as LTL satisfaction above a threshold under worst-case transition probabilities within the sets, then proves soundness and optimality (every admissible policy is safe and vice versa) from those definitions. The PAC sampling combination is presented as a practical extension without reducing the central theorems to fitted inputs, self-citations, or ansatzes. The derivation chain is self-contained against the stated assumptions and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Transition dynamics of an MDP can be represented as sets of probability distributions forming an RMDP
- domain assumption LTL formulas can be evaluated with threshold probabilities over RMDP paths
Reference graph
Works this paper leans on
-
[1]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. A Bradford Book, Cambridge, MA, USA, 2018
2018
-
[2]
Bagnell, and Jan Peters
Jens Kober, J. Bagnell, and Jan Peters. Reinforcement learning in robotics: A survey.The International Journal of Robotics Research, 32:1238–1274, 09 2013
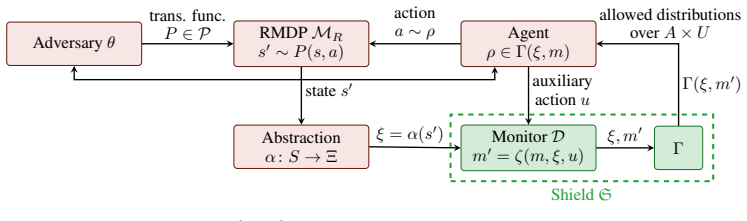
2013
-
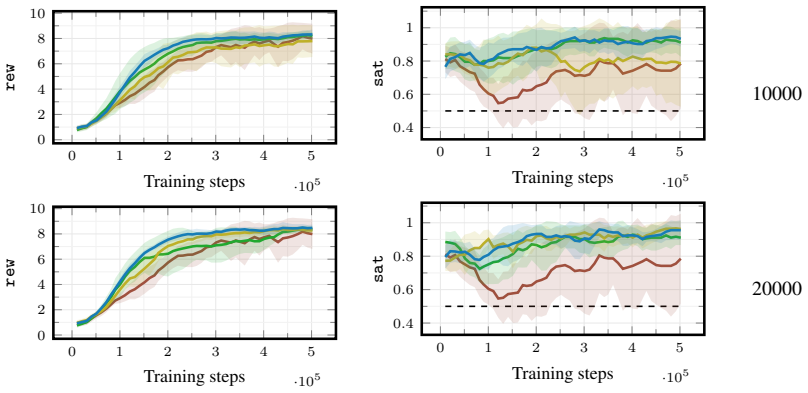
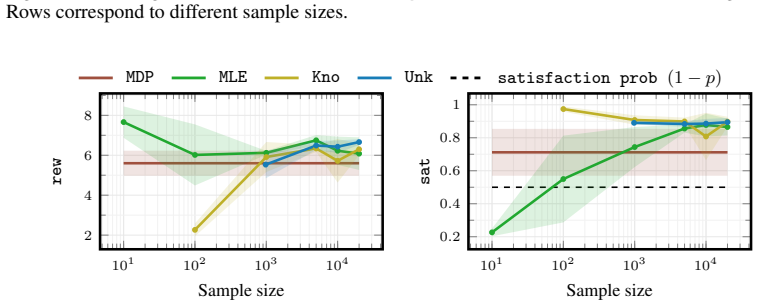
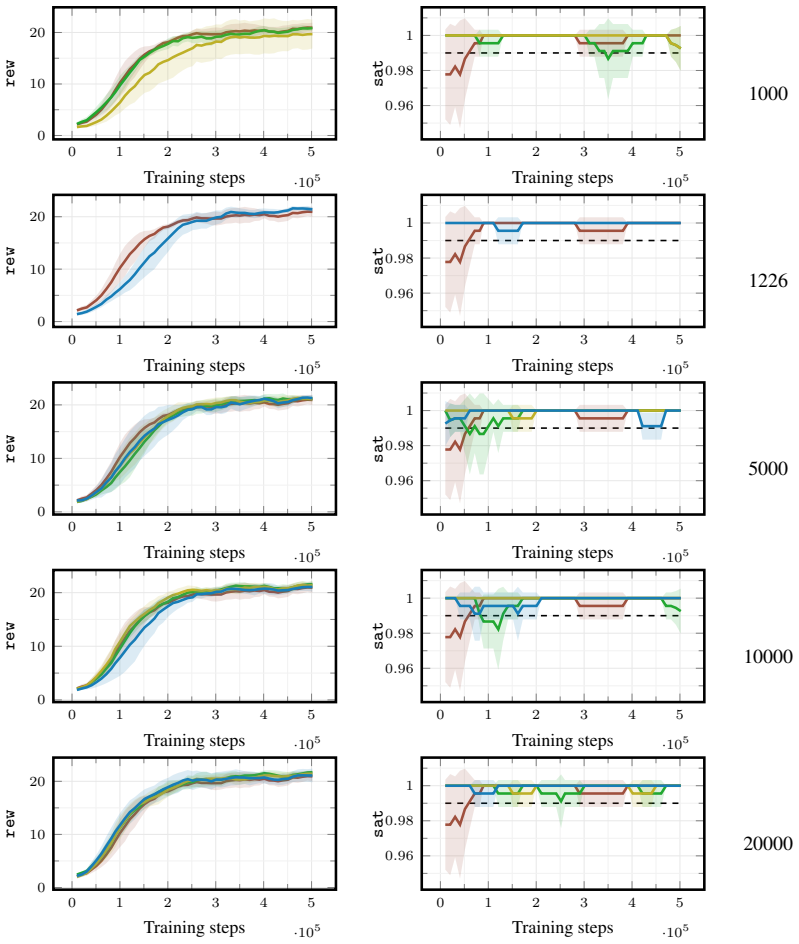
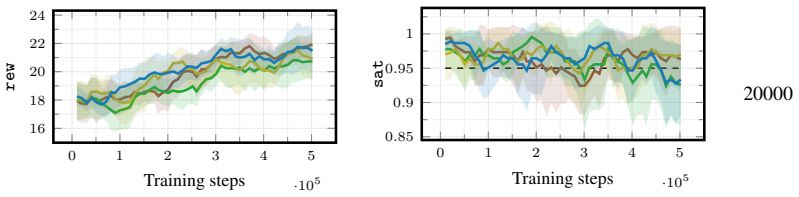
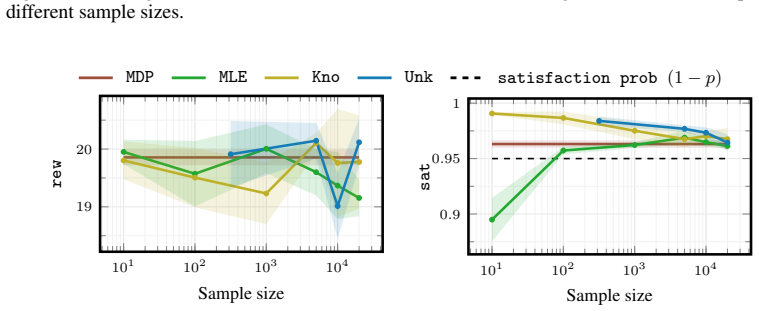
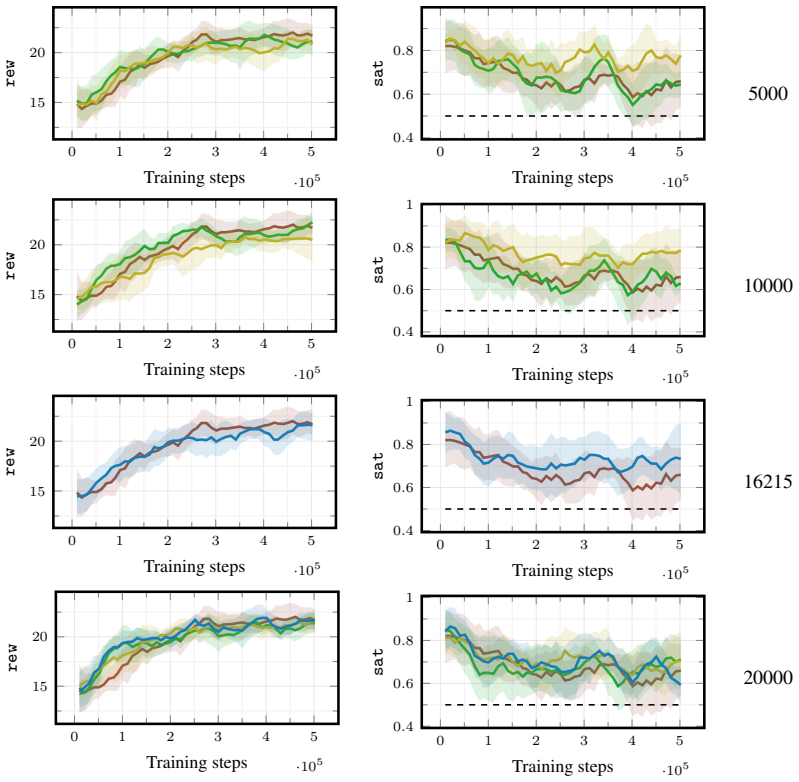
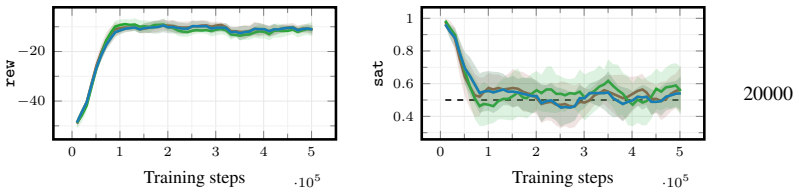
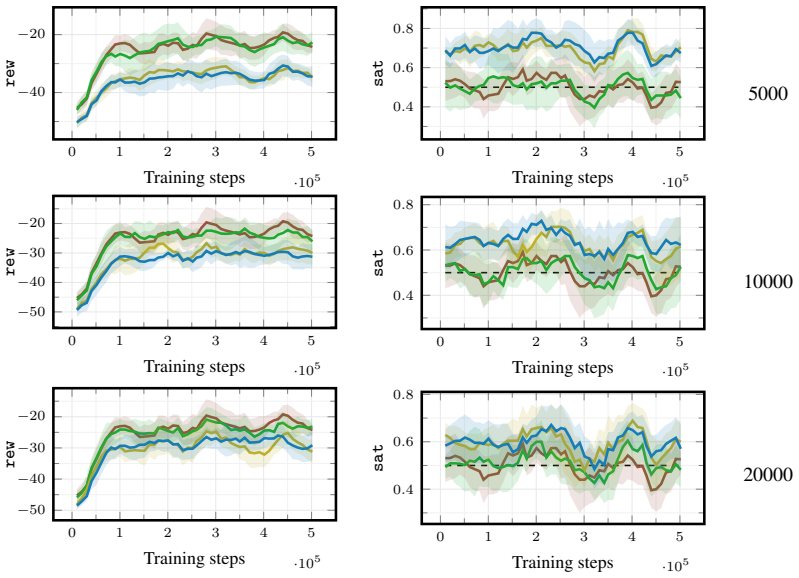
[3]
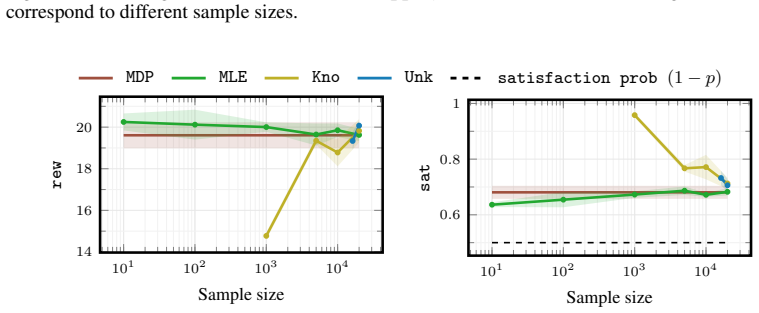
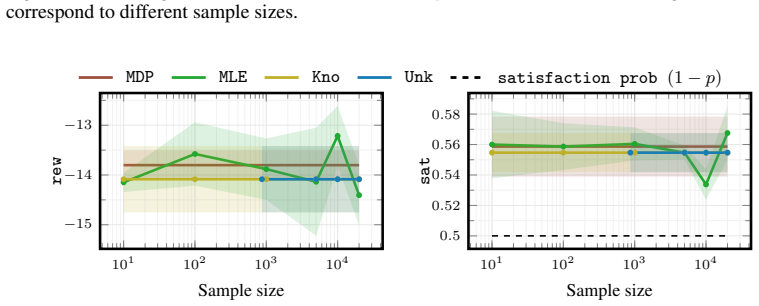
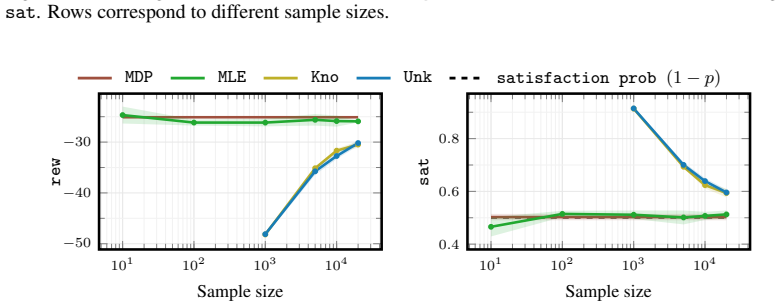
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing Atari with deep reinforcement learning.CoRR, abs/1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A
B. Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A. Al Sallab, Senthil Ku- mar Yogamani, and Patrick Pérez. Deep reinforcement learning for autonomous driving: A survey.IEEE Trans. Intell. Transp. Syst., 23(6):4909–4926, 2022
2022
-
[5]
A comprehensive survey on safe reinforcement learning
Javier García and Fernando Fernández. A comprehensive survey on safe reinforcement learning. J. Mach. Learn. Res., 16:1437–1480, 2015
2015
-
[6]
Safe Reinforcement Learning via Shielding
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. volume abs/1708.08611, 2017. 10
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Edwin Hamel-De le Court, Francesco Belardinelli, and Alexander W. Goodall. Probabilistic shielding for safe reinforcement learning. InAAAI, pages 16091–16099. AAAI Press, 2025
2025
-
[8]
Safe reinforcement learning using probabilistic shields (invited paper)
Nils Jansen, Bettina Könighofer, Sebastian Junges, Alex Serban, and Roderick Bloem. Safe reinforcement learning using probabilistic shields (invited paper). InCONCUR, LIPIcs, pages 3:1–3:16. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 2020
2020
-
[9]
Safe reinforcement learning via shielding under partial observability
Steven Carr, Nils Jansen, Sebastian Junges, and Ufuk Topcu. Safe reinforcement learning via shielding under partial observability. InAAAI, pages 14748–14756. AAAI Press, 2023
2023
-
[10]
Tsitsiklis
Shie Mannor, Duncan Simester, Peng Sun, and John N. Tsitsiklis. Bias and variance approxima- tion in value function estimates.Manag. Sci., 53(2):308–322, 2007
2007
-
[11]
Robust control of Markov decision processes with uncertain transition matrices.Oper
Arnab Nilim and Laurent El Ghaoui. Robust control of Markov decision processes with uncertain transition matrices.Oper. Res., 53(5):780–798, 2005
2005
-
[12]
Bovy, David Parker, and Nils Jansen
Marnix Suilen, Thom Badings, Eline M. Bovy, David Parker, and Nils Jansen. Robust markov decision processes: A place where AI and formal methods meet. InPrinciples of Verification (3), Lecture Notes in Computer Science, pages 126–154. Springer, 2024
2024
-
[13]
Robust Markov decision processes
Wolfram Wiesemann, Daniel Kuhn, and Berç Rustem. Robust Markov decision processes. Math. Oper. Res., 38(1):153–183, 2013
2013
-
[14]
Orna Kupferman and Moshe Y . Vardi. Model checking of safety properties.Formal Methods Syst. Des., 19(3):291–314, 2001
2001
-
[15]
Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P
Lukas Brunke, Melissa Greeff, Adam W. Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P. Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annu. Rev. Control. Robotics Auton. Syst., 5:411–444, 2022
2022
-
[16]
A review of safe reinforcement learning: Methods, theories, and applications.IEEE Trans
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, and Alois Knoll. A review of safe reinforcement learning: Methods, theories, and applications.IEEE Trans. Pattern Anal. Mach. Intell., 46(12):11216–11235, 2024
2024
-
[17]
Shielded rein- forcement learning: A review of reactive methods for safe learning
Haritz Odriozola-Olalde, Maider Zamalloa, and Nestor Arana-Arexolaleiba. Shielded rein- forcement learning: A review of reactive methods for safe learning. InSII, pages 1–8. IEEE, 2023
2023
-
[18]
Safe reinforcement learning via probabilistic logic shields
Wen-Chi Yang, Giuseppe Marra, Gavin Rens, and Luc De Raedt. Safe reinforcement learning via probabilistic logic shields. InIJCAI, pages 5739–5749. ijcai.org, 2023
2023
-
[19]
Safe multi-agent reinforcement learning via shielding
Ingy Elsayed-Aly, Suda Bharadwaj, Christopher Amato, Rüdiger Ehlers, Ufuk Topcu, and Lu Feng. Safe multi-agent reinforcement learning via shielding. InAAMAS, pages 483–491. ACM, 2021
2021
-
[20]
Online shielding for reinforcement learning.Innov
Bettina Könighofer, Julian Rudolf, Alexander Palmisano, Martin Tappler, and Roderick Bloem. Online shielding for reinforcement learning.Innov. Syst. Softw. Eng., 19(4):379–394, 2023
2023
-
[21]
Shields for safe reinforcement learning.Commun
Bettina Könighofer, Roderick Bloem, Nils Jansen, Sebastian Junges, and Stefan Pranger. Shields for safe reinforcement learning.Commun. ACM, 68(11):80–90, 2025
2025
-
[22]
Goodall and Francesco Belardinelli
Alexander W. Goodall and Francesco Belardinelli. Leveraging approximate model-based shielding for probabilistic safety guarantees in continuous environments. InAAMAS, pages 2291–2293. International Foundation for Autonomous Agents and Multiagent Systems / ACM, 2024
2024
-
[23]
Safe reinforcement learning in black-box environments via adaptive shielding
Daniel Bethell, Simos Gerasimou, Radu Calinescu, and Calum Imrie. Safe reinforcement learning in black-box environments via adaptive shielding. InECAI, Frontiers in Artificial Intelligence and Applications, pages 2450–2457. IOS Press, 2025
2025
-
[24]
Learning-based shielding for safe autonomy under unknown dynamics
Robert Reed and Morteza Lahijanian. Learning-based shielding for safe autonomy under unknown dynamics. InACC, pages 4940–4946. IEEE, 2025
2025
-
[25]
Optimization-based robust permissive synthesis for interval MDPs, 2026
Khang V o Huynh, David Parker, and Lu Feng. Optimization-based robust permissive synthesis for interval MDPs, 2026. 11
2026
-
[26]
Risk-constrained reinforcement learning with percentile risk criteria.J
Yinlam Chow, Mohammad Ghavamzadeh, Lucas Janson, and Marco Pavone. Risk-constrained reinforcement learning with percentile risk criteria.J. Mach. Learn. Res., 18:167:1–167:51, 2017
2017
-
[27]
Responsive safety in reinforcement learning by PID lagrangian methods
Adam Stooke, Joshua Achiam, and Pieter Abbeel. Responsive safety in reinforcement learning by PID lagrangian methods. InICML, Proceedings of Machine Learning Research, pages 9133–9143. PMLR, 2020
2020
-
[28]
Efficient policy optimization in robust constrained MDPs with iteration complexity guarantees
Sourav Ganguly, Arnob Ghosh, Kishan Panaganti, and Adam Wierman. Efficient policy optimization in robust constrained MDPs with iteration complexity guarantees. InNeurIPS, 2025
2025
-
[29]
Reazul Hasan Russel, Mouhacine Benosman, and Jeroen van Baar. Robust constrained-MDPs: Soft-constrained robust policy optimization under model uncertainty.CoRR, abs/2010.04870, 2020
-
[30]
Duéñez-Guzmán, and Mohammad Ghavamzadeh
Yinlam Chow, Ofir Nachum, Edgar A. Duéñez-Guzmán, and Mohammad Ghavamzadeh. A Lyapunov-based approach to safe reinforcement learning. InNeurIPS, pages 8103–8112, 2018
2018
-
[31]
Lyapunov-based Safe Policy Optimization for Continuous Control
Yinlam Chow, Ofir Nachum, Aleksandra Faust, Mohammad Ghavamzadeh, and Edgar A. Duéñez-Guzmán. Lyapunov-based safe policy optimization for continuous control.CoRR, abs/1901.10031, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[32]
Schoellig, and Andreas Krause
Felix Berkenkamp, Matteo Turchetta, Angela P. Schoellig, and Andreas Krause. Safe model- based reinforcement learning with stability guarantees. InNIPS, pages 908–918, 2017
2017
-
[33]
Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting.SIGART Bull., 2(4):160–163, 1991
1991
-
[34]
When to trust your model: Model-based policy optimization
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. InNeurIPS, pages 12498–12509, 2019
2019
-
[35]
Trust the model where it trusts itself - model-based actor-critic with uncertainty-aware rollout adaption
Bernd Frauenknecht, Artur Eisele, Devdutt Subhasish, Friedrich Solowjow, and Sebastian Trimpe. Trust the model where it trusts itself - model-based actor-critic with uncertainty-aware rollout adaption. InICML, Proceedings of Machine Learning Research, pages 13973–14005. PMLR / OpenReview.net, 2024
2024
-
[36]
MIT press, 2008
Christel Baier and Joost-Pieter Katoen.Principles of model checking. MIT press, 2008
2008
-
[37]
Bertsekas and Steven E
Dimitri P. Bertsekas and Steven E. Shreve.Stochastic Optimal Control: The Discrete-Time Case. Athena Scientific, 2007
2007
-
[38]
The temporal logic of programs
Amir Pnueli. The temporal logic of programs. InFOCS, pages 46–57. IEEE Computer Society, 1977
1977
-
[39]
Runtime verification - 17 years later
Klaus Havelund and Grigore Rosu. Runtime verification - 17 years later. InRV, Lecture Notes in Computer Science, pages 3–17. Springer, 2018
2018
-
[40]
Deshmukh, Alexandre Donzé, Georgios Fainekos, Oded Maler, Dejan Nickovic, and Sriram Sankaranarayanan
Ezio Bartocci, Jyotirmoy V . Deshmukh, Alexandre Donzé, Georgios Fainekos, Oded Maler, Dejan Nickovic, and Sriram Sankaranarayanan. Specification-based monitoring of cyber- physical systems: A survey on theory, tools and applications. InLectures on Runtime Verification, Lecture Notes in Computer Science, pages 135–175. Springer, 2018
2018
-
[41]
What are the odds? improving statistical model checking of Markov decision processes
Tobias Meggendorfer, Maximilian Weininger, and Patrick Wienhöft. What are the odds? improving statistical model checking of Markov decision processes. InQEST+FORMATS, Lecture Notes in Computer Science, pages 195–218. Springer, 2025
2025
-
[42]
Data-driven abstraction and synthesis for stochastic systems with unknown dynamics
Mahdi Nazeri, Thom Badings, Anne-Kathrin Schmuck, Sadegh Soudjani, and Alessandro Abate. Data-driven abstraction and synthesis for stochastic systems with unknown dynamics. InCDC, pages 6754–6759. IEEE, 2025
2025
-
[43]
Poonawala, Mariëlle Stoelinga, and Nils Jansen
Thom Badings, Licio Romao, Alessandro Abate, David Parker, Hasan A. Poonawala, Mariëlle Stoelinga, and Nils Jansen. Robust control for dynamical systems with non-Gaussian noise via formal abstractions.J. Artif. Intell. Res., 76:341–391, 2023. 12
2023
-
[44]
Simão, David Parker, and Nils Jansen
Marnix Suilen, Thiago D. Simão, David Parker, and Nils Jansen. Robust anytime learning of Markov decision processes. InNeurIPS, 2022
2022
-
[45]
Certifiably robust policies for uncertain parametric environments
Yannik Schnitzer, Alessandro Abate, and David Parker. Certifiably robust policies for uncertain parametric environments. InTACAS (3), Lecture Notes in Computer Science, pages 63–83. Springer, 2025
2025
-
[46]
The use of confidence or fiducial limits illustrated in the case of the binomial.Biometrika, 26(4):404–413, 1934
Charles J Clopper and Egon S Pearson. The use of confidence or fiducial limits illustrated in the case of the binomial.Biometrika, 26(4):404–413, 1934
1934
-
[47]
Henzinger, Jan Kretínský, and Tatjana Petrov
Przemyslaw Daca, Thomas A. Henzinger, Jan Kretínský, and Tatjana Petrov. Faster statistical model checking for unbounded temporal properties.ACM Trans. Comput. Log., 18(2):12:1– 12:25, 2017
2017
-
[48]
Garud N. Iyengar. Robust dynamic programming.Math. Oper. Res., 30(2):257–280, 2005
2005
-
[49]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
Goodall, Omar Adalat, Edwin Hamel De-le Court, and Francesco Belardinelli
Alexander W. Goodall, Omar Adalat, Edwin Hamel De-le Court, and Francesco Belardinelli. MASA-Safe-RL: Multi and single agent safe reinforcement learning. https://github.com/ sacktock/MASA-Safe-RL/, 2025. GitHub repository
2025
-
[51]
Simão, Marnix Suilen, and Nils Jansen
Thom Badings, Thiago D. Simão, Marnix Suilen, and Nils Jansen. Decision-making under uncertainty: beyond probabilities.Int. J. Softw. Tools Technol. Transf., 25(3):375–391, 2023
2023
-
[52]
Bertsimas and D
D. Bertsimas and D. den Hertog.Robust and Adaptive Optimization. Dynamic Ideas LLC, 2022
2022
-
[53]
DOPE: doubly optimistic and pessimistic exploration for safe reinforcement learning
Archana Bura, Aria HasanzadeZonuzy, Dileep Kalathil, Srinivas Shakkottai, and Jean-François Chamberland. DOPE: doubly optimistic and pessimistic exploration for safe reinforcement learning. InNeurIPS, 2022. 13 A Extended Preliminaries Remark A.1.Throughout the appendices, we provide formalizations of all definitions and results from the paper, including t...
2022
-
[54]
ifα(s) =α(s ′), thenL(s) =L(s ′)andA(s) =A(s ′)
-
[55]
for every actiona∈A(s), we have µ◦α −1 |µ∈ P(s, a) = µ◦α −1 |µ∈ P(s ′, a)
-
[56]
the induced correspondence Pα defined by Pα(ξ, a) = µ◦α −1 :µ∈ P(s, a) for any s∈α −1(ξ)has measurable graph. Intuitively, condition 1 requires that all states s, s′ ∈S mapping to the same abstract state have the same label and enabled actions, and condition 2 that these states induce the same sets of transition probabilities under the abstraction map. Si...
-
[57]
∞X t=0 γtR(st, at) # −E s0a0···∼ν
for all states (s, q, y) of MR ⊗ D, the set Γ(s, q, y) contains exactly those distributions ρ∈∆(A× V β)such that ρ(A(s)× V β) = 1, and such that E(a,v)∼ρ h sup µ∈P(s,a) Es′∼µ v s′, δ(q, L(s′)) i ≤y. Lemma B.2.The pairS(M R,A, β) = (D,Γ)is a shield over(S, A). Proof.SinceS,Q, andAare finite, we equip them with the discrete topology. The space Vβ = Y (s,q)∈...
-
[58]
ThenSis C- 2Zϵ 1−γ , γ -optimal over(M R, α)forΦ
Suppose that sup(s,a)∈S×A |R(s, a)| ≤Z , that γ <1 , and that S is C-ϵ-W1,γ-complete over(M R, α)forΦ. ThenSis C- 2Zϵ 1−γ , γ -optimal over(M R, α)forΦ
-
[59]
ThenSis C-(2Bϵ,1)-optimal over(M R, α)forΦ
Suppose that the absolute value of the total undiscounted return is uniformly bounded by B, and thatSisC-ϵ-TV-complete over(M R, α)forΦ. ThenSis C-(2Bϵ,1)-optimal over(M R, α)forΦ. Proof. We prove the first item; the second is analogous. Let π∈ C be such that MR, π|= Φ . By C-ϵ-W1,γ-completeness, there exists a compliant policy πsuch that, W1,γ probMR[θ],...
-
[60]
If the absolute value of the total undiscounted return is uniformly bounded by B, then S(MR/α,A, β)is HR-(2Bϵ,1)-optimal over(M R, α)forΦ
-
[61]
In particular, the shield S(MR/α,A, β ∞) is HR-(0, γ)-optimal for every γ∈(0,1] for which the corresponding return is well-defined
Ifγ∈(0,1)andsup (s,a)∈S×A |R(s, a)| ≤Z, thenS(M R/α,A, β)is HR- 2Zϵ 1−γ , γ -optimal over(M R, α)forΦ. In particular, the shield S(MR/α,A, β ∞) is HR-(0, γ)-optimal for every γ∈(0,1] for which the corresponding return is well-defined. C Probabilistic Shielding for Unknown MDPs In this appendix, we present all extended definitions, results, and proofs for ...
-
[62]
for every HR policy π, the total rewardP∞ t=0 R(st, at) is almost surely convergent and has finite expectation
-
[63]
∞X t=0 c((st, qt), at) # is the probability to reachGfollowingπ, so the constraint M, π|=P ≥1−p(φ) is equivalent to Eπ
an optimal feasible HR policy exists. Then there exists an optimal feasible policy π⋆ ∈ C A(M). Moreover,π⋆ can be chosen as an initial mixture of at most two deterministicA-memory policies. Proof. Consider the product MDP M ⊗L A with state space S×Q , and let G=S×F be the set of bad product states. We make G absorbing and set the reward to zero after G i...
-
[64]
the choice of two actions, of a trade-off λ∈[0; 1] between those two action, inducing a distributionµover actions, and
-
[65]
the choice of an extremal point ofV λ(ξ, q, y). In practice, we optimize with PPO [49] over M S , we leave the choice of the trade-off λ to the actor, and implement the following heuristic for the choice of the extremal point ofV λ(ξ, q, y). Auxiliary action heuristic.We describe the heuristic used to choose the auxiliary actions after the actor has selec...
-
[66]
learning curves over training steps, shown for each sample size (the specific number that changes across the various environments represents the minimum number of samples needed forUnk)
-
[67]
averaged performance as a function of sample size. Colour bomb gridworld MDP MLE Kno Unk satisfaction prob(1−p) Samples 0 1 2 3 4 5 ·105 0 5 10 Training steps rew 0 1 2 3 4 5 ·105 0 0.5 1 Training steps sat 10 0 1 2 3 4 5 ·105 0 5 10 Training steps rew 0 1 2 3 4 5 ·105 0.5 1 Training steps sat 100 0 1 2 3 4 5 ·105 0 2 4 6 8 10 Training steps rew 0 1 2 3 4...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.