FLaG: Fine-Grained Latent Grouping for Hallucination Detection
Pith reviewed 2026-06-28 23:28 UTC · model grok-4.3
The pith
FLaG approximates the Bayes-optimal hallucination detector by routing instances to latent evidence groups and combining their signals via log-marginal aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
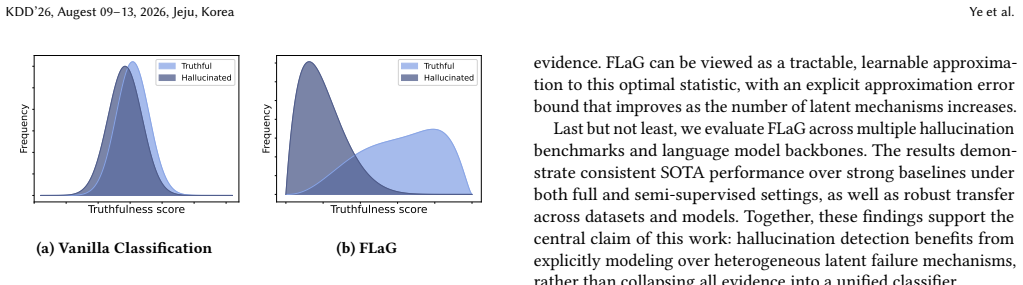
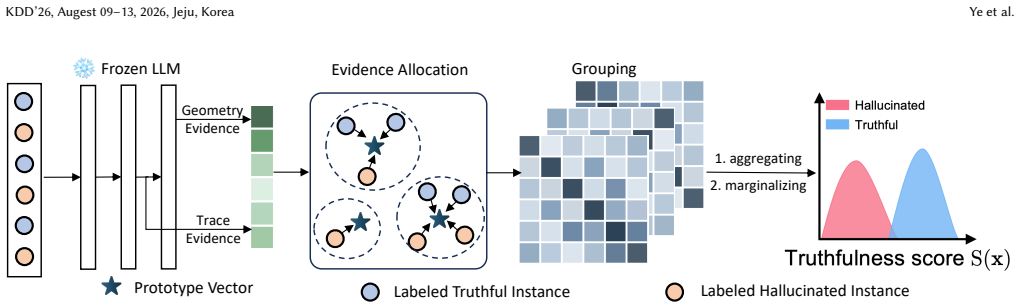
FLaG models correctness through a set of latent evidence groups, softly associates each instance with multiple groups via an energy-based routing mechanism, and combines group-conditional reliability signals through principled log-marginal aggregation. It connects this construction to the Bayes-optimal test statistic, which necessarily admits a log-marginal form, and shows that FLaG is a tractable approximation with a controllable error bound while achieving state-of-the-art performance across benchmarks and remaining invariant to decision thresholds and evaluation metrics.
What carries the argument
Energy-based routing that softly assigns instances to latent evidence groups, followed by log-marginal aggregation of the group-conditional signals.
If this is right
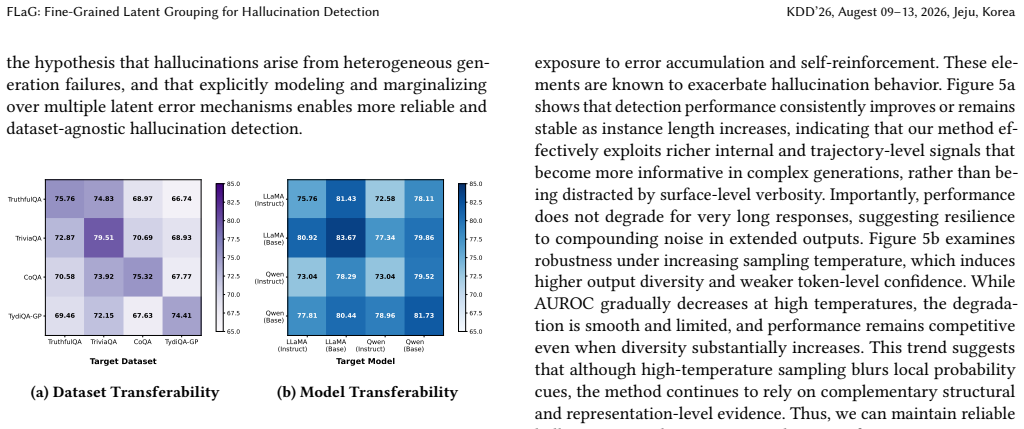
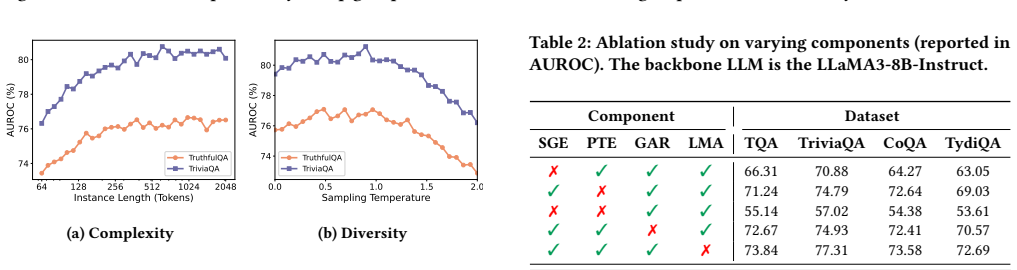
- Detection remains effective under limited supervision and transfers across datasets and LLM backbones.
- Performance stays superior to prior methods while requiring no changes to the underlying language model.
- The detector produces consistent results regardless of the chosen decision threshold or evaluation metric.
- The framework incurs only minimal computational overhead as a frozen-model head.
Where Pith is reading between the lines
- The same latent-group routing could be tested on uncertainty estimation tasks outside text generation, such as image captioning or code synthesis.
- If the log-marginal form proves robust, it might replace ad-hoc ensemble averaging in other reliability settings.
- Explicit modeling of multiple failure modes might reduce the need for post-hoc calibration in deployed language-model systems.
Load-bearing premise
Hallucination patterns arise from heterogeneous failure mechanisms that can be usefully captured by a finite set of latent evidence groups whose soft assignments and group-conditional signals can be aggregated via log-marginal form without losing critical information.
What would settle it
An experiment in which replacing the multi-group routing and log-marginal aggregation with a single global aggregation produces no performance loss on the same benchmarks would indicate that the heterogeneous-mechanism premise does not hold.
Figures

read the original abstract
Hallucinations in large language models (LLMs) arise from heterogeneous failure mechanisms, making reliable detection difficult for any single global uncertainty score. In this work, we formulate hallucination detection as a mechanism-aware evidence aggregation problem, where diverse representation- and token-level signals must be interpreted under multiple latent explanations. We propose FLaG, a lightweight hallucination detection framework that models correctness through a set of latent evidence groups. Each instance is softly associated with multiple groups via an energy-based routing mechanism, and group-conditional reliability signals are combined through a principled log-marginal aggregation. This design enables FLaG to capture heterogeneous hallucination patterns while remaining invariant to decision thresholds and evaluation metrics. The framework operates as a frozen-model head, requires no modification to the underlying language model, and incurs minimal computational overhead. We further provide a theoretical perspective that connects FLaG to optimal evidence aggregation under heterogeneous error mechanisms, showing that the Bayes-optimal test statistic necessarily admits a log-marginal form and that FLaG constitutes a tractable approximation with a controllable error bound. Extensive experiments across multiple benchmarks and LLM backbones demonstrate that FLaG consistently achieves SOTA performance, while exhibiting robust transfer across datasets and models, and remaining effective under limited supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations arise from heterogeneous failure mechanisms and formulates detection as mechanism-aware evidence aggregation. It proposes FLaG, which models correctness via a finite set of latent evidence groups, uses energy-based soft routing for instance-to-group associations, and aggregates group-conditional signals via log-marginal form. The manuscript states that this yields a tractable approximation to the Bayes-optimal test statistic under heterogeneous errors, with a controllable error bound, while remaining invariant to thresholds and metrics; FLaG is implemented as a frozen-model head and is reported to achieve SOTA results across benchmarks with robust transfer.
Significance. If the log-marginal aggregation indeed approximates the Bayes-optimal statistic with a controllable error bound and the empirical gains prove reproducible across models and datasets, the work would supply a lightweight, mechanism-aware alternative to single-score uncertainty methods for hallucination detection.
major comments (2)
- [Abstract / theoretical perspective] Abstract: the central claim that FLaG is a tractable approximation to the Bayes-optimal test statistic with a controllable error bound is asserted without any displayed equations, derivation steps, or error-bound analysis, so the approximation property and its controllability cannot be evaluated from the manuscript as presented.
- [Abstract / experiments] Abstract: the SOTA performance claim and invariance to thresholds/metrics are stated but no quantitative results, ablation tables, or baseline comparisons are supplied, preventing assessment of whether the reported gains are load-bearing or reducible to standard mixture-model fitting.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review. Below we respond point-by-point to the two major comments. The full theoretical derivation and all empirical results are contained in the manuscript body; the abstract serves only as a summary.
read point-by-point responses
-
Referee: [Abstract / theoretical perspective] Abstract: the central claim that FLaG is a tractable approximation to the Bayes-optimal test statistic with a controllable error bound is asserted without any displayed equations, derivation steps, or error-bound analysis, so the approximation property and its controllability cannot be evaluated from the manuscript as presented.
Authors: The abstract summarizes the contribution at a high level. Section 3 of the manuscript contains the full derivation: it shows that the Bayes-optimal detector under heterogeneous mechanisms takes a log-marginal form, derives the energy-based routing as a tractable approximation, and states the controllable error bound (Theorem 2) with its proof. We will revise the abstract to include an explicit pointer to Section 3 and the key result so that the claim can be evaluated directly from the opening paragraph. revision: partial
-
Referee: [Abstract / experiments] Abstract: the SOTA performance claim and invariance to thresholds/metrics are stated but no quantitative results, ablation tables, or baseline comparisons are supplied, preventing assessment of whether the reported gains are load-bearing or reducible to standard mixture-model fitting.
Authors: Section 5 and Tables 1–4 supply the quantitative results, including SOTA comparisons across multiple LLM backbones and benchmarks, ablations isolating the latent grouping and log-marginal aggregation components, and explicit tests of threshold- and metric-invariance. These experiments demonstrate that the gains exceed those obtainable from standard mixture-model baselines. The abstract is not the appropriate location for tables; we therefore make no change to the experimental reporting but can add one or two headline numbers to the abstract if the editor prefers. revision: no
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description present FLaG as a mixture-style model using latent groups, energy-based routing, and log-marginal aggregation, with a claimed theoretical link to the Bayes-optimal statistic under heterogeneous mechanisms. No equations, self-citations, or derivations are exhibited that reduce the approximation, error bound, or SOTA claim to fitted parameters or self-referential definitions by construction. The log-marginal form is asserted as a property of the optimal statistic rather than derived from FLaG itself, and the framework is described as internally consistent without load-bearing self-citation chains or ansatz smuggling. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amos Azaria and Tom Mitchell. 2023. The internal state of an LLM knows when it’s lying. InEMNLP Findings(2023)
2023
-
[2]
Lennart Bürger, Fred A Hamprecht, and Boaz Nadler. 2024. Truth is universal: Robust detection of lies in llms.Advances in Neural Information Processing Systems 37 (2024), 138393–138431
2024
-
[3]
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2023. Discovering latent knowledge in language models without supervision. InICLR(2023)
2023
-
[4]
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. 2024. INSIDE: LLMs’ Internal States Retain the Power of Hallucination Detection. InICLR(2024)
2024
-
[5]
Jonathan H Clark, Eunsol Choi, Michael Collins, Dan Garrette, Tom Kwiatkowski, Vitaly Nikolaev, and Jennimaria Palomaki. 2020. Tydi qa: A benchmark for information-seeking question answering in ty pologically di verse languages. In TACL(2020)
2020
-
[6]
Xuefeng Du, Chaowei Xiao, and Yixuan Li. 2024. Haloscope: Harnessing unlabeled llm generations for hallucination detection. InNeurIPS(2024)
2024
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity.J. Mach. Learn. Res.23, 1, Article 120 (Jan. 2022), 39 pages
2022
-
[9]
Xiang Gao, Jiaxin Zhang, Lalla Mouatadid, and Kamalika Das. 2024. SPUQ: Perturbation-Based Uncertainty Quantification for Large Language Models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2336–2346
2024
-
[10]
Xiaomeng Hu, Yiming Zhang, Ru Peng, Haozhe Zhang, Chenwei Wu, Gang Chen, and Junbo Zhao. 2024. Embedding and Gradient Say Wrong: A White-Box Method for Hallucination Detection. InEMNLP(2024)
2024
-
[11]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2023. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems(2023)
2023
-
[12]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. 1991. Adaptive Mixtures of Local Experts.Neural Com- putation3, 1 (03 1991), 79–87. arXiv:https://direct.mit.edu/neco/article- pdf/3/1/79/812104/neco.1991.3.1.79.pdf doi:10.1162/neco.1991.3.1.79
-
[13]
Jordan and Robert A
Michael I. Jordan and Robert A. Jacobs. 1994. Hierarchical mixtures of experts and the EM algorithm.Neural Comput.6, 2 (March 1994), 181–214. doi:10.1162/ neco.1994.6.2.181
1994
-
[14]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. InACL(2017)
2017
-
[15]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, et al. 2022. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Semantic entropy probes: Robust and cheap hallucination detection in llms.arXiv preprint arXiv:2406.15927(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic Uncertainty: Lin- guistic Invariances for Uncertainty Estimation in Natural Language Generation. InICLR(2023)
2023
-
[18]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wat- tenberg. 2024. Inference-time intervention: Eliciting truthful answers from a language model. InNeurIPS(2024)
2024
-
[19]
Stephanie Lin, Jacob Hilton, and Owain Evans. [n. d.]. Teaching Models to Express Their Uncertainty in Words.Transactions on Machine Learning Research([n. d.])
-
[20]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words. InTMLR(2022)
2022
-
[21]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. InACL(2022)
2022
-
[22]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models. InTMLR (2024)
2024
-
[23]
Junteng Liu, Shiqi Chen, Yu Cheng, and Junxian He. 2024. On the Universal Truthfulness Hyperplane Inside LLMs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 18199–18224
2024
-
[24]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations. https://openreview.net/ forum?id=Bkg6RiCqY7
2019
-
[25]
Andrey Malinin and Mark Gales. 2018. Predictive uncertainty estimation via prior networks. InProceedings of the 32nd International Conference on Neural Information Processing Systems(Montréal, Canada)(NIPS’18). Curran Associates Inc., Red Hook, NY, USA, 7047–7058
2018
-
[26]
Andrey Malinin and Mark Gales. 2021. Uncertainty estimation in autoregressive structured prediction. InICLR(2021)
2021
-
[27]
Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Selfcheckgpt: Zero- resource black-box hallucination detection for generative large language models. InEMNLP(2023)
2023
-
[28]
Samuel Marks and Max Tegmark. 2024. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InCOLM (2024)
2024
-
[29]
Pham, Hongyu Zhang, and Jun Sun
Nay Myat Min, Long H. Pham, Hongyu Zhang, and Jun Sun. 2026. CORVUS: Red-Teaming Hallucination Detectors via Internal Signal Camouflage in Large Language Models. arXiv:2601.14310 [cs.CR] https://arxiv.org/abs/2601.14310
-
[30]
Jonas Ngnawé, Sabyasachi Sahoo, Yann Pequignot, Frédéric Precioso, and Chris- tian Gagné. 2024. Detecting Brittle Decisions for Free: Leveraging Margin Con- sistency in Deep Robust Classifiers. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Decem...
2024
-
[31]
Anna Pagh, Rasmus Pagh, and Milan Ruzic. 2007. Linear probing with constant independence. InProceedings of the thirty-ninth annual ACM symposium on Theory of computing. 318–327
2007
-
[32]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2023. Med- HALT: Medical Domain Hallucination Test for Large Language Models. InCoNLL (2023)
2023
-
[33]
Seongheon Park, Xuefeng Du, Min-Hsuan Yeh, Haobo Wang, and Yixuan Li. 2025. Steer LLM Latents for Hallucination Detection. InForty-second International KDD’26, Augest 09–13, 2026, Jeju, Korea Ye et al. Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19,
2025
-
[34]
https://openreview.net/forum?id=UMqNQEPNT3
OpenReview.net. https://openreview.net/forum?id=UMqNQEPNT3
-
[35]
Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversa- tional question answering challenge. InTACL(2019)
2019
-
[36]
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Laksh- minarayanan, and Peter J Liu. [n. d.]. Out-of-Distribution Detection and Selective Generation for Conditional Language Models. InThe Eleventh International Con- ference on Learning Representations
-
[37]
Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Laksh- minarayanan, and Peter J Liu. 2022. Out-of-distribution detection and selective generation for conditional language models. InICLR(2022)
2022
-
[38]
Thibault Sellam, Dipanjan Das, and Ankur P Parikh. 2020. BLEURT: Learning robust metrics for text generation. InACL(2020)
2020
-
[39]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Con- ference Track Proceedings. OpenReview.net. https...
2017
-
[40]
Ben Snyder, Marius Moisescu, and Muhammad Bilal Zafar. 2024. On early detec- tion of hallucinations in factual question answering. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2721–2732
2024
-
[41]
Hsuan Su, Ting-Yao Hu, Hema Swetha Koppula, Kundan Krishna, Hadi Pouransari, Cheng-Yu Hsieh, Cem Koc, Joseph Yitan Cheng, Oncel Tuzel, and Raviteja Vemulapalli. 2025. Learning to Reason for Hallucination Span Detection. CoRRabs/2510.02173 (2025). arXiv:2510.02173 doi:10.48550/ARXIV.2510.02173
-
[42]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi
-
[43]
InICLR(2024)
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InICLR(2024)
2024
-
[44]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al . 2024. Qwen2. 5 Technical Report.arXiv preprint arXiv:2412.15115(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Fan Yin, Jayanth Srinivasa, and Kai-Wei Chang. 2024. Characterizing truthfulness in large language model generations with local intrinsic dimension. InICML (2024)
2024
-
[46]
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al . 2023. Siren’s song in the AI ocean: a survey on hallucination in large language models.arXiv preprint arXiv:2309.01219(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023). A In-depth Theoretical Analysis This appendix provides detailed derivations and proof steps for the theoretical statements used in the main t...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.