Rethinking the Role of Temperature in Large Language Model Distillation
Pith reviewed 2026-06-28 23:24 UTC · model grok-4.3
The pith
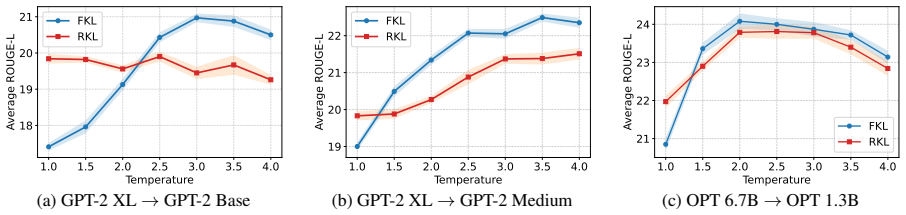
Increasing temperature in LLM distillation makes forward KL outperform reverse KL on instruction tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
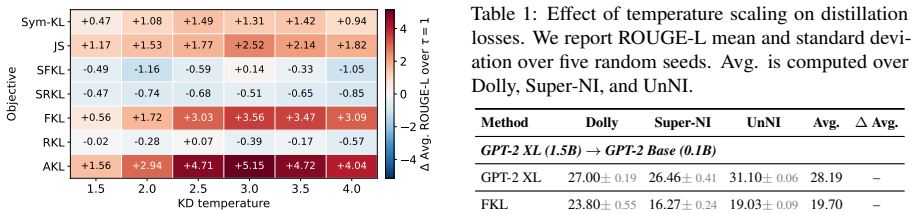
Temperature scaling in LLM distillation produces an asymmetric effect: it substantially enriches forward KL with non-dominant token signals while mainly rescaling gradients for reverse KL. As a result, although reverse KL outperforms forward KL at temperature one, forward KL surpasses reverse KL at higher temperatures across instruction-following benchmarks. The benefit of temperature extends beyond these two divergences to a broader family of distillation objectives.
What carries the argument
Temperature scaling of the teacher distribution inside forward and reverse KL distillation losses, which creates an asymmetric enrichment of gradient signals from non-dominant tokens.
If this is right
- FKL consistently surpasses RKL at higher temperatures across instruction-following benchmarks.
- Temperature scaling improves performance for a broader family of distillation objectives beyond the two KL variants.
- Simple KL-based distillation methods reach competitive results against recent state-of-the-art approaches once temperature is raised.
- The performance gain stems from temperature enriching non-dominant token signals more in FKL than in RKL.
Where Pith is reading between the lines
- Temperature may need to be tuned jointly with the choice of divergence rather than held fixed at one.
- The same temperature adjustment could be tested in distillation settings outside language models to check for similar asymmetry.
- Practitioners could add temperature sweeps as a standard step when selecting or combining distillation losses.
Load-bearing premise
The observed asymmetry between forward and reverse KL under temperature scaling holds across model sizes, datasets, and training setups without being driven by other unmentioned choices.
What would settle it
Re-running the distillation experiments on a new collection of model sizes or datasets and finding that reverse KL still outperforms forward KL at high temperatures would falsify the central claim.
Figures
read the original abstract
Reverse Kullback-Leibler (RKL) divergence is widely favored over forward KL (FKL) in large language models (LLM) distillation, yet this preference is largely based on comparisons that omit the temperature $\tau$, overlooking its central role in softening teacher distributions and improving knowledge transfer. In this work, we revisit temperature in LLM distillation and show that it fundamentally changes the comparison between FKL and RKL. Our analysis reveals an asymmetric effect: temperature substantially enriches FKL with non-dominant token signals, whereas it mainly rescales RKL gradients, causing FKL to benefit much more from $\tau$ scaling than RKL. This asymmetry overturns the standard empirical conclusion: although RKL outperforms FKL at $\tau=1$, FKL consistently surpasses RKL at higher temperatures across instruction-following benchmarks. Moreover, the impact of temperature is not limited to FKL; it improves a broader family of distillation objectives, enabling simple KL-based methods to achieve competitive performance against recent state-of-the-art LLM distillation approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that temperature scaling τ in LLM distillation has an asymmetric effect on forward KL (FKL) versus reverse KL (RKL): τ enriches FKL with non-dominant token signals while primarily rescaling RKL gradients. Consequently, although RKL outperforms FKL at τ=1, FKL surpasses RKL at higher τ across instruction-following benchmarks. The work further asserts that temperature improves a broader family of distillation objectives, allowing simple KL-based methods to compete with recent SOTA approaches.
Significance. If the empirical reversal and gradient asymmetry hold under controlled conditions, the result would challenge the prevailing preference for RKL in distillation and underscore temperature as a first-class hyperparameter. The mechanistic analysis of how τ affects each divergence provides a concrete explanation that, if supported by the experiments, elevates the contribution beyond a simple benchmark comparison.
major comments (2)
- [Experimental protocol / §4] The central empirical claim—that FKL overtakes RKL at high τ—rests on the assumption that temperature is the sole variable altered between comparisons. The manuscript must explicitly document (e.g., in the experimental protocol section) that optimizer, learning-rate schedule, number of epochs, data order, and initialization were identical across all FKL/RKL × τ settings; without such controls the observed reversal could arise from differential convergence or regularization effects rather than the claimed asymmetry.
- [Gradient analysis / §3] The abstract states that temperature “substantially enriches FKL with non-dominant token signals” while “mainly rescales RKL gradients,” yet no quantitative measure (e.g., gradient norm ratios, token-probability histograms, or an equation defining the enrichment) is referenced. A load-bearing claim of this form requires an explicit derivation or table (e.g., Eq. (X) or Table Y) showing the asymmetry before the benchmark results can be interpreted as evidence for it.
minor comments (2)
- [Results / §5] Clarify whether statistical significance (e.g., paired t-tests or bootstrap intervals) was computed for the benchmark reversals; reporting only mean scores leaves open the possibility that differences lie within run-to-run variance.
- [Broader objectives / §6] The claim that temperature improves “a broader family of distillation objectives” should be accompanied by the precise list of objectives tested and the corresponding performance deltas, ideally in a single summary table.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major comment below.
read point-by-point responses
-
Referee: [Experimental protocol / §4] The central empirical claim—that FKL overtakes RKL at high τ—rests on the assumption that temperature is the sole variable altered between comparisons. The manuscript must explicitly document (e.g., in the experimental protocol section) that optimizer, learning-rate schedule, number of epochs, data order, and initialization were identical across all FKL/RKL × τ settings; without such controls the observed reversal could arise from differential convergence or regularization effects rather than the claimed asymmetry.
Authors: We agree that explicit documentation strengthens the interpretation of the results. In the revised manuscript we will expand §4 to state that the optimizer, learning-rate schedule, number of epochs, data order, and initialization were held fixed across all FKL/RKL × τ combinations. revision: yes
-
Referee: [Gradient analysis / §3] The abstract states that temperature “substantially enriches FKL with non-dominant token signals” while “mainly rescales RKL gradients,” yet no quantitative measure (e.g., gradient norm ratios, token-probability histograms, or an equation defining the enrichment) is referenced. A load-bearing claim of this form requires an explicit derivation or table (e.g., Eq. (X) or Table Y) showing the asymmetry before the benchmark results can be interpreted as evidence for it.
Authors: Section 3 already contains the derivation showing the asymmetric effect of τ on the two divergences. To make the claim more directly verifiable we will add an explicit table (new Table Y) reporting gradient-norm ratios and token-probability histograms for representative τ values, with a cross-reference from the abstract and §3. revision: yes
Circularity Check
No significant circularity in empirical claims
full rationale
The paper's central claims rest on empirical benchmark comparisons of FKL vs RKL under temperature scaling, plus analysis of how temperature affects token signals and gradients in the loss. No derivation chain is presented that reduces by construction to fitted inputs, self-citations, or ansatzes; the asymmetry result is demonstrated experimentally rather than forced by definition or prior self-work. This matches the default expectation for an empirical study with no load-bearing mathematical reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature τ
axioms (1)
- standard math KL divergence definitions and gradient forms behave as described under temperature scaling
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Rethinking kullback-leibler divergence in knowledge distillation for large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[2]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Weight-inherited distillation for task-agnostic bert compression , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[3]
Journal of Machine Learning Research , volume=
Greedification operators for policy optimization: Investigating forward and reverse kl divergences , author=. Journal of Machine Learning Research , volume=
-
[4]
Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
Sequence-level knowledge distillation , author=. Proceedings of the 2016 conference on empirical methods in natural language processing , pages=
2016
-
[5]
Advances in Neural Information Processing Systems , volume=
Token-scaled logit distillation for ternary weight generative language models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Promptkd: Distilling student-friendly knowledge for generative language models via prompt tuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[7]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[8]
International Conference on Learning Representations , year=
Minillm: Knowledge distillation of large language models , author=. International Conference on Learning Representations , year=
-
[9]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Computer Vision and Image Understanding , volume=
Self-knowledge distillation via dropout , author=. Computer Vision and Image Understanding , volume=. 2023 , publisher=
2023
-
[11]
arXiv preprint arXiv:2212.12965 , year=
Bd-kd: Balancing the divergences for online knowledge distillation , author=. arXiv preprint arXiv:2212.12965 , year=
-
[12]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
F-divergence minimization for sequence-level knowledge distillation , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[13]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Decoupled knowledge distillation , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[14]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
TinyLlama: An Open-Source Small Language Model
Tinyllama: An open-source small language model , author=. arXiv preprint arXiv:2401.02385 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Forty-first International Conference on Machine Learning , year=
DistiLLM: Towards Streamlined Distillation for Large Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[18]
2025 , volume =
Wang, Guanghui and Yang, Zhiyong and Wang, Zitai and Wang, Shi and Xu, Qianqian and Huang, Qingming , booktitle =. 2025 , volume =
2025
-
[19]
OPT: Open Pre-trained Transformer Language Models
Opt: Open pre-trained transformer language models , author=. arXiv preprint arXiv:2205.01068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[21]
Distillation of Large Language Models via Concrete Score Matching
Distillation of Large Language Models via Concrete Score Matching , author=. arXiv preprint arXiv:2509.25837 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2009 , publisher=
Probabilistic graphical models: principles and techniques , author=. 2009 , publisher=
2009
-
[23]
arXiv preprint arXiv:2309.16240 , year=
Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints , author=. arXiv preprint arXiv:2309.16240 , year=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scaled decoupled distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Advances in Neural Information Processing Systems , volume=
Decoupled kullback-leibler divergence loss , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Mike Conover and Matt Hayes and Ankit Mathur and Jianwei Xie and Jun Wan and Sam Shah and Ali Ghodsi and Patrick Wendell and Matei Zaharia and Reynold Xin , title =
-
[27]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[28]
and Stoica, Ion and Xing, Eric P
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and Sheng, Ying and Wu, Zhanghao and Zhang, Hao and Zheng, Lianmin and Zhuang, Siyuan and Zhuang, Yonghao and Gonzalez, Joseph E. and Stoica, Ion and Xing, Eric P. , year =. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90\ url =
-
[29]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[30]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Unnatural instructions: Tuning language models with (almost) no human labor , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
A diversity-promoting objective function for neural conversation models , author=. Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2016
-
[32]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[33]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Texygen: A benchmarking platform for text generation models , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[34]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
On the efficacy of knowledge distillation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[35]
Proceedings of the AAAI conference on artificial intelligence , volume=
Improved knowledge distillation via teacher assistant , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-level logit distillation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Logit standardization in knowledge distillation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Yuxian Gu and Hao Zhou and Fandong Meng and Jie Zhou and Minlie Huang , booktitle=. Mini. 2025 , url=
2025
-
[39]
Proceedings of the AAAI conference on artificial intelligence , volume=
Curriculum temperature for knowledge distillation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[40]
2020 , eprint=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. 2020 , eprint=
2020
-
[41]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Tinybert: Distilling bert for natural language understanding , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[42]
A Survey of On-Policy Distillation for Large Language Models
A Survey of On-Policy Distillation for Large Language Models , author=. arXiv preprint arXiv:2604.00626 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Entropy-Aware On-Policy Distillation of Language Models
Entropy-Aware On-Policy Distillation of Language Models , author=. arXiv preprint arXiv:2603.07079 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Llm-oriented token-adaptive knowledge distillation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[45]
arXiv preprint arXiv:2604.00223 , year=
Diversity-Aware Reverse Kullback-Leibler Divergence for Large Language Model Distillation , author=. arXiv preprint arXiv:2604.00223 , year=
-
[46]
Jongwoo Ko and Tianyi Chen and Sungnyun Kim and Tianyu Ding and Luming Liang and Ilya Zharkov and Se-Young Yun , booktitle=. Disti. 2025 , url=
2025
-
[47]
arXiv preprint arXiv:2002.03532 , year=
Understanding and improving knowledge distillation , author=. arXiv preprint arXiv:2002.03532 , year=
-
[48]
In Proceedings of ICLR , year =
Adriana Romero and Nicolas Ballas and Samira Ebrahimi Kahou and Antoine Chassang and Carlo Gatta and Yoshua Bengio , title =. In Proceedings of ICLR , year =
-
[49]
International journal of computer vision , volume=
Knowledge distillation: A survey , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Knowledge distillation: A good teacher is patient and consistent , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Knowledge distillation with refined logits , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[52]
Consistently Informative Soft-Label Temperature for Knowledge Distillation
Consistently Informative Soft-Label Temperature for Knowledge Distillation , author=. arXiv preprint arXiv:2605.20357 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.