ScaRF-SLAM: Scale-Consistent Reconstruction with Feed-Forward Models and Classical Visual SLAM
Pith reviewed 2026-06-28 21:54 UTC · model grok-4.3
The pith
Decoupling classical SLAM tracking from GFM mapping, then anchoring and scaling the maps, produces more accurate trajectories and denser reconstructions than joint approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
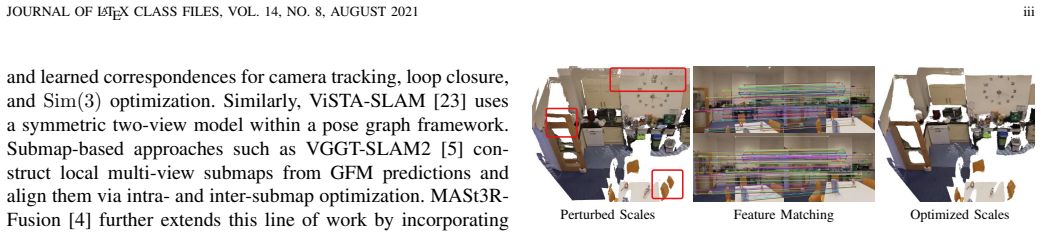
By using classical visual SLAM exclusively for robust tracking and GFMs exclusively for mapping, anchoring the mapping stage to the produced poses, and performing lightweight scale optimization plus projection-based fusion within submaps that update online, the system prevents geometric inaccuracies in GFM predictions from propagating into pose estimates while imposing geometric constraints that improve both trajectory accuracy and reconstruction precision.
What carries the argument
Decoupled framework that fixes classical SLAM poses as anchors for GFM-based submap construction and enforces scale consistency via frame and submap scale optimization.
If this is right
- Trajectory estimates remain more accurate than in systems that feed GFM predictions directly into tracking.
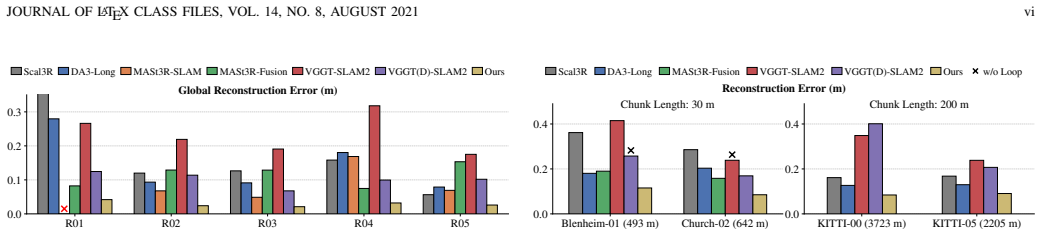
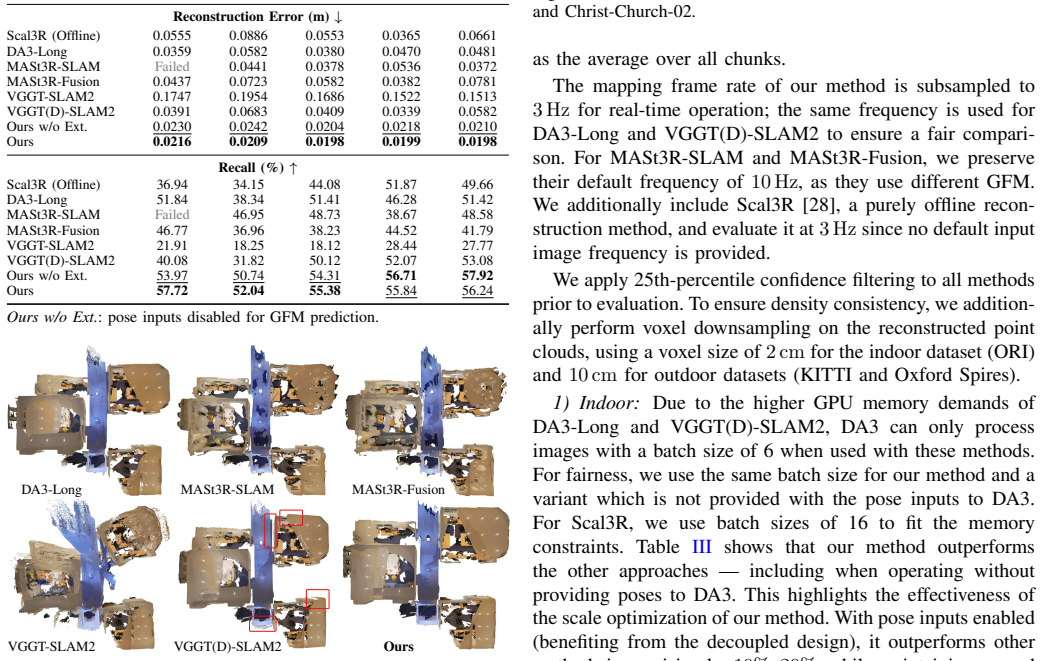
- Reconstruction precision improves 10-20 percent over existing unified methods on building-scale data.
- Error stays around 2 cm per 10 m chunk indoors and 10 cm per 30 m chunk outdoors relative to LiDAR ground truth.
- Submaps can be updated online whenever the classical tracker revises its trajectory without restarting the dense reconstruction.
Where Pith is reading between the lines
- The same anchor-and-scale pattern might apply to other tasks where one module is reliable but sparse and another is dense but uncertain.
- Removing the need for mapping-to-tracking feedback could simplify real-time pipelines on resource-limited robots.
- Scale optimization across submaps may generalize to outdoor scenes where absolute scale is harder to recover from monocular input alone.
Load-bearing premise
Classical feature-based SLAM can supply poses accurate and stable enough to serve as fixed anchors without any corrections flowing back from the mapping stage.
What would settle it
A direct comparison on the same sequences where classical SLAM poses contain larger drift than reported, checking whether reconstruction error then rises above the claimed 2 cm per 10 m or 10 cm per 30 m levels.
Figures




read the original abstract
Recent works have explored unifying SLAM with geometric foundation models (GFMs). However, directly using GFM predictions for tracking is highly sensitive to model capability and uncertainty, as geometric inaccuracies in the predictions can adversely affect pose estimation. To address this limitation, we present a decoupled framework that integrates classical feature-based SLAM with GFMs, which achieves higher quality and more consistent dense reconstruction. In brief, we use classical visual SLAM for robust low-latency tracking and use GFMs exclusively for mapping. By anchoring mapping to poses produced by the SLAM module and optimizing across depth scales, the proposed design avoids propagating inaccuracies from GFM predictions into pose estimation while imposing geometric constraints on the reconstruction. The system builds submaps from multiple posed keyframes and enforces scale consistency via lightweight frame and submap scale optimization. It also performs projection-based point cloud fusion within each submap, and updates submaps online to reflect trajectory updates from the feature-based SLAM. To evaluate tracking and reconstruction of our method, we introduce a loop-rich, building-scale indoor dataset with accurate sensor trajectories and LiDAR ground-truth. Experiments show that our approach achieves superior trajectory accuracy while improving reconstruction precision by 10%-20% over existing methods, with about 2 cm reconstruction error per 10 m chunk on building-scale dataset. On large-scale outdoor datasets, it attains 10 cm error per 30 m chunk (w.r.t LiDAR ground-truth models).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaRF-SLAM, a decoupled framework integrating classical feature-based visual SLAM for robust low-latency tracking with geometric foundation models (GFMs) used exclusively for mapping. Mapping is anchored to SLAM poses, with lightweight optimization of per-frame and per-submap scale factors to enforce consistency; submaps are built from posed keyframes, fused via projection-based point-cloud merging, and updated online. A new loop-rich building-scale indoor dataset with LiDAR ground truth is presented. Experiments claim superior trajectory accuracy and 10-20% gains in reconstruction precision (~2 cm error per 10 m chunk indoors; 10 cm per 30 m outdoors).
Significance. If validated, the hybrid decoupled design offers a practical route to leverage dense GFM predictions without their geometric uncertainties corrupting pose estimation, addressing a known sensitivity issue in unified GFM-SLAM systems. The new dataset is a useful contribution for evaluating scale-consistent reconstruction on loop-rich indoor scenes.
major comments (2)
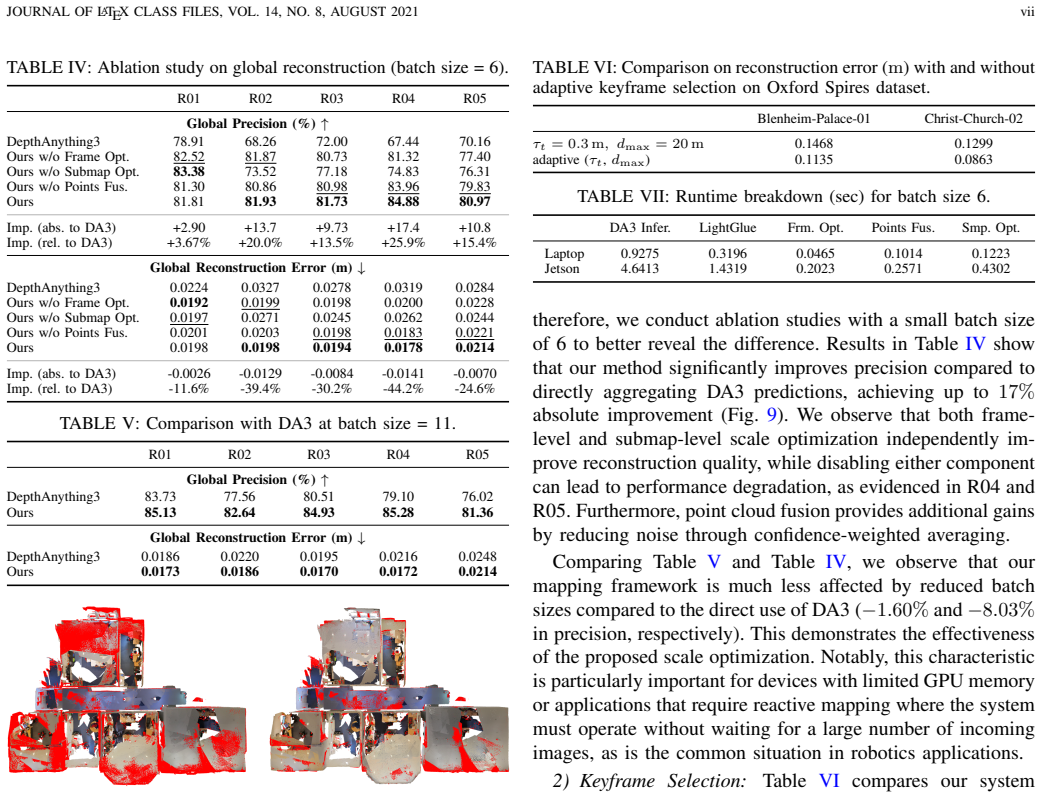
- [Abstract and §3] Abstract and §3 (decoupled architecture): the central claim that anchoring GFM mapping to classical SLAM poses plus frame/submap scale optimization yields 10-20% precision gains rests on the assumption that GFM depth errors are predominantly global scale errors. The manuscript must demonstrate (via ablation or residual-error analysis) that local geometric distortions, view-dependent biases, or outliers remaining after scale correction do not propagate under realistic GFM noise when poses are fixed and no mapping-to-tracking feedback exists.
- [§5] §5 (experiments and new dataset): quantitative claims of superior trajectory accuracy and reconstruction error (2 cm/10 m, 10 cm/30 m) are reported without visible baselines, ablations on scale optimization, error bars, or controls for post-hoc dataset choices. The loop-rich indoor dataset is introduced to stress-test consistency, yet no table or figure isolates whether the reported gains survive when classical SLAM drift is injected or when GFM predictions contain non-scale errors.
minor comments (2)
- Clarify the precise objective function and convergence criteria for the lightweight frame and submap scale optimization; state whether it is solved jointly or sequentially.
- Specify the exact projection-based fusion procedure (e.g., voxel size, outlier rejection thresholds) and how online submap updates handle trajectory corrections from the feature-based SLAM module.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the decoupled hybrid design and the new dataset. We address the major comments below, committing to revisions where the manuscript requires additional evidence.
read point-by-point responses
-
Referee: [Abstract and §3] The central claim that anchoring GFM mapping to classical SLAM poses plus scale optimization yields 10-20% gains rests on the assumption that GFM depth errors are predominantly global scale errors. The manuscript must demonstrate via ablation or residual-error analysis that local geometric distortions, view-dependent biases, or outliers do not propagate when poses are fixed.
Authors: We agree that the effectiveness of the decoupled approach depends on scale optimization primarily addressing global inconsistencies rather than local distortions. The current manuscript shows improved reconstruction metrics through submap fusion and scale factors, but does not include explicit residual analysis isolating local errors under fixed poses. We will add an ablation study in the revised §3 and §5 that quantifies residual geometric errors after scale correction on the building-scale dataset and analyzes their propagation under realistic GFM noise levels. revision: yes
-
Referee: [§5] Quantitative claims of superior trajectory accuracy and reconstruction error are reported without visible baselines, ablations on scale optimization, error bars, or controls for post-hoc dataset choices. No table or figure isolates whether gains survive when classical SLAM drift is injected or when GFM predictions contain non-scale errors.
Authors: The experiments section compares against existing methods and reports absolute errors relative to LiDAR ground truth, but we acknowledge the absence of explicit ablations on scale optimization, error bars, and controls for injected drift or non-scale GFM errors. In the revision we will expand §5 with: (i) an ablation table isolating the contribution of frame/submap scale optimization, (ii) error bars across multiple runs, and (iii) additional experiments injecting controlled SLAM drift and non-scale GFM perturbations to verify robustness of the reported gains. revision: yes
Circularity Check
No circularity; decoupled integration of independent classical SLAM and GFM components
full rationale
The paper presents a system-level integration that uses classical feature-based SLAM solely for tracking (providing fixed poses) and GFMs solely for mapping, followed by post-hoc scale optimization and fusion. No equations, uniqueness theorems, or self-citations are shown that define any claimed output (trajectory accuracy, reconstruction precision, or error rates) in terms of the method's own fitted parameters or prior results by the same authors. The performance numbers are presented as experimental outcomes on external datasets rather than reductions by construction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- frame and submap scale factors
axioms (2)
- domain assumption Classical feature-based visual SLAM produces robust low-latency poses suitable for anchoring dense mapping
- domain assumption Geometric foundation model depth predictions remain useful when camera poses are supplied externally
Reference graph
Works this paper leans on
-
[1]
SLAM Handbook: From Localization and Mapping to Spatial Intelligence,
L. Carlone, A. Kim, T. Barfoot, D. Cremers, and F. Dellaert, “SLAM Handbook: From Localization and Mapping to Spatial Intelligence,” 2025
2025
-
[2]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shiet al., “Depth Anything 3: Recovering the Visual Space from Any Views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
MASt3R-SLAM: Real- Time Dense SLAM with 3D Reconstruction Priors,
R. Murai, E. Dexheimer, and A. J. Davison, “MASt3R-SLAM: Real- Time Dense SLAM with 3D Reconstruction Priors,” inIEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[4]
MASt3R-Fusion: Integrating Feed-Forward Visual Model with IMU, GNSS for High- Functionality SLAM,
Y . Zhou, X. Li, S. Li, Z. Yan, C. Xia, and S. Feng, “MASt3R-Fusion: Integrating Feed-Forward Visual Model with IMU, GNSS for High- Functionality SLAM,”arXiv preprint arXiv:2509.20757, 2025
-
[5]
VGGT-SLAM 2.0: Real-time dense feed- forward scene reconstruction,
D. Maggio and L. Carlone, “VGGT-SLAM 2.0: Real-Time Dense Feed- Forward Scene Reconstruction,”arXiv preprint arXiv:2601.19887, 2026
-
[6]
A Benchmark for the Evaluation of RGB-D SLAM Systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A Benchmark for the Evaluation of RGB-D SLAM Systems,” inIEEE/RSJ Intl. Conf. on Intelligent Robots and Systems (IROS), 2012
2012
-
[7]
BAD SLAM: Bundle Adjusted Direct RGB-D SLAM,
T. Schops, T. Sattler, and M. Pollefeys, “BAD SLAM: Bundle Adjusted Direct RGB-D SLAM,” inIEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[8]
The EuRoC Micro Aerial Vehicle Datasets,
M. Burri, J. Nikolic, P. Gohl, T. Schneider, J. Rehder, S. Omari et al., “The EuRoC Micro Aerial Vehicle Datasets,”Intl. J. of Robotics Research, 2016
2016
-
[9]
ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard´os, “ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual–Inertial, and Multimap SLAM,”IEEE Trans. Robotics, 2021
2021
-
[10]
OpenVINS: A Research Platform for Visual-Inertial Estimation,
P. Geneva, K. Eckenhoff, W. Lee, Y . Yang, and G. Huang, “OpenVINS: A Research Platform for Visual-Inertial Estimation,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), 2020
2020
-
[11]
maplab: An Open Framework for Research in Visual-Inertial Mapping and Localization,
T. Schneider, M. Dymczyk, M. Fehr, K. Egger, S. Lynen, I. Gilitschenski et al., “maplab: An Open Framework for Research in Visual-Inertial Mapping and Localization,”IEEE Robotics and Automation Letters, 2018
2018
-
[12]
KinectFusion: Real-Time Dense Surface Mapping and Tracking,
R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davisonet al., “KinectFusion: Real-Time Dense Surface Mapping and Tracking,” inIEEE/ACM Intl. Sym. on Mixed and Augmented Reality (ISMAR), 2011
2011
-
[13]
ElasticFusion: Dense SLAM without a Pose Graph,
T. Whelan, S. Leutenegger, R. F. Salas-Moreno, B. Glocker, and A. J. Davison, “ElasticFusion: Dense SLAM without a Pose Graph,” in Robotics: Science and Systems (RSS), 2015
2015
-
[14]
CodeSLAM: Learning a Compact, Optimisable Representation for Dense Visual SLAM,
M. Bloesch, J. Czarnowski, R. Clark, S. Leutenegger, and A. J. Davison, “CodeSLAM: Learning a Compact, Optimisable Representation for Dense Visual SLAM,” inIEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[15]
SimpleMapping: Real- Time Visual-Inertial Dense Mapping with Deep Multi-View Stereo,
Y . Xin, X. Zuo, D. Lu, and S. Leutenegger, “SimpleMapping: Real- Time Visual-Inertial Dense Mapping with Deep Multi-View Stereo,” in IEEE/ACM Intl. Sym. on Mixed and Augmented Reality (ISMAR), 2023
2023
-
[16]
Uncertainty-Aware Visual-Inertial SLAM with V olumetric Occupancy Mapping,
J. Jung, S. Boche, S. B. Laina, and S. Leutenegger, “Uncertainty-Aware Visual-Inertial SLAM with V olumetric Occupancy Mapping,” inIEEE Intl. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[17]
OKVIS2-X: Open Keyframe-Based Visual-Inertial SLAM Configurable with Dense Depth or LiDAR, and GNSS,
S. Boche, J. Jung, S. B. Laina, and S. Leutenegger, “OKVIS2-X: Open Keyframe-Based Visual-Inertial SLAM Configurable with Dense Depth or LiDAR, and GNSS,”IEEE Trans. Robotics, 2025
2025
-
[18]
Grounding Image Matching in 3D with MASt3R,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding Image Matching in 3D with MASt3R,” inEur . Conf. on Computer Vision (ECCV), 2024
2024
-
[19]
VGGT: Visual Geometry Grounded Transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “VGGT: Visual Geometry Grounded Transformer,” inIEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[20]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer et al., “MapAnything: Universal Feed-Forward Metric 3D Reconstruc- tion,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie, “VGGT-Long: Chunk It, Loop It, Align It–Pushing VGGT’s Limits on Kilometer-Scale Long RGB Sequences,”arXiv preprint arXiv:2507.16443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
LASER: Layer-Wise Scale Alignment for Training-Free Streaming 4D Reconstruction,
T. Ding, Y . Xie, Y . Liang, M. Chatterjee, P. Miraldo, and H. Jiang, “LASER: Layer-Wise Scale Alignment for Training-Free Streaming 4D Reconstruction,”arXiv preprint arXiv:2512.13680, 2025
-
[23]
arXiv preprint arXiv:2509.01584 (2025)
G. Zhang, S. Qian, X. Wang, and D. Cremers, “ViSTA-SLAM: Vi- sual SLAM with Symmetric Two-View Association,”arXiv preprint arXiv:2509.01584, 2025
-
[24]
LightGlue: Local Feature Matching at Light Speed,
P. Lindenberger, P.-E. Sarlin, and M. Pollefeys, “LightGlue: Local Feature Matching at Light Speed,” inIntl. Conf. on Computer Vision (ICCV), 2023
2023
-
[25]
borglab/gtsam,
F. Dellaert and G. Contributors, “borglab/gtsam,” May 2022. [Online]. Available: https://github.com/borglab/gtsam)
2022
-
[26]
Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite,” inIEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[27]
The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR- Visual Localisation, Reconstruction, and Radiance Field Methods,
Y . Tao, M. ´A. Mu˜noz-Ba˜n´on, L. Zhang, J. Wang, L. F. T. Fu, and M. Fal- lon, “The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR- Visual Localisation, Reconstruction, and Radiance Field Methods,”Intl. J. of Robotics Research, 2024
2024
-
[28]
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction,
T. Xie, P. Yang, Y . Jin, Y . Cai, W. Yin, W. Renet al., “Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction,”IEEE Int. Conf. Computer Vision and Pattern Recognition (CVPR), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.