Which Institutional Frameworks Do Chatbots Assume? Auditing Jurisdictional Defaults in Multilingual LLMs
Pith reviewed 2026-06-28 22:05 UTC · model grok-4.3
The pith
Multilingual LLMs default to U.S. legal frameworks on English prompts and China frameworks on Chinese prompts when jurisdiction is omitted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
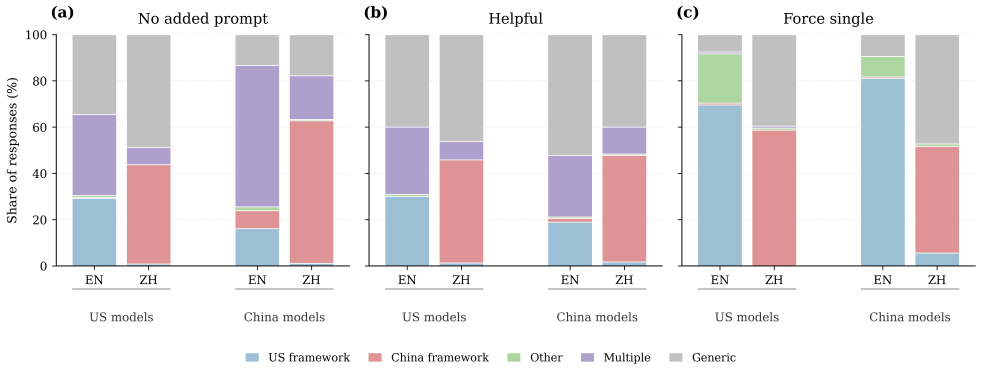
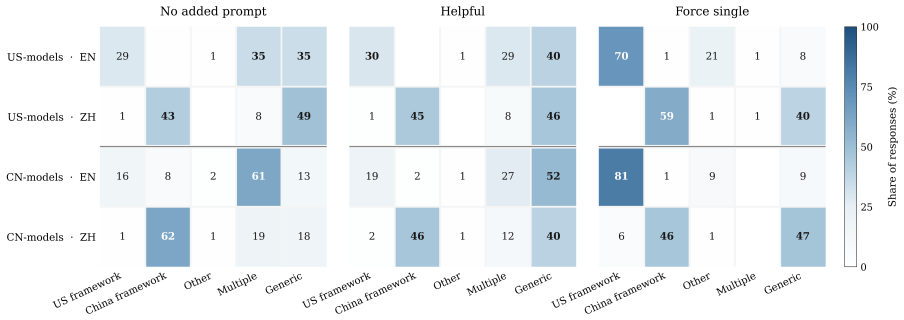
When jurisdiction is omitted from prompts about taxes, labor protections, healthcare, education, pensions, and administrative procedures, seven LLMs consistently supply answers assuming the legal-administrative framework associated with the input language: China-specific answers rise with Mandarin Chinese input, while U.S.-specific, comparative, or generic answers rise with English input. This directional pattern appears across all models and system-prompt conditions, and prompts requiring a single answer increase jurisdiction selection to 74.5 percent U.S. framework for English input and 53.3 percent China framework for Chinese input.
What carries the argument
Input language functioning as an implicit default selector among institutional frameworks in underspecified legal-administrative queries.
If this is right
- Users whose comfortable language differs from the relevant jurisdiction face elevated risk of receiving answers under the wrong set of rules.
- LLM interfaces should request location information or explicitly state the jurisdictional scope when it is absent from the prompt.
- The observed pattern is independent of whether the model was developed in the United States or China.
Where Pith is reading between the lines
- The same language cue may shape model outputs on non-legal topics such as political or cultural advice.
- Testing additional languages could reveal whether the effect is specific to English-Chinese pairs or generalizes to other language pairs.
- Explicit jurisdiction statements in prompts may serve as an override that reduces reliance on language defaults.
Load-bearing premise
The 60 prompts adequately represent real underspecified legal-administrative queries and the manual annotations of the 2,520 responses correctly and consistently identify the assumed jurisdiction without substantial bias from prompt choice or annotator judgment.
What would settle it
Running the same 60 prompts with an added explicit statement of a different jurisdiction and checking whether the language-based pattern disappears or reverses.
Figures


read the original abstract
LLMs increasingly answer questions about taxes, labor protections, healthcare, education, pensions, and administrative procedures, where usefulness often depends on the applicable jurisdiction. Multilingual users may write in their most comfortable language rather than one associated with the country or region whose rules apply. We ask whether deployed LLMs use input language as a default jurisdictional signal when prompts omit any country or region. Prior multilingual audits show that prompt language can shift cultural, political, or normative outputs; we examine which legal-administrative framework models supply when jurisdiction is underspecified. We evaluate seven LLMs developed in the United States or China on 60 underspecified legal-administrative prompts in English and Mandarin Chinese under three system-prompt conditions, yielding 2,520 manually annotated responses. Across models and conditions, Chinese input more often produces China-specific answers, while English input more often produces U.S.-specific, comparative, or generic answers. Prompts requiring a single answer further increase jurisdiction selection: pooled across models, 74.5% of English-input responses adopt a U.S. framework, while 53.3% of Chinese-input responses adopt a China framework. This directional pattern appears in all seven models. We describe this deployment-level pattern as institutional-framework misselection risk: a fluent answer may rely on a legal-administrative context the user did not intend, especially when their preferred language differs from the relevant jurisdiction. LLM interfaces should not route institutional advice by input language alone; when location is absent, they should request it or state the jurisdictional scope of the answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits whether seven US- and China-developed LLMs default to US- or China-specific legal-administrative frameworks when answering 60 underspecified prompts (taxes, labor, healthcare, etc.) in English versus Mandarin Chinese under three system-prompt conditions. Manual annotation of the resulting 2,520 responses reveals a consistent directional pattern: English inputs more often elicit U.S.-specific, comparative, or generic answers (pooled 74.5% U.S. framework), while Chinese inputs more often elicit China-specific answers (pooled 53.3% China framework); single-answer prompts amplify jurisdiction selection. The authors label this “institutional-framework misselection risk” and recommend that interfaces request location or state scope rather than routing by input language alone.
Significance. If the annotation scheme is reliable, the result supplies a concrete, falsifiable empirical baseline on language-as-jurisdiction proxy in deployed multilingual models. The scale (seven models, 2,520 responses, three conditions) and the fact that the directional pattern holds in every model are strengths; the finding directly informs interface design for cross-lingual users of legal-administrative advice.
major comments (2)
- [Abstract / Evaluation Setup] The central pooled percentages (74.5 % English-input U.S. framework, 53.3 % Chinese-input China framework) rest entirely on human classification of 2,520 model outputs. The manuscript provides neither an annotation protocol, inter-annotator agreement statistics, nor a description of how ambiguous or multi-jurisdictional answers were coded (see the abstract and the paragraph describing the 2,520 responses). This directly affects the load-bearing claim that the directional pattern is robust.
- [Prompt Construction] The 60 prompts are presented as representative of underspecified legal-administrative queries, yet no sampling frame, coverage argument, or sensitivity analysis is supplied. If the prompt set is idiosyncratic, the reported jurisdiction-selection rates could shift substantially.
minor comments (2)
- [Abstract] The abstract states that prompt examples and annotation guidelines are omitted; providing at least a few representative prompts and the exact coding rubric would allow readers to assess classification decisions.
- [Results] Table or figure that breaks the 74.5 % / 53.3 % figures down by model and condition would make the “appears in all seven models” claim easier to verify at a glance.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify areas where additional methodological transparency will strengthen the paper. We address each point below and commit to revisions that directly respond to the concerns while preserving the core empirical contribution.
read point-by-point responses
-
Referee: [Abstract / Evaluation Setup] The central pooled percentages (74.5 % English-input U.S. framework, 53.3 % Chinese-input China framework) rest entirely on human classification of 2,520 model outputs. The manuscript provides neither an annotation protocol, inter-annotator agreement statistics, nor a description of how ambiguous or multi-jurisdictional answers were coded (see the abstract and the paragraph describing the 2,520 responses). This directly affects the load-bearing claim that the directional pattern is robust.
Authors: We agree that the submitted manuscript omitted a full description of the annotation protocol. In the revision we will add a dedicated subsection (and appendix) that (i) reproduces the complete annotation guidelines used by the three annotators, (ii) specifies the coding rules for ambiguous, multi-jurisdictional, or refusal responses (treated as 'comparative' or 'generic' when no single jurisdiction was selected), and (iii) reports inter-annotator agreement on a 10 % stratified sample (Cohen's κ). These additions will make the 74.5 % / 53.3 % figures directly reproducible and will address the robustness concern. revision: yes
-
Referee: [Prompt Construction] The 60 prompts are presented as representative of underspecified legal-administrative queries, yet no sampling frame, coverage argument, or sensitivity analysis is supplied. If the prompt set is idiosyncratic, the reported jurisdiction-selection rates could shift substantially.
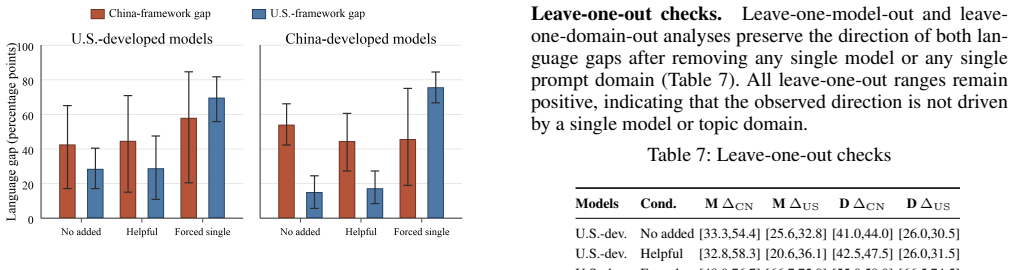
Authors: The 60 prompts were constructed to span six high-stakes domains (tax, labor, healthcare, education, pensions, administrative procedures) with balanced single-answer versus open-ended formats. While a formal probabilistic sampling frame from a larger population of queries was not feasible, the set was iteratively refined for domain coverage and underspecification. In revision we will (i) add an explicit coverage argument mapping each prompt to the six domains, (ii) include a sensitivity analysis that recomputes the pooled percentages after successively dropping each domain, and (iii) report that the directional English→U.S. / Chinese→China pattern remains stable across all leave-one-domain-out subsets. These steps will quantify the dependence on the particular prompt collection. revision: yes
Circularity Check
No circularity: purely empirical counts from model outputs and manual annotation
full rationale
The paper reports an audit consisting of 60 prompts run on seven LLMs under controlled conditions, followed by manual annotation of 2,520 responses into jurisdictional categories and simple percentage tabulation. No equations, parameters, derivations, or uniqueness theorems appear. The central 74.5%/53.3% figures are direct empirical tallies, not outputs of any fitted model or self-referential construction. No self-citations are invoked to justify load-bearing premises, ansatzes, or uniqueness results. The methodology is externally replicable via the prompt set and annotation criteria; therefore the findings do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 60 prompts omit any explicit country or region and are therefore jurisdiction-underspecified.
- domain assumption Human annotators can reliably classify model responses as adopting a U.S. framework, China framework, comparative, or generic.
Reference graph
Works this paper leans on
-
[1]
AlKhamissi, Badr and ElNokrashy, Muhammad and Alkhamissi, Mai and Diab, Mona , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.671 , url =
-
[2]
2026 , note =
AI Mistakes Accountants Are Fixing This Tax Season , howpublished =. 2026 , note =
2026
-
[3]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =
Bignotti, Camilla and Camassa, Carolina , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , doi =
2024
-
[4]
Cheong, Inyoung and Xia, King and Feng, K. J. Kevin and Chen, Quan Ze and Zhang, Amy X. , title =. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , series =. 2024 , publisher =
2024
-
[5]
and Zhang, Wei and Gomes, Jose O
Guey, William and Bougault, Pierrick and de Moura, Vitor D. and Zhang, Wei and Gomes, Jose O. , title =. 2025 , doi =
2025
-
[6]
Guha, Neel and Nyarko, Julian and Ho, Daniel E. and R. LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models , booktitle =. 2023 , url =
2023
-
[7]
, title =
Haslett, David and Huang, Linus Ta-Lun and Khalatbari, Leila and Hsiao, Janet Hui-wen and Chan, Antoni B. , title =. 2025 , doi =
2025
-
[8]
Findings of the Association for Computational Linguistics: ACL 2025 , pages =
Helwe, Chadi and Balalau, Oana and Ceolin, Davide , title =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , address =. doi:10.18653/v1/2025.findings-acl.883 , url =
-
[9]
Challenges and Strategies in Cross-Cultural
Hershcovich, Daniel and Frank, Stella and Lent, Heather and de Lhoneux, Miryam and Abdou, Mostafa and Brandl, Stephanie and Bugliarello, Emanuele and Cabello Piqueras, Laura and Chalkidis, Ilias and Cui, Ruixiang and Fierro, Constanza and Margatina, Katerina and Rust, Phillip and S. Challenges and Strategies in Cross-Cultural. Proceedings of the 60th Annu...
-
[10]
2025 , doi =
Huang, PeiHsuan and Lin, ZihWei and Imbot, Simon and Fu, WenCheng and Tu, Ethan , title =. 2025 , doi =
2025
-
[11]
Proceedings of the 33rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems , pages =
Janowicz, Krzysztof and Liu, Zilong and Mai, Gengchen and Wang, Zhangyu and Majic, Ivan and Fortacz, Alexandra and McKenzie, Grant and Gao, Song , title =. Proceedings of the 33rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems , pages =. 2025 , publisher =
2025
-
[12]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =. 2020 , address =. doi:10.18653/v1/2020.acl-main.560 , url =
-
[13]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =
Kay, Jackie and Kasirzadeh, Atoosa and Mohamed, Shakir , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , doi =
2024
-
[14]
Kumar, Shivani and Jurgens, David , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , address =. doi:10.18653/v1/2025.acl-long.294 , url =
-
[15]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , series =
Lopez, Paola , title =. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , series =. 2024 , publisher =
2024
-
[16]
and Ritter, Alan and Xu, Wei , title =
Naous, Tarek and Ryan, Michael J. and Ritter, Alan and Xu, Wei , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.862 , url =
-
[17]
R. Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models , booktitle =. 2024 , address =. doi:10.18653/v1/2024.acl-long.816 , url =
-
[18]
and Held, William and Yang, Diyi , title =
Ryan, Michael J. and Held, William and Yang, Diyi , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.853 , url =
-
[19]
Multilingual != Multicultural: Evaluating Gaps Between Multilingual Capabilities and Cultural Alignment in
Rystr. Multilingual != Multicultural: Evaluating Gaps Between Multilingual Capabilities and Cultural Alignment in. Proceedings of Interdisciplinary Workshop on Observations of Misunderstood, Misguided and Malicious Use of Language Models , pages =. 2025 , address =
2025
-
[20]
2026 , doi =
Smirnov, Oleg , title =. 2026 , doi =
2026
-
[21]
, title =
Varshney, Kush R. , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , doi =
2024
-
[22]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =
Vida, Karina and Damken, Fabian and Lauscher, Anne , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , doi =
2024
-
[23]
Do Prompt-Based Models Really Understand the Meaning of Their Prompts? , author =. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , month = jul, year =. doi:10.18653/v1/2022.naacl-main.167 , pages =
-
[24]
Wang, Wenxuan and Jiao, Wenxiang and Huang, Jingyuan and Dai, Ruyi and Huang, Jen-tse and Tu, Zhaopeng and Lyu, Michael R. , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.345 , url =
-
[25]
2026 , note =
Why Using. 2026 , note =
2026
-
[26]
2024 , doi =
Zhong, Qishuai and Yun, Yike and Sun, Aixin , title =. 2024 , doi =
2024
-
[27]
Zhou, Naitian and Bamman, David and Bleaman, Isaac L. , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/2025.acl-long.1256 , url =
-
[28]
The Twelfth International Conference on Learning Representations , year =
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or: How I Learned to Start Worrying about Prompt Formatting , author =. The Twelfth International Conference on Learning Representations , year =
-
[29]
Durmus, Esin and Nyugen, Karina and Liao, Thomas I. and Schiefer, Nicholas and Askell, Amanda and Bakhtin, Anton and Chen, Carol and Hatfield-Dodds, Zac and Hernandez, Danny and Joseph, Nicholas and Lovitt, Liane and McCandlish, Sam and Sikder, Orowa and Tamkin, Alex and Thamkul, Janel and Kaplan, Jared and Clark, Jack and Ganguli, Deep , title =. First C...
2024
-
[30]
and Kizilcec, Ren
Tao, Yan and Viberg, Olga and Baker, Ryan S. and Kizilcec, Ren. Cultural Bias and Cultural Alignment of Large Language Models , journal =. 2024 , doi =
2024
-
[31]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and. The. 2024 , eprint =
2024
-
[32]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems 37 (. 2024 , url =
2024
-
[33]
2024 , eprint =
Yang, An and Yang, Baosong and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Zhou, Chang and Li, Chengpeng and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Dong, Guanting and Wei, Haoran and Lin, Huan and Tang, Jialong and Wang, Jialin and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Ma, Jianxin and Yang, Jianxin and Xu, Jin and Zhou, Jingren a...
2024
-
[34]
Computational Linguistics , volume =
Pawar, Siddhesh and Park, Junyeong and Jin, Jiho and Arora, Arnav and Myung, Junho and Yadav, Srishti and Haznitrama, Faiz Ghifari and Song, Inhwa and Oh, Alice and Augenstein, Isabelle , title =. Computational Linguistics , volume =. 2025 , doi =. 2411.00860 , archivePrefix =
arXiv 2025
-
[35]
2007 , publisher =
Fricker, Miranda , title =. 2007 , publisher =
2007
-
[36]
and Boyd, Danah and Friedler, Sorelle A
Selbst, Andrew D. and Boyd, Danah and Friedler, Sorelle A. and Venkatasubramanian, Suresh and Vertesi, Janet , title =. Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT*) , pages =. 2019 , publisher =
2019
-
[37]
, title =
Herd, Pamela and Moynihan, Donald P. , title =. 2018 , publisher =
2018
-
[38]
Biased Tales: Cultural and Topic Bias in Generating Children's Stories , booktitle =
Rooein, Donya and Zouhar, Vil\'. Biased Tales: Cultural and Topic Bias in Generating Children's Stories , booktitle =. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.3 , url =
-
[39]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
Bhatt, Shaily and Diaz, Fernando , title =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-emnlp.942 , url =
-
[40]
Proceedings of the Third Workshop on Narrative Understanding , pages =
Lucy, Li and Bamman, David , title =. Proceedings of the Third Workshop on Narrative Understanding , pages =. 2021 , address =. doi:10.18653/v1/2021.nuse-1.5 , url =
-
[41]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Wan, Yixin and Pu, George and Sun, Jiao and Garimella, Aparna and Chang, Kai-Wei and Peng, Nanyun , title =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , address =. doi:10.18653/v1/2023.findings-emnlp.243 , url =
-
[42]
Toro Isaza, Paulina and Xu, Guangxuan and Oloko, Toye and Hou, Yufang and Peng, Nanyun and Wang, Dakuo , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , address =. doi:10.18653/v1/2023.acl-long.359 , url =
-
[43]
Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =
Arzaghi, Mina and Carichon, Florian and Farnadi, Golnoosh , title =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , volume =. 2024 , doi =
2024
-
[44]
Transactions of the Association for Computational Linguistics , volume =
Malaviya, Chaitanya and Chang, Joseph Chee and Roth, Dan and Iyyer, Mohit and Yatskar, Mark and Lo, Kyle , title =. Transactions of the Association for Computational Linguistics , volume =. 2025 , address =. doi:10.1162/tacl.a.24 , url =
-
[45]
2024 , url =
Niklaus, Joel and Matoshi, Veton and St. 2024 , url =
2024
-
[46]
1948 , note =
Universal Declaration of Human Rights , howpublished =. 1948 , note =
1948
-
[47]
Decent Work , howpublished =
-
[48]
2026 , note =
Worldwide Governance Indicators , howpublished =. 2026 , note =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.