From Talking Words to Sharing Thoughts: Scalable Multi-LLM Aggregation via Structured Message Passing
Pith reviewed 2026-06-28 19:29 UTC · model grok-4.3
The pith
A bipartite factor graph with message passing aggregates LLM outputs at the semantic layer without extra inference calls, cutting token use 97 percent and API calls up to 6X.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
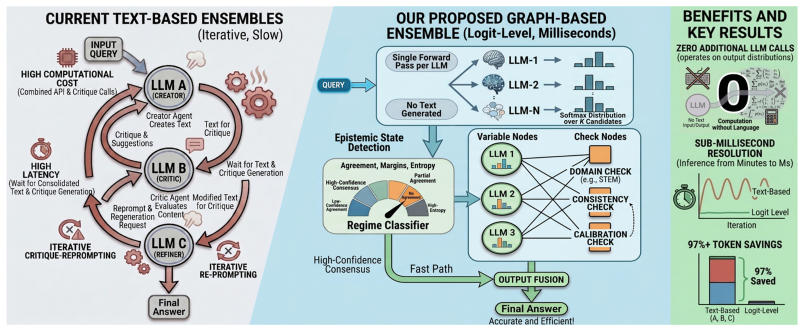
Individual LLMs are modeled as variable nodes in a bipartite factor graph whose check nodes evaluate output consistency on diverse epistemic criteria; a message-passing schedule inspired by error-recovery codes then iteratively updates beliefs, protected by asymmetric damping that prevents high-reliability anchors from being overridden, all performed on output distributions so that no further LLM inference is required during refinement.
What carries the argument
Bipartite factor graph whose variable nodes hold LLM output distributions and check nodes perform consistency scoring, together with the message-passing protocol and asymmetric damping rule.
If this is right
- Token consumption during aggregation falls by 97 percent relative to iterative multi-agent baselines.
- API calls drop by a factor of up to six, moving inference time from minutes to milliseconds.
- Accuracy exceeds that of leading multi-agent systems on MMLU, MMLU-Pro, GPQA, and MedMCQA.
- The refinement stage consumes zero additional model inferences once initial outputs are obtained.
- The approach scales to larger numbers of models without a proportional rise in cost.
- pith_inferences=[
Load-bearing premise
Check nodes can correctly judge consistency using the chosen epistemic criteria and the message-passing updates can reach a stable aggregate without any additional calls to the original models.
What would settle it
On the same four benchmarks, a version of the system whose check-node consistency scores are replaced by random values produces final accuracy no higher than simple majority voting.
Figures
read the original abstract
The emergence of specialized, domain-tuned Large Language Models (LLMs) has demonstrated that smaller models can achieve expert-level performance in specific tasks, while struggling in out-of-domain settings. Current ensemble methods to combine their complementary expertise primarily rely on iterative re-prompting or cross-model refinement. These approaches suffer from high computational costs and latency because they require repeated LLM inference calls. Furthermore, naive aggregation often leads to anchor corruption, in which noise propagated from weaker models degrades the performance of the most accurate expert. To address these challenges, we propose a framework that integrates model predictions at the semantic layer using a bipartite factor graph. In this architecture, individual LLMs are represented as variable nodes, while a set of check nodes assess their consistency based on diverse epistemic criteria. We develop a message-passing protocol inspired by error-recovery systems to resolve disagreements iteratively. Furthermore, we introduce an asymmetric damping mechanism that protects high-reliability anchor nodes from being overridden by the ensemble majority. Unlike existing methods, our approach operates on output distributions and requires no additional LLM calls during the refinement phase. Evaluating on four benchmarks, including MMLU, MMLU-Pro, GPQA, and MedMCQA, our method demonstrates a 97% reduction in token usage and up to a 6X decrease in API calls, reducing inference time from several minutes to mere milliseconds while consistently outperforming leading multi-agent baselines. These results suggest that graph-based belief propagation is a robust, high-speed, and scalable alternative to the current multi-agent LLM systems. The full pipeline and code will be made public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bipartite factor graph framework for aggregating predictions from multiple specialized LLMs. Variable nodes represent individual models while check nodes evaluate consistency via diverse epistemic criteria; a message-passing protocol inspired by error-recovery systems iteratively resolves disagreements, and an asymmetric damping mechanism protects high-reliability anchors. The method is claimed to operate directly on output distributions with no additional LLM inference calls during refinement, yielding a 97% reduction in token usage, up to 6X fewer API calls, and superior accuracy to multi-agent baselines on MMLU, MMLU-Pro, GPQA, and MedMCQA.
Significance. If the central claim that check nodes can perform reliable semantic consistency assessment and disagreement resolution purely from output distributions without further inference holds, the work would provide a genuinely low-latency, scalable alternative to iterative re-prompting ensembles. The public code release would strengthen reproducibility.
major comments (2)
- [Abstract and §3] Abstract and architecture description: The load-bearing claim that check nodes assess consistency using 'diverse epistemic criteria' and that the message-passing protocol resolves disagreements 'without any further LLM inference calls' is stated but never given a concrete algorithmic definition or pseudocode showing how these operations act on token distributions rather than text. Without this, it is impossible to verify whether the zero-call guarantee during refinement is actually satisfied or whether the method reduces to standard aggregation whose advantage over baselines is no longer guaranteed.
- [§5] §5 (Experiments): The reported 97% token reduction, 6X API-call decrease, and consistent outperformance are presented without implementation details, statistical tests, ablation results on the asymmetric damping mechanism, or precise descriptions of the multi-agent baselines and their prompting regimes. This absence prevents assessment of whether the efficiency and accuracy claims are supported by the data.
minor comments (1)
- The abstract states that 'the full pipeline and code will be made public,' which is welcome, but the manuscript itself should still contain sufficient methodological detail for independent verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and architecture description: The load-bearing claim that check nodes assess consistency using 'diverse epistemic criteria' and that the message-passing protocol resolves disagreements 'without any further LLM inference calls' is stated but never given a concrete algorithmic definition or pseudocode showing how these operations act on token distributions rather than text. Without this, it is impossible to verify whether the zero-call guarantee during refinement is actually satisfied or whether the method reduces to standard aggregation whose advantage over baselines is no longer guaranteed.
Authors: We agree that Section 3 would benefit from greater algorithmic specificity. The current description outlines the bipartite factor graph, variable/check node roles, and message-passing protocol operating on output distributions, but lacks explicit pseudocode. In the revision we will add a detailed algorithm box (and accompanying prose) that specifies exactly how check nodes compute consistency scores from token distributions using the listed epistemic criteria and how the asymmetric damping is applied, confirming that all operations remain distribution-based with zero additional LLM calls during refinement. revision: yes
-
Referee: [§5] §5 (Experiments): The reported 97% token reduction, 6X API-call decrease, and consistent outperformance are presented without implementation details, statistical tests, ablation results on the asymmetric damping mechanism, or precise descriptions of the multi-agent baselines and their prompting regimes. This absence prevents assessment of whether the efficiency and accuracy claims are supported by the data.
Authors: We acknowledge the need for greater experimental transparency. The revision will include: (i) full implementation details and hyper-parameter settings, (ii) statistical significance tests (paired t-tests and Wilcoxon signed-rank tests with p-values) on the accuracy improvements, (iii) an ablation study isolating the contribution of the asymmetric damping mechanism, and (iv) precise descriptions of each multi-agent baseline, including their exact prompting templates and number of refinement rounds. These additions will directly support the reported efficiency and accuracy claims. revision: yes
Circularity Check
No circularity: new graph-based aggregation method is self-contained
full rationale
The paper proposes a bipartite factor graph with variable nodes for LLMs and check nodes for consistency assessment via message passing on output distributions, without any equations, fitted parameters, or predictions that reduce to inputs by construction. Claims of token reduction and zero additional LLM calls during refinement follow directly from the architecture description rather than self-definition or self-citation chains. Empirical results on MMLU and related benchmarks provide independent evaluation support.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bipartite factor graph representation suffices to capture LLM predictions and consistency checks at the semantic layer
invented entities (1)
-
asymmetric damping mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Llm-blender: Ensembling large language models with pairwise ranking and generative fusion
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 14165–14178, 2023
2023
-
[2]
Don't Waste Bits! Adaptive KV-Cache Quantization for Lightweight On-Device LLMs
Sayed Pedram Haeri Boroujeni, Niloufar Mehrabi, Patrick Woods, Gabriel Hillesheim, and Abolfazl Razi. Don’t waste bits! adaptive kv-cache quantization for lightweight on-device llms. arXiv preprint arXiv:2604.04722, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Toward expert-level medical question answering with large language models
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models. Nature medicine, 31(3):943–950, 2025
2025
-
[4]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. Are we done with mmlu? In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolog...
2025
-
[5]
Graph-of-Agents: A Graph-based Framework for Multi-Agent LLM Collaboration
Sukwon Yun, Jie Peng, Pingzhi Li, Wendong Fan, Jie Chen, James Zou, Guohao Li, and Tianlong Chen. Graph-of-agents: A graph-based framework for multi-agent llm collaboration. arXiv preprint arXiv:2604.17148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities, 2024. URL https://arxiv. org/abs/2406.04692, 1(2):5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Toward massive, ultrareliable, and low- latency wireless communication with short packets
Giuseppe Durisi, Tobias Koch, and Petar Popovski. Toward massive, ultrareliable, and low- latency wireless communication with short packets. Proceedings of the IEEE, 104(9):1711– 1726, 2016
2016
-
[8]
Harnessing consistency for robust test-time llm ensemble
Zhichen Zeng, Qi Yu, Xiao Lin, Ruizhong Qiu, Xuying Ning, Tianxin Wei, Yuchen Yan, Jingrui He, and Hanghang Tong. Harnessing consistency for robust test-time llm ensemble. In Findings of the Association for Computational Linguistics: EACL 2026, pages 3528–3545, 2026
2026
-
[9]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. In Forty-first international conference on machine learning, 2024
2024
-
[10]
Encouraging divergent thinking in large language models through multi- agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent thinking in large language models through multi- agent debate. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 17889–17904, 2024
2024
-
[11]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Wenzhe Li, Yong Lin, Mengzhou Xia, and Chi Jin. Rethinking mixture-of-agents: Is mixing different large language models beneficial? arXiv preprint arXiv:2502.00674, 2025
-
[13]
Se- lene: Selective and evidence-weighted llm debating for efficient and reliable reasoning
Akshay Verma, Swapnil Gupta, Deepak Gupta, Prateek Sircar, and Siddharth Pillai. Se- lene: Selective and evidence-weighted llm debating for efficient and reliable reasoning. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (V olume5: Industry Track), pages 95–104, 2026
2026
-
[14]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Smoothie: Label free language model routing
Neel Guha, Mayee F Chen, Trevor Chow, Ishan S Khare, and Christopher Re. Smoothie: Label free language model routing. Advances in Neural Information Processing Systems, 37:127645– 127672, 2024
2024
-
[16]
Token-Level LLM Collaboration via FusionRoute
Nuoya Xiong, Yuhang Zhou, Hanqing Zeng, Zhaorun Chen, Furong Huang, Shuchao Bi, Lizhu Zhang, and Zhuokai Zhao. Token-level llm collaboration via fusionroute. arXiv preprint arXiv:2601.05106, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Latent Collaboration in Multi-Agent Systems
Jiaru Zou, Xiyuan Yang, Ruizhong Qiu, Gaotang Li, Katherine Tieu, Pan Lu, Ke Shen, Hang- hang Tong, Yejin Choi, Jingrui He, et al. Latent collaboration in multi-agent systems. arXiv preprint arXiv:2511.20639, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[19]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[20]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Conference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[22]
Qwen2.5: A party of foundation models.https://qwen.ai/blog?id=qwen2.5,
Qwen Team. Qwen2.5: A party of foundation models.https://qwen.ai/blog?id=qwen2.5,
-
[23]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
MathΣtral.https://mistral.ai/news/mathstral/, 2024
Mistral AI. MathΣtral.https://mistral.ai/news/mathstral/, 2024. July 2024
2024
-
[25]
Bio-Medical-Llama-3-8B: A high-performance biomedical language model
ContactDoctor. Bio-Medical-Llama-3-8B: A high-performance biomedical language model. Online, 2024
2024
-
[26]
Instruction pre-training: Language models are supervised multitask learners
Daixuan Cheng, Yuxian Gu, Shaohan Huang, Junyu Bi, Minlie Huang, and Furu Wei. Instruction pre-training: Language models are supervised multitask learners. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2529–2550, 2024
2024
-
[27]
SaulLM-7B: A pioneering large language model for law.arXiv preprint arXiv:2403.03883, 2024
Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre FT Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, et al. Saullm-7b: A pioneering large language model for law. arXiv preprint arXiv:2403.03883, 2024
-
[28]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems, 36:46534–46594, 2023. 11
2023
-
[29]
Reconcile: Round-table conference improves reasoning via consensus among diverse llms
Justin Chen, Swarnadeep Saha, and Mohit Bansal. Reconcile: Round-table conference improves reasoning via consensus among diverse llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 7066–7085, 2024
2024
-
[30]
Google- proof
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. A dynamic llm-powered agent network for task-oriented agent collaboration. In First Conference on Language Modeling, 2024. 12 A Appendix This appendix provides supplementary notation, proofs, theoretical foundations, and extended experi- mental results. We first summarize the key notation and para...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.